
VISTA: An End-to-End Benchmark for Visual Spec-to-Web-App Coding Agents
Source: arXiv:2605.26144 · Published 2026-05-22 · By JunJia Guo, Yuhang Yao, Jiawei, Zhou, Jingdi Chen
TL;DR
The VISTA benchmark addresses the gap in evaluating large language model (LLM)-based coding agents on realistic, end-to-end web application development tasks. Unlike prior benchmarks focused on algorithmic code generation, VISTA targets UI-centric app synthesis from underspecified inputs, requiring agents to generate functional, visually coherent, multi-page web apps with interactive behavior. It introduces five prompt conditions varying in visual/structural fidelity and tech stack constraint, enabling granular analysis of how input modality and implementation freedom impact agent performance. VISTA includes manually annotated ground truth for interactive components and visual anchors, combined with a rigorous evaluation combining DOM-grounded structural matching, behavior-specific tests, and CLIP-based visual similarity to comprehensively measure UI correctness, functionality, and visual fidelity.
Evaluations across four state-of-the-art agents from two LLM families and harnesses reveal that visual fidelity and behavioral correctness only partially correlate, and agent editing styles vary widely but are largely orthogonal to task success. Free stack conditions consistently yield the best combined performance scores, and incorporation of structural design inputs improves localization but not always overall task quality. VISTA thus establishes a reproducible and nuanced evaluation framework that bridges visual design-to-code accuracy with functional UI behavior, providing a realistic benchmark for advancing LLM agent-driven front-end development workflows.
Key findings
- Adding reference screenshots increased localization score by +18% relative (C0: 0.489 to C1: 0.577) but slightly decreased combined structure-function score (0.242 to 0.229) due to fixed stack constraints limiting behavior correctness.
- Removing stack constraints with the same visual inputs improved combined scores significantly (C1 to C2: 0.229 to 0.264), the largest single gain observed.
- Adding pruned Figma structure pushes localization to the highest values (C3=0.615, C4=0.600) but combined task success is lower under fixed stacks (C3: 0.236 < C2: 0.264), showing structural input aids grounding but requires implementation flexibility for behavior.
- Across agents, GPT-5.5 had the highest localization (0.602) and CLIP visual similarity (0.853) but lowest behavior score (0.283), indicating visual fidelity does not guarantee functional correctness.
- Opus achieved the best behavior (0.336), combined success (0.261), and combined median (0.250) but had lower CLIP score (0.764), demonstrating a divergence between functional accuracy and visual appearance.
- The Surgical Diff Score exposed contrasting editing styles: Opus rewrote almost entirely (rewrite share 0.988) yielding better scores, while GPT-5.5 made more localized edits but scored lower (ρ between Diff Score and Combined = -0.145).
- All agents follow a macro workflow pattern: inspecting early, writing in the middle, and verifying at the end, but differ in failure recovery strategies.
- CLIP similarity correlates more with visual input richness (highest in C4: 0.827) rather than functional correctness.
Threat model
Not applicable; the study does not explicitly consider adversarial threats but rather evaluates benign coding agents generating UI code from underspecified specs under varied input conditions.
Methodology — deep read
Threat Model & Assumptions: VISTA targets coding agents (LLM-based) generating web applications from underspecified natural language and visual design inputs under various stack constraints. The adversary in this context is effectively the benchmark evaluating agent outputs; no explicit adversarial threat is modeled. Agents lack prior exposure to the benchmark's exact pages but rely on general LLM knowledge.
Data: The benchmark comprises 10 application categories (newsletter, real estate, job board, forum, travel booking, chat, cloud storage, e-commerce, project management, music streaming) with 128 pages total. Each page includes rendered PNG screenshots and pruned JSON extracted from Figma design files. The data is human annotated with 3,253 interactive UI elements and 458 visual anchors to enable precise evaluation. Template scaffolds derive from create-next-app with three LLM-suggested tech stacks per task.
Architecture/Algorithm: The evaluation pipeline combines three complementary components: (a) a DOM-grounded evaluator that aligns human-annotated component locations to rendered app DOM elements and verifies component presence and behavior correctness via interaction-specific browser tests; (b) a CLIP-based visual similarity metric comparing rendered screenshots with ground truth to measure design fidelity tolerant of minor pixel differences; and (c) Surgical Diff Score to quantify editing style by classifying file mutations into rewrites, edits, and deletions, weighted by changed bytes and file size to assess targetedness of edits.
