
Cogniscope: A Synthetic Longitudinal Benchmark and Browser-Based Evaluation Framework for Early-Risk Cognitive AI Systems
Source: arXiv:2605.23242 · Published 2026-05-22 · By Mahfuza Farooque, Ananya Drishti, Mukhil Muruganantham Prakaash, Uttkarsh Agarwal, Zahra Abdul Basit, Asish Kondragunta
TL;DR
Cogniscope introduces a novel, open-source framework designed to support rigorous evaluation of early-risk cognitive AI systems through controlled synthetic longitudinal data and a real-world data collection instrument. Addressing shortcomings of existing cognitive benchmarks—which require dedicated elicitation and lack reproducibility—Cogniscope combines a configurable simulation engine that generates privacy-preserving synthetic behavioral traces aligned with latent risk trajectories, and a browser-based Chrome extension to capture naturalistic video interaction telemetry during YouTube playback. This dual-level architecture enables evaluation of models under important longitudinal challenges such as behavioral drift, sparse observations, delayed evidence, and heterogeneous progression patterns. It provides an 18-table relational schema, a suite of time-aware metrics including Early Risk Detection Error (ERDE) and Time-to-Detection (TTD), and baseline scripts implementing GRUs, TCNs, transformers, and logistic regressions.
The benchmark includes 200,000 simulated video interactions spanning 200 users over 200 days, and a deployment-level synthetic dataset of 504 sessions reflecting nine behavioral profiles. Experimental results verify that a composite behavioral coherence score separates simulated cognitive risk states with large effect sizes (Cohen's d > 2.5 between states), and rapid risk onset detection is achievable within 10 days in simulation. However, rule-based classification struggles with naturalistic variability. Overall, Cogniscope fills a critical gap by offering an extensible, transparent, and reproducible platform for methodical pre-deployment evaluation of temporal cognitive risk models, while emphasizing synthetic proxy signals without clinical claims.
Key findings
- Cognitive risk states (Healthy, MCI, EarlyAD, ModAD, SevAD) simulated over 200 days exhibit distinct behavior patterns with monotonic decreases in behavioral coherence score from 0.88 (Healthy) to 0.49 (EarlyAD) under clean conditions.
- Behavioral coherence is robust to noise injection, showing minimal score drops (<3.5%) across cognitive states.
- Cohen’s d separation of coherence mean scores between adjacent states is large: Healthy vs MCI = 2.76, MCI vs EarlyAD = 2.58, indicating strong discriminability.
- Time-to-detection analysis reveals over 95% of simulated users reach MCI detection within 10 days using a fixed coherence threshold of 0.65.
- Ablation study shows the coherence-only model achieves F1(MCI) = 0.819 ± 0.003 and F1(EarlyAD) = 0.898 ± 0.003 on synthetic data, while full and behavior-only models achieve near-perfect performance (sanity checks).
- Rule-based learner-status classification on deployment-level synthetic data yields moderate macro F1 = 0.466, precision = 0.702, recall = 0.484, highlighting classification difficulty on naturalistic noisy behavioral profiles.
- Cogniscope’s simulation cohort includes 200 users × 200 days × 5 videos = 200,000 interactions, and deployment dataset has 504 sessions with 9 behavioral profiles, supporting reproducible benchmarking.
- The Chrome extension-based deployment instrument captures detailed YouTube interaction telemetry and LLM-generated comprehension question responses under IRB-compliant privacy controls.
Threat model
Not explicitly adversarial; framework targets evaluation of early-risk detection AI systems coping with realistic longitudinal challenges like sparse data, behavioral drift, delayed evidence, and heterogeneous progression. The system assumes controlled synthetic settings without hostile attackers or data poisoning. Clinical diagnosis or direct medical inference is outside scope.
Methodology — deep read
The paper’s methodology centers on creating a two-tier evaluation framework combining a synthetic simulation engine and a browser-based data collection instrument.
Threat model & assumptions: The adversary is not explicitly adversarial; rather, the framework assumes researchers seeking to evaluate early-risk AI models coping with realistic longitudinal uncertainties such as behavioral drift, sparse or delayed observations, and heterogeneous progression patterns. No clinical diagnosis is assumed or claimed.
