
What Does the Caption Really Say? Counterfactual Phrase Intervention for Compositional Data Selection in Vision-Language Pretraining
Source: arXiv:2605.22651 · Published 2026-05-21 · By Hyejin Go, Semi Lee, Hyesong Choi
TL;DR
This paper addresses a key limitation in CLIP-style vision-language pretraining data curation, where conventional pair-level filtering based on global image-caption alignment saturates and fails to ensure that captions provide meaningful compositional supervision at the phrase level. The authors introduce Counterfactual Phrase Intervention (CPI), a novel phrase-level data curation method using controlled nonce-token substitutions within captions to measure the sensitivity of image-text similarity scores to individual object, attribute, or relation phrases. By applying CPI after coarse global alignment filtering, they identify a subset of training pairs with higher phrase-level sensitivity that yields stronger compositional generalization without changing model architecture or training loss. Experimental evaluations on CC3M-scale pretraining with CLIP ViT-B/32 show that CPI-based data selection improves phrase-sensitive compositional benchmarks such as VL-CheckList-VG Relation by +1.91 points over full data and +1.00 over alignment-only filtering at matched data budget (50%), while preserving or improving general transfer tasks. CPI also complements compositional objectives like NegCLIP and CE-CLIP when applied as a loss-orthogonal data-side intervention, further boosting relation-sensitive scores by +3.84 and +4.92 respectively. The work highlights the importance of selecting pretraining data with phrase-level compositional support rather than relying solely on pair-level global alignment scores.
Key findings
- Global image-caption alignment filtering saturates in compositional supervision after coarse mismatch removal, limiting further gains from stricter pair-level filtering (Table 1).
- Controlled nonce-token phrase substitutions produce phrase attribution scores (PAS) that measure first-order image-text similarity sensitivity to phrases, isolating meaningful compositional signals.
- Two-stage CPI pipeline, with top 70% global alignment filtering followed by phrase-level PAS ranking, selects a curated 50% subset (Ours50) that improves VL-CheckList-VG Relation by +1.91 vs Full and +1.00 vs Align-only top50 (matched budget).
- Ours50 improves SugarCrepe overall metric by +0.71 points and SugarCrepe Replace/Add Agg by +0.83 over full data; it also preserves or slightly improves ImageNet zero-shot and Flickr retrieval scores (Table 2 and 3).
- CPI is loss-orthogonal: applying Ours50 data to NegCLIP boosts VL-CheckList-VG Relation by +3.84 points, and to CE-CLIP by +4.92 points compared to their full-data baselines (Table 4).
- Normalized mean PAS is weakly correlated with global alignment scores (Pearson r=0.084), indicating CPI captures compositional signal orthogonal to pair-level alignment (Section 7).
- Nonce replacements meet the Three-Invariance Replacement Protocol with 99.79% coverage, minimizing confounding tokenization or syntactic effects.
- Mean aggregation of phrase PAS outperforms max-only and combined aggregations in selecting compositional data (Section 7).
Threat model
The adversary context is nonspecific noise or misleading captions within web-scale image-text data that degrade compositional visual-language learning. The adversary's capability equates to the presence of globally plausible but compositionally hollow captions that yield weak phrase-level supervision. The method assumes access to pretrained fixed image-text similarity scorers and does not address intentional adversarial attacks or direct model manipulation.
Methodology — deep read
Threat model & assumptions: The adversary is implicitly the noise or redundancy in web-scale image-caption pairs that degrades compositional supervision during pretraining. The assumption is that pair-level global image-text similarity scores can remove gross mismatches but cannot distinguish whether individual noun, adjective, or relation phrases are meaningfully supported by the image. The attacker/adversary model is thus nonspecific but framed as compositional noise within captions that weakens training.
Data: Experiments use a subset of Conceptual Captions 3M (CC3M) containing ~2.22 million image-caption pairs. They apply global alignment filtering with CLIP ViT-B/32, yielding 1.56 million pairs (top 70% by global score) as the Stage-1 pool (Dalign70). The final CPI-curated subset (Ours50) retains 50% of the original corpus (1.11 million pairs) after phrase-level ranking.
Architecture / algorithm: The fixed scoring model is OpenAI CLIP ViT-B/32 (and additionally ViT-B/16 in some experiments) used to measure image-text similarity. CPI operates offline using a controlled-substitution procedure: For each candidate phrase within a caption (object, attribute, or relation spans), a controlled nonce token substitute is generated preserving exact CLIP-BPE token count and syntactic surface form (capitalization, plural, possessive) but removing lexical semantics (Three-Invariance Replacement Protocol). The perturbed caption is scored by CLIP, and the phrase attribution score (PAS) is computed as the similarity drop caused by phrase replacement. This measures phrase-level sensitivity of the fixed scorer as a first-order controlled substitution effect. Sample-level CPI score aggregates all phrase PAS values by mean after normalizing across the Dalign70 pool.
Training regime: CLIP ViT-B/32 is pretrained on different subsets (Full, Full-Random50, Align-only top50, and Ours50) with fixed optimization hyperparameters: epochs, batch size, seeds, and learning rates are kept constant to isolate data selection effects. NegCLIP and CE-CLIP objectives are also evaluated with and without CPI-curated subsets.
