
Synthetic Sources?: Auditing Generative Search Engine Citations for Evidence of AI-Generated Sources
Source: arXiv:2605.23684 · Published 2026-05-22 · By Mowafak Allaham, Nicholas Diakopoulos
TL;DR
This paper investigates the prevalence of AI-generated source content cited by prominent generative search engines (GSEs) such as ChatGPT, Copilot, Gemini, and Perplexity. As these engines synthesize answers with citations to web sources, understanding whether cited content is human-authored or AI-generated is critical, especially for topics of public importance like politics, health, and the environment. Through an audit of 712 real-world, human-generated queries covering these domains, the authors collected and analyzed 26,266 unique cited URLs across the four GSEs. They scraped available source content from 19,154 URLs and used state-of-the-art AI-detection tools to identify synthetic text. The key finding is that approximately 16% of cited sources across all engines contain AI-generated content, with the highest prevalence in environment-related queries.
Beyond quantifying the proportion of AI-generated citations, the study also mapped the distribution of source web domains, finding a mixture of a limited set of frequently cited domains alongside many minimally cited ones. The results highlight that despite the promise of GSEs to provide authoritative information, they currently integrate a significant amount of potentially lower-quality AI-generated source content. This raises concerns about the reliability of their synthesized answers and the risks to users, particularly for critical topics. The findings underscore the need for improved governance, transparency, and source quality controls in generative search engines.
Key findings
- Across four generative search engines (ChatGPT, Copilot, Gemini, Perplexity), ~16% of all unique cited sources contain AI-generated content.
- Environment-related queries exhibited the highest proportion of AI-generated cited source content (~16% overall, highest among all topics).
- The final audited dataset included 712 queries spanning politics (N=175), health (N=257), and environment (N=280).
- The paper scraped content from 19,154 of 26,266 unique cited URLs (72.9%), limited by inaccessible or non-text formats.
- AI-detection tool Pangram was selected for final analysis due to its low false positive rate (~1 in 10,000) in benchmark testing.
- Frequent citation domain analysis revealed generative search engines rely disproportionately on a narrow set of domains for sourcing information.
- The study found many cited domains are minimally cited, creating a dual distribution of frequent and rare source domains.
- Evaluation of Pangram and GPTZero on a 105-article benchmark of AI-generated news showed 55.2% detected by Pangram as Highly Likely AI, confirming detection challenges.
Threat model
The adversary in this work is the ecosystem of AI-generated web content that may be inadvertently or intentionally included as sources by generative search engines. This includes malicious actors or content creators who engineer low-quality or misleading AI-generated content to manipulate information synthesis by GSEs. The generative search engines themselves are treated as black boxes auditing their citation outputs. The adversary is capable of seeding AI-generated sources on the web but cannot directly alter the GSE internal source selection mechanisms examined in this audit.
Methodology — deep read
The study followed a multi-step approach to audit the citations of four generative search engines (GSEs).
Threat Model & Assumptions: The adversary is effectively the underlying web content ecosystem generating AI-generated (synthetic) sources. The focus is on whether GSEs cite these synthetic sources unknowingly. Attackers injecting AI-generated low-quality content could degrade GSE output quality. The authors assume that neither the GSEs' internal mechanics nor the scraped datasets are adversarially manipulated during the study.
Data: The authors curated 712 English-language queries from two datasets: the Search Arena dataset (user queries from multi-language generative search engine interactions) and Climate Q&A dataset (focused environment queries). Queries were manually filtered for relevance to U.S. contexts and to the topics of politics (N=175), health (N=257), and environment (N=280). Each query was submitted to each of ChatGPT (web search enabled), Copilot, Gemini, and Perplexity interfaces, and the resulting responses with citations were scraped.
Citation Extraction: Using Playwright-powered web scraping to simulate user queries on each GSE, the authors collected the sources cited within the generated answers including URL, source snippet, and title. This yielded 26,266 unique URLs linking to 7,675 unique web domains.
Content Scraping & Preprocessing: The main body text of each source URL was extracted with the newspaper3k library. Content extraction succeeded for 19,154 URLs (72.9%), limited by file formats like PDFs and inaccessible or removed pages.
AI Detection Models Evaluation: Two detection tools, Pangram (a transformer-based classifier trained on human and AI-generated corpora) and GPTZero (hierarchical classifier), were compared on benchmark datasets of human and AI texts and on a 105-article “AI slop” news media benchmark. Both tools showed strong accuracy on curated datasets but variable detection rates on real-world news articles. Pangram was chosen for final analysis due to the lowest false positive rate to avoid overestimating AI-generated content prevalence.