Training Regime: Not applicable as VISTA is a benchmark and evaluation framework rather than a trained model. The evaluated agents include GPT-5.4, GPT-5.5, Claude Sonnet, and Claude Opus, each paired with specific harnesses for interaction.
Evaluation Protocol: Each task runs under five prompt conditions varying in information and stack constraints: C0 (text only, free stack), C1 (text + screenshot, 3 fixed stacks), C2 (text + screenshot, free stack), C3 (text + screenshot + Figma, single fixed stack), C4 (text + screenshot + Figma, free stack). Metrics reported are (i) localization accuracy (Li), (ii) behavior correctness (Bi), combined as S = mean(Li * Bi), and (iii) CLIP visual similarity score. Baselines consist of agent family pairs and condition ablations, with results averaged and median values reported. Trajectories of agent actions are analyzed for workflow patterns. Statistical tests are not explicitly mentioned.
Reproducibility: The dataset is based on Figma exports with manual annotation details publicly described. It is unclear if code, evaluation scripts, or trained agent weights are released. The benchmark is designed for reproducible evaluation of agent-harness systems under controlled input conditions.
Example: For a travel booking app under condition C2, an agent receives natural language specification plus a screenshot with free choice of stack. The agent uses its harness to generate multi-page UI code, incorporating interactive components. The app is deployed and rendered. The DOM-grounded evaluator aligns annotated interactive elements (e.g., booking buttons, date selectors) to DOM nodes, verifying presence and expected behaviors (e.g., navigation). Visual fidelity is measured by comparing app screenshots to Figma ground truth via CLIP. Editing logs yield Surgical Diff Score showing whether agent edits are surgical or rewrite-heavy. Metrics are reported and compared to agent variants and other conditions.
Technical innovations
- A combined multi-axis benchmarking framework varying both visual/structural fidelity and tech stack constraints to isolate sources of failure in LLM-based web app generation.
- Manual human annotation of interactive UI elements and visual anchors at fine granularity to enable DOM-grounded alignment and behavior-specific evaluations beyond brittle script-based testing.
- A DOM-grounded interaction evaluator that aligns reference mockup coordinates to rendered app DOM elements and performs behavior-specific browser tests for precise end-to-end functional correctness scoring.
- Integration of CLIP-based visual similarity as a complementary metric measuring high-level design fidelity resistant to small pixel-level rendering differences.
- Definition and application of the Surgical Diff Score to objectively measure agent editing style by quantifying the ratio of localized edits versus full-file rewrites, enabling insight into agent workflows.
Datasets
- VISTA benchmark — 128 pages, 3,253 interactive annotations, 458 visual anchors — Collected from human-annotated Figma exports across 10 application categories
Baselines vs proposed
- C0 (text only, free stack): Combined score = 0.242 vs C2 (text + screenshot, free stack): Combined = 0.264 (+9% relative improvement)
- C1 (text + screenshot, fixed stack): Combined = 0.229 vs C0: 0.242 (performance drop due to fixed stacks despite added visual input)
- C3 (text + screenshot + Figma, fixed stack): Combined = 0.236 vs C4 (same but free stack): Combined = 0.261 (+10.6% relative increase)
- Agent GPT-5.4: Combined = 0.251 vs Opus: Combined = 0.261 (best agent score)
- Agent GPT-5.5 localization = 0.602 and CLIP = 0.853 but behavior = 0.283 (lowest functional correctness among agents)
- Agent Opus behavior = 0.336 and Combined = 0.261 exceeding GPT variants despite lower visual similarity (CLIP = 0.764)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.26144.
