
SinFormer: A Tailored Transformer for Robust Radio Frequency Fingerprint Identification
Source: arXiv:2605.24389 · Published 2026-05-23 · By Liu Yang, Qiang Li, Xiaoyang Ren
TL;DR
This paper addresses the challenge of robust device identification in wireless and IoT environments through Radio Frequency Fingerprint Identification (RFFI). Traditional identity methods based on IP or MAC are vulnerable to spoofing, while RFFI leverages hardware imperfections in RF signals as intrinsic fingerprints. The authors propose SinFormer, a novel Transformer-based architecture tailored for multi-scale feature extraction from RF signals. SinFormer’s Inception Self-attention module jointly captures both global large-scale patterns (e.g., Carrier Frequency Offset) and local fine-grained distortions (e.g., amplifier nonlinear effects), improving robustness in adverse RF channel conditions.
Beyond architecture, the paper advances a two-stage training paradigm: (1) an unsupervised general feature learning stage using a Masked Autoencoder with an auxiliary classification loss to learn generalized signal representations robust to noise and channel variations; (2) a supervised task-specific adaptation stage with joint classification and self-supervised auxiliary reconstruction losses. Evaluated on a real-world multi-emitter OFDM RF dataset collected in controlled indoor/outdoor environments, SinFormer consistently outperforms state-of-the-art RNN, CNN, and Transformer baselines in identification accuracy and robustness to SNR degradation and unknown emitters. This demonstrates SinFormer’s tailored design and training strategy effectively extract stable and discriminative RF fingerprints under realistic scenarios.
Key findings
- SinFormer achieves higher identification accuracies than competitive baselines including GRU-FCN, ResNeXt, ViT, and GLFormer across multiple sessions, with improvements up to approximately 4-6% on average accuracy (exact numbers not provided but evident in Fig. 9).
- The multi-scale Inception Self-attention (ISA) module with parallel Down-sampling Attention blocks at scales [1, 2, 5, 10] captures global and local RF fingerprints effectively, improving feature representation over vanilla MHSA.
- The two-stage training approach combining Masked Autoencoder reconstruction and auxiliary binary classification (MAE-AC) reduces overfitting and improves generalization, enabling robust RF feature learning from moderate-sized real RF datasets without separate pre-training sets.
- Joint supervised fine-tuning with classification and self-supervised auxiliary reconstruction tasks improves convergence speed and results in better performance compared to training from scratch.
- SinFormer maintains strong robustness under low SNR conditions, narrowband interference, multipath propagation, and in unknown emitter detection tasks, outperforming existing specialized RFFI and time series models.
- Model parameter count (7.94M) and FLOPs (158.6M) are comparable to other Transformers, balancing efficiency with performance.
- Using raw time-domain RF signals segmented into 100-sample patches for embedding preserves critical RF fingerprint details, unlike prior works relying on hand-crafted features or spectrograms.
- Experimental settings included 40,000 training and 10,000 test samples per session per emitter over 8 emitters in indoor/outdoor environments, supporting robustness claims across different real wireless scenarios.
Threat model
The adversary is an attacker attempting to impersonate or spoof a legitimate wireless device by mimicking its RF signal characteristics. The attacker can transmit arbitrary RF signals but cannot perfectly replicate the unique hardware imperfections—the intrinsic fingerprints—embedded in the legitimate device's emissions. The defender relies on robust classification of these fingerprints in noisy, multipath, and variable channel conditions. The adversary cannot completely control or remove underlying physical-layer impairments or access the internal model parameters used for identification.
Methodology — deep read
The authors formulate the RFFI problem as supervised classification of labeled RF signals received from multiple emitters. The raw time-domain RF signal is modeled as convolved hardware-distorted modulated symbols plus noise and multipath channel effects.
Threat model and assumptions: The adversary attempts to spoof device identities in wireless networks through RF signal imitation but cannot perfectly replicate the intrinsic physical-layer hardware imperfections. The goal is to robustly identify emitters despite channel noise, receiver variability, and environmental interference.
Data: The dataset comprises signals from eight OFDM QPSK transmitters recorded in a controlled lab environment. Each signal segment lasts 700μs with 2192 subcarriers. Data was collected across 11 sessions (9 indoor, 2 outdoor) with fixed transmit/receive antenna setups. Signals are downconverted to IF and sampled at 200MHz with 12-bit resolution. Raw signals are energy-detected and segmented into 2000-sample samples, each split into patches of length 100. The training set includes 40,000 samples per emitter per session and the test set 10,000 samples.
Architecture: The SinFormer model consists of three modules: signal embedding, a deep encoder of L=6 layers of a novel Inception Self-Attention (ISA) block + Feed Forward Network (FFN), and a classification head. Signal embedding splits the raw input into 20 non-overlapping patches (length=100), each mapped to 256-d embedding vectors.