Classification of Sources: Scraped source texts were classified into: Highly Likely AI, Unlikely AI (human), or Mixed categories by Pangram, with Mixed merged cautiously into AI if confidence thresholds were exceeded.
Analysis: The authors tabulated frequency and proportion of AI-generated sources cited across GSEs and topics, profiled distribution of citation frequency per domain, and mapped domain overlap among engines.
Limitations: Authors note potential underestimation due to missed sources (non-text formats, inaccessible URLs), limitations caused by single-turn query evaluation rather than multi-turn context, and potential inaccuracies in AI-detector performance.
Concrete Example: For a given query about climate change, the authors submitted it to each GSE, scraped the list of cited URLs presented to the user, then retrieved the source webpage content where possible. This content was fed to Pangram for AI-generated text classification. The proportion of synthetic content cited for this query was computed and aggregated across all environment-related queries to determine topic-level prevalence.
Code and scraped data are not publicly released, which limits reproducibility. Exact hyperparameters for AI detection models were not disclosed beyond citing Pangram’s original release. The scraping was performed via UI automation to capture user-facing citations rather than API results, reflecting real-world user experience.
Technical innovations
- Systematic auditing of cited sources in generative search engines to detect AI-generated content using large-scale real-world queries across public interest topics.
- Leveraging Pangram, a transformer-based AI-text detection tool, to classify the cited source content from scraped URLs for AI-generation likelihood.
- Developing a scraping pipeline emulating user interaction with four GSE UIs to collect citations exactly as users see them, addressing discrepancy between API and UI responses.
- Mapping citation frequency distributions across 7,675 unique web domains to reveal disproportionate sourcing patterns in generative search engines.
Datasets
- Search Arena dataset — 11,185 English queries (filtered down to 432 politics and health queries) — public but not fully open
- Climate Q&A dataset — 3,425 queries (subsampled to 280 environment queries) — from prior academic study
- Curated benchmark of 200 human-authored and 200 AI-generated texts (for AI-detector assessment) — not publicly available
- 105-article AI-generated news media benchmark — sampled from journalistic reports of known AI-generated content
Baselines vs proposed
- Pangram AI detection tool: false positive rate ~1 in 10,000 on curated texts vs GPTZero false positive rate not numerically specified but higher.
- On the 105-article benchmark, Pangram classified 55.2% as Highly Likely AI vs GPTZero classified 64.7% as AI-generated, indicating differing detection thresholds but Pangram prioritized low false positives.
- Overall AI-generated source prevalence by Pangram: ~16% of cited sources across all four GSEs.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.23684.
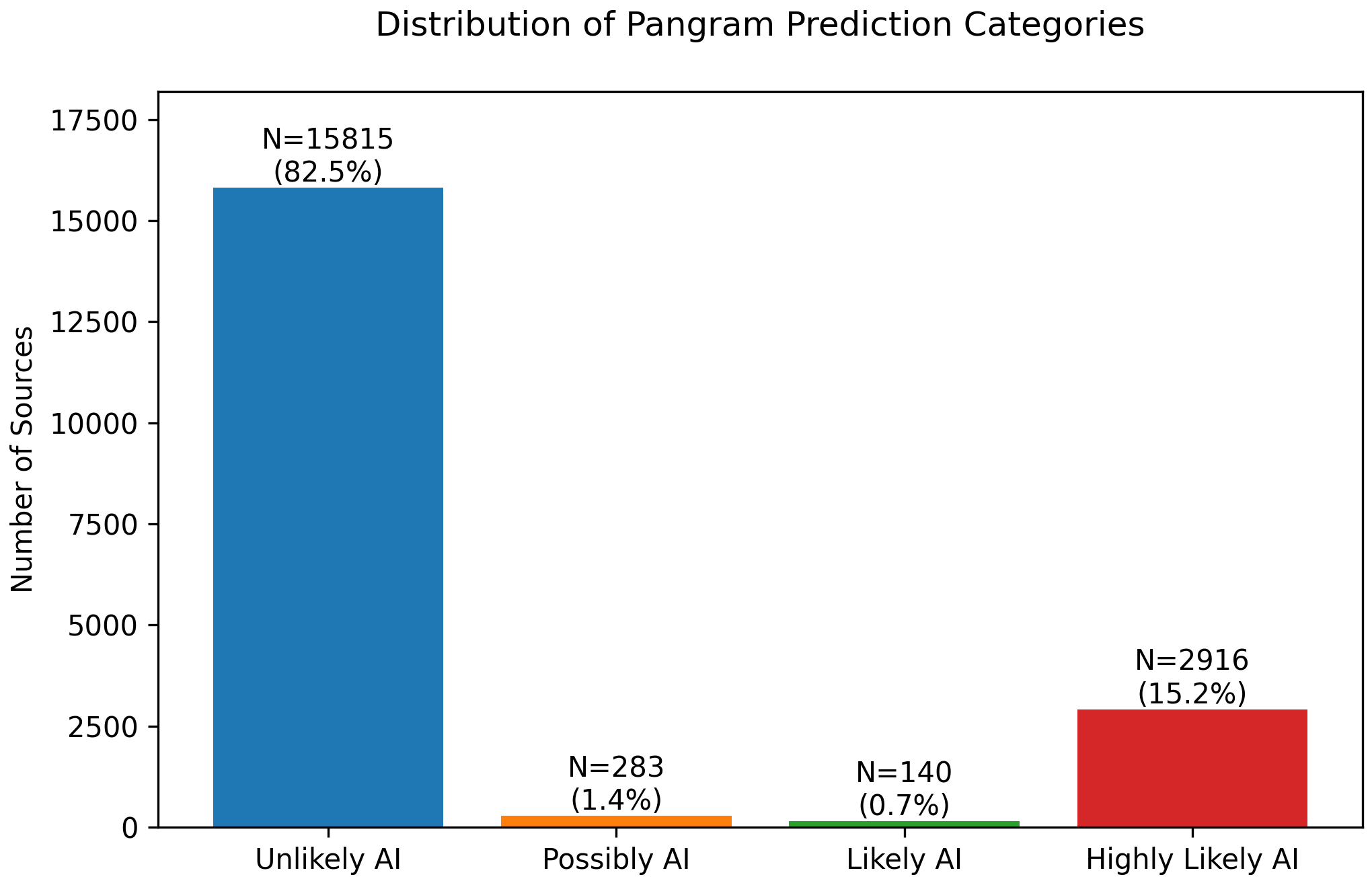
Fig 1: Distribution of Pangram prediction categories.
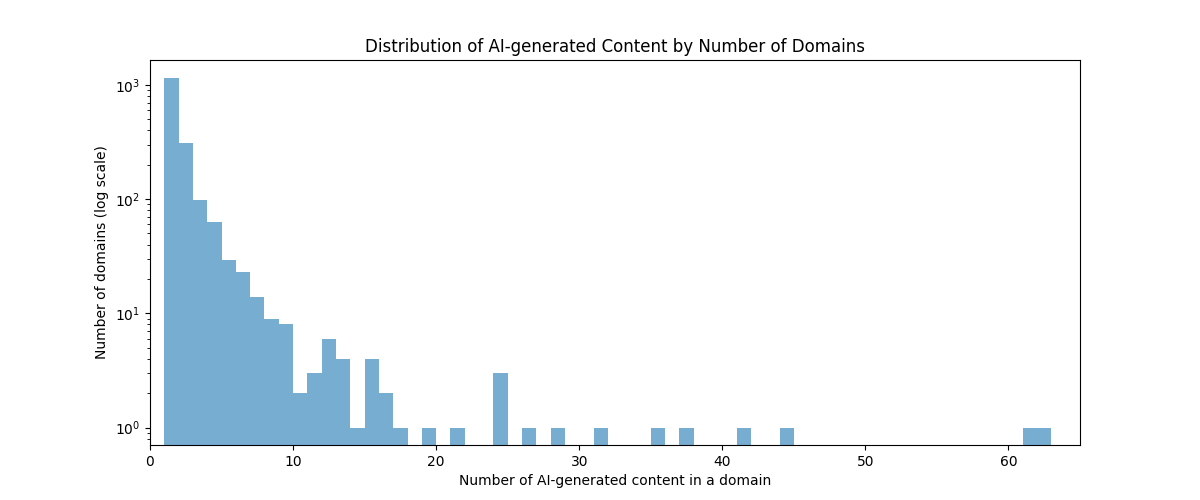
Fig 2: Distribution of AI-generated sources by number of source web domains.
