
Towards a General Intelligence and Interface for Wearable Health Data
Source: arXiv:2605.22759 · Published 2026-05-21 · By Girish Narayanswamy, Maxwell A. Xu, A. Ali Heydari, Samy Abdel-Ghaffar, Marius Guerard, Kara Vaillancourt et al.
TL;DR
This paper addresses the challenge of converting raw wearable sensor data into generalized, personalized health insights across a broad spectrum of conditions and populations. Traditional supervised models require costly labeled data and are often narrowly focused on specific health endpoints, limiting generalizability. To overcome this, the authors introduce SensorFM, a large-scale foundation model pretrained on over one trillion minutes of unlabeled multimodal wearable sensor data from 5 million participants across 20+ device types. SensorFM uses a self-supervised reconstruction objective to learn rich embeddings that generalize well to 35 downstream health tasks covering cardiovascular, metabolic, sleep, mental health, lifestyle, and demographic predictions.
By jointly scaling model capacity (up to 100 million parameters) and pretraining data volume by several orders of magnitude, SensorFM achieves near-linear improvements in both reconstruction quality and downstream discriminative task performance. The learned sensor representations show strong label efficiency, outperforming supervised baselines trained on engineered features across almost all tasks. The model also demonstrates powerful generative capabilities for imputing and forecasting missing sensor data, enabling more accurate estimation of daily health metrics even with substantial data gaps. Furthermore, an automated downstream head design framework driven by multiple LLM agents autonomously searches the space of predictive models on top of SensorFM embeddings, yielding substantial performance gains over simple linear heads. Finally, integrating SensorFM into a Personal Health Agent and evaluating against clinician ratings confirms improved relevance, personalization, and safety of health summaries compared to language-model-only baselines. Overall, this work represents the largest scale pretraining and broadest evaluation of foundation models for wearable health data, demonstrating the value of self-supervised large-scale sensor representations for scalable, context-aware health prediction and interpretation.
Key findings
- Pretraining on 1 trillion minutes (approx. 2 billion hours) of multimodal sensor data from 5 million participants led to near-linear improvements in reconstruction loss and downstream task performance as model capacity increased from 105 to 108 parameters.
- Largest SensorFM model (100M params) pretrained on full dataset reduced MSE reconstruction validation loss by 31% and improved generative task loss by 28% compared to smallest model (105 params).
- On 35 downstream discriminative health tasks, SensorFM embeddings outperformed supervised baselines trained on engineered features on 34/35 tasks (see Fig 1d, Table ED.9).
- Adding demographic features boosted performance on many tasks, but gains diminished as model scale increased, suggesting implicit encoding of physiological traits at scale (Table ED.8).
- Generative capabilities enable imputation of missing sensor data, with SensorFM surpassing baselines by 74.8% on random imputation and 83.7% on sensor imputation tasks (Table ED.10), retaining >99% accuracy on daily step and sleep estimates even with 60 mins missing data (Fig 1c).
- Scaling model and data together improves label efficiency, with larger SensorFM variants consistently outperforming baselines even at low labeled sample volumes (Fig ED.5).
- Agentic LLM-driven search of downstream prediction heads on SensorFM embeddings improved F1 or Pearson r on 28 of 35 classification and regression health tasks compared to linear heads (Fig 5, Table ED.12).
- Clinician evaluation (1,860 ratings across 31 real patient profiles) showed SensorFM-augmented Personal Health Agent responses had higher personalization, safety, and clinical relevance than language models processing wearable data directly (Fig 3c).
Threat model
n/a - This work focuses on learning generalizable representations from wearable sensor data for health prediction and does not explicitly model adversaries or threat scenarios.
Methodology — deep read
Threat Model & Assumptions: The paper does not focus on adversarial attacks but assumes wearable sensor data is passively collected from individuals with diverse health statuses. The model is designed to generalize representations capturing physiological and behavioral traits, implicitly assuming no manipulation of raw sensor streams.
