
Synthetic Data Alone is Enough? Rethinking Data Scarcity in Pediatric Rare Disease Recognition
Source: arXiv:2605.22767 · Published 2026-05-21 · By Ganlin Feng, Yuxi Long, Erin Lou, Lianghong Chen, Zihao Jing, Pingzhao Hu et al.
TL;DR
This paper addresses the critical challenge of data scarcity in pediatric rare disease recognition using facial images, where real datasets are extremely limited due to privacy concerns and difficulty sharing sensitive pediatric data. The authors investigate whether models trained exclusively on synthetic pediatric facial images can achieve comparable performance to those trained on real data, a setting not systematically studied before. Using phenotype-aware synthetic data generated by DreamBooth on the RDFace dataset, they conduct controlled experiments training multiple backbone architectures at varying synthetic data scales.
They find that synthetic-only training achieves performance approaching or even exceeding real-data baselines for certain architectures such as FaceNet and CLIP, especially at intermediate synthetic dataset sizes (around 6K to 8K samples). Performance improves consistently with scale up to a point but degrades beyond 10K samples, likely due to lower-quality or redundant synthetic images. This demonstrates that high-fidelity synthetic facial images can approximate clinically meaningful distributions, enabling privacy-preserving visual resources for training clinicians and supporting genetic education and counseling. Their results highlight synthetic data alone as a viable training resource under ultra-low-resource conditions in pediatric rare disease recognition.
Key findings
- Synthetic-only training on RDFace-Syn synthetic data matches or exceeds real-data-only baselines on Top-1 accuracy for FaceNet (13.27% synthetic vs. 9.91% real) and CLIP (10.62% vs. 3.10%) at larger scales (8K samples).
- Performance peaks at 6K–8K synthetic samples per condition across backbones; increasing beyond 10K samples causes accuracy degradation (e.g., ResNet Top-1 drops from 7.08% at 8K to 3.54% at 10K).
- Different backbone architectures vary in sensitivity to synthetic-only training; DenseNet performs notably worse than real data baseline (11.50% vs. 15.93% Top-1 accuracy at 8K).
- Top-5, Top-10, and Top-30 accuracies for synthetic-only training closely approach real-data performance across multiple backbones, showing consistent trends across varying k.
- Synthetic samples are ranked by cosine similarity to real class prototypes and top-ranked samples are used to construct training sets, highlighting the importance of quality-based sample selection.
- The RDFace-Syn dataset contains 10,300 synthetic images across 103 rare genetic conditions, with 100 synthetic images class-wise generated from few real samples using DreamBooth diffusion models.
- Models are trained and validated under a controlled 5-fold cross-validation regime and evaluated on a held-out real-image test set to ensure fair comparison.
- Synthetic facial images enable scalable, privacy-preserving visual resources for genetic counseling and educational workflows to improve clinician recognition skills.
Threat model
The study assumes a data-constrained clinical setting where real pediatric facial images are scarce and subject to strict privacy constraints preventing sharing or aggregation. The adversary is not adversarial in a security sense; rather the threat is severe data scarcity and privacy barriers limiting access to usable training data. Synthetic data is proposed as a privacy-preserving substitute, assuming attackers cannot reverse-engineer the synthetic faces to reveal identities or leak real patient information. The model evaluates utility under these restricted access conditions.
Methodology — deep read
The authors aim to rigorously study the use of synthetic data alone for pediatric rare disease facial recognition under extreme data scarcity and privacy constraints.
Threat model & assumptions: The adversary here is not explicitly defined since this is medical ML research focusing on privacy-preserving data usage rather than attack-defense. The key assumption is that real patient data is extremely limited and cannot be shared freely, motivating synthetic data generation as a privacy-safe alternative.
Data provenance and splits: The study uses RDFace-Syn, a synthetic dataset derived from the RDFace benchmark containing pediatric rare disease facial images. RDFace-Syn is generated via DreamBooth, a diffusion-based model fine-tuned per disease class using very limited real samples. It includes 10,300 images spanning 103 rare genetic conditions (100 synthetic images per class). The held-out test set comes from real RDFace data, allowing evaluation of synthetic training on real test examples to measure generalization.
Architecture/algorithm: Six backbone architectures are evaluated: ResNet152, DenseNet169, FaceNet, VGG16, Swin-T transformer, and CLIP (ViT-B/32). The classification head is replaced with a 103-way softmax to predict disease classes. Synthetic samples are ranked by cosine similarity of their facial landmark representations to real class prototypes; the training sets are constructed by selecting the top-n ranked synthetic samples per class to study scale effects.
Training regime: Input images are resized to 224×224 and normalized using ImageNet statistics. Models are trained using a unified pipeline with hyperparameters selected via 5-fold cross-validation on the synthetic training data. The same protocol applies for real-only baseline runs. Specific training epochs, batch sizes, optimizers, or seeds are not detailed, which limits reproducibility resolution.
