
RADAR: Defending RAG Dynamically against Retrieval Corruption
Source: arXiv:2605.22041 · Published 2026-05-21 · By Ziyuan Chen, Yueming Lyu, Yi Liu, Weixiang Han, Jing Dong, Caifeng Shan et al.
TL;DR
This paper addresses the vulnerabilities of Retrieval-Augmented Generation (RAG) systems used in dynamic web search to evolving adversarial attacks, such as corpus poisoning and prompt injection. Unlike static defenses designed for fixed document corpora, RADAR is explicitly tailored for continuous time-evolving settings where the retrieval corpus changes and attacks mutate over time. RADAR models the problem of selecting reliable retrieved documents as a graph-based energy minimization, exactly solved via Max-Flow Min-Cut, enabling principled and efficient inference. A novel Bayesian memory node incorporates temporal continuity by recursively updating a belief state rather than storing raw historical documents, elegantly balancing robustness against attacks with adaptive responsiveness to genuine knowledge updates. The authors create a new dynamic evaluation benchmark with temporally indexed adversarial injections and demonstrate that RADAR achieves substantially better robustness (lower attack success rates) and accuracy trade-offs than strong baselines under both static and dynamic adversarial conditions, and across multiple LLM generators and retrieval depths.
Key findings
- RADAR achieves 75.0% answer accuracy with 5.0% attack success rate (ASR) on RealTimeQA (RQA) under Prompt Injection Attack (PIA) at position 10 with top-k = 10, outperforming baselines like RobustRAG and ReliabilityRAG by 6-9% accuracy or lower ASR (Table 1).
- On the Bio long-form generation task, RADAR maintains high factual accuracy (up to 84.4% under PIA at position 50 with top-k = 50), far surpassing Vanilla RAG accuracy of 10.2% in the same setting (Table 2).
- In dynamic evolving attack experiments with cumulative snapshot evidence and top-k = 50, RADAR sustains 63.60% accuracy with 17.85% ASR under the strongest Pos 1 PIA attack, compared to baselines showing both lower accuracy and higher ASR (Table 3).
- The Bayesian memory node allows RADAR to balance stability and plasticity, reducing oscillations caused by sparse or noisy evidence, which is critical for robustness in dynamic settings (§4.3).
- RADAR requires minimal extra storage compared to snapshot-based defenses that store all historical documents, yet improves both response quality and robustness significantly (Abstract, §1).
- The graph construction encodes semantic entailment and contradiction via an NLI model into edge capacities, establishing exact equivalence between energy minimization and min-cut, ensuring globally optimal consistent document selection (§4.1-4.2).
- RADAR outperforms heuristic and approximate selection baselines by guaranteeing exact and efficient inference using max-flow min-cut algorithms (Fig 1, §4).
- Post-processing with a similarity threshold λ to drop inconsistent atomic answers improves semantic coherence without sacrificing recall (Appendix G).
Threat model
An adversary who can continuously inject or optimize malicious documents into the external retrieval corpus to increase the likelihood of retrieving poisoned content at specific ranks, aiming to mislead the LLM into producing incorrect or harmful outputs. The attacker has black-box query access and knowledge of the general retrieval workflow and corpus, but cannot modify internal model parameters, intercept queries, or directly alter the model’s generation process.
Methodology — deep read
The authors consider adversaries who can inject or optimize malicious documents into the evolving RAG retrieval corpus to subtly corrupt answers without direct access to model internals or queries—only black-box query access is assumed (§3.2). The attacker’s knowledge includes the approximate external knowledge base and retrieval methods.
Data includes four static QA datasets for initial evaluation—RealTimeQA (RQA), Natural Questions (NQ), TriviaQA (TQA), and Bio long-form biographies. For dynamic evaluations, they construct a new dataset of 500 dynamic questions with temporally indexed web page retrieval snapshots via SerpApi, injecting adversarial documents and prompt injections to simulate evolving attacks (§5.1).
RADAR first generates atomic answers per retrieved document using an LLM. It then computes entailment (M) and contradiction (C) matrices between these atomic answers with a pretrained NLI model (DeBERTa-v3 based), producing pairwise semantic relationships (§4.1, 4.2).
A directed graph G=(V,E) is constructed with source (s), sink (t), and a node per document. Edge capacities encode unary potentials—source edges measure each document’s alignment with global semantic consensus (via eigenvector centrality and retrieval rank), while sink edges encode contradiction weighted by centrality. Dense inter-document edges encode pairwise entailment to enforce logical consistency through penalties on conflicting label assignments (§4.2).
