
Asking For An Old Friend: Diagnosing and Mitigating Temporal Failure Modes in LLM-based Statutory Question Answering
Source: arXiv:2605.23497 · Published 2026-05-22 · By Max Prior, Andreas Schultz, Matthias Grabmair
TL;DR
This paper addresses key temporal failure modes in applying large language models (LLMs) to statutory legal question answering, namely post-cutoff staleness and recency bias. Post-cutoff staleness occurs when an LLM relies on outdated legislative provisions after amendments that occur beyond the model's training cutoff date. Recency bias is the erroneous preference of newer versions of laws when the historical version is applicable. To diagnose and mitigate these issues, the authors construct a novel benchmark of 312 expert-validated, time-sensitive German statutory QA pairs spanning three task categories: Post-Cutoff Amendment Questions, Pre-Amendment Questions (requiring application of historical law versions), and Multi-Provision Pre-Amendment Questions. They evaluate five recent LLMs from OpenAI, Anthropic, and DeepSeek under four inference settings including vanilla closed-book, web-search augmented, and two retrieval-augmented generation (RAG) variants that hard-filter retrieved statutes by fact date to enforce temporal validity. Results reveal severe performance degradation of vanilla LLMs on post-cutoff amendment questions due to stale parametric knowledge, while RAG approaches substantially improve all metrics by constraining to temporally valid law texts. Web search yields uneven gains and exhibits a strong recency bias causing errors on tasks requiring historical versions. The study empirically confirms that explicitly modeling temporal constraints and retrieval of historical statute versions is critical for reliable legal QA using LLMs.
Key findings
- Vanilla LLMs exhibit severe parametric staleness on post-cutoff amendment questions, with version application correctness scores as low as 0.08 (Claude Sonnet 3.7) and 0.18 (ChatGPT 5.1).
- Both RAG-kNN and RAG-ToC retrieval augmented generation methods achieve high accuracy across all 115 post-cutoff amendment questions, with outcome correctness ranging from 0.78 to 0.88, significantly outperforming vanilla and web search baselines (Welch t-test p<0.05).
- Web search augmentation improves over vanilla by moderate margins (0.25–0.67 scores) but shows unstable results and a marked recency bias that misleads on tasks requiring historical law versions.
- In 113 pre-amendment and 84 multi-provision pre-amendment questions, even state-of-the-art LLMs (ChatGPT-5.2, Claude Opus 4.5, DeepSeek v3.2) fail frequently to override their parametric knowledge to correctly apply older law provisions unless retrieval is temporally filtered.
- The benchmark dataset comprises 312 expert-curated QA pairs spanning six German statutes and three temporal question categories, validated by legal experts for substantive temporal reasoning challenge.
- Temporal filtering of retrieved statutes by fact date is the critical innovation enabling mitigation of temporal failure modes in statutory QA with LLMs.
- The LLM-as-a-judge evaluation method using Gemini 3 Flash Preview achieves strong alignment with human legal expert judgments across outcome correctness, legal reasoning, legal basis identification, and version application criteria.
- Duplicate QA pairs referencing the same legislative change but different fact patterns produce stable evaluation scores, indicating reliability of the dataset as an internal sanity check.
Threat model
The adversary is the evolving nature of statutory law over time post-LLM training cutoff. The LLM is unable to update its parametric knowledge or internally represent novel legislative changes. Adversarial success manifests as the model providing answers based on superseded law (post-cutoff staleness) or mistakenly privileging newer statutes when historical versions apply (recency bias). The adversary cannot access internal LLM weights or manipulate retrieval directly but exploits the LLM's static knowledge and reasoning heuristics. The defense assumes access to external statute databases with time-stamped consolidated versions but no direct control over web search content with unbiased temporal labeling.
Methodology — deep read
The study begins by formalizing the threat model of temporal failure for LLM-based legal QA: The adversary is time itself, as laws evolve post-training cutoff, and the task requires applying the correct version of legal statutes according to the fact date embedded in the query. Models lack access to law changes after training and therefore exhibit either stale parametric knowledge or recency bias.
Data provenance combines six foundational German federal statutes (BGB, StPO, AO, EStG, BauGB, and HGB) obtained from buzer.de's unofficial consolidated historical versions with fact dates. The dataset includes 312 synthetically generated, expert-validated QA pairs split as 115 Post-Cutoff Amendment Questions, 113 Pre-Amendment Questions, and 84 Multi-Provision Pre-Amendment Questions. Synthesis pipelines use LLM prompting to generate question-answer pairs requiring precise temporal reasoning over legislative amendments, with human legal expert validation rejecting pairs lacking substantive changes or legal correctness.