Evaluation protocol: Models trained solely on synthetic images at various dataset sizes (2K, 4K, 6K, 8K, 10K samples) are evaluated for Top-1, Top-5, Top-10, and Top-30 classification accuracy on a held-out real-image test set. Comparisons are made versus models trained on equivalent real data only. Mean and standard deviation across folds are reported.
Reproducibility: RDFace-Syn dataset is a publicly documented synthetic dataset, and backbones are standard architectures. Code and exact training configurations are not explicitly mentioned, so full replication is unclear. The ranking scheme for synthetic samples selection adds an additional layer needing careful reproduction.
Concrete example: For the FaceNet backbone, models trained on top 8000 synthetic images selected by cosine similarity reach a Top-1 accuracy of 13.27%, surpassing the real-only baseline accuracy of 9.91%. This shows that at this scale and architecture, synthetic training effectively captures disease-relevant visual patterns. Increasing synthetic samples beyond this (to 10K) decreases accuracy to 9.73%, indicating diminishing returns or noise.
Overall, the methodology is a controlled, systematic empirical study isolating the utility of synthetic data alone by large-scale quantitative testing across multiple backbones and dataset scales with fair evaluation against held-out real data.
Technical innovations
- Systematic study of training deep models exclusively on phenotype-aware synthetic pediatric facial images, isolating synthetic-only data effects.
- Use of a ranking method based on cosine similarity of synthetic samples to real class prototypes to select high-quality synthetic data for scalable experiments.
- Evaluation of synthetic-only training across multiple deep architectures under a unified protocol with increasing synthetic data scales.
- Demonstration that synthetic data at intermediate scale (6K–8K) can match or exceed real-data baseline performance in pediatric rare disease recognition.
Datasets
- RDFace-Syn — 10,300 synthetic facial images — synthetic images generated per-class using DreamBooth diffusion model fine-tuned from limited real RDFace pediatric rare disease samples
- RDFace (held-out real test set) — not quantified here in detail — public pediatric rare disease facial dataset
Baselines vs proposed
- FaceNet real-only baseline Top-1 accuracy = 9.91% vs synthetic-only (8K) = 13.27%
- CLIP real-only baseline Top-1 accuracy = 3.10% vs synthetic-only (8K) = 10.62%
- DenseNet real-only baseline Top-1 accuracy = 15.93% vs synthetic-only (8K) = 11.50%
- Swin-T real-only baseline Top-1 accuracy = 14.34% vs synthetic-only (8K) = 12.39%
- ResNet real-only baseline Top-1 accuracy = 6.90% vs synthetic-only (8K) = 7.08%
- VGG real-only baseline Top-1 accuracy = 11.68% vs synthetic-only (8K) = 9.73%
- Performance drops beyond 8K synthetic samples: e.g., ResNet Top-1 drops from 7.08% (8K) to 3.54% (10K)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.22767.
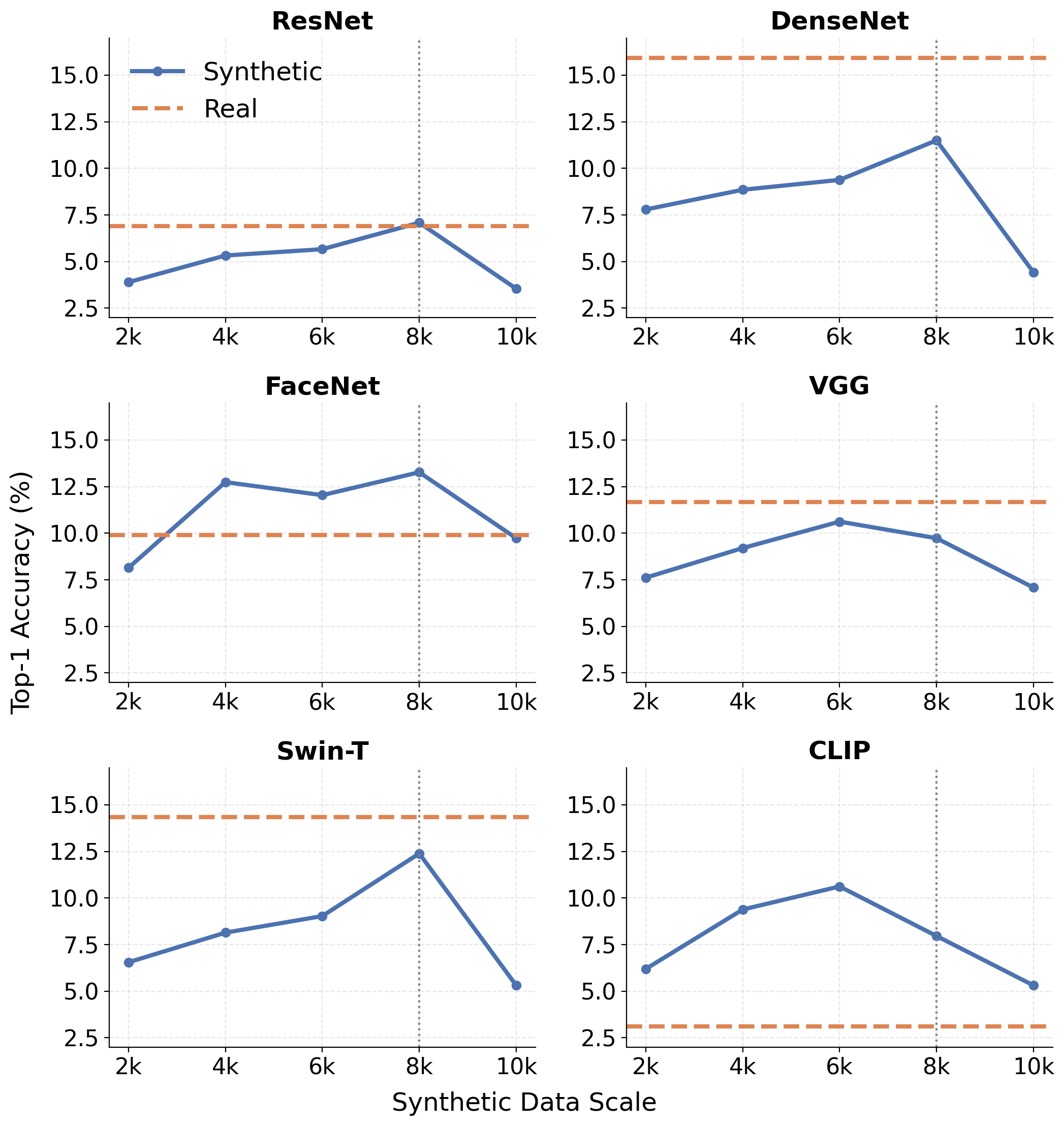
Fig 1: Top-1 accuracy versus synthetic data scale for six