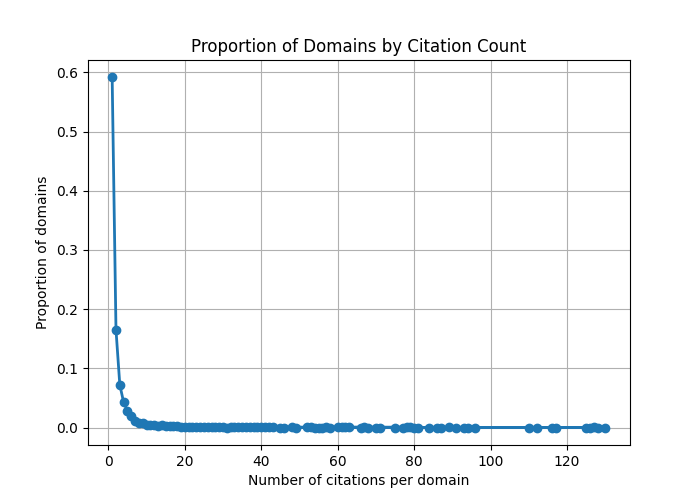
Fig 3: Concentration and distribution of citations across source web domains. Figure 1(a) illustrates the high proportion
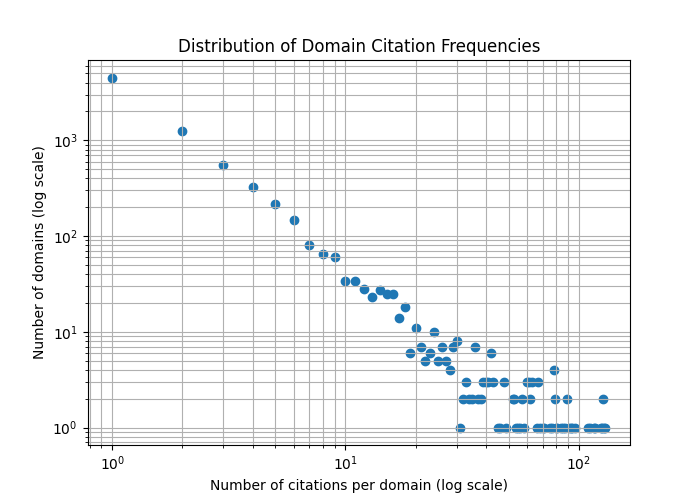
Fig 4: Prompt template used for to generate text across the categories of “research abstract”, “wiki page”, “reddit post”,
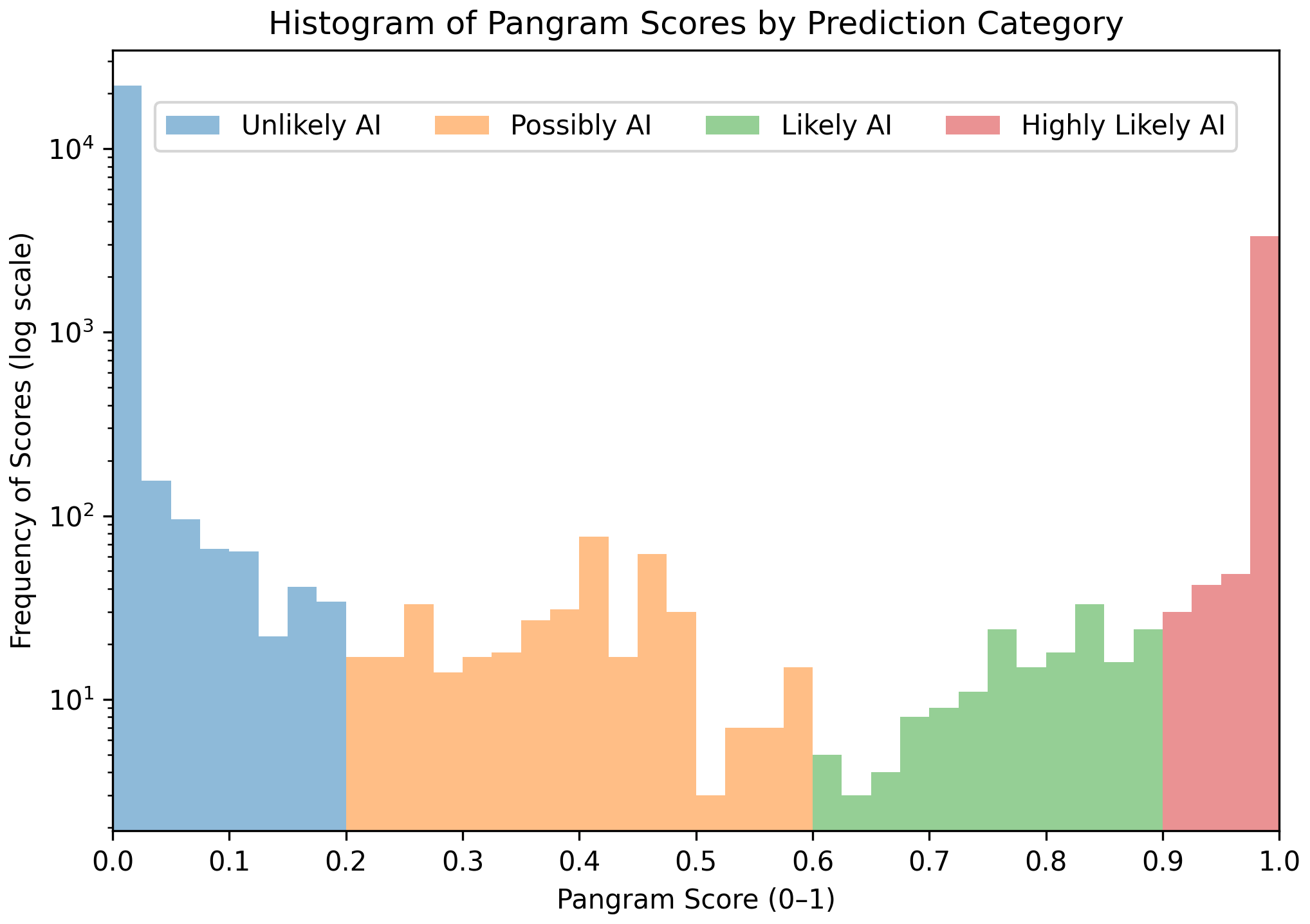
Fig 5: Distribution of Pangram prediction categories.
Limitations
- Content scraping successful for only 72.9% of URLs; missing pages (e.g., PDFs, images) lead to incomplete coverage and potential underestimation of AI-content prevalence.
- Study focused on single-turn queries rather than multi-turn conversational context, limiting understanding of source citation dynamics in ongoing interactions.
- Reliance on AI-detection tools which, despite evaluation, possess inherent false negatives and false positives; results interpreted as a conservative lower bound.
- Data and code not publicly released, limiting exact reproducibility of experiments and further external validation.
- Regional focus on U.S.-relevant queries excludes potentially different patterns in other linguistic or geopolitical contexts.
- Scraping methodology limited to visible citations; some GSEs may omit or hide sources impacting completeness.
Open questions / follow-ons
- How can generative search engines integrate AI-detection mechanisms in real-time to filter out or flag AI-generated source content during response generation?
- What is the impact of multi-turn conversational context on the prevalence and persistence of AI-generated sources cited by GSEs?