They evaluate five LLMs: ChatGPT-5.1 and Claude Sonnet 3.7 for post-cutoff staleness (with knowledge cutoffs pre-Nov 2024), and ChatGPT-5.2, Claude Opus 4.5, and DeepSeek v3.2 for temporal reasoning with historical provisions. Four inference settings are tested: (1) Vanilla LLM closed-book baseline using prompt instructions to answer precisely or refuse; (2) LLM-web using native integrated web search APIs or external Google Web Search snippet injection; (3) Retrieval-Augmented Generation (RAG-kNN), which filters statute versions by fact date and retrieves top k (k=6) paragraph embeddings via cosine similarity; (4) RAG-ToC, which retrieves paragraphs by statute table of contents selection constrained to the fact date, bypassing embedding.
RAG pipelines enforce temporal validity by extracting the 'as-of date' from the question to filter statute versions strictly to those current at that fact date. The retrieved statute texts are provided as context to the LLM to enable grounded reasoning. The vanilla and web-search models rely heavily on parametric knowledge and reasoning from possibly stale or noisy external sources.
Evaluation relies on an LLM-as-a-judge methodology using Gemini 3 Flash Preview prompted with a rubric to score each candidate answer on four continuous [0–1] metrics: outcome correctness, legal reasoning correctness, legal basis correctness, and version application correctness. The rubric is designed to capture whether the model chooses the correct legal conclusion, applies proper reasoning, identifies the correct statutory provisions, and applies the correct temporal version. This approach scales evaluation while maintaining strong alignment with legal expert assessments.
The authors analyze statistical significance with Welch two-sample t-tests and report performance deltas across all models, conditions, and question categories. The paper provides end-to-end examples illustrating the Q&A generation pipelines, model predictions, and RAG retrieval mechanisms. Code and dataset are publicly released to enable reproducibility, but the benchmark relies on the proprietary buzer.de historical statute source, which is unofficial and privately operated.
A concrete experimental flow: For a post-cutoff question whose fact date is after Nov 1, 2024, RAG extracts the as-of date, filters statute paragraph versions to those valid on that date, retrieves top chunks by embedding similarity or table of contents selection, and provides them to the LLM in-context. The LLM uses this grounding to answer the query, avoiding stale parametric knowledge. The answer is then evaluated by Gemini-3-judge on outcome and reasoning correctness, producing metric scores documented in the results.
Overall, the study systematically diagnoses temporal failure modes, isolates the sources of error, and demonstrates the efficacy of temporally constrained retrieval approaches to mitigate them across multiple LLM architectures using a newly constructed, legally validated benchmark.
Technical innovations
- Introduction of a novel, expert-validated temporal statutory QA benchmark of 312 German legal questions targeting post-cutoff staleness and recency bias, spanning single- and multi-provision temporal applications.
- Two novel retrieval-augmented generation methods (RAG-kNN and RAG-ToC) that enforce strict temporal validity by filtering statute retrieval strictly by the fact date extracted from queries, ensuring only legally applicable statute versions are provided as context.
- Use of an LLM-as-a-judge evaluation paradigm employing Gemini 3 Flash Preview LLM guided by a detailed rubric to reliably score temporal correctness components of legal QA at scale.
- Analysis and evidence demonstrating that naive web search augmentation introduces unstable temporal and recency bias, unlike curated temporally-filtered statutory retrieval.
- Pipeline for synthetic generation of temporally anchored legal QA pairs with fact dates aligned to specific statutory versions, demonstrating a principled approach to dataset construction targeting temporal legal reasoning.
Datasets
- Temporal Legal Benchmark (proposed) — 312 QA pairs — synthesized from buzer.de historical versions of six German federal statutes with expert validation
- buzer.de historical consolidated statutes — full corpus of German federal law with time-stamped versions (private/unofficial source)
Baselines vs proposed
- Vanilla LLM (Claude Sonnet 3.7) Post-Cutoff Questions: version application correctness = 0.08 vs RAG-ToC = 0.83
- Vanilla LLM (ChatGPT-5.1) Post-Cutoff Questions: version application correctness = 0.18 vs RAG-kNN = 0.88
- Web search augmented ChatGPT-5.1 on Post-Cutoff Questions: outcome correctness ≈ 0.25–0.67 vs RAG methods 0.78–0.88
- RAG-kNN vs RAG-ToC: no statistically significant difference across all metrics (p>0.05)
- Pre-Amendment Questions (ChatGPT-5.2) vanilla outcome correctness < 0.5 vs RAG methods > 0.8
- Multi-Provision Pre-Amendment Questions (Claude Opus 4.5) vanilla outcome correctness < 0.4 vs RAG methods > 0.75
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.23497.
