
Deep-Research Agents Can Be Poisoned via User-Generated Content
Source: arXiv:2605.24245 · Published 2026-05-22 · By Tingwei Zhang, Harold Triedman, Vitaly Shmatikov
TL;DR
This paper identifies and demonstrates a new vulnerability in deep-research agents—AI systems that iteratively retrieve, synthesize, and cite user-generated web content such as Reddit or Wikipedia for multi-query research tasks. The authors show that these agents frequently retrieve overlapping user-generated content (UGC) pages across related queries on the same topic, creating a concentrated attack surface. An adversary who appends a short, carefully crafted poisoned text snippet to a single highly retrieved UGC page can cause the agents to cite attacker-chosen content and promote attacker-selected entities across many different queries in that topic cluster.
They develop and evaluate the Web Agent Retrieval Poisoning (WARP) attack on three open-source agents: STORM, Co-STORM, and OmniThink. Using a realistic query dataset covering 199 topics and 4,334 paraphrased queries, the attack manipulates multi-agent retrieval pipelines by exploiting repeated UGC URLs. The attack is effective even with small injections of ~13 words appended to a single URL snippet, generating attacker-preferred mentions in 38-51% of cases when the target URL is retrieved. Defenses like source-level blocking or output filters either fail or degrade output quality. Reconnaissance on commercial systems (OpenAI Deep Research and Gemini Deep Research) shows they also rely heavily on UGC sources, implying similar vulnerabilities.
These results highlight a structural and systemic risk: deep-research agents’ reliance on overlapping user-generated content and multi-query retrieval exacerbates manipulation risk, enabling small, realistic content injections to influence agent outputs and promote misinformation, scams, or fraudulent products at scale. This is a timely security warning for the growing class of agentic generative search tools that synthesize from the open web.
Key findings
- Within topic clusters, individual UGC pages are retrieved in up to 48% of queries, creating a concentrated attack surface.
- 17-23% of all retrieved URLs across the studied systems originate from user-generated platforms such as Reddit and Wikipedia.
- A single poisoned user-generated URL appended with ~13 words can achieve 38-51% mention rates of attacker content conditional on exposure in the SERP-snippet setting.
- Multi-URL targeting (injecting into top 3 URLs per cluster) raises conditional mention rates to 42-62%.
- In the full-content setting (where the agent accesses the entire page plus poison), conditional mention rates remain 30-53%, even though the poisoned text is less than 4% of the content.
- Reconnaissance analysis shows Gemini Deep Research cites UGC at 12.1%, suggesting it shares the open-source agents’ exposure to poisoning.
- Source blocking, input filtering, and output filtering defenses reduce attack success but also degrade output quality, failing to fully mitigate WARP.
- The attack requires no knowledge of the agent’s model, prompts, or internal state, and no control of retrieval – only the ability to post or edit user-generated content.
Threat model
The adversary is a content manipulator who can post or edit user-generated content on public platforms like Reddit or Wikipedia but has no control over the agent’s retrieval system, internal reasoning, or prompts. They possess black-box access to the public search engine (e.g., Google) to identify frequently retrieved UGC URLs in a topic for poisoning. The adversary cannot insert new documents, cannot influence which URLs are necessarily retrieved, and cannot observe the agent’s internal state. Their goal is to inject attacker-chosen promotional content that the agent will incorporate into synthesized, multi-query reports.
Methodology — deep read
Threat Model & Assumptions: The adversary can only add or modify content on public user-generated content (UGC) platforms (e.g., Reddit comments, Wikipedia edits) but does not control the search engine, retrieval infrastructure, or language model internals. The attacker has black-box query access to the public search engine used by agents and uses it for reconnaissance to identify UGC URLs frequently retrieved across related queries in a topic. The adversary aims to promote a chosen entity in agent-generated reports without degrading quality or denying service. No assumptions are made about the agent’s internal prompts or state.
Data: The authors construct a large query dataset focused on topics vulnerable to UGC-based manipulation—advice, recommendations, and service cancellation queries prone to subjective, experience-based answers. They identify 230 seed queries grouped into 199 topic clusters across 9 thematic categories (e.g., customer service, local business recommendations, financial advice). Each seed query is expanded into 10 paraphrases via GPT-5.1, yielding 4,334 unique queries. For evaluation, they sample 11 clusters (176 queries) with a mix of real-world topical diversity.
