
Humans Cannot Detect AI-Generated Media But Communities May -- For Now: Collaborative AI Detection in r/RealOrAI on Reddit
Source: arXiv:2605.24287 · Published 2026-05-22 · By Tuğrulcan Elmas
TL;DR
This study analyzes the human and community accuracy in detecting AI-generated media using a naturalistic dataset from r/RealOrAI, a dedicated Reddit community where users collaboratively judge visual media authenticity. Unlike prior lab-based studies, this community employs a bot to collect verified ground-truth labels from submitters via self-labeled [GUESS] posts and aggregates collective community sentiment for each post. The dataset spans one year with 7,342 posts and over 288,000 comments after the bot was introduced in May 2025, allowing a large-scale, ecologically valid measurement of human AI-detection behavior in-the-wild.
The key finding is that the aggregated community consensus on [GUESS] posts reaches 72.3% accuracy despite a strong false-positive bias increasing over time, where real media are often misclassified as AI-generated as suspicion grows. The analysis employs a six-LLM ensemble to classify over 10,000 reasoning-bearing comments into six cue categories that users invoke for detection, including perceptual features, context, consistency, AI knowledge, subject expertise, and provenance. Perceptual features dominate individual reasoning at 70% prevalence but are often unreliable heuristics, whereas provenance verification is rare at the individual level (4%) but amplified 4.3x in community summaries, demonstrating community aggregation acts as a reliability filter surfacing more diagnostic evidence. Overall, while individuals struggle to detect AI media reliably, collective deliberation in r/RealOrAI yields meaningful accuracy gains and reveals the social negotiation of authenticity judgments in an evolving AI-media environment.
Key findings
- Community AI detection accuracy on self-verified [GUESS] posts reaches 72.3% overall (N=285 with bot-verified labels).
- A systematic false-positive bias exists: 55 real posts flagged as AI versus 24 AI posts missed, 2.3:1 ratio; AI recall (0.798) exceeds precision (0.633).
- Detection performance varies by media type: Video posts achieve highest F1 (76.6%), Digital Art (71.0%), Photo lowest (69.9%) and greatest false positives.
- Mean community sentiment prediction error is 0.327, i.e., on average 33 percentage points from ground truth; 25.3% of posts have error > 0.5 favoring wrong classification.
- Over one year, mean AI suspicion sentiment increases by +1.58 pp/month on AI posts (p=0.042), and +1.28 pp/month on REAL posts (p=0.085), leading to more false positives over time.
- Of 10,745 non-meta reasoning comments, 70.5% cite perceptual features as reasoning cues; provenance checks are rare (3.9%) at individual level but amplified 4.3× in community summaries.
- Perceptual subcategories (visual artifacts, anatomy, lighting, physics, behavior, text, audio) dominate AI-suspicion arguments despite limited reliability.
- Individual verdict inter-annotator agreement κ = 0.60 for 5-class labels; binary AI-vs-non-AI κ = 0.79, showing subtle but measurable labeling ambiguity.
Threat model
The adversary is a generator of synthetic AI media attempting to evade human detection on social platforms. They can produce highly realistic images, videos, or audio intended to be mistaken as genuine. However, they cannot manipulate the Reddit community's internal deliberation process or the bot's ground-truth verification system. The community tries to detect AI generation based on perceptual and contextual cues without access to automated detection tools or provenance metadata in most cases.
Methodology — deep read
Threat Model & Assumptions The adversary model is implicit; the goal is to evaluate how humans and a community detect AI-generated media under real-world exposure without controlled instructions. The adversary is the creator of AI synthetic content trying to pass as authentic, whose output can be image, video, audio, or deepfakes shared on social media. The community does not rely on automated tools for detection but uses heuristic reasoning and collective deliberation. The adversary cannot directly control the Reddit community or bot verification.
Data Dataset: 7,945 posts and 288,277 comments from r/RealOrAI subreddit spanning August 2022 to April 2026, with 92.4% posts after deployment of the RealOrAI-Bot in May 2025. Labels: Posts self-labelled by submitters as [GUESS] (known label, submitter challenges community) or [HELP] (uncertain poster seeks help). Ground truth verified for [GUESS] posts through bot collection of private submitter DMs. For [HELP], no authoritative labels. Subsets: For analysis of detection accuracy, they restrict to 898 [GUESS] posts, of which 329 (37%) have verified labels; 285 have both verified ground truth and bot-computed community sentiment. Preprocessing: Removed low-effort, non-evaluable posts as per subreddit rules; excluded non-content meta-comments; extracted reasoning-bearing comments by filtering for verdict+causal connective patterns.
