
APT-Agent: Automated Penetration Testing using Large Language Models
Source: arXiv:2605.24949 · Published 2026-05-24 · By William Guanting Li, Alsharif Abuadbba, Kristen Moore, Dan Dongseong Kim
TL;DR
The paper "APT-Agent: Automated Penetration Testing using Large Language Models" addresses key challenges in automating penetration testing (pen-testing) workflows with large language models (LLMs). Traditional manual pen-testing is resource-intensive and struggles to scale with infrastructure complexity. While LLMs have demonstrated potential for automated pen-testing, existing methods face critical issues: hallucination of technical commands and insufficient long-term contextual memory. APT-Agent is a novel fully automated framework that systematically orchestrates recon, exploit, and exfiltration phases using LLMs enhanced by two core technical innovations: a hybrid rectification module that corrects hallucinated Metasploit commands and a command-specific, stage-aware context management module (CMM) to maintain operational state across multi-step attack campaigns. Evaluated against Metasploitable 2 vulnerabilities spanning web, database, and network services, APT-Agent achieves a high 84.29% end-to-end exploitation success rate, substantially outperforming baseline frameworks Script Kiddie (48.57%) and PentestGPT (18.57%) under matched GPT-4o conditions. By combining precise command validation and explicit multi-stage memory retention, the system reduces human involvement and cognitive overhead while improving automation reliability and efficiency. This work significantly advances the state of automated LLM-driven penetration testing toward scalable, defensible, and fully autonomous security assessments.
Key findings
- APT-Agent attains an 84.29% end-to-end successful exploitation rate across 7 vulnerable services on Metasploitable 2 (59/70 runs), compared to 48.57% for Script Kiddie and 18.57% for PentestGPT using the same GPT-4o LLM.
- The hybrid rectification module corrects 62.5% of hallucinated Metasploit module invocations in-run, recovering 10 out of 16 hallucinated commands among 53 total module calls.
- Removing the Rectification Module drops the success rate from 84.29% to 71.43%, and removing the Context Management Module (CMM) reduces it further to 65.71%. Disabling both reduces success rate drastically to 54.29%.
- APT-Agent achieves consistent success across heterogeneous service types: 10/10 on vsftpd, 9/10 on OpenSSH, PostgreSQL, and Samba; 7/10 on Apache HTTP and UnrealIRCd.
- Average iterations per campaign vary by service complexity: from 4.6 for Telnet to 17.3 for Apache HTTP; exploitation iterations range from 1.2 to 7.9 per service.
- The CMM reduces duplicated command generation and enables adaptive strategy refinement by injecting concise JSON-format stage-specific execution logs (iteration, command, success/fail) back into prompts.
- APT-Agent outperforms prior methods particularly on services requiring iterative reasoning and multi-step planning, with major gaps on Apache 2.2.8, OpenSSH 4.7 and Telnet services.
- Brute-force service modules are dynamically tagged and allocated longer execution windows (e.g., 180s) to efficiently manage extensive outputs and runtime budgets.
Threat model
The adversarial model assumed is an automated penetration testing agent orchestrated by an LLM acting as a simulated attacker against a known vulnerable target infrastructure. The adversary can issue commands, parse scan outputs, and adaptively plan penetration steps but does not have external expert guidance or the ability to directly manipulate the underlying LLM internal state or knowledge base. The agent cannot exploit zero-day unknown vulnerabilities outside of Metasploit module coverage, nor can it evade active defenses dynamically. The focus is on autonomous, scripted exploitation rather than adversaries with human-level domain expertise or evasion tactics.
Methodology — deep read
APT-Agent's methodology is built around addressing two critical LLM limitations in automated penetration testing: hallucinated technical commands and lacking long-term memory for multi-step campaigns.
Threat Model & Assumptions: The adversary is an autonomous LLM agent executing penetration testing against a realistic, public open-source target environment (Metasploitable 2) with known vulnerabilities. The agent has no external expert input during campaigns, relies solely on parsing scan results and module databases, and seeks to exfiltrate sensitive files. The adversary cannot modify or deceive the LLM internally or externally and cannot manipulate the knowledge base. The system assumes access to Metasploit framework modules.
Data: The evaluation uses Metasploitable 2 virtual machine as the testbed, hosting vulnerable services spanning web (Apache), database (PostgreSQL, MySQL), and network protocols (FTP vsftpd, SSH OpenSSH, Telnet, Samba SMB, UnrealIRCd IRC). Target services have built-in vulnerabilities exploitable through Metasploit modules. The agent uses a curated knowledge base of 3,253 valid Metasploit modules collected from official repositories, indexed by service, OS, module type, and payload details. 10 independent runs per service are conducted under a 30 iteration budget per stage.
