
Generative AI as a Design Variable: An Evidence-Centered Framework for Principled Governance in STEM Assessment
Source: arXiv:2605.24837 · Published 2026-05-24 · By Yizhu Gao, Zhongzhou Chen, Min Li, Xiaoming Zhai
TL;DR
This paper addresses the challenge that Generative Artificial Intelligence (GenAI) poses to STEM educational assessments by undermining traditional validity assumptions. Instead of viewing GenAI solely as a threat or external variable, the authors propose a novel framework grounded in Evidence-Centered Design (ECD) that treats GenAI as a design variable incorporated into the construct, evidence, and task models of assessment arguments. The approach specifies three principled governance modes—Restrict, Scaffold, and Require—based on whether GenAI use contaminates inferential validity, supports peripheral demands, or constitutes the target disciplinary AI interaction competency itself.
The framework is then illustrated concretely through two Require-mode tasks deployed in an introductory physics course. These tasks are designed to elicit layered student-AI interaction artifacts such as prompts, critiques, and revisions which enable scoring based on defensible, student-data and expert-knowledge-grounded rubrics. The results demonstrate that student disciplinary AI interaction competencies become observable, scorable, and distinguishable from AI outputs, supporting validity arguments that integrate GenAI as an integral part of the assessment. This situates governance decisions in a principled validity framework rather than ad hoc prohibitions or unchecked use, bridging assessment integrity with authentic preparation for AI-enabled workplaces.
Key findings
- Generative AI threatens validity by contaminating the inferential link from student work products to underlying unaided proficiency, especially for standard STEM problems (Section 2.2).
- Tasks with cognitive demands beyond GenAI’s substitution capacity (e.g., ambiguous or novel problems) preserve evidential integrity and allow Scaffold governance without redesign (Section 3.2, condition 1).
- Conversation-based or multi-step tasks can leverage GenAI interaction to produce rich process artifacts (prompts, critiques, revisions) that make student reasoning observable and scorable (Section 2.3, 3.2 condition 2).
- Guardrailing GenAI to peripheral functions (e.g., formula retrieval but not solution generation) can preserve validity with task redesign (Section 3.2 condition 3).
- Require-GenAI tasks explicitly treat AI interaction competency as the target construct, eliciting evidence of student prompt engineering, critical evaluation, and reasoning distinguishable from AI output (Section 3.1, 4).
- Two Require-GenAI tasks designed for an undergraduate physics course demonstrate observable Physics-Driven AI Interaction and Physics-Grounded Evaluation dimensions from process artifacts (Section 4).
- Students who uncritically accept AI output produce artifacts lacking domain-specific critique, making detection possible via rubric scoring of prompts and error identification (Section 4.1).
- The framework enables principled, validity-grounded governance decisions: Restrict only when no scaffold or require design can preserve construct inference (Section 3.3).
Threat model
The threat model assumes students with access to current generative AI tools who may use these systems to complete STEM assessments either uncritically outsourcing or with varying degrees of interaction. The adversary does not have ability to compromise assessment systems or hide AI use but can influence observable student response artifacts. The governance framework aims to preserve validity under these conditions by either restricting, scaffolding, or requiring GenAI use depending on whether construct inference can be maintained or redefined. Malicious or highly covert adversarial behaviors fall outside scope.
Methodology — deep read
Threat Model and Assumptions: The study assumes adversaries are not malicious hackers but normal students who might use GenAI tools to outsource answers, potentially invalidating assessment inferences about unaided proficiency. The adversary’s knowledge includes access to current GenAI systems (e.g., ChatGPT, Google Gemini), with the capacity to engage interactively but not to manipulate assessment infrastructure or produce unobservable outputs. The focus is on principled governance decisions to preserve validity under realistic student AI use.
Data: Empirical illustration uses two novel assessment tasks deployed in an introductory undergraduate physics course. Participants produced multi-part response artifacts including AI tool identification, prompt conversation summaries, AI-generated outputs, student critiques identifying AI errors, and reflections on AI assumptions. These artifacts served as observable data for scoring and validity analyses. Exact dataset size and participant demographics are not specified in the truncated text.