Data: SensorFM was pretrained on a massive corpus of over one trillion minutes (approximately 2 billion hours) of multimodal wearable sensor data collected from 5 million participants across 20+ device types and 100+ countries. Five sensor modalities were used: accelerometer, altitude, electrodermal activity (EDA), heart rate/heart rate variability (HR/HRV), SpO2, temperature, and sleep data. Downstream evaluation used curated, rigorously phenotyped datasets from three prospective studies totaling 13,985 individuals, annotated across 35 clinical and behavioral health tasks including cardiovascular, metabolic, mental health, sleep, lifestyle factors, and demographics. Data was split for pretraining validation and downstream cross-validation. Preprocessing handled missingness inherent in wearable data.
Architecture / Algorithm: SensorFM leverages a masked autoencoder (MAE)-style architecture tailored for multimodal time series. It encodes 24-hour windows of minute-resolution sensor data via a bottleneck embedding, training to reconstruct ablated inputs using a latent representation capturing global physiological signals. Models varied in scale from 105 to 108 parameters (XXSmall to Base). Training used a self-supervised reconstruction objective that models nonlinear temporal dynamics and missing segments. No labels were used during pretraining.
Training Regime: Pretraining involved co-scaling model capacity and data volume by orders of magnitude (from 5K to 5M subjects, and 105 to 108 params). Larger models were trained on more data for more compute cycles, achieving stable convergence and improved validation loss. Downstream linear heads reduced embeddings to 50 principal components to avoid overfitting, trained with standard supervised objectives on each downstream task. Exact optimizer, epochs, batch sizes, seed strategies, and hardware were not detailed in the summary but likely leveraged Google Research infrastructure.
Evaluation Protocol: Evaluation employed held-out validation sets for pretraining reconstruction loss and metrics on 35 downstream classification and regression tasks. Metrics included ROC AUC and Pearson correlation for respective tasks, averaged over 5-fold cross-validation. Performance was compared against strong baselines including supervised models trained on engineered sensor features and demographic-only models. Ablation with and without demographics assessed model reliance on priors. Generative capabilities were benchmarked on sensor data imputation and forecasting tasks, measuring percent improvement over baselines. Agentic LLM search was benchmarked by comparing performance of automated heads to linear probes across tasks.
Reproducibility: The paper does not state public code or pretrained weights release explicitly, and large-scale sensor datasets are typically proprietary or privacy-sensitive. However, detailed tables and figures enable comparison and replication in principle given access to similar data and compute infrastructure.
Example End-to-End Use Case: Raw minute-resolution wearable data streams from 5 million participants worldwide were collected across multiple sensor types. SensorFM was pretrained with a masked autoencoder objective to reconstruct missing signals, learning a 100 million parameter embedding model. This learned embedding was then frozen and fed to a low-dimensional linear model trained to predict metabolic syndrome risk in a labeled cohort of ~1,600 participants. Performance was evaluated by ROC AUC against a baseline model trained on summary features, showing a significant performance improvement, thus demonstrating transfer from massive unlabeled pretraining to a clinically relevant outcome prediction.
Technical innovations
- Pretraining a masked autoencoder large foundation model on an unprecedented scale of over one trillion minutes of raw, unlabeled multimodal wearable sensor data from 5 million participants.
- Joint scaling of both model capacity (up to 100 million parameters) and pretraining data volume by 50x demonstrating near-linear improvements in reconstruction and downstream task predictive performance.
- Leveraging self-supervised reconstruction to natively handle missingness and heterogeneity common in wearable sensor streams, enabling robust generative capabilities for imputation and forecasting.
- Design of an autonomous 'classroom' of collaborative and competitive LLM agents that iteratively generate and optimize downstream predictive heads on top of frozen SensorFM embeddings, substantially improving prediction performance without manual feature engineering.
- Integration of the SensorFM embeddings with a Personal Health Agent system, validated with extensive clinician ratings to improve response safety, personalization, and clinical relevance compared to language-model-only baselines.
Datasets
- Unlabeled Wearable Sensor Data — 1 trillion minutes (~2 billion hours) — collected from 5 million participants across 100+ countries and 20+ device types (proprietary)
- Prospective Clinical & Behavioral Datasets — 13,985 participants — annotated across 35 health tasks including metabolic, mental health, cardiovascular, sleep, lifestyle, and demographic factors (combination of clinical studies and self-report)
Baselines vs proposed
- Supervised model trained on engineered sensor features: average ROC AUC and Pearson correlation across 35 tasks; SensorFM embeddings improved performance on 34/35 tasks.