Architecture / Algorithms: APT-Agent consists of three primary LLM-driven components iterated each cycle: (a) Tactic Selection Module - uses accumulated knowledge and prior results to pick a stage from the MITRE ATT&CK framework (Reconnaissance, Exploitation, Exfiltration); (b) Command Generation Module - translates high-level tactics into executable commands, heavily assisted by the Rectification Module and Context Management Module; (c) Output Translation Module - parses raw tool outputs (Nmap scans, Metasploit responses) into structured feedback (success/fail and summaries) for decision loops.
Core innovations include:
- Rectification Module: uses a hybrid fuzzy-string and suffix-based matching algorithm (leveraging RapidFuzz Levenshtein similarity) to ground hallucinated LLM-generated Metasploit command paths to the closest valid module from the curated database. It also performs option injection to ensure mandatory arguments and validate payload compatibility.
- Context Management Module (CMM): maintains concise JSON state logs (iteration number, command string, binary success/fail) per stage (EXPLOIT and EXFILTRATE) instead of verbose raw outputs. These context logs are reinjected into Command Generation prompts each iteration to preserve long-term state, avoid command repetition, and support adaptive planning.
Training Regime: No training per se. The system operates by querying a pretrained GPT-4o as the core LLM engine. Prompt engineering is used extensively with injected context and structured feedback. Module rectification and option filling utilize external lookup databases and Metasploit RPC APIs. Execution timeout and iteration budgets are set per module type.
Evaluation Protocol: Metrics are per-service success defined as successful file exfiltration within iteration budgets, tracked over 10 independent runs per service. Baselines include Script Kiddie and PentestGPT run under identical GPT-4o backends with controlled human intervention limits (none for automated systems; minimal allowed for PentestGPT). Ablation studies disable rectification or CMM components individually and jointly to measure impact on success rates. Success rates, iteration counts, and duplication rates of command generation are analyzed.
Reproducibility: Source code and curated Metasploit module databases are publicly released on GitHub. The Metasploitable 2 VM is widely available as an open research tool. GPT-4o model weights are not open but the system is designed to allow plug-in of comparable LLMs. Detailed method descriptions enable replication of hybrid rectification and memory management algorithms.
Example End-to-End Workflow: On recognizing a vulnerable SSH service via Nmap scan (RECON), the Tactic Selection Module prompts the LLM to generate appropriate Metasploit commands targeting ssh_enumusers. If the path is hallucinated as exploit/linux/ssh/openssh_user_enum, the Rectification Module corrects it to auxiliary/scanner/ssh/ssh_enumusers by fuzzy suffix matching. The command is issued via MSFRPCD. Upon success/failure, the outcome and commands are logged compactly in CMM. Future exploitation attempts consult this memory to avoid repeating failed commands, dynamically shifting to credentials brute-force modules or alternate exploits until a session opens. Then in EXFILTRATION, Unix or meterpreter commands are crafted adaptively based on session type, monitored, and refined until flag.txt is extracted or iteration limit is reached.
Technical innovations
- Hybrid Rectification Module combining fuzzy string matching and suffix alignment to correct hallucinated LLM-generated Metasploit command paths referencing a curated 3,253-module knowledge base.
- Stage-aware Command-specific Context Management Module (CMM) that logs compact JSON-formatted execution histories with iteration count, command string, and binary success/fail, reinjected into prompts to preserve long-horizon operational state.
- Modular LLM framework separating Tactic Selection (strategy), Command Generation (execution), and Output Translation (feedback) to mirror human penetration tester workflows and support fully autonomous multi-stage campaigns.
- Dynamic brute-force awareness tagging enabling adaptive runtime budgets and console execution windows (e.g., 180s for brute-force modules vs. 30s otherwise) to optimize throughput and resource allocation.
Datasets
- Metasploitable 2 VM — Open-source vulnerable target environment with multiple vulnerable services — publicly available
- Curated Metasploit Modules Knowledge Base — 3,253 validated module paths and metadata — constructed by authors from official Metasploit repositories
Baselines vs proposed
- Script Kiddie: End-to-end success rate = 48.57% vs APT-Agent: 84.29%
- PentestGPT: End-to-end success rate = 18.57% vs APT-Agent: 84.29%
- APT-Agent without Rectification Module: success rate = 71.43% vs full system: 84.29%
- APT-Agent without Context Management Module: success rate = 65.71% vs full system: 84.29%
- APT-Agent with both Rectification and Context Management removed: success rate = 54.29% vs full system: 84.29%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.24949.