Evaluation protocol: Performance is assessed on zero-shot ImageNet and CIFAR-10/100 classification, Flickr retrieval (R@1, R@5), linear probes, and compositionality benchmarks SugarCrepe, SugarCrepe++, and VL-CheckList-VG Relation. Metrics are mean ± stddev over two random seeds. Ablations study the PAS aggregation methods, pruning ratios, and correlations with alignment or text-only perturbations. Statistical significance is measured with sign tests.
Reproducibility: The method depends on publicly available CC3M and CLIP models, but the nonce substitution tokens and phrase extraction use deterministic rule-based procedures. The exact code or frozen weights are not explicitly stated as released. The procedure is offline and can be amortized across objectives.
Technical innovations
- Counterfactual Phrase Intervention (CPI): phrase-level controlled nonce-token substitution measuring first-order image-text similarity sensitivity to individual words or phrases in captions.
- Three-Invariance Replacement Protocol: a deterministic controlled substitution method preserving exact CLIP-BPE subtoken count, lexical semantics removal, and surface syntactic form (capitalization/plural/possessive) to isolate phrase sensitivity.
- Two-stage coarse-to-fine data curation pipeline using global alignment filtering followed by phrase-level PAS ranking to select compositional data subsets.
- Formulation of phrase-attribution score (PAS) as a first-order approximation of phrase-level compositional support distinct from global image-caption compatibility.
Datasets
- Conceptual Captions 3M (CC3M)-derived subset — 2,222,261 image-caption pairs — public web-crawled image captions
Baselines vs proposed
- Full (100%) data: VL-CheckList-VG Relation = 37.71 vs Ours50 (50%) = 39.62 (+1.91)
- Align-only top50 (50%): VL-CheckList-VG Relation = 38.62 vs Ours50 = 39.62 (+1.00)
- Full random 50%: SugarCrepe overall = 57.56 vs Ours50 = 58.49 (+0.93)
- NegCLIP Full: VL-CheckList-VG Relation = 37.72 vs NegCLIP Ours50 = 41.56 (+3.84)
- CE-CLIP Full: VL-CheckList-VG Relation = 32.72 vs CE-CLIP Ours50 = 37.64 (+4.92)
- Full vs Ours50 ImageNet zero-shot: 7.27 ± 0.07 vs 7.43 ± 0.01
- Align-only top50 vs Ours50 SugarCrepe++ Replace Avg: 47.26 ± 0.23 vs 47.61 ± 0.14
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.22651.
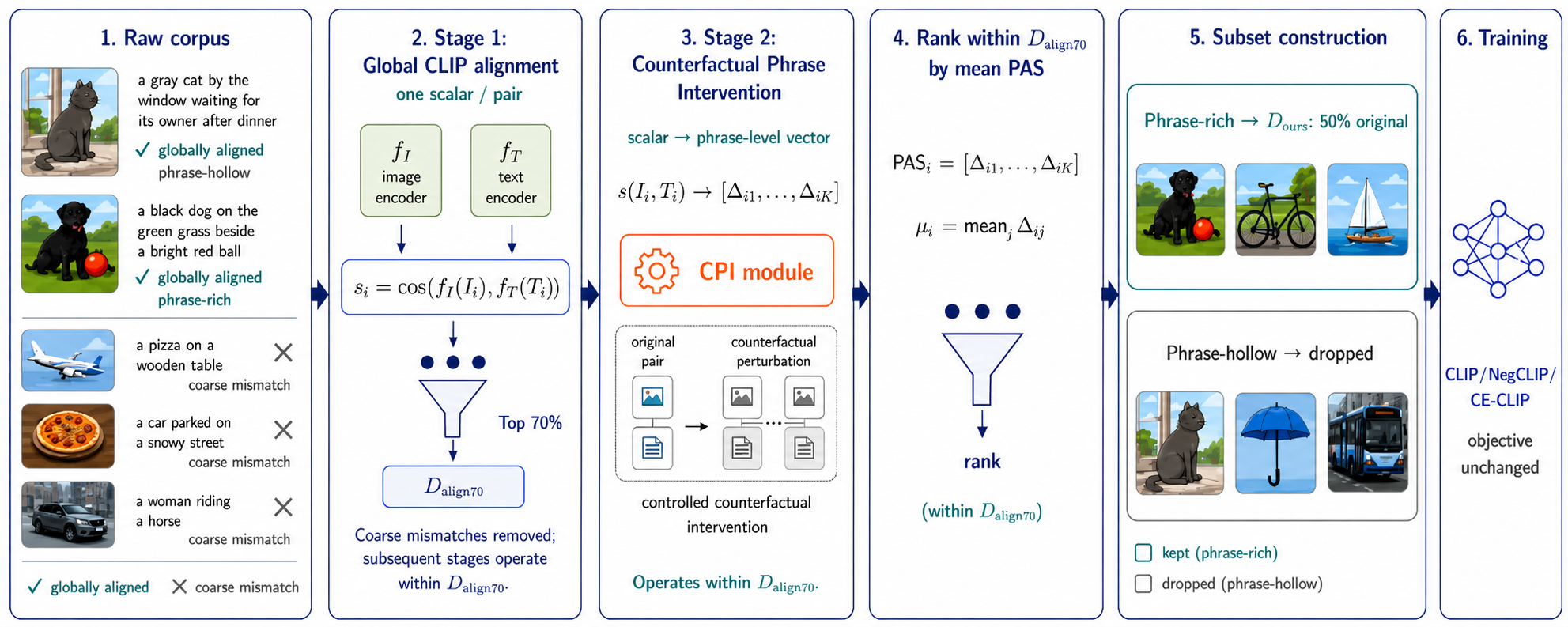
Fig 1: Overview of the coarse-to-fine CPI curation pipeline. Stage 1 filters coarse mismatches
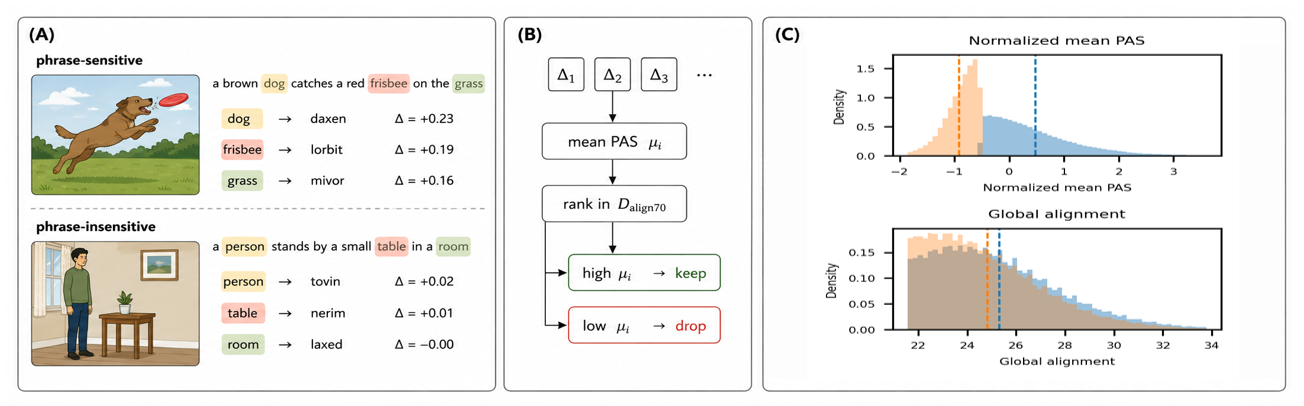
Fig 2: Stage 2 CPI scoring: illustration and empirical score distributions. (A) Controlled head-
Limitations
- PAS is a relative first-order sensitivity metric, not a grounding, localization, or causal identification signal for phrase visual presence.
