
Meta-Agent: From Task Descriptions to Verified Multi-Agent Systems
Source: arXiv:2605.25233 · Published 2026-05-24 · By Andy Xu, Yu-Wing Tai
TL;DR
Meta-Agent addresses the brittleness and error propagation challenges in existing multi-agent AI frameworks that arise as task workflows increase in scale and complexity. The key innovation is a two-phase framework integrating automatic construction and execution of specialized multi-agent systems from natural language task descriptions, with explicit verification at both construction and runtime. In the construction phase, the system decomposes tasks into a directed acyclic graph of agents with precise input/output contracts and verification criteria, grounding each agent with external evidence and generating code artifacts that are rigorously verified before execution. Execution phase coordination includes continuous verification and error attribution to localize and correct faults efficiently.
Evaluated on six diverse benchmarks spanning coding (HumanEval, MBPP), mathematical reasoning (GSM8K, MATH), and reading comprehension (HotpotQA, DROP), Meta-Agent consistently outperforms strong baselines including recent automated agent-design systems (AFlow) with average task success improvement of 2.4 points, rising to 13.4 points on complex symbolic math tasks. Ablation studies underscore the essential contribution of integrated verification and API grounding, while executor-agnostic experiments confirm the transferability and robustness of the synthesized agent workflows across underlying language models. This work reframes multi-agent systems as synthesize-and-validate artifacts rather than fixed architectures, highlighting the importance of tight integration between planning, grounding, and structured verification for reliable long-horizon AI workflows.
Key findings
- Meta-Agent improves average benchmark scores by 2.4 points over AFlow baseline, achieving 82.7 vs 80.3 across six diverse tasks using GPT-4o-mini executor (Table 2).
- On the challenging MATH benchmark focused on symbolic reasoning, Meta-Agent outperforms AFlow by 13.4 points (69.6 vs 56.2).
- Ablation on DROP shows removing verification causes largest performance drop of 7.1 points, followed by removing external API research causing a 5.5-point drop (Table 3).
- Executor-agnostic experiments replacing GPT-4o-mini with Claude Sonnet 4.6 improve average performance from 82.7 to 87.9 without workflow changes, indicating method generalizes beyond specific LLMs (Table 4).
- Three-level error attribution (local, upstream, structural) enables targeted recovery strategies, preventing cascading failures and improving workflow stability.
- Construction-time verification validates agent specifications, code generation, and grounding, allowing targeted regeneration of failing components instead of full pipeline retry.
- Execution-time verification gates intermediate outputs with schema and behavioral checks to block error propagation during task execution.
- The system automatically decomposes tasks into DAGs of specialized agents with explicit contracts and verification criteria synthesized from natural-language descriptions.
Threat model
n/a — The system does not consider a malicious adversary but focuses on reliability challenges inherent in complex multi-agent AI workflows where errors arise from imperfect task decomposition, knowledge grounding, or agent execution. The framework assumes trustworthy language models and external information, aiming to prevent error propagation rather than adversarial attacks.
Methodology — deep read
Threat model & assumptions: The adversary is not explicitly defined as a malicious entity; rather, the challenge addressed is the brittleness and error propagation inherent to automated multi-agent systems executing complex workflows from incomplete or ambiguous user task descriptions. The system assumes the underlying language models and external knowledge sources are generally reliable but prone to errors in specification, grounding, or execution. The design prevents compounding errors but does not specifically mitigate adversarial manipulation or malicious inputs.
Data: The evaluation uses six established benchmarks: HumanEval (code generation, ~164 problems), MBPP (Python programming, ~974 samples), GSM8K (math word problems, 8k+ samples), MATH (level-5 math competition problems, ~12k), HotpotQA (multi-hop reading comprehension, ~113k questions), and DROP (discrete reasoning over paragraphs, ~96k samples). Official test splits from Zhang et al. [2025d] are used with single-run evaluation. No additional preprocessing beyond standard task-specific formatting is performed.
Architecture/algorithm: Meta-Agent is a two-phase system:
- Construction phase: The meta-agent parses a natural-language task description into a DAG of agent specifications. Each node has explicit input/output contracts and verification criteria. External web/API grounding is retrieved to inform agent roles. Agent code and prompts are generated (e.g., system prompts, tool configs) by language models (e.g., GPT-4o-mini). Construction-time verification applies static code checks and behavioral simulation against specifications, generating typed failure signals when violations occur. Failures map to precise upstream stages for targeted regeneration (e.g., re-planning, re-grounding, re-coding).