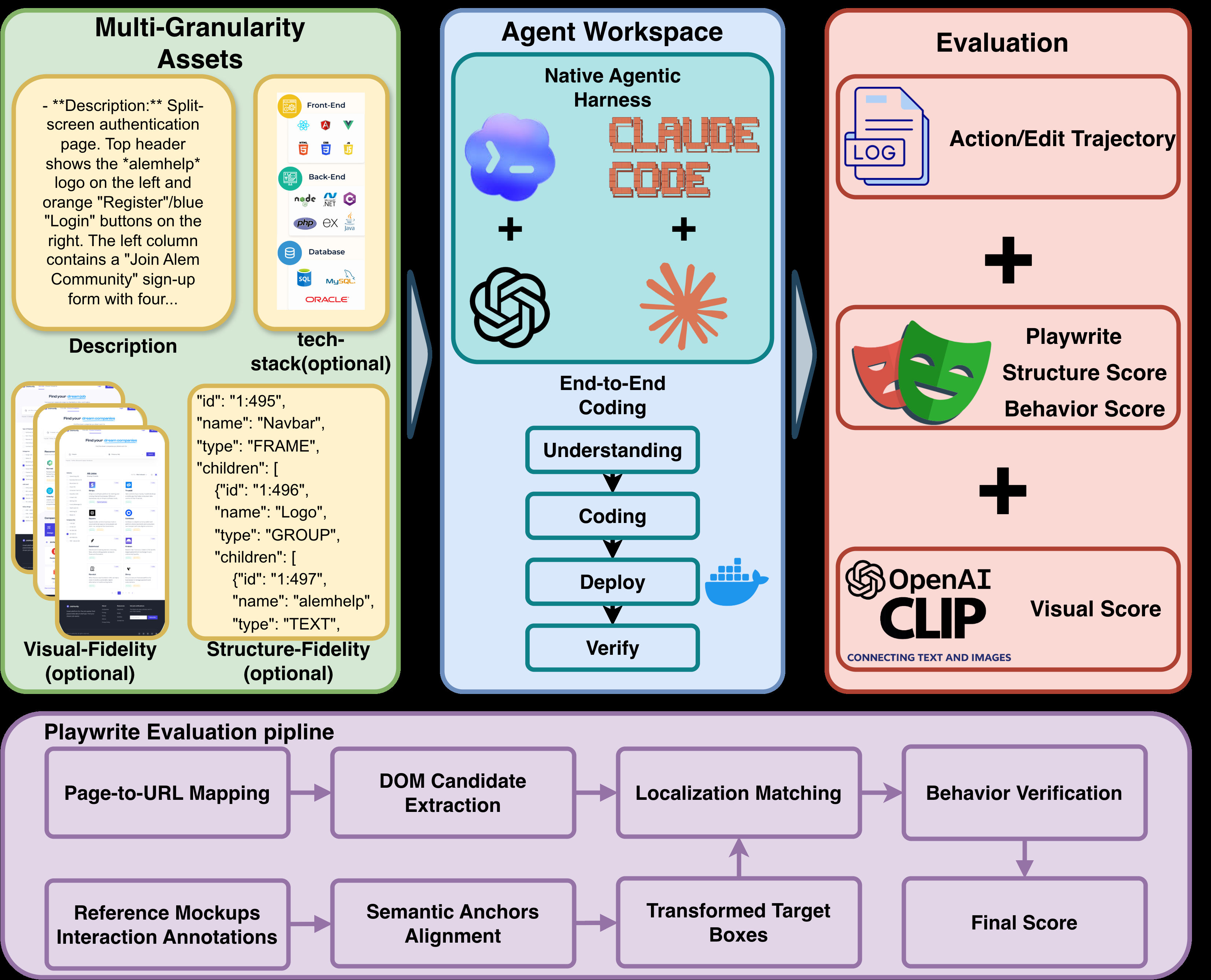
Fig 1: Pipeline of the DOM-grounded interaction evaluator. Human-annotated mockup targets are
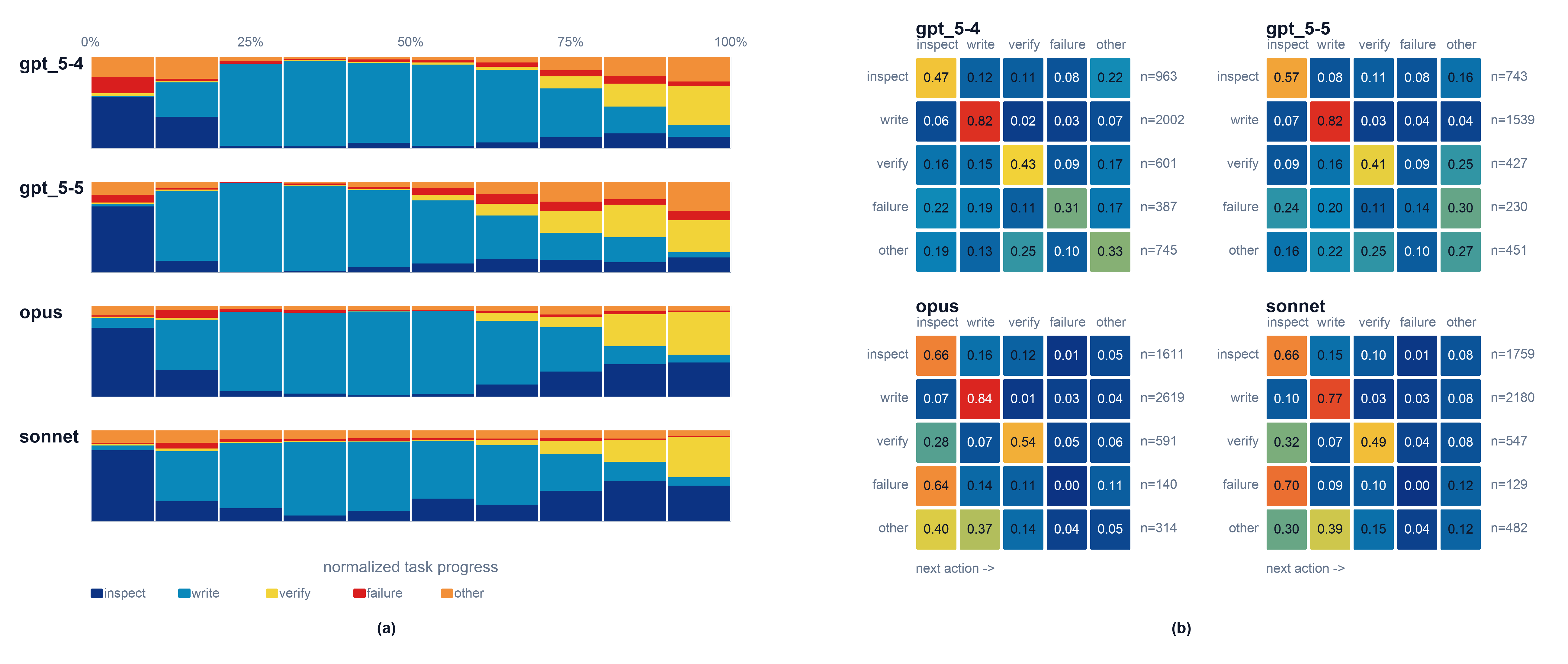
Fig 2: Overview of model workflow trajectories. The left panel shows the action mix over
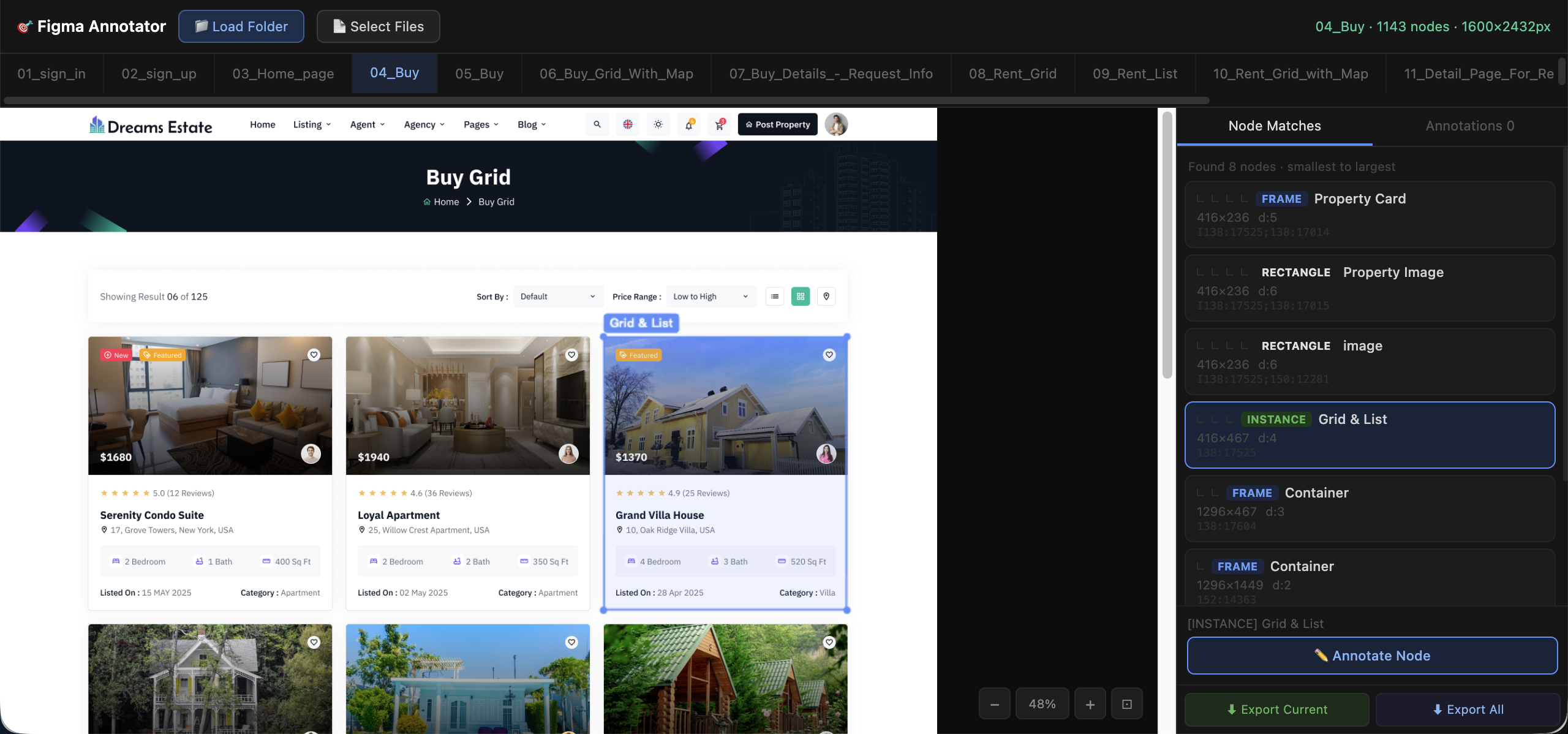
Fig 3: Annotation interface used to inspect Figma-derived pages, match candidate nodes, and
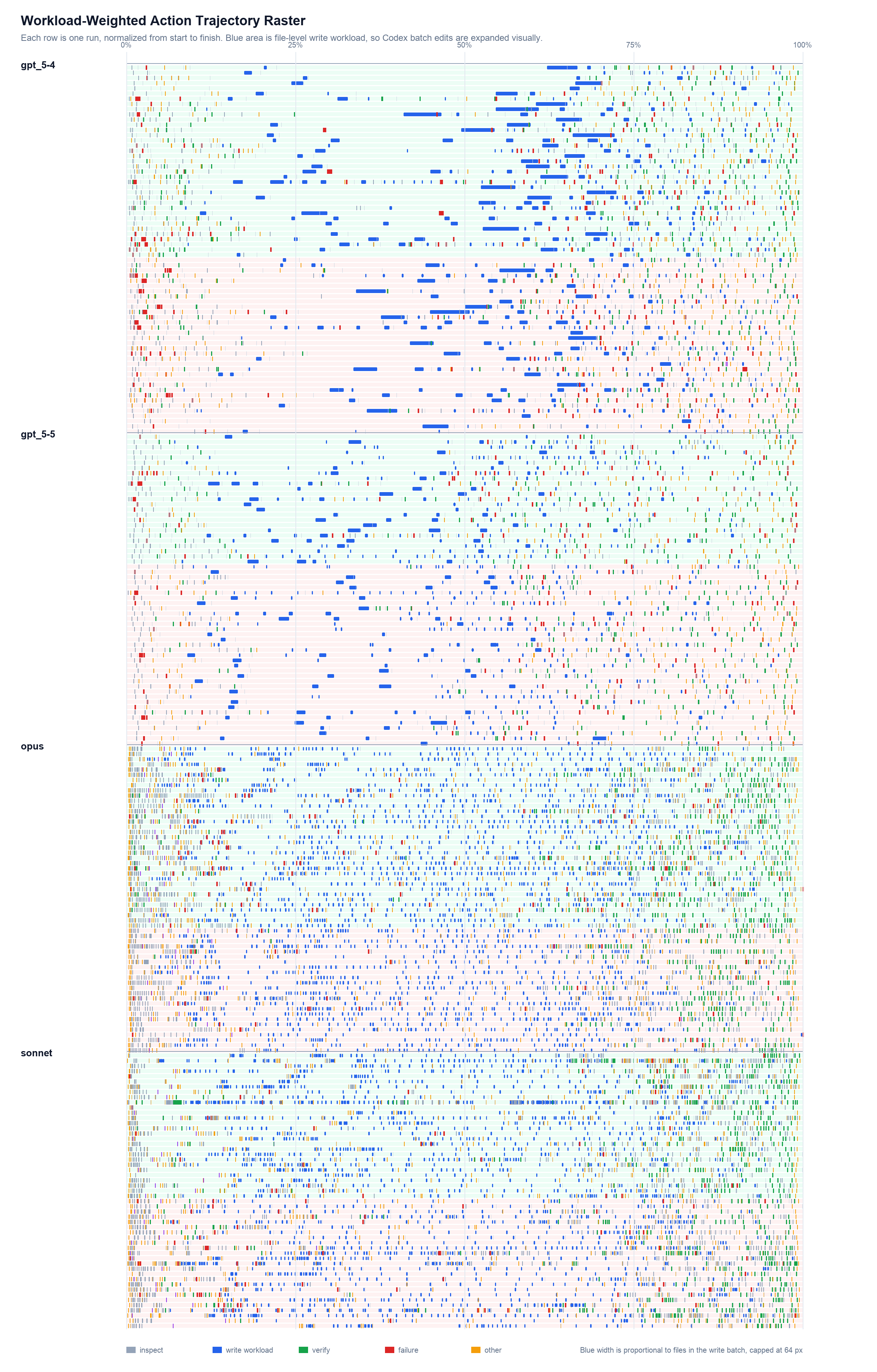
Fig 4: Workload-weighted action trajectory raster. Each row is one run, with the horizontal axis
Limitations
- Benchmark covers only 10 application categories and 128 pages, omitting complex real-world web app phenomena like real-time multiuser state or deep native integrations.
- Tech stacks per task are proposed by an LLM not human experts, introducing potential bias toward LLM-favored frameworks and affecting absolute performance interpretation under fixed stacks.