- How generalizable are these findings across non-English languages, different geographic regions, or domains beyond politics, health, and environment?
- Can advances in AI detection reduce false negatives sufficiently to provide more accurate estimates of AI-generated content prevalence in real-time?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this study highlights an emerging vector of information manipulation within AI-driven information retrieval systems. As generative search engines increasingly synthesize web knowledge with citations, the mixing of human-authored and AI-generated source content—with the latter potentially containing hallucinations or misinformation—poses novel challenges for ensuring truthful and reliable bot responses. CAPTCHA or bot-detection systems that rely on modeling user search behavior or content verification could be impacted by the variability and opacity of source provenance in GSE responses. Further, awareness that approximately one-sixth of cited sources may be AI-generated underscores the need for developing robust detection and validation techniques to contextualize AI responses, preventing bots or users from exploiting synthetic citations to propagate misinformation. Incorporating AI-generated source detection could be a layer complementary to existing behavioral or technical CAPTCHA defenses in information-seeking applications.
Cite
@article{arxiv2605_23684,
title={ Synthetic Sources?: Auditing Generative Search Engine Citations for Evidence of AI-Generated Sources },
author={ Mowafak Allaham and Nicholas Diakopoulos },
journal={arXiv preprint arXiv:2605.23684},
year={ 2026 },
url={https://arxiv.org/abs/2605.23684}
}