- Execution phase: A coordinator dispatches subtasks to agents following DAG dependencies. Intermediate outputs are verified before passing downstream using schema and behavioral checks. A three-level error attribution mechanism classifies failures as local (agent-level), upstream (dependency), or structural (decomposition errors). Recovery is applied accordingly: retries, upstream re-execution, or partial re-decomposition.
Training regime: Not traditional ML training; components instantiate with pre-trained LLMs (GPT-4o-mini or Claude Sonnet 4.6) used at inference time. Hyperparameters include prompt engineering for agent generation and verification steps, but no stochastic training or fine-tuning is performed.
Evaluation protocol: Metrics vary by benchmark, e.g., pass@1 for HumanEval/MBPP code tasks, solve rate for MATH and GSM8K, F1 or exact match for reading comprehension. Baselines include strong prompting strategies (CoT, MedPrompt, MultiPersona), self-refine agents, and recent multi-agent models (ADAS, AFlow). Single-run scores on held-out test sets are reported, with ablations removing construction components to measure impact. Executor-agnostic tests replace base LLM to evaluate workflow generality. No explicit adversarial or distribution-shift stress tests were reported.
Reproducibility: Code and detailed implementation data not publicly released as of the paper version. Evaluation uses publicly available benchmarks and standard test splits for comparability. The system relies on proprietary LLMs (GPT-4o-mini and Claude Sonnet 4.6) for generation and verification stages. The paper includes extensive task-specific running examples and detailed methodology to support reproduction.
Technical innovations
- Integration of a unified verification loop combining construction-time static and behavioral verification with execution-time runtime validation to prevent cascading failures in multi-agent workflows.
- Introduction of a three-level error attribution framework distinguishing local, upstream, and structural failures, enabling targeted, cost-scaled recovery strategies in multi-agent execution.
- Automatic synthesis of task-specific multi-agent systems as directed acyclic graphs with explicit input/output contracts and verification criteria from natural-language task descriptions.
- Design-time grounding of agent specifications by incorporating external web/API evidence prior to execution, reducing ambiguity and improving reliability.
Datasets
- HumanEval — ~164 programming problems — public
- MBPP — ~974 Python programming tasks — public
- GSM8K — 8,000+ math word problems — public
- MATH — ~12,000 level-5 competition math problems — public
- HotpotQA — ~113,000 multi-hop reading comprehension questions — public
- DROP — ~96,000 discrete reasoning tasks over text — public
Baselines vs proposed
- AFlow baseline: average score = 80.3 vs Meta-Agent: 82.7 (on GPT-4o-mini)
- CoT-SC prompting: average = 76.0 vs Meta-Agent: 82.7
- ADAS (auto-agent design): average = 67.2 vs Meta-Agent: 82.7
- HumanEval pass@1: AFlow 94.7% vs Meta-Agent 96.0%
- MATH solve rate: AFlow 56.2% vs Meta-Agent 69.6% (+13.4 points)
- DROP F1: AFlow 80.6 vs Meta-Agent 82.7
- Executor swap (Claude Sonnet 4.6) with fixed construction pipeline: average score improves from 82.7 to 87.9
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.25233.