- Demographic-feature-only baseline: SensorFM embeddings outperformed on 24/30 tasks; dependence on demographics decreased with model scale.
- Smallest SensorFM variant (105 params) & smallest data (2 million hours): baseline for scaling comparison; largest variant (100M params, 2 billion hours) reduced reconstruction MSE by 31%, improved generative task loss by 28%, and increased downstream classification ΔAUC by 0.09 and regression Δr by 0.21.
- Generative imputation baseline: SensorFM improved random imputation error by 74.8%, temporal interpolation by 38.8%, temporal extrapolation by 39.6%, and sensor imputation by 83.7%.
- Agentic model design: automated heads had improved F1 scores on 16/20 classification and Pearson r on 12/15 regression tasks compared to linear probes.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.22759.

Fig 1: | Scaling and Evaluating a Sensor Foundation Model (SensorFM) for Wearable Health.

Fig 2: | Intelligent Search of Prediction Heads. We employ an LLM-driven architecture to
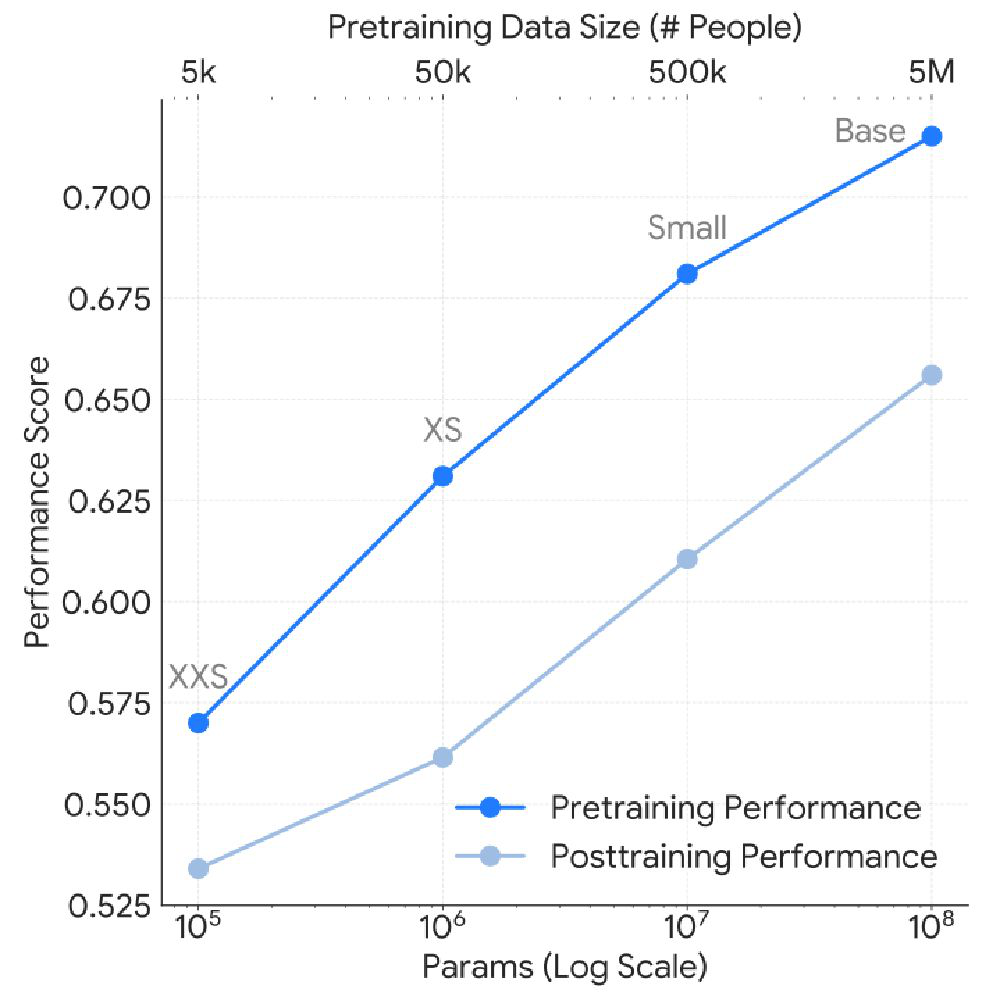
Fig 3 (page 3).