Architecture / Algorithm: The core methodological contribution is a conceptual framework rather than an ML model. The framework applies Evidence-Centered Design's student, evidence, and task models to analyze GenAI’s impact on assessment validity and guides governance modes (Restrict, Scaffold, Require) by interpreting construct shifts, evidence rules disruption, and task redesign possibilities. For the Require mode tasks, bespoke analytic rubrics based on prior frameworks (Li et al., 2025) decompose AI interaction competency into Physics-Driven AI Interaction and Physics-Grounded Evaluation dimensions. Evidence rules specify how student-generated meta-data and critiques are used to infer disciplinary competence distinct from AI capability.
Training Regime: Not applicable as the focus is assessment design and rubric development rather than training predictive models.
Evaluation Protocol: Validity arguments rely on expert review and student data to verify that the layered task artifacts (prompts, critiques, etc.) contain observable behaviors that differentiate student reasoning from AI output. Scoring rubrics operationalize evaluation with criteria for prompt quality, error identification specificity, and justification rigor. Empirical deployment in physics education confirms students’ capability to meet rubric criteria, demonstrating feasibility and construct validity of AI interaction competency. No formal quantitative metrics or statistical tests are reported in the truncated text.
Reproducibility: Code release or dataset sharing is not mentioned; the physics tasks are described in detail but artifact data and scoring materials appear held internally. The framework itself is generalizable to STEM assessment design contexts where GenAI is present.
Example End-to-End Illustration (Remora Free Body Diagram task): Students receive an image of a remora fish and must collaboratively construct a free body diagram using GenAI. They document which AI tools and versions they used, summarize the prompting conversation to show how physics concepts guided AI queries, produce the AI-generated diagram, critique errors or omissions in the AI output at multiple physics modeling levels, and reflect on AI assumptions. Raters use the summary of prompts (Q2) to assess Physics-Driven AI Interaction, and the critique response (Q4) for Physics-Grounded Evaluation. Students who critically engage physically specific forces yield higher scores, while uncritical acceptance is detectable by generic or incomplete force listings. This layered documentation preserves the inferential chain linking student knowledge to artifacts even with generative AI involvement.
Technical innovations
- Integration of Evidence-Centered Design models (student, evidence, task) to analyze and govern Generative AI use in STEM assessment.
- Formal taxonomy of three governance modes (Restrict, Scaffold, Require) linked to distinct validity conditions concerning GenAI's impact on construct measurement and evidential integrity.
- Operationalization of disciplinary AI interaction competency as an explicit target construct assessed via multi-layered process artifacts including AI prompt conversations, critiques, and reflections.
- Design and rubric-based scoring of Require-mode tasks that make student cognitive contributions observable, differentiable, and scorable despite generative AI tool involvement.
Datasets
- Introductory Physics Require-GenAI Task Responses — size unspecified — data collected from an undergraduate course at University of Georgia
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.24837.