- DOM-grounded evaluation assumes affine layout alignment and may degrade with non-affine transforms, scroll-bound, or custom controls, leading to partial fallback credits rather than absolute correctness guarantees.
- CLIP visual similarity measures high-level image resemblance but cannot verify exact pixel-perfect design fidelity or accessibility compliance.
- The Surgical Diff Score is harness-dependent, influenced by model–harness interface design rather than purely model behavior, limiting cross-agent fairness comparisons.
- Potential training data contamination is acknowledged: although public HTML/CSS code is excluded, models likely have seen many similar UI patterns, complicating claims of zero-shot performance.
Open questions / follow-ons
- How would agent performance and editing style evolve when integrating real-time feedback or live execution environments beyond static multi-page apps?
- Can incorporating richer structural and interactive design metadata beyond pruned Figma JSON further improve functional correctness without sacrificing implementation flexibility?
- What is the impact of human-in-the-loop or interactive refinement workflows in improving agent code quality and personalization in design-to-code tasks?
- How generalizable are the observed agent behaviors and editing patterns across other code generation domains beyond web front-end development?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, VISTA provides an important example of evaluating AI agents in generating complex, interactive front-end code conditioned on underspecified specifications. The benchmark’s multidimensional evaluation combining functional correctness, visual fidelity, and editing style insights demonstrates how agents can produce superficially plausible but functionally incorrect UI behavior—an important consideration when designing adversarial detection or robustness metrics for systems generating user-facing code. Moreover, the use of human-annotated interactive components and visual anchors suggests a promising approach to create more resilient evaluation tools beyond brittle end-to-end scripts. Finally, the observed partial decoupling of visual fidelity from behavioral correctness highlights that visual assessments alone are insufficient to guarantee security or usability properties, a lesson applicable in defenses against visual spoofing or automated form generation bots.
Cite
@article{arxiv2605_26144,
title={ VISTA: An End-to-End Benchmark for Visual Spec-to-Web-App Coding Agents },
author={ JunJia Guo and Yuhang Yao and Jiawei and Zhou and Jingdi Chen },
journal={arXiv preprint arXiv:2605.26144},
year={ 2026 },
url={https://arxiv.org/abs/2605.26144}
}