Fig 1: Overview of Pipeline for Post-Cutoff Amendment
Fig 2: Overview of Pipeline for Multi-Provision Pre-
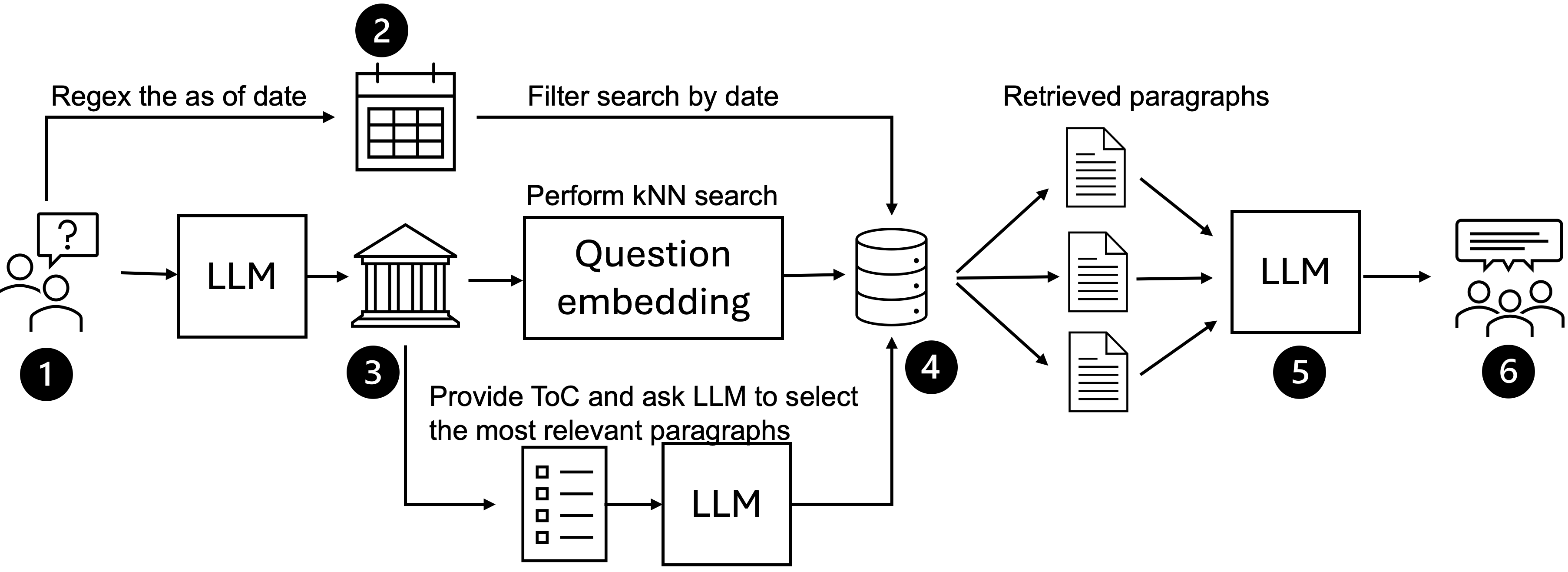
Fig 3: RAG-kNN and RAG-ToC
Limitations
- Dataset limited to German federal statutes from a private, unofficial legal data source (buzer.de), which may limit generalizability to other jurisdictions or official versions.
- Synthetic QA generation reliant on LLM prompting and legal expert revision; some legal nuance or real-world complexity may be underrepresented relative to authentic cases.
- No explicit adversarial evaluation on deliberately ambiguous temporal questions or intentional misleading fact patterns to stress-test model temporal robustness.
- Experiments focus on retrieval augmentation but do not explore incremental or continual learning approaches that update parametric knowledge longitudinally.
- Web search augmentation uses general search APIs leading to unstable results and recency biases; the pipeline does not control web data quality or temporal labeling rigorously.
- Reproducibility limited by reliance on proprietary models (ChatGPT, Claude, DeepSeek) and proprietary APIs for retrieval and embedding.
Open questions / follow-ons
- How can continual learning methods be integrated with temporal retrieval to further enhance temporal robustness without catastrophic forgetting?
- Can similar temporal failure modes and remediation strategies be generalized to common-law jurisdictions with precedent-based reasoning?
- What methods can be developed to detect temporal uncertainty to trigger abstention or human-in-the-loop review gracefully?
- How do temporal biases interact with semantic and doctrinal reasoning in large-context LLMs across complex multi-provision statutory interpretation tasks?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work underlines the importance of explicitly enforcing temporal validity constraints when using LLMs for specialized domains where underlying knowledge evolves, such as legal question answering. It demonstrates that naive reliance on static parametric knowledge, web search augmentation, or unfettered retrieval risks severe degradation or bias—analogous to CAPTCHAs issued for outdated challenges or relying on stale heuristics. Retrieval-augmented methods that filter context by temporal metadata provide a practical, effective strategy to maintain accuracy in time-sensitive applications. The evaluation methodology, including LLM-as-a-judge rubric-guided scoring, may inspire analogous approaches for measuring evolving challenges in bot-detection task validity over time.
Cite
@article{arxiv2605_23497,
title={ Asking For An Old Friend: Diagnosing and Mitigating Temporal Failure Modes in LLM-based Statutory Question Answering },
author={ Max Prior and Andreas Schultz and Matthias Grabmair },
journal={arXiv preprint arXiv:2605.23497},
year={ 2026 },
url={https://arxiv.org/abs/2605.23497}
}