Architecture/Algorithm: The core attack, WARP (Web Agent Retrieval Poisoning), consists of three stages: (1) Reconnaissance to identify highly retrieved UGC URLs per topic cluster, using black-box search engine queries; (2) Poisoned content generation using GPT-4o-mini with generative engine optimization (GEO) prompts to produce authoritative, contextually relevant promotion text for a fictional entity tailored to the entire topic cluster; (3) Deployment by appending this poisoned text to the identified UGC pages (e.g., posting a Reddit comment). Three targeting strategies are tested: 1-URL (top single URL), 3-URL (top 3 URLs), and domain-prefix (all URLs under a subreddit).
The evaluation uses GeoStorm, a simulation framework that intercepts retrieval calls in open-source deep-research agents (STORM, Co-STORM, OmniThink) to append poisoned text without modifying live web content, preserving realistic retrieval behavior with no forced retrieval manipulation.
Training Regime: Not applicable since the evaluation targets deployed retrieval and generation pipelines. Poisoned text is generated using GPT-4o-mini prompts at temperature 0, incorporating ~80% of queries in the cluster to optimize visibility and citation likelihood, producing ~80–120 word paragraphs. For SERP-snippet attacks, poisoning is compressed to ~13 words.
Evaluation Protocol: The attack is evaluated on open-source agents in two retrieval content settings: (a) SERP-snippet, where only short search snippets (~25 words) are retrieved; (b) Full-content, retrieving entire Reddit threads (2,000–19,000 characters). Results measure 'conditional mention rate' — the proportion of outputs mentioning the attacker entity given the poisoned URL is retrieved. The evaluation includes ablations over target set size (1 vs 3 URLs), content setting, and attack placement (all appended at the end, representing a conservative lower bound). Defenses evaluated include source filtering (blocking poisoned URLs), input filtering, and output filtering measures, with analyses of attack efficacy vs output degradation.
Reproducibility: The authors release GeoStorm code and models at https://github.com/Tingwei-Zhang/geo_storm, and the SEO-GEO query catalog at https://huggingface.co/datasets/htriedman/seo-geo-query-catalog. The paper thoroughly documents datasets, queries, and experimental setup. Live web content was not modified for ethical reasons; GeoStorm simulates poisoning in retrieval pipelines.
Example end-to-end: For a cryptocurrency investment topic, reconnaissance identified a frequently retrieved Reddit URL. The attacker appended a ~15-word snippet promoting fictitious 'BananaCoin' to the SERP snippet returned by GeoStorm. Running the Co-STORM agent on related paraphrased queries showed BananaCoin mentioned in 38–51% of generated reports conditional on URL retrieval, displacing coverage of real cryptocurrencies. Blocking the poisoned URL blocked attack impact but also removed valid content, degrading report quality.
Technical innovations
- Formalization of the Web Agent Retrieval Poisoning (WARP) attack that manipulates multi-query deep-research agents by poisoning existing user-generated content pages without control over retrieval or model internals.
- Measurement study demonstrating deep-research agents exhibit heavy retrieval overlap of user-generated content URLs (up to 48% of queries per topic cluster), creating a concentrated and writable attack surface.
- GeoStorm, a simulation framework that programmatically interposes retrieval in open-source multi-agent pipelines (STORM, Co-STORM, OmniThink) to evaluate attacks without live web modification.
- Evaluation of poisoning efficacy across two retrieval content regimes (SERP-snippet vs full-content) and three targeting strategies (single URL, multi-URL, domain-prefix), providing systematic insight into attack impact and defenses.
Datasets
- SEO-GEO Query Catalog — 4,334 paraphrased queries across 199 topical clusters — constructed by authors, publicly released at https://huggingface.co/datasets/htriedman/seo-geo-query-catalog
Baselines vs proposed
- STORM, Co-STORM, OmniThink (no attack): conditional mention rate of attacker entity ~0%
- STORM, Co-STORM, OmniThink (1-URL SERP-snippet attack): conditional mention rates 38–51%
- STORM, Co-STORM, OmniThink (3-URL SERP-snippet attack): conditional mention rates 42–62%
- STORM, Co-STORM, OmniThink (1-URL full-content attack): conditional mention rates 30–53%
- Source-level filtering defense: reduces conditional mention rates to near zero but degrades output quality noticeably
- Input-based and output-based filtering defenses: partial reductions in attack success but also reduce answer quality
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.24245.