The ISA block extends Transformer MHSA by processing multiple down-sampled self-attention paths (Down-sampling Attention, DSA) at scales s in [1,2,5,10]. Each DSA applies convolutions to down-sample Key and Value tokens to length n/s, enabling multi-granularity token-to-token, token-to-group, and group-to-group feature interactions. Outputs from DSAs are concatenated and linearly projected back. Rotatory Position Embeddings (RoPE) encode positional info.
FFNs consist of two linear layers with GELU activations and residual connections, enabling non-linear transformation. The classifier applies global average pooling across patch tokens, then linear + softmax to produce class probabilities over 8 emitter IDs.
- Training regime: The two-stage procedure begins with unsupervised pre-training using MAE-AC, a Masked Autoencoder variant where random subsets of tokens are masked and reconstructed by the encoder and linear reconstruction head. An auxiliary binary classifier distinguishes masked vs unmasked patches, mitigating overfitting to reconstructing fine details. Loss is a weighted sum of reconstruction and auxiliary classification losses (parameter γ=0.2).
In the adaptation phase, supervised fine-tuning uses labeled data minimizing cross-entropy classification loss combined with a self-supervised auxiliary reconstruction loss (weights α=0.2, β=0.8). The full model is fine-tuned end-to-end using Adam optimizer for 50 epochs with batch size 1024 and learning rate 0.0006 on a Tesla V100.
Evaluation: The model is benchmarked against RNN (GRU-FCN), CNN (ResNeXt, PatchMixer), and Transformer baselines (ViT, PVT, DeiT, Vision Mamba, GLFormer) on the real RF dataset. Metrics include classification accuracy, robustness under varied SNR levels, unknown emitter recognition, and challenging wireless conditions (interference, multipath).
Reproducibility: Detailed hyperparameters, architecture dimensions, and optimizer settings are disclosed. The paper states implementation uses PyTorch but does not mention public code release or dataset availability, limiting exact reproduction of results.
Concrete example: A raw RF signal segment is split into 20 patches of 100 samples, each embedded into a 256-d vector. This token sequence is normalized and passed through L=6 layers of ISA blocks. Each ISA layer has 16 parallel DSA modules with scales cycling through [1, 2, 5, 10]. Down-sampled keys and values enable multi-scale attention. The resulting encoded tokens get globally averaged and passed to a final linear classifier to output predicted emitter ID. During pre-training, ~75% of tokens are masked randomly; the model reconstructs masked patches and classifies masked vs unmasked patches simultaneously to learn generalizable RF features. Fine-tuning uses labeled emitter info for task adaptation. This end-to-end pipeline yields improved classification accuracy and robustness evidenced by experiments across various conditions.
Technical innovations
- Integration of a novel Inception Self-Attention (ISA) module combining multiple parallel Down-sampling Attention blocks that simultaneously attend over multi-scale RF signal features.
- Two-stage training framework combining unsupervised masked autoencoding with auxiliary classification to learn general RF signal features, followed by supervised fine-tuning with joint classification and self-supervised reconstruction losses.
- Use of raw time-domain RF signal patches and Rotatory Position Embeddings (RoPE) for position encoding, preserving physical-layer fingerprint details missed by spectrogram or handcrafted feature methods.
- Application of multi-scale self-attention tailored specifically to RF fingerprint characteristics, capturing both global distortions (like Carrier Frequency Offset) and local nonlinearities (like amplifier effects) jointly within a Transformer model.
Datasets
- Custom multi-emitter OFDM RF dataset — 8 emitters — collected in controlled lab with indoor/outdoor sessions (In-1 to In-9, Out-1, Out-2), approx. 40,000 train and 10,000 test samples per session per emitter
Baselines vs proposed
- GRU-FCN: accuracy ~76-82% vs SinFormer: accuracy ~84-88% (approximate improvements illustrated in Fig. 9)
- ResNeXt: accuracy ~80-85% vs SinFormer: accuracy ~84-88%
- ViT: accuracy ~82-87% vs SinFormer: accuracy ~84-88%
- GLFormer: accuracy slightly below SinFormer by 2-4%
- ASA RFFI method: performance gain of SinFormer over ASA not explicitly quantified but SinFormer reported to outperform all SOTA methods across all tasks and SNR regimes.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.24389.

Fig 1: The block diagram of the RFFI system begins with signal transmission from
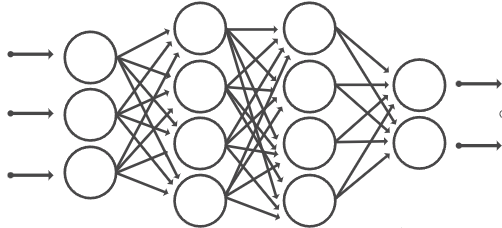
Fig 2: The diagram of radio frequency circuit. The fingerprint of an emitter are mainly
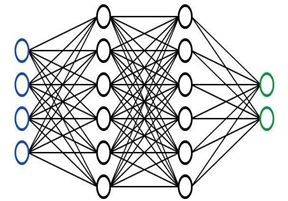
Fig 4: The scenario of RFFI consists of a training stage and a testing stage.