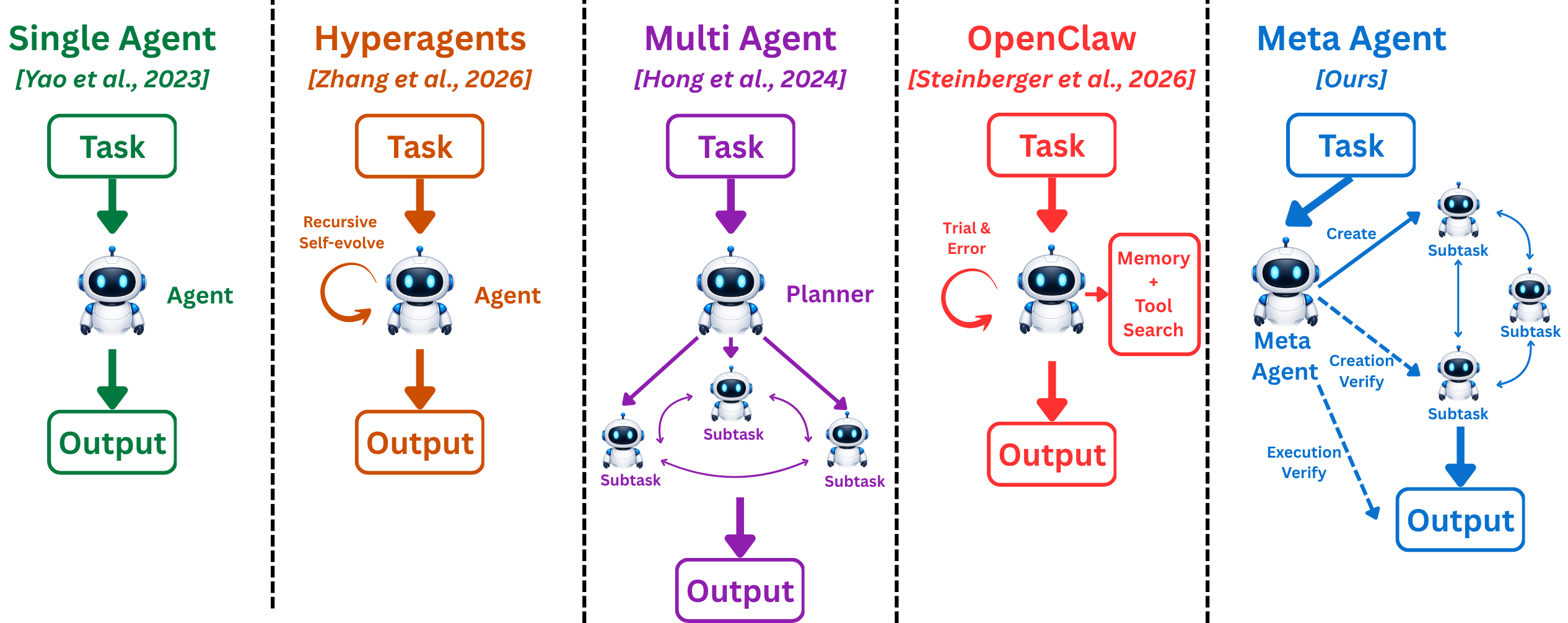
Fig 1: Comparison of agent paradigms. We contrast five approaches to constructing AI agents
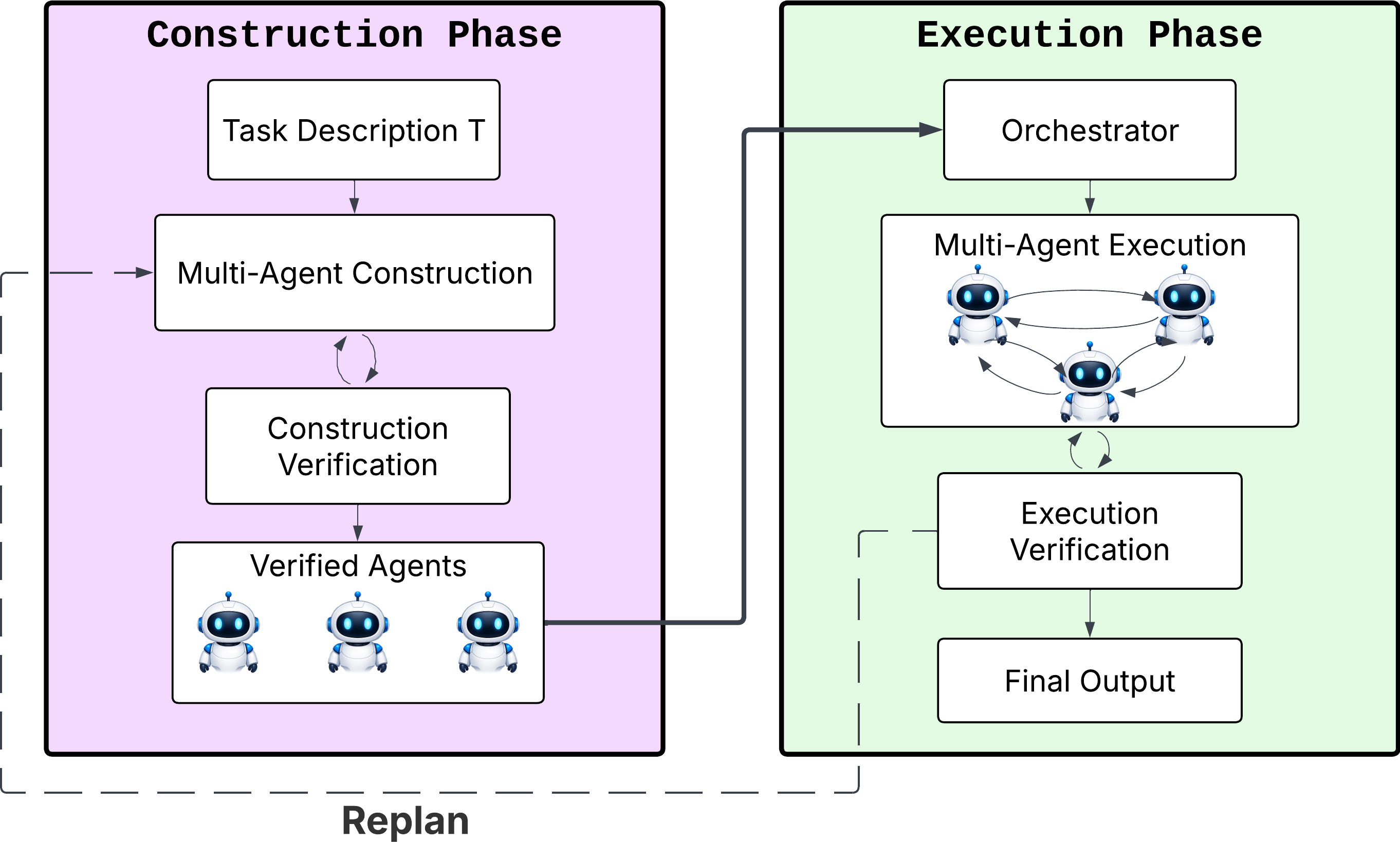
Fig 2: Overview of the Meta-Agent. Phase 1 (left) transforms a task description into a DAG of
Limitations
- Automatically generated multi-agent workflows may underperform expert-designed systems with rich domain knowledge and handcrafted heuristics.
- Verification and grounding introduce computational overhead during construction and execution, impacting efficiency.
- Evaluation is limited to established academic benchmarks without testing robustness under adversarial or real-world distribution shifts.
- No public code or model weights released, which may hinder reproducibility and external validation.
- The system assumes reliable underlying LLMs and external knowledge sources; failures due to noisy or malicious inputs are not explicitly addressed.
- Error recovery relies on heuristics for attribution and retry, which could be insufficient in highly ambiguous or dynamic task settings.
Open questions / follow-ons
- Can verification and error attribution mechanisms be extended to detect and mitigate adversarial manipulations or poisoned inputs?
- How can domain-specific priors or expert heuristics be incorporated without sacrificing scalability or generality in system construction?
- What are the trade-offs between verification cost and execution latency in real-time or interactive multi-agent applications?
- How does Meta-Agent perform under distribution shift or on tasks requiring lifelong adaptation and learning from interaction?
Why it matters for bot defense