- Dependence on the underlying CLIP model's scoring function; generalization to other vision-language scorers is untested.
- Rule-based phrase extraction and deterministic nonce generation may retain residual text-encoder artifacts that confound sensitivity measurement.
- Experiments confined to CC3M-scale subsets and CLIP ViT-B/32 architecture with limited training steps; scalability to large web-scale datasets or architectures (e.g., LAION, ViT-L/14) unknown.
- Effect sizes on compositional metrics are moderate and evaluation uses only two random seeds, limiting statistical power.
- No direct head-to-head comparisons with other caption-based or learned filtering methods (e.g., T-MARS, DFN, Sieve) under matched compute or budgets.
Open questions / follow-ons
- Does CPI phrase-level sensitivity scoring generalize to larger-scale datasets like CC12M or LAION, and bigger architectures (e.g., ViT-L/14)?
- Can the CPI framework improve compositional generalization when integrated with alternative or learned vision-language scorers beyond CLIP?
- How would CPI-curated data affect robustness to adversarial or distributional shifts not covered in current benchmarks?
- Can CPI be combined effectively with advanced learned filtering methods or active curation pipelines for further gains?
Why it matters for bot defense
For bot-defense and CAPTCHA engineers interested in vision-language model robustness, this work highlights the importance of training data quality—not just global sample alignment but phrase-level compositional support. Similar to challenges in detecting subtle bot behaviors, improving model sensitivity to fine-grained phrase-object relations can enhance semantic fidelity, reducing models' susceptibility to spurious correlations or simplistic cues that attackers might exploit. The CPI controlled substitution technique offers a promising offline data selection method to improve compositional generalization without modifying model architecture or objectives, which could be adapted to improve robustness of vision-language or multimodal models used in bot detection pipelines. However, the limited scale and dependency on fixed scoring models suggest the approach needs further validation in larger and more diverse real-world datasets pertinent to bot and CAPTCHA tasks.
Cite
@article{arxiv2605_22651,
title={ What Does the Caption Really Say? Counterfactual Phrase Intervention for Compositional Data Selection in Vision-Language Pretraining },
author={ Hyejin Go and Semi Lee and Hyesong Choi },
journal={arXiv preprint arXiv:2605.22651},
year={ 2026 },
url={https://arxiv.org/abs/2605.22651}
}