The energy minimization problem over document labels (select reliable or not) corresponds exactly to finding a minimum s-t cut in G. Max-flow min-cut algorithms compute the global optimum partition efficiently. The source-side documents form the reliable evidence set for final generation. A post-processing step filters out low-coherence atomic answers based on cosine similarity to protect semantic integrity (§4.2).
For dynamic defense, a memory node representing the prior timestep’s reliable answer is added to the graph, connected to source and sink with capacities computed via a Bayesian update combining prior belief and new evidence entailment/contradiction scores. This enables RADAR to adaptively retain or discard historical information, balancing the stability-plasticity tradeoff in time-evolving contexts (§4.3).
Training is not the focus since the approach uses off-the-shelf NLI and LLM models. Instead, the pipeline is a deterministic graph construction and inference mechanism operating on retrieved documents and atomic answers for each query/timestep.
Evaluation spans static and dynamic scenarios, measuring answer accuracy and attack success rate against strong adversarial baselines (RobustRAG, AstuteRAG, InstructRAG, ReliabilityRAG). Experiments vary top-k retrieval depths (10, 50), injection positions, attack types (PIA, poisoning), and generators (DeepSeek, GPT-4o, Grok-4-fast). Ablations include historic evidence usage strategies in dynamic settings (cumulative snapshot vs lightweight memory). Metrics specific to long-form generation include relevance and coherence scored via LLM-based judges (§5).
The method is fully reproducible with code released. Datasets for the novel dynamic evaluation are newly introduced but not public. The paper provides detailed appendix sections on graph proof, NLI scoring, atomic generation, and hyperparameter settings.
A concrete run example is: at time t, retrieve top-k documents; generate atomic answers; compute semantic matrices; build graph, adding memory node if t>0; solve min-cut to select reliable documents; post-process for coherence; synthesize final answer from selected atoms; update belief priors for next timestep. This cycle repeats sequentially in dynamic deployment (§4, Algorithm 1).
Technical innovations
- Reformulating reliable document selection in RAG as a graph-based energy minimization exactly solved by Max-Flow Min-Cut, guaranteeing globally optimal consistent context selection.
- Introducing a Bayesian memory node into the graph to recursively update belief states for dynamic temporal consistency and automatic balance of stability versus plasticity in evolving evidence streams.
- Leveraging semantic entailment and contradiction relations computed by a pretrained NLI model to construct pairwise potentials in the graph optimization, enabling intuitive logical consistency enforcement.
- Proposing a novel dynamic dataset and evaluation benchmark for adversarial robustness analysis in continuously evolving RAG scenarios.
Datasets
- RealTimeQA (RQA) — unspecified size — public QA benchmark
- Natural Questions (NQ) — standard dataset — public Wikipedia-based QA
- TriviaQA (TQA) — standard dataset — public evidence-grounded trivia QA
- Bio dataset — unspecified size — public Wikipedia biographies
- Dynamic time-evolving QA benchmark — 500 questions with temporally indexed web search evidence and injected adversarial artifacts — constructed by authors, not publicly released
Baselines vs proposed
- Vanilla RAG: Acc = 75.0% benign, ASR unreported; RADAR: 75.0% acc, 5.0% ASR under PIA Pos 10 (top-k=10) on RQA
- AstuteRAG: Acc = 69.0%, ASR = 15.0% vs RADAR: 69.0%, 11.0% ASR under PIA Pos 1 (top-k=10)
- RobustRAG: Acc = 62.0%, ASR=13.0% vs RADAR: 70.0%, 11.0% ASR under Poison Pos 1 (top-k=10)
- ReliabilityRAG: Acc = 70.0%, ASR=14.0% vs RADAR: 70.0%, 11.0% ASR under Poison Pos 1 (Top-k=10)
- RADAR outperforms all baselines with highest accuracy and lowest ASR across multiple attack types and positions, especially notable in Bio long-form QA (Acc 84.4% vs Vanilla 10.2% under PIA Pos50 top-k=50)
- In dynamic setting with cumulative snapshot, RADAR achieves 63.60% accuracy and 17.85% ASR under Pos 1 PIA attack vs RobustRAG’s 61.29% and 18.62% ASR (Table 3)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.22041.