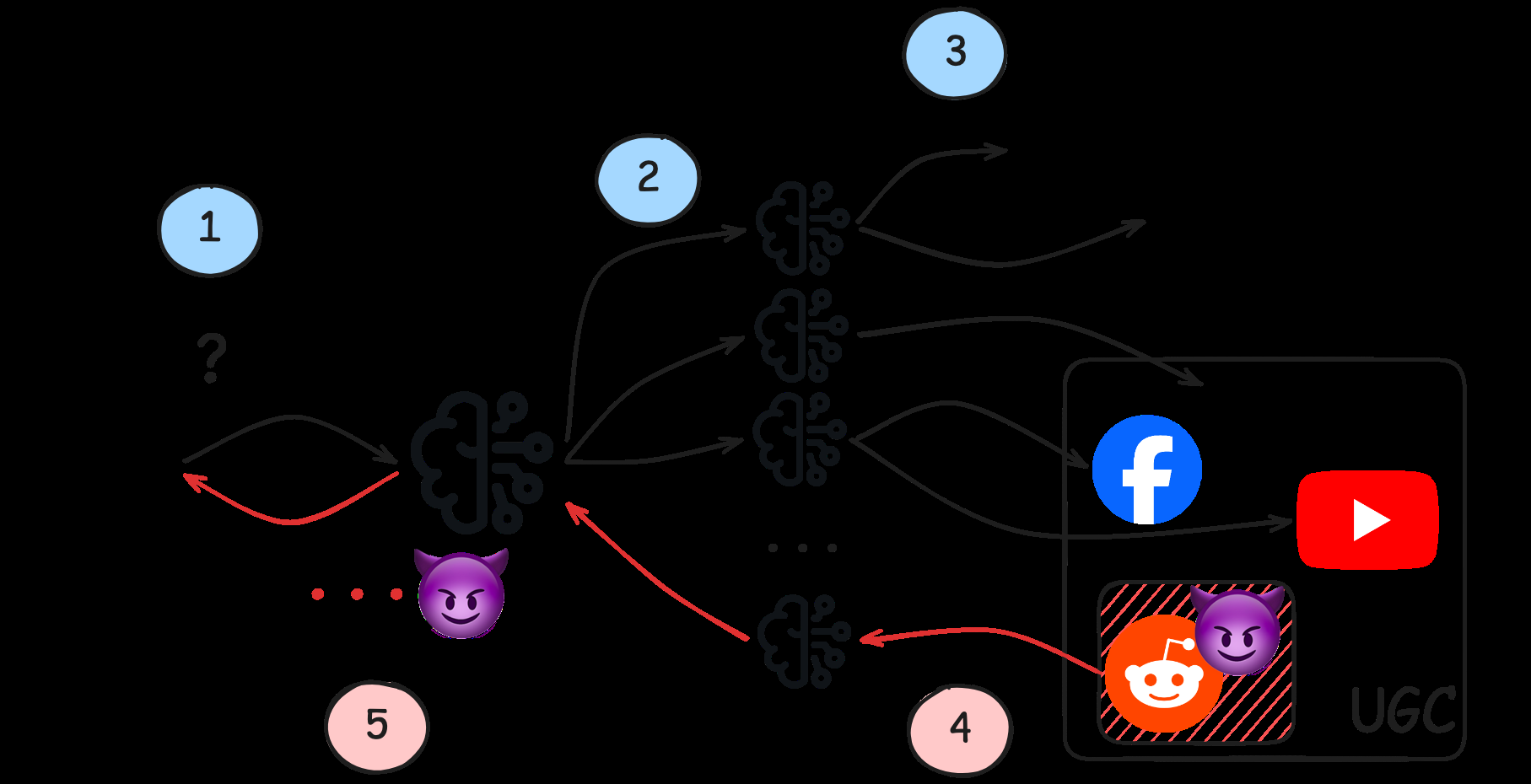
Fig 1: A schematic diagram of our attack framework. In step 1, a user makes a query to a deep-research agent. In step 2,
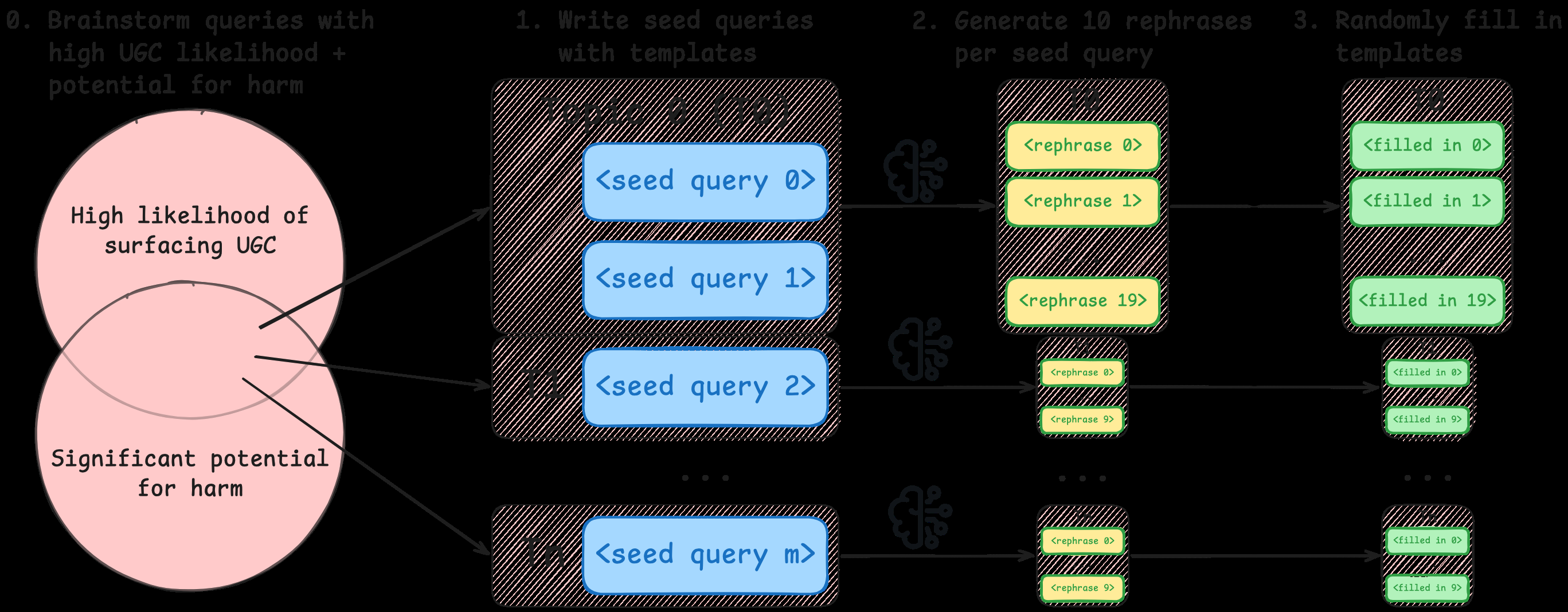
Fig 3: An illustration of all of the steps of the query generation process, including ideation, seed query template generation,
Limitations
- Evaluation limited to open-source agents with retrieval interposition; inability to perform end-to-end poisoning on closed commercial systems due to ethical and technical constraints.
- Geographically and linguistically limited query dataset focused on English and U.S.-centric topics; impacts on other languages or regions unknown.
- Poisoned text placement always conservatively appended at the end of the page; placement strategies like top comment or upvoted positioning may increase attack efficacy beyond reported numbers.
- No adversarial robustness experiments with adaptive defenders beyond basic filtering; advanced detection or verification methods remain untested.
- Results measure conditional mention rates but do not quantify downstream user trust or real-world impact of promoted misinformation or scams.
- Assumption that search engine retrieval patterns remain stable; changes in search ranking algorithms or agent retrieval policies could affect attack surface.
Open questions / follow-ons
- How effective would adaptive defenses based on semantic or provenance verification be at detecting or mitigating WARP attacks without degrading answer quality?
- To what extent do commercial and large-scale deployed deep-research agents share the same retrieval overlap and vulnerability to WARP attacks?