Bot-defense and CAPTCHA systems increasingly rely on multi-agent AI workflows for complex decision-making such as adaptive challenge generation, dynamic user behavior analysis, and automated fraud detection. Meta-Agent’s approach of constructing verified, task-specific multi-agent systems from natural language specifications provides a promising paradigm to improve reliability and robustness in these long-horizon, multi-step workflows. The explicit construction-time and execution-time verification loops, along with error attribution mechanisms, help prevent subtle cascading failures and improve system stability — critical in security settings where erroneous intermediate outputs can be exploited. Furthermore, grounding agent specifications with external evidence reduces ambiguity and potentially strengthens resilience to adversarial input noise.
Practitioners could leverage Meta-Agent’s synthesis framework to automatically generate modular, verifiable agent pipelines aligned with evolving threat models without extensive manual engineering. However, the approach’s overhead and requirement for strong underlying LLMs suggest it may be better suited currently for high-assurance or backend analytics tasks rather than latency-sensitive interactive CAPTCHA challenges. Future work integrating domain-specific security heuristics and adversarial robustness evaluations would further enhance applicability in bot-defense.
Cite
@article{arxiv2605_25233,
title={ Meta-Agent: From Task Descriptions to Verified Multi-Agent Systems },
author={ Andy Xu and Yu-Wing Tai },
journal={arXiv preprint arXiv:2605.25233},
year={ 2026 },
url={https://arxiv.org/abs/2605.25233}
}