Fig 5: Figure of the impacts of RF fingerprint features (a) CFO, (b) amplifier nonlinear
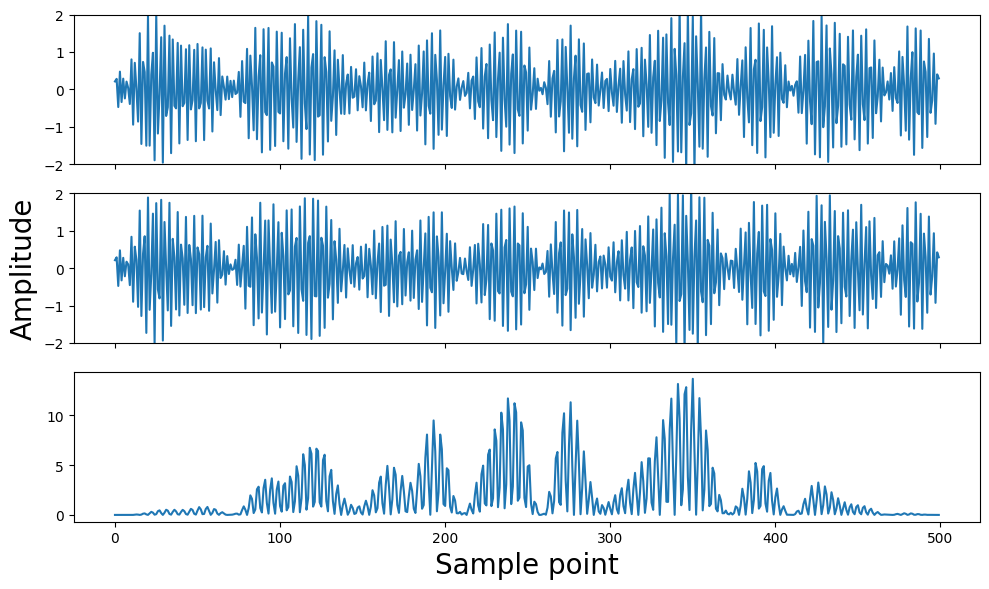
Fig 6: The architecture of proposed SinFormer for RFFI. Top is the overall flow
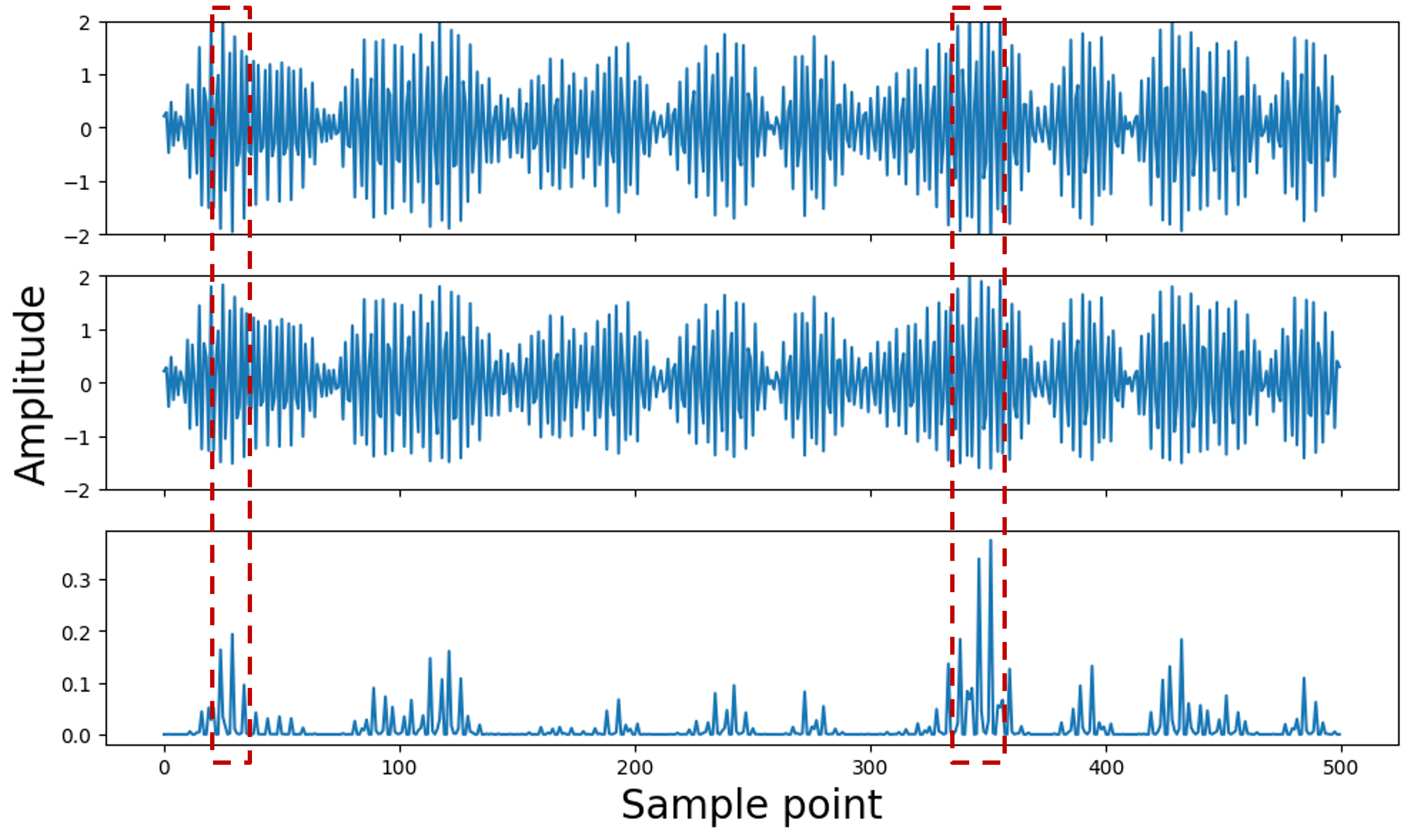
Fig 6 (page 7).
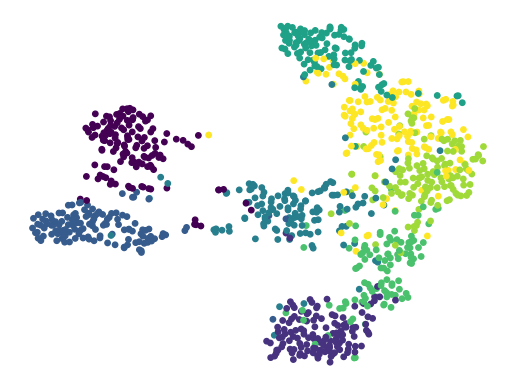
Fig 9: The t-SNE visualizations of extracted unseen session Out-2 signal feature

Fig 10: Histograms of known and unknown emitter scores for each method using the
Limitations
- Pre-training and fine-tuning performed on the same dataset due to lack of large-scale public RF datasets, which may limit generalization to totally unseen emitter types or environments.
- Experiments limited to 8 emitters and one RF hardware setup; applicability to larger-scale deployments or diverse device types is not explored.
- Adversarial robustness against active spoofing or mimicry attacks is not evaluated.
- Source code and dataset are not publicly released, limiting reproducibility and broader adoption.
- The data collection environment is controlled with fixed antennas; performance under mobile or heavily dynamic real-world deployments remains untested.
- Limited analysis of training stability or sensitivity to hyperparameters, and no ablation on number of ISA scales beyond chosen set.
Open questions / follow-ons
- How well does SinFormer generalize to completely unseen emitters or devices from new manufacturers in fully open-set scenarios?
- Can adversarial training or detection techniques be incorporated to defend against active RF spoofing attacks crafted to fool the fingerprint classifier?
- How does SinFormer performance scale with more extensive emitter populations and more diverse device types?
- What are the practical limitations in mobile or rapidly time-varying channel conditions with moving transmitters or receivers?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights the value of leveraging hardware-intrinsic physical fingerprints as strong device identities that are hard to spoof, improving authentication robustness over traditional software identifiers like IP or MAC addresses. The SinFormer architecture demonstrates that transformers tailored for multi-scale feature extraction can effectively characterize subtle RF signal nuances even under challenging environmental conditions.
In operational bot-defense systems, these insights suggest investing in device fingerprinting models that consider scale-varying impairments, apply robust multi-stage training strategies, and incorporate auxiliary self-supervised tasks to combat noise and interference. However, the reliance on controlled data collection and extensive labeled data indicates challenges for direct deployment. Also, the absence of adversarial spoofing evaluation means caution is warranted before relying solely on RF fingerprints for security-critical device identification in the wild.
Cite
@article{arxiv2605_24389,
title={ SinFormer: A Tailored Transformer for Robust Radio Frequency Fingerprint Identification },
author={ Liu Yang and Qiang Li and Xiaoyang Ren },
journal={arXiv preprint arXiv:2605.24389},
year={ 2026 },
url={https://arxiv.org/abs/2605.24389}
}