Fig 2: Educational workflow for rare disease. Learners are provided with resources and tasked with classifying facial images.
Limitations
- Performance varies significantly by backbone architecture; not all models match or exceed real data performance under synthetic-only training.
- Synthetic data quality decreases when scaled beyond 8K samples due to ranking strategy including lower-quality or redundant samples.
- No detailed adversarial evaluation or robustness tests against distribution shifts were conducted.
- Exact training details like optimizer settings, epochs, batch sizes, and seeds are missing, impeding exact replication.
- The synthetic dataset is generated conditioned on real samples, limiting exploration of fully novel synthetic generation.
- Evaluation relies on classification accuracy only; clinical impact and usability require further user studies.
Open questions / follow-ons
- How can synthetic data fidelity and diversity be improved to avoid performance degradation at large scales beyond 8K samples?
- Can architecture-aware training techniques be developed to better align synthetic data with varying model backbones for improved performance?
- What is the clinical utility and acceptance of synthetic facial datasets validated through user studies with genetic counselors and clinicians?
- How robust are synthetic-only trained models under real-world distribution shifts and adversarial conditions?
Why it matters for bot defense
This work provides insightful evidence about the effectiveness of synthetic data alone to train models for high-stakes, privacy-sensitive visual recognition tasks under extreme data scarcity. For bot-defense and CAPTCHA engineers, the findings highlight that sufficiently high-fidelity synthetic visual data—carefully filtered and scaled—can substitute for scarce real data in training robust classifiers. In adversarial or privacy-constrained environments, this suggests synthetic data generation and ranking could be used to build classifier training sets without risking direct exposure of sensitive or proprietary user images.
Furthermore, the degradation of performance when synthetic data scales too large without quality controls warns that practitioners should monitor data quality alongside quantity in synthetic data pipelines. The emphasis on multi-backbone evaluation illustrates that synthetic data utility is not uniform across architectures, advising careful selection and tuning of model design when deploying synthetic-only regimes for bot detection or CAPTCHA classification. Lastly, the study's approach of rigorous evaluation against held-out real references and scalable synthetic set construction offers a replicable methodology for CAPTCHA researchers aiming to rely on synthetic data under privacy or data scarcity constraints.
Cite
@article{arxiv2605_22767,
title={ Synthetic Data Alone is Enough? Rethinking Data Scarcity in Pediatric Rare Disease Recognition },
author={ Ganlin Feng and Yuxi Long and Erin Lou and Lianghong Chen and Zihao Jing and Pingzhao Hu and Wei Xu },
journal={arXiv preprint arXiv:2605.22767},
year={ 2026 },
url={https://arxiv.org/abs/2605.22767}
}