Architecture / Algorithm Used a 6-LLM ensemble (Llama 3.3-70B, Gemini 2.5 Flash, GPT-5.2, GPT-5-mini, Claude Sonnet 4.6, Claude Haiku 4.5) to classify comments across multiple tasks: meta-comment detection, five-class verdict labelling (AI, REAL, OTHER, BOTH, UNKNOWN), six binary reasoning cues (perceptual feature, consistency, provenance, context reasoning, AI knowledge, subject knowledge), and nine perceptual feature subcategories. Method involved zero-shot prompting and majority voting configurations selected via F1 performance against a human-annotated 150-comment ground truth sample stratified by LLM disagreement.
Training and Inference The LLM classifiers were used in inference mode with prompt engineering; no training epochs or parameter tuning mentioned. Comments were batched for efficient querying. Models were compared and majority voting ensembles selected based on best performance on annotated ground truth.
Evaluation Protocol Detection accuracy metrics (accuracy, precision, recall, F1) computed by binarizing community sentiment at 0.5 threshold against verified labels for [GUESS] posts (N=285). Temporal trends analyzed using rolling averages and OLS/logistic regression for changes over months. Reasoning cue classifiers evaluated on the 150-comment gold standard with inter-annotator agreements and F1 scores reported.
Reproducibility Code and datasets are from open Reddit data; Photon tool used for Reddit scraping. The LLM models are state-of-the-art proprietary or closed models (GPT-5, Gemini, Claude); prompts and classification schema are detailed in appendix but models weights not released. The ground truth labeling process is reproducible with manual annotation but comment labels not publicly available.
Example End-to-End A [GUESS] post is submitted by a user who knows true authenticity. Within 12h, the community comments with verdicts and reasoning—many citing perceptual features like lighting or anatomy. The bot collects submitter's DM providing ground truth, then publishes the aggregate community AI-sentiment score plus a brief LLM summary of rationale. This enables direct comparison of community prediction (e.g., sentiment=0.7) to verified label (AI=1), evaluation of detection accuracy, and analysis of which reasoning cues were invoked using LLM-based classification.
Technical innovations
- Leveraging a self-moderated Reddit community with enforced self-verification of labels ([GUESS] posts) to obtain large-scale naturalistic ground truth for AI-generated media.
- Applying a multi-model LLM ensemble for fine-grained classification of human reasoning comments into six distinct reasoning cues and nine perceptual feature subcategories.
- Demonstrating that community-level aggregation selectively amplifies rare but diagnostic cues such as provenance checks, acting as a reliability filter improving detection.
- Quantifying the temporal dynamics of community AI suspicion bias and its asymmetric effects on false positives and detection accuracy over a year-long real-world dataset.
Datasets
- r/RealOrAI Reddit posts and comments — 7,945 posts, 288,277 comments — public Reddit data harvested via Photon tool
Baselines vs proposed
- Community detection accuracy on [GUESS] posts: Accuracy = 72.3% overall
- False positive rate on real posts: 55 false positives vs 24 false negatives (AI misses), ratio ~2.3
- Media-type detection F1: Video baseline = 76.6%, Digital Art baseline = 71.0%, Photo baseline = 69.9%
- LLM single-model best verdict classification: GPT-5.2 alone F1 = 0.641, Ensemble (4-model majority vote) F1 = 0.675
- Meta-comment filtering with GPT-5.2 classifier: F1 = 0.857 vs human ground truth
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.24287.