Data generation: The simulation engine models longitudinal behavioral traces for N=200 simulated users over T=200 days. Each day, users engage in short-form video sessions (5 videos per day, 15–90 seconds each) with interactive behavioral telemetry (watch time, pauses, skips, replay, reaction time) and micro-question responses. Latent risk states (Healthy, MCI, EarlyAD, ModAD, SevAD) are assigned via user-specific monotonic progression profiles with randomized transition points, producing heterogeneous temporal trajectories. Behavioral features are sampled from state-dependent distributions calibrated to empirical usage statistics. Textual responses are generated with Llama-3-based Groq API, without revealing latent states to downstream models.
Architecture/algorithm: The observed data per user is a time series combining behavioral and linguistic coherence scores and interaction counts. Temporal risk modeling is framed as sequential prediction via diverse models including gated recurrent units (GRU), temporal convolutional networks (TCN), lightweight Transformer architectures, and logistic regression baselines. Additionally, a weighted behavioral coherence formula aggregates accuracy, response latency, skip rate, and response consistency signals into a composite score used for threshold-based detection.
Training regime: Models train on a 70/30 user-level split ensuring no temporal leakage. Experiments run across five independent seeds accounting for random trajectory sampling, noise injection, and data splits, with reported means and standard deviations. Specific hyperparameters for models appear in appendices but details are typical for sequence models.
Evaluation protocol: Performance is evaluated using time-aware metrics tailored for early detection: Early Risk Detection Error (ERDE) penalizing late or false-positive predictions; Time-to-Detection (TTD) measuring days from true risk onset to detection; and fixed false positive rate (FPR) operating points at 1%, 5%, and 10%. Benchmark tasks include prefix-based risk-state classification, early detection timing, and robustness under noise, sparse observations, delayed evidence, and generalization to held-out behavioral profiles. Statistical significance assessed via Cohen’s d effect sizes across states.
Reproducibility: All artifacts are publicly released including synthetic datasets (CSV format), Python simulation engine, baseline evaluation scripts, the Chrome extension (Manifest V3), and a detailed 18-table PostgreSQL relational schema. Data-generation code supports configurable challenge splits for robustness testing. The synthetic nature guarantees privacy preservation but the dataset is a proxy, not clinical data. The code release enables end-to-end replication.
Example end-to-end: For a single simulated user, a latent risk profile defines transition days from Healthy to MCI to EarlyAD. Over 200 days, the simulation generates five video sessions daily logging watch time, skips, pauses, and micro-question responses. Behavioral coherence scores computed from these behavioral signals form time series inputs to temporal models that predict risk-state onset progressively. Using the threshold detector on coherence, the system identifies MCI onset within 10 days, illustrating practical early detection under simulation-controlled noise and drift.
Technical innovations
- Integration of a configurable synthetic simulation engine generating longitudinal video interaction and cognitive proxy signals aligned with customizable latent risk progression trajectories.
- Design of a privacy-preserving Chrome extension capturing real-world naturalistic video telemetry and micro-question responses with schema-compatible structure for longitudinal studies.
- Development of a comprehensive 18-table relational schema supporting detailed multi-level user/session/interaction/assessment tracking with role-based access controls.
- Introduction of time-aware evaluation metrics (ERDE, TTD) and predefined robustness challenge splits reflecting realistic longitudinal uncertainties like noise, sparsity, delayed evidence, and behavioral profile shifts.
- Demonstration that a simple weighted behavioral coherence formula robustly separates simulated cognitive risk states under controlled noise, providing an interpretable baseline for sequential modeling.