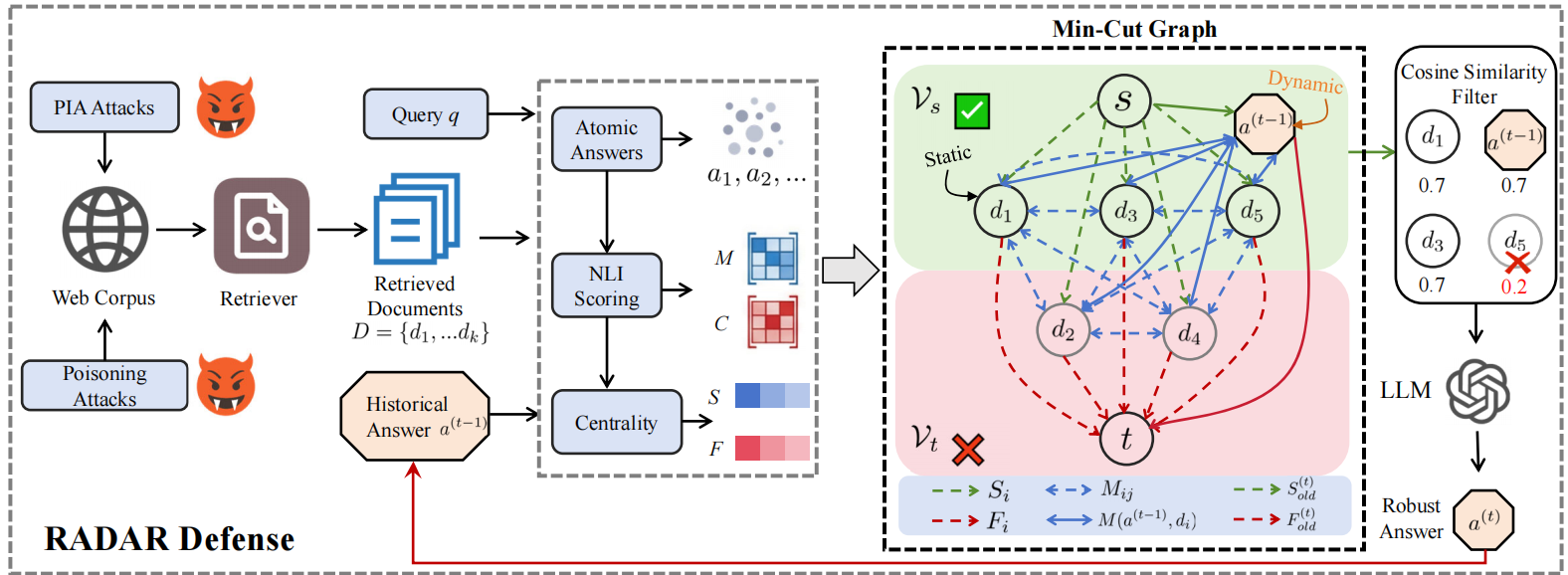
Fig 1: Overview of RADAR. It generates an atomic answer for each retrieved document, scores entailment and contradiction using an
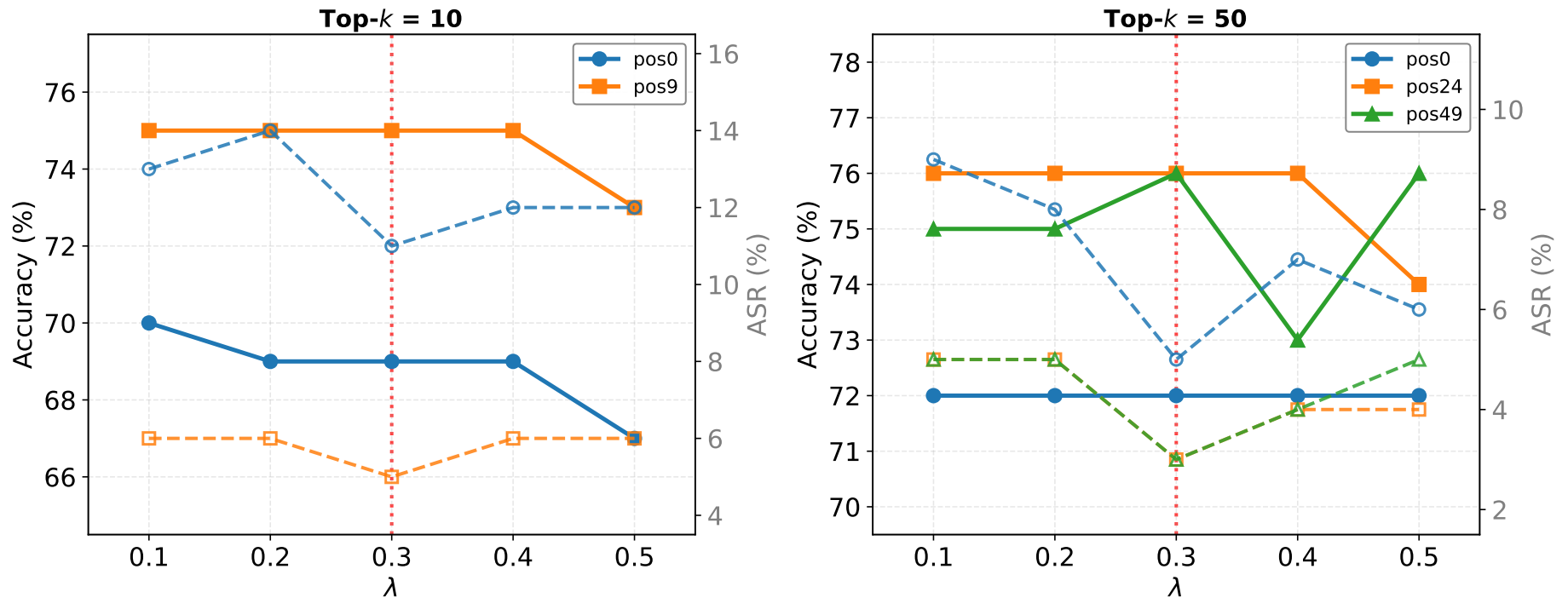
Fig 2: Sensitivity of the post-processing threshold λ.
Limitations
- Dependence on pretrained NLI model quality: errors in entailment or contradiction scoring could reduce defense effectiveness.
- Dynamic dataset constructed by authors is not yet publicly available, limiting reproducibility by other researchers.
- Evaluation primarily on retrieval and generation pipelines with three LLMs; results may vary with other models or languages.
- Assumes attackers have only black-box access, not stronger white-box or system-level control.
- No explicit adversarial training or model fine-tuning, meaning extremely sophisticated adaptive attacks may circumvent defenses.
- Storage and computation overheads of graph construction and Min-Cut solving scale with retrieved documents, though claimed minimal compared to snapshot storage.
Open questions / follow-ons
- How does RADAR perform against stronger attackers with partial white-box access or model parameter knowledge?
- Can the Bayesian memory node framework be extended to incorporate richer temporal dynamics beyond single-step history?
- How robust is RADAR to errors or biases in the pretrained NLI model used to score entailment and contradiction?