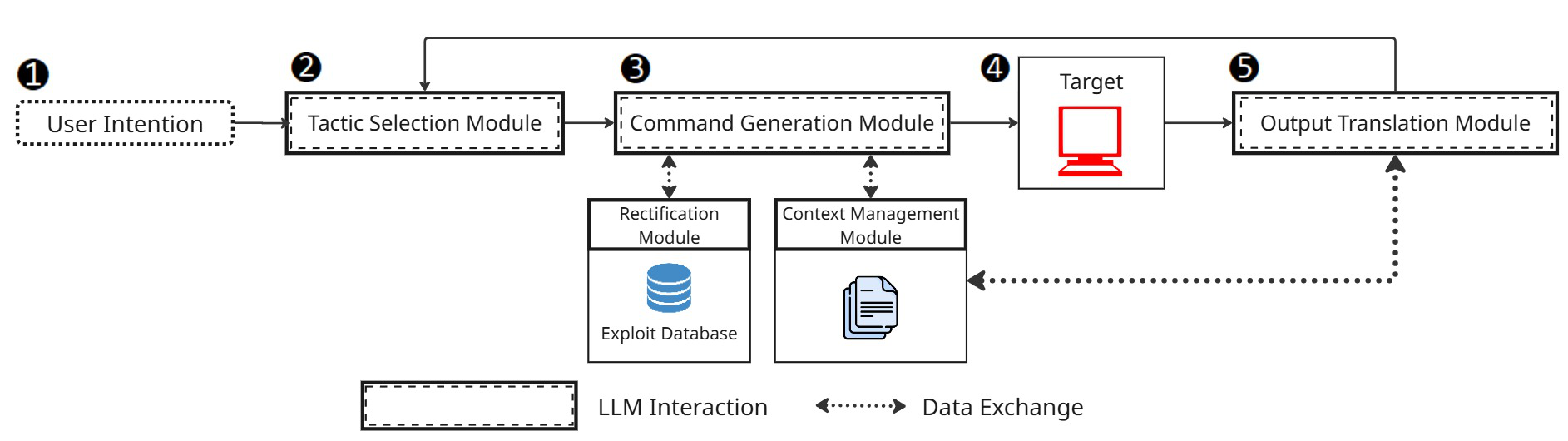
Fig 3: Overview of APT-Agent
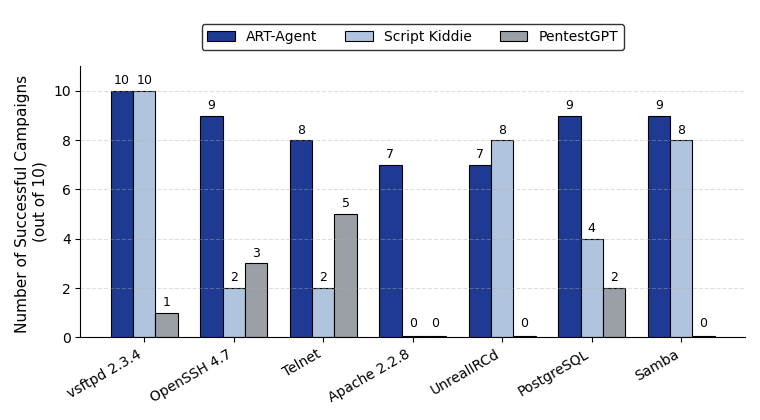
Fig 4: APT-Agent vs. Script Kiddie
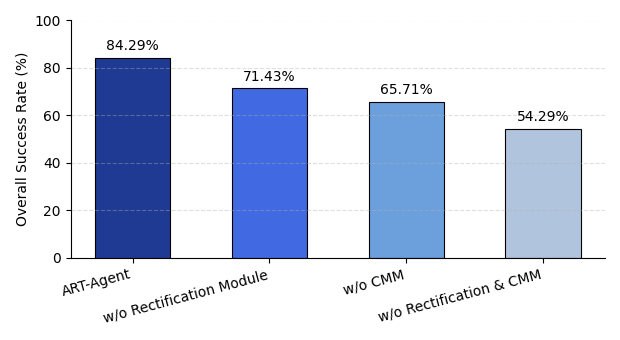
Fig 5: Ablation Study: Success Rate
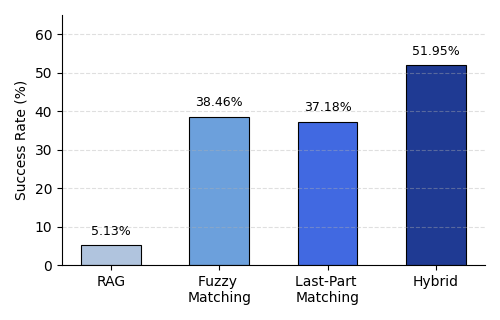
Fig 6: Rectification Methods Success Rate
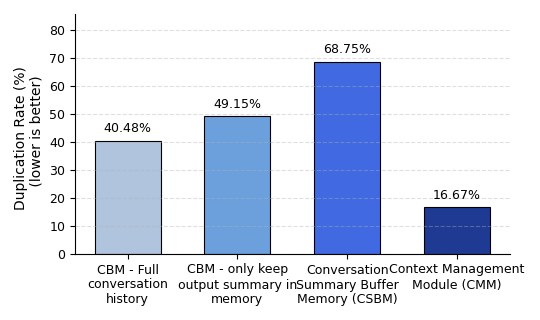
Fig 7: LLM Context Comparison: Duplication Rate
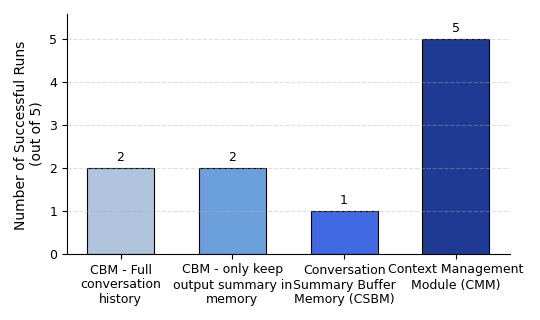
Fig 8: LLM Context Methods Comparison: Success Rate
Limitations
- System is evaluated only on the Metasploitable 2 benchmark; no assessment on more complex or real-world production environments.
- The approach relies heavily on GPT-4o, and lower-capacity LLMs like GPT-3.5-Turbo or Llama3-7B failed to achieve successful exploitations and were excluded.
- Focus is limited to three core pen-testing stages (Recon, Exploit, Exfiltrate); lateral movement, persistence, or advanced post-exploitation tactics are not yet included.
- Rectification module focuses mainly on Metasploit command hallucination; potential hallucinations in other command domains or tools are not addressed.
- No adversarial evaluation to test robustness against defenses designed to mislead or confuse LLM agents.
- Cost and latency considerations for large-scale deployment are not analyzed, especially token usage impact of context injection.
Open questions / follow-ons
- How well does the APT-Agent framework generalize to more realistic, complex, or production-scale environments beyond Metasploitable 2?
- Can the hybrid rectification approaches be extended to other penetration testing toolchains or reduce hallucinations in non-Metasploit command domains?
- How might adversarial defenses, such as honeypots or deceptive responses, affect the efficacy and robustness of LLM-driven automated penetration testing?