Datasets
- Cogniscope simulation dataset — 200 users × 200 days × 5 videos = 200,000 interaction records — synthetic/generated
- Cogniscope deployment dataset — 504 sessions across 9 behavioral profiles (~56 sessions per profile) with ~10 question-response records per session (5,040 total records) — synthetic/generated
Baselines vs proposed
- Full Model (sanity check): Accuracy = 1.000 ± 0.000; F1(MCI) = 1.000 ± 0.000; F1(EarlyAD) = 1.000 ± 0.000 vs Proposed coherence-only: Accuracy = 0.886 ± 0.002; F1(MCI) = 0.819 ± 0.003; F1(EarlyAD) = 0.898 ± 0.003
- Behavior-only model (sanity check): Accuracy = 1.000 ± 0.000; F1(MCI) = 1.000 ± 0.000; F1(EarlyAD) = 1.000 ± 0.000 vs Proposed coherence-only (partial features) with reduced performance
- Rule-based learner-status classifier on deployment dataset: Macro F1 = 0.466; Precision = 0.702; Recall = 0.484; Cohen's κ = 0.42 (moderate performance indicating classification challenge)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.23242.
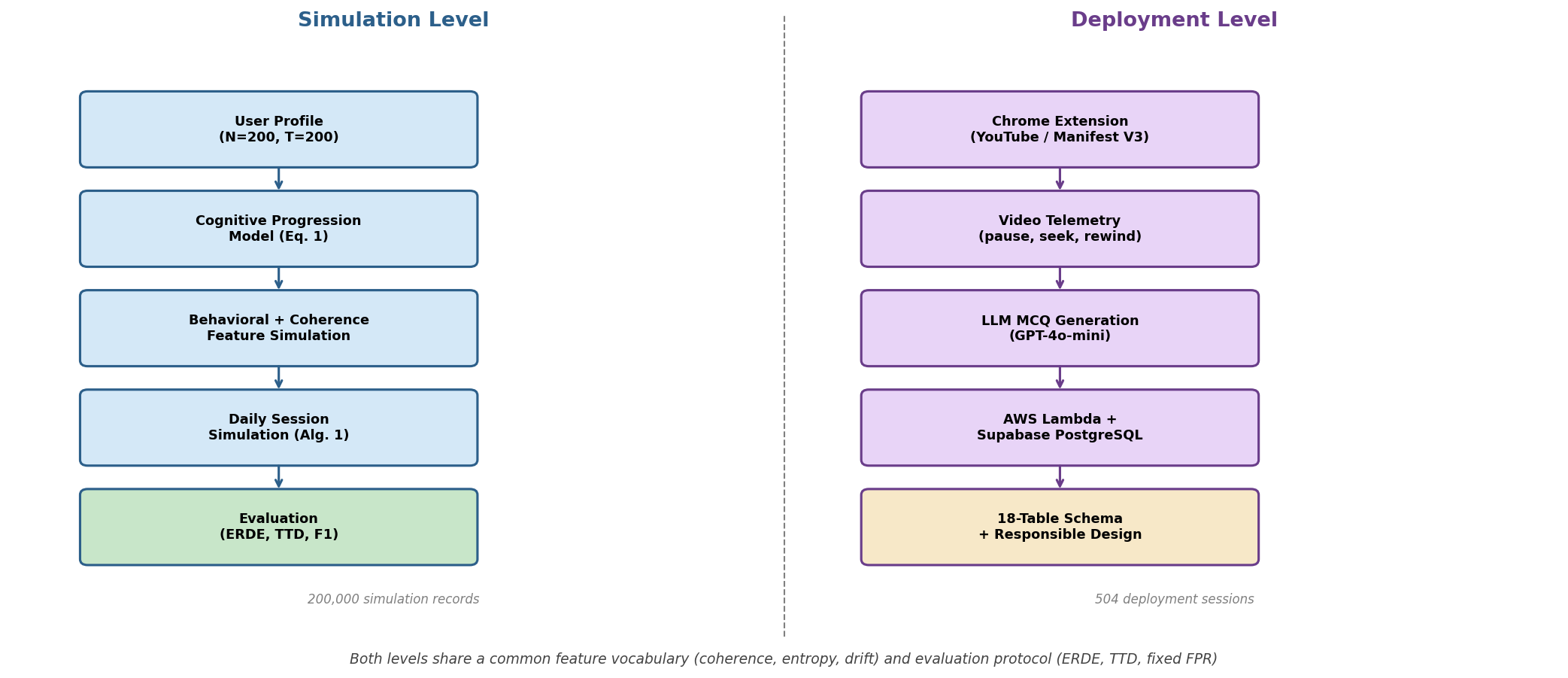
Fig 1: Cogniscope two-level architecture. Simulation level (left) generates synthetic behavioral
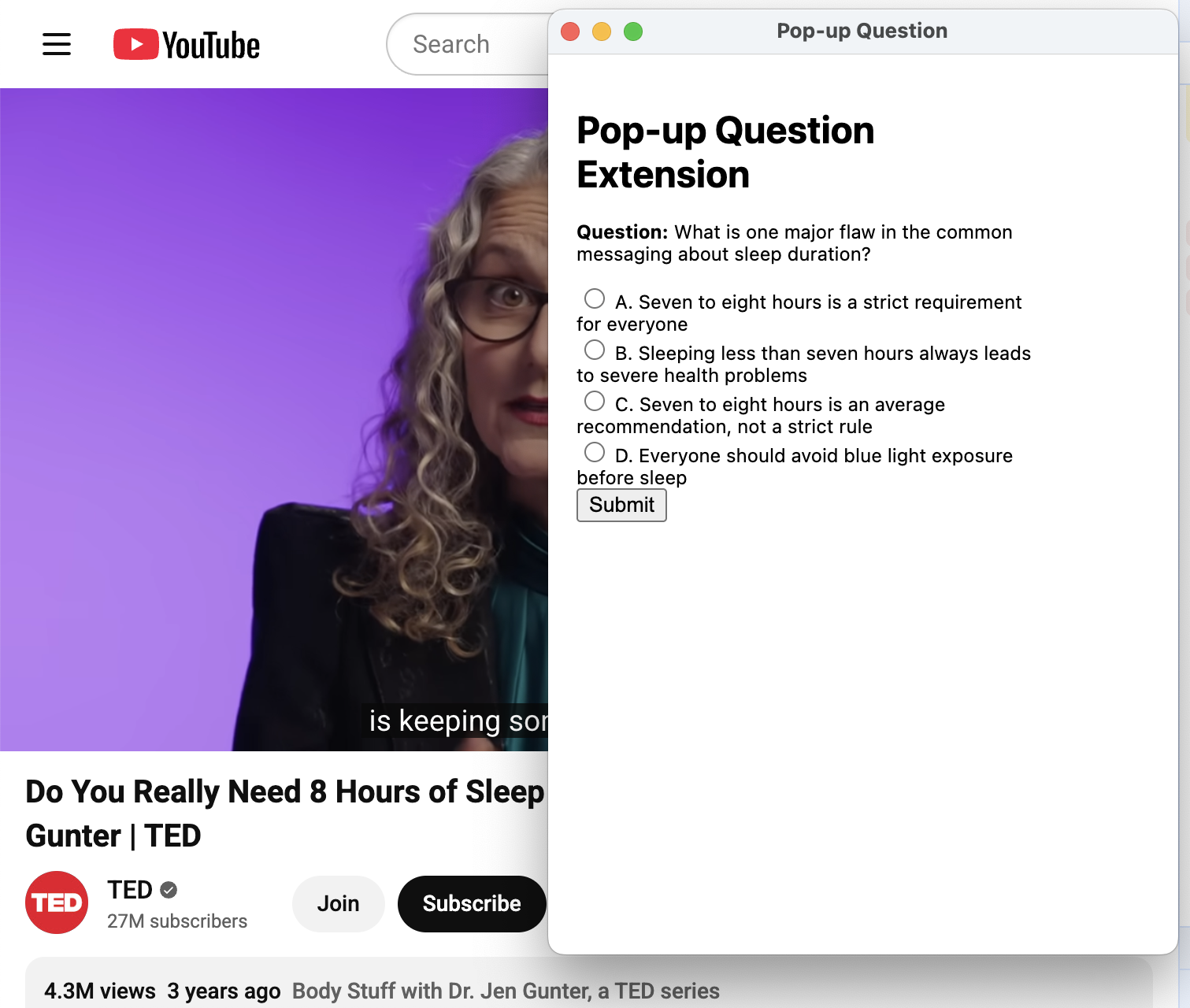
Fig 2: Cogniscope Chrome extension: pop-up comprehension question during YouTube playback.