- What are the trade-offs between computational overhead and robustness at larger retrieval sizes (e.g., top-k > 50) in real-time systems?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, RADAR exemplifies a rigorous approach to defending multi-turn, dynamically updated knowledge-augmented LLM systems against corpus poisoning and retrieval corruption. Its graph-based exact inference avoids heuristic approximations common in prior work, offering a provably consistent mechanism to select trustworthy context. The Bayesian memory node foresightfully balances adherence to historically reliable information with adaptability for genuine content shifts, a crucial design consideration for temporal adversarial robustness. Although focused on RAG, analogous concepts in evidence validation and dynamic context filtering could inspire more robust challenge-response protocols in bot detection systems leveraging continuously refreshed knowledge.
Practitioners should consider how temporal evidence reliability mechanisms like RADAR’s may complement traditional CAPTCHA defenses to better handle evolving adversarial tactics that manipulate auxiliary information sources rather than the bot interaction itself. This work also highlights the utility of formal graph-based optimizations and semantic entailment modeling as tools to systematically quantify and mitigate adversarial influence in retrieval-augmented AI pipelines, which increasingly underpin sophisticated bot behaviors and language-based threat vectors.
Cite
@article{arxiv2605_22041,
title={ RADAR: Defending RAG Dynamically against Retrieval Corruption },
author={ Ziyuan Chen and Yueming Lyu and Yi Liu and Weixiang Han and Jing Dong and Caifeng Shan and Tieniu Tan },
journal={arXiv preprint arXiv:2605.