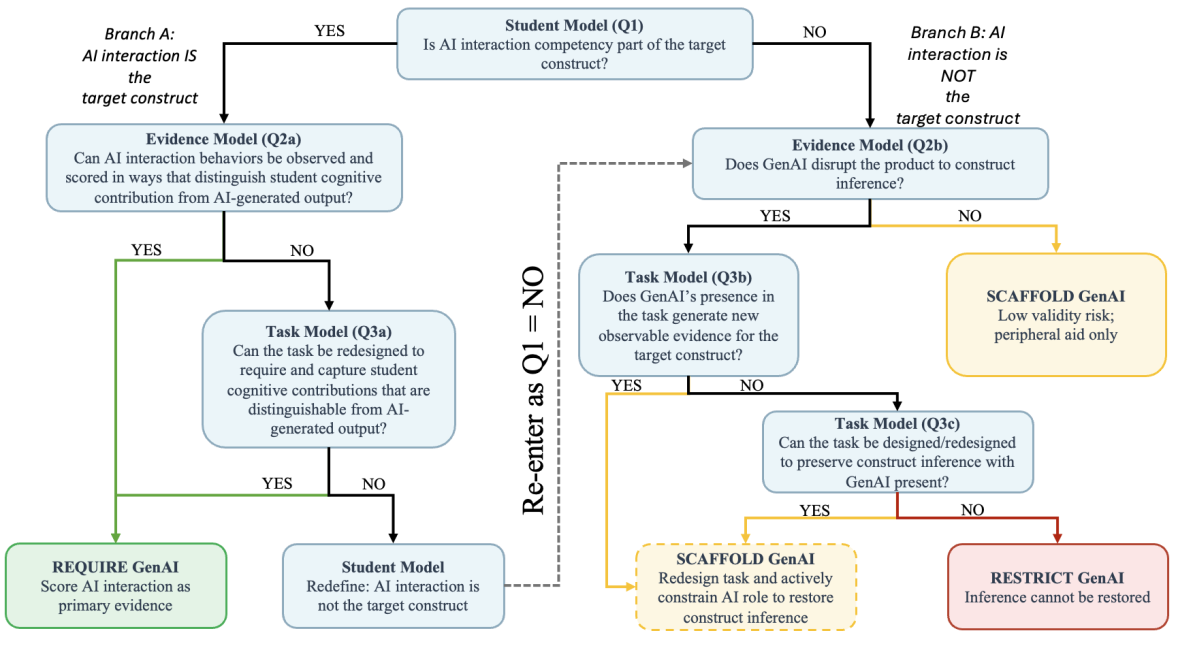
Fig 1: GenAI Governance in STEM Assessment

Fig 2: Require-GenAI Task “Remora Free Body Diagram”

Fig 3: Require-GenAI Task “Water Balloon”
Limitations
- The study does not report quantitative metrics or large-scale statistical validation of the rubric scoring or framework application.
- Data provenance and sample size details for the physics task deployments are not fully specified, limiting assessment of generalizability.
- No adversarial testing against sophisticated attempts to game the AI interaction or detection rubrics is reported.
- The approach requires considerable infrastructure and instructor expertise to implement scaffold and require governance modes at scale.
- Current GenAI capabilities may evolve rapidly, requiring continuous reassessment and updates to governance decisions and task designs.
- The paper focuses on introductory physics tasks; applicability to other STEM disciplines requires further investigation.
Open questions / follow-ons
- How well do the proposed rubrics and governance modes generalize across diverse STEM disciplines beyond physics?
- What are the best methods to scale conversation-based and multi-step GenAI interaction tasks in large courses with limited instructor bandwidth?
- How will ongoing advances in GenAI capabilities and multimodal models alter the boundaries between Restrict, Scaffold, and Require governance decisions?
- Can automated or semi-automated scoring systems effectively support the human rubric evaluations of layered AI interaction process artifacts?
Why it matters for bot defense
This work is valuable to bot-defense and CAPTCHA practitioners as it reframes AI not only as a threat but as a design variable to be integrated and measured authentically. For CAPTCHA algorithm designers, the concept of eliciting process artifacts (prompts, critiques) to make AI interaction behavior observable and scorable informs new directions for challenges that require human-AI collaboration rather than simple human-AI distinction. The Require stance parallels designs that enforce and verify meaningful cognitive engagement rather than detecting outright automation. Scaffold-mode governance suggests that brain-computer interaction measurement can be designed to permit bounded AI assistance without forfeiting security guarantees. Overall, this paper advocates principled, validity-grounded approaches rather than blanket restrictions or simplistic detection, encouraging bot-defense systems to leverage the transparency and interaction logs that AI collaboration produces. It also highlights the importance of aligning assessment or defense goals with the cognitive or interaction constructs rather than solely final products, which is relevant for next-generation CAPTCHA design.
Cite
@article{arxiv2605_24837,
title={ Generative AI as a Design Variable: An Evidence-Centered Framework for Principled Governance in STEM Assessment },
author={ Yizhu Gao and Zhongzhou Chen and Min Li and Xiaoming Zhai },
journal={arXiv preprint arXiv:2605.24837},
year={ 2026 },
url={https://arxiv.org/abs/2605.24837}
}