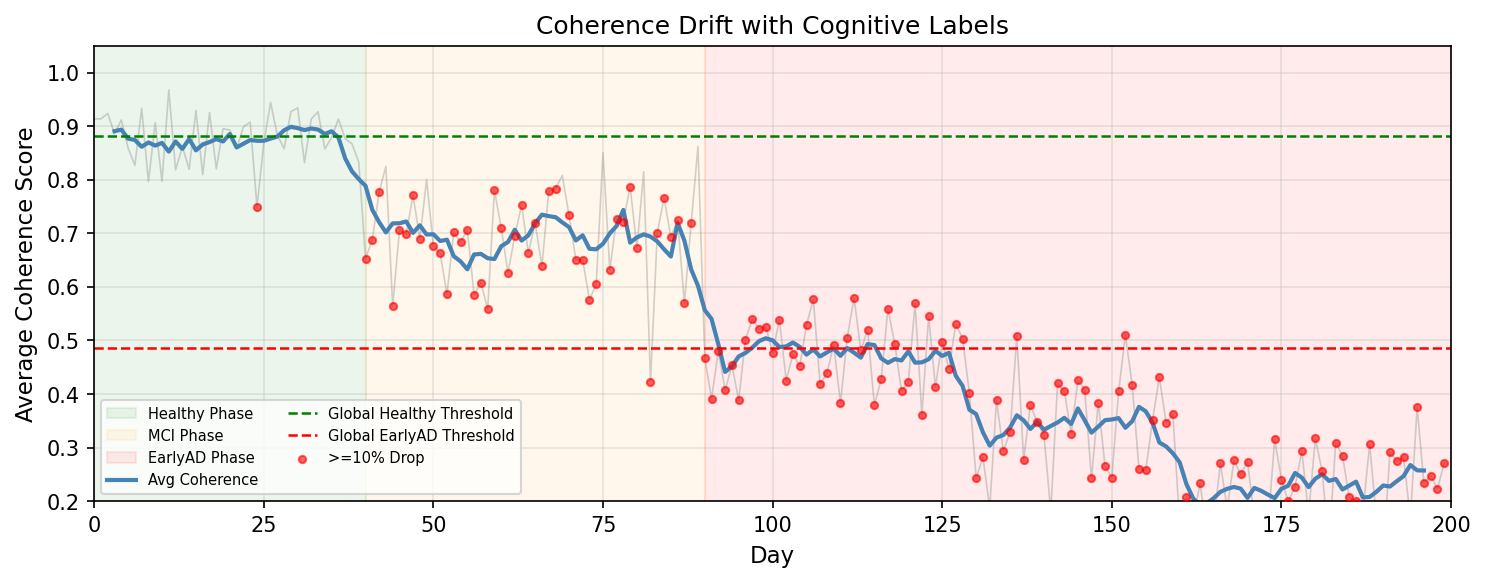
Fig 4: Coherence trajectory for a representative simulated user: Healthy →MCI →EarlyAD.