- What are the trade-offs in computational costs and token usage when scaling context retention methods to longer campaigns or distributed multi-agent settings?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the APT-Agent study illustrates key challenges and solutions in automated reasoning and command generation within security automation workflows. The hybrid rectification approach highlights the critical need to validate and ground LLM-generated commands against authoritative databases to reduce hallucinations that could cause unintended or failed operations. This insight is applicable when deploying LLM-driven automation in adversarial environments where exactness is crucial, such as automated CAPTCHA solvers or bot detection tool integrations. Additionally, the explicit and compact context management design in APT-Agent showcases a practical method to maintain long-term memory of past interactions without overloading prompts, which is valuable for improving decision-making continuity in multi-step bot challenges and adaptive defenses. However, security teams should note limitations, including dependence on high-capacity LLMs and challenges extending beyond controlled environments. Overall, APT-Agent contributes concrete architectural patterns and failure modes important for trustworthy and efficient LLM-driven bot defense and automated interaction systems.
Cite
@article{arxiv2605_24949,
title={ APT-Agent: Automated Penetration Testing using Large Language Models },
author={ William Guanting Li and Alsharif Abuadbba and Kristen Moore and Dan Dongseong Kim },
journal={arXiv preprint arXiv:2605.24949},
year={ 2026 },
url={https://arxiv.org/abs/2605.24949}
}