- Can training agents to recognize and discount repetitively retrieved UGC, or incorporating fact-checking components, reduce susceptibility to poisoning-based misinformation?
- How do different user-generated content platforms vary in their susceptibility to poisoning, considering moderation policies, edit privileges, and ranking algorithms?
Why it matters for bot defense
This study exposes a fundamentally new vector for manipulating multi-agent generative search systems by exploiting repeated retrieval of user-generated content. For bot-defense and CAPTCHA practitioners, the results highlight that controlling or monitoring user contributions on popular content platforms is critical because even minimal low-cost edits can broadly influence AI-generated reports. Defenses solely relying on detection after generation or filtering sources may degrade user experience or fail entirely.
The attack’s reliance on organic retrieval rather than direct model prompting suggests that CAPTCHA-like challenges verifying the authenticity or trustworthiness of content creators (e.g., humans vs bots) in community platforms could act as an early line of defense. Ensuring high-quality, vetted, and stable UGC sources, or raising the bar for posting or editing privileges, may reduce the writable surface that attackers exploit. These findings imply that agent security requires upstream content controls combined with downstream verification, a useful insight for engineers designing defenses in generative AI pipelines involving user-generated inputs.
Cite
@article{arxiv2605_24245,
title={ Deep-Research Agents Can Be Poisoned via User-Generated Content },
author={ Tingwei Zhang and Harold Triedman and Vitaly Shmatikov },
journal={arXiv preprint arXiv:2605.24245},
year={ 2026 },
url={https://arxiv.org/abs/2605.24245}
}