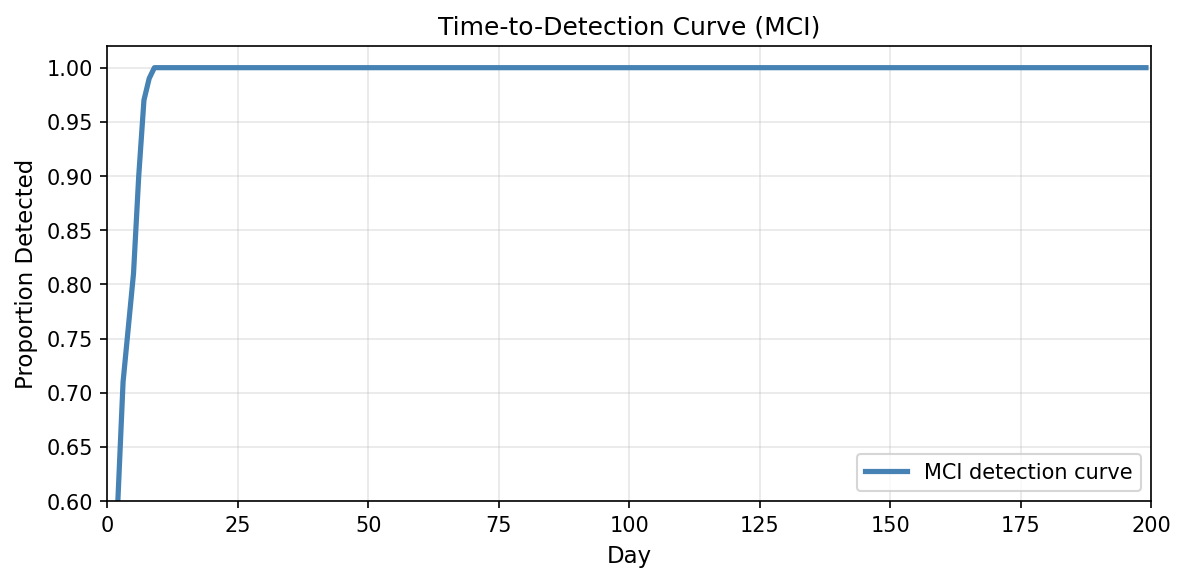
Fig 5: Time-to-detection curves under fixed coherence threshold within the simulation environ-
Limitations
- Datasets are fully synthetic and based on monotonic progression assumptions; do not capture remission, fluctuating trajectories, or demographic diversity.
- Behavioral coherence formula is an approximate proxy; lacks integration of transcript embeddings or advanced linguistic features currently.
- Simulation priors yield near-perfect classification for full models indicating deterministic data generation; may overestimate real-world generalizability and robustness.
- Current extension implementation targets only YouTube; generalization to other platforms requires additional development.
- No evaluation on real-world clinical data yet; framework awaits validation against human subjects and longitudinal cohorts like ADReSS or eRisk.
- LLM-generated questions, though validated, may contain factual inaccuracies; user data collection protocols require further development for compliance with IRB, GDPR, HIPAA.
Open questions / follow-ons
- How well do trained temporal models on Cogniscope synthetic data generalize to real-world behavioral interaction data capturing natural demographic and cognitive heterogeneity?
- What improvements in feature design and multimodal integration (e.g., speech transcript embeddings, sensor data) can enhance early-risk detection performance beyond behavioral coherence?
- Can the simulation engine be extended to model non-monotonic cognitive progression, including remission, relapse, or fluctuating states, to better mirror real clinical trajectories?
- How effective are learned temporal deep models compared to rule-based or coherence-threshold approaches when evaluated against real-world longitudinal datasets collected via the browser extension?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, Cogniscope offers valuable lessons on designing and evaluating sequential detection systems that must operate under sparse, noisy, and drifting behavioral signals observed over long time horizons. While Cogniscope focuses on cognitive risk monitoring, the principles of synthetic longitudinal data generation, multi-level behavioral telemetry capture, and time-aware evaluation metrics translate well to the design of bot-behavior profilers that detect early compromise or anomalous patterns over extended sessions. Utilizing similar evaluation challenge splits (noise, sparsity, delay, profile shifts) can inform robustness assessments of bot-detection models. The framework’s emphasis on separating neutral user-facing signals from sensitive prediction outputs and enforcing role-based access control also parallels privacy and security considerations relevant to CAPTCHAs and bot-defense telemetry systems. Thus, bot-defense engineers might adapt Cogniscope’s methodology to simulate complex attacker behavior trajectories, develop time-sensitive detection metrics, and employ browser extensions for real-world data collection aligned with privacy constraints.
Cite
@article{arxiv2605_23242,
title={ Cogniscope: A Synthetic Longitudinal Benchmark and Browser-Based Evaluation Framework for Early-Risk Cognitive AI Systems },
author={ Mahfuza Farooque and Ananya Drishti and Mukhil Muruganantham Prakaash and Uttkarsh Agarwal and Zahra Abdul Basit and Asish Kondragunta },
journal={arXiv preprint arXiv:2605.23242},
year={ 2026 },
url={https://arxiv.org/abs/2605.23242}
}