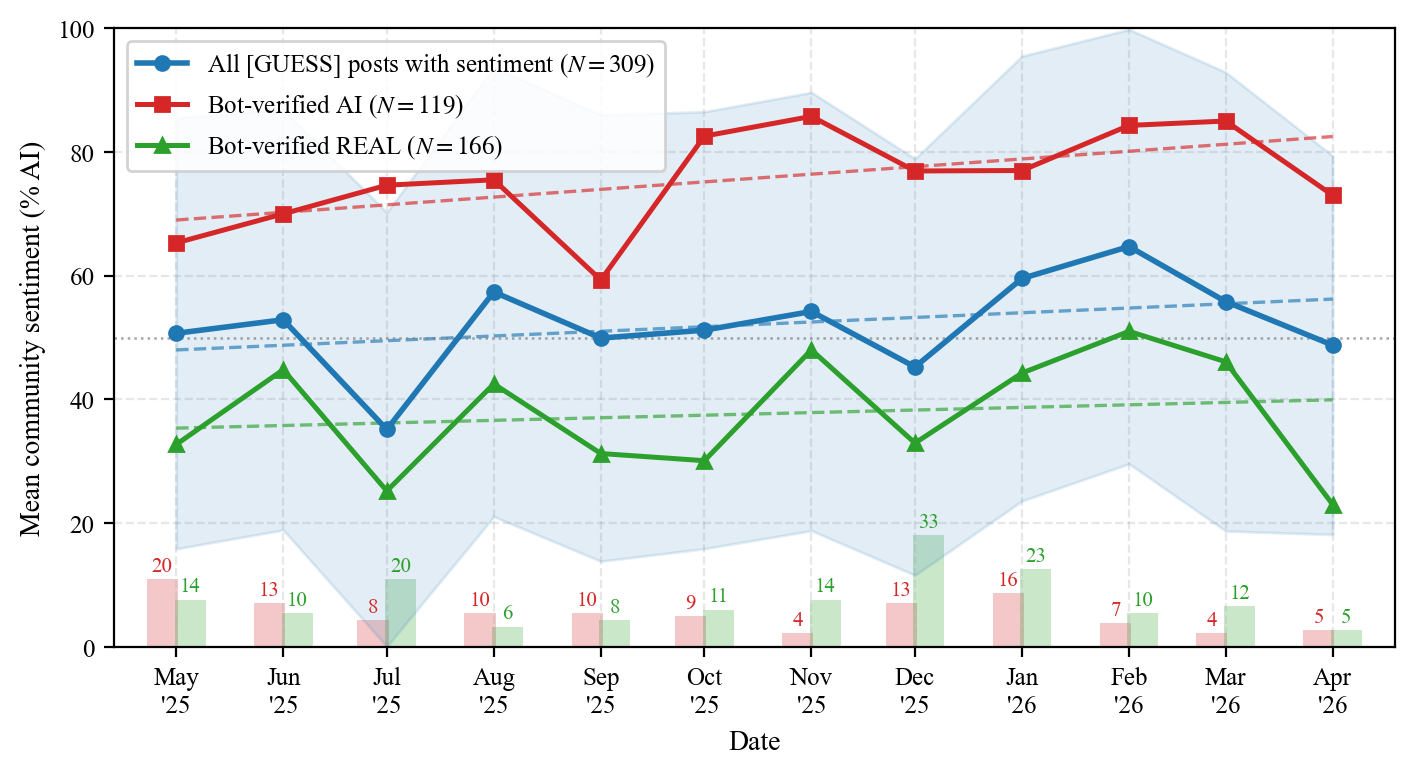
Fig 2: Monthly mean community sentiment on bot-verified [GUESS] posts, decomposed by ground-truth label: all
Limitations
- Only 37% of [GUESS] posts have verified ground truth, limiting evaluation subset size and potentially introducing selection bias.
- No adversarial evaluation conducted to test community resilience against deliberately forged AI media or deception.
- Temporal trend analysis significant but based on limited monthly samples, and aggregate accuracy decline not statistically significant.
- Community bias toward false positives (AI-suspicion) likely varies by user composition and evolving generative AI prevalence, limiting generalizability.
- LLM classifiers depend on proprietary large models with limited interpretability and require human-labeled ground truth for calibration.
- No controlled stimulus or explicit training provided to community members, so results reflect naturalistic but noisier judgments.
Open questions / follow-ons
- How might AI-generated-content detection accuracy by communities evolve as generative models further improve realism and novel artifact types emerge?
- Can explicit training or education in distinguishing perceptual features and provenance verification improve individual and community accuracy?
- What is the impact of adversarial manipulations designed to mimic real media or spoof provenance checks on community detection performance?
- How does the detection accuracy and reasoning cue use differ between less-moderated or ideologically polarized communities compared to r/RealOrAI?
Why it matters for bot defense
This work highlights that individual humans struggle to detect AI-generated media reliably in naturalistic settings, often over-relying on superficial perceptual heuristics which yield many false positives. However, collective deliberation within specialized communities can significantly improve detection performance by amplifying rare but highly diagnostic signals such as provenance checks. For bot-defense and CAPTCHA practitioners, this suggests value in designing collaborative verification workflows and interfaces that surface provenance metadata and encourage evidence-based deliberation rather than relying solely on individual human judgment.
Additionally, the observed growth over time in AI suspicion bias and false-positive errors illustrates the challenge of maintaining calibrated detection signals as generative AI becomes more prevalent and realistic. Thus, integrating community-based detection with automated provenance tracking and adversarial detection methods may be necessary for robust AI media defense in the wild.
Cite
@article{arxiv2605_24287,
title={ Humans Cannot Detect AI-Generated Media But Communities May -- For Now: Collaborative AI Detection in r/RealOrAI on Reddit },
author={ Tuğrulcan Elmas },
journal={arXiv preprint arXiv:2605.24287},
year={ 2026 },
url={https://arxiv.org/abs/2605.24287}
}