Fig 4 (page 3).
Fig 5 (page 3).
Fig 6 (page 3).
Fig 3: | Agentic Use of SensorFM as a Tool. (a) Architecture of the SensorFM-augmented workflow,
Fig 8 (page 5).
Limitations
- No explicit adversarial robustness or security analysis of model embeddings or downstream predictors, limiting understanding of model behavior under attack or data manipulation.
- Lack of publicly available dataset and pretrained weights limits reproducibility and external validation.
- Pretraining relies heavily on data from a specific set of consumer-grade wearable devices, which may limit generalization to other sensor types or clinical settings.
- Downstream evaluation focuses primarily on linear or agentically designed heads atop frozen embeddings without end-to-end finetuning, which might underestimate potential performance gains.
- Interpretability analysis is limited to dimensionality reduction and SHAP on linear heads; more granular insights on how physiological signals map to embeddings remain underexplored.
- While clinicians evaluated predicted health summaries, user-centric evaluations or long-term clinical impact remain to be studied.
Open questions / follow-ons
- How robust are SensorFM embeddings and downstream predictors to adversarial manipulation or spoofed wearable sensor signals?
- Can end-to-end finetuning of SensorFM improve performance further on specific health endpoints compared to frozen embeddings plus prediction heads?
- What are the limits of model generalization across devices with different sensor modalities and sampling frequencies not seen during pretraining?
- How effectively can these large-scale foundation models be adapted to personalized continuous health monitoring and real-time intervention delivery?
Why it matters for bot defense
For bot-defense or CAPTCHA practitioners, this research offers insights into how self-supervised large-scale sensor data pretraining can produce rich, generalizable embeddings from noisy, heterogeneous time-series data. The study’s approach to jointly scaling data and model capacity and leveraging downstream task-specific agentic model design could inspire analogous strategies for robust user behavior modeling, anomaly detection, or human-bot interaction classification in real-world CAPTCHA systems. Their generative model’s handling of missing or corrupted signals also parallels challenges in modeling incomplete or adversarial web traffic data. Moreover, the clinical evaluation to ensure contextual relevance and safety underscores the importance of human-in-the-loop validation in sensitive AI applications, a principle that resonates in secure, user-friendly bot defense design. While the data domain differs, the foundational approach to scalable, universal, multimodal representation learning holds valuable methodological lessons for designing resilient machine learning models robust to interaction variability and user diversity.
Cite
@article{arxiv2605_22759,
title={ Towards a General Intelligence and Interface for Wearable Health Data },
author={ Girish Narayanswamy and Maxwell A. Xu and A. Ali Heydari and Samy Abdel-Ghaffar and Marius Guerard and Kara Vaillancourt and Zhihan Zhang and Jake Garrison and Levi Albuquerque and Dimitris Spathis and Hong Yu and Hamid Palangi and Xuhai "Orson" Xu and David G. T. Barrett and Joseph Breda and Jed McGiffin and Yubin Kim and Yuwei Zhang and Naghmeh Rezaei and Samuel Solomon and Karan Ahuja and Tim Althoff and Jake Sunshine and Ming-Zher Poh and Benjamin Yetton and Ari Winbush and Nicholas B. Allen and James M. Rehg and Isaac Galatzer-Levy and Yun Liu and John Hernandez and Anupam Pathak and Conor Heneghan and Yuzhe Yang and Ahmed A. Metwally and Pushmeet Kohli and Mark Malhotra and Shwetak Patel and Xin Liu and Daniel McDuff },
journal={arXiv preprint arXiv:2605.22759},
year={ 2026 },
url={https://arxiv.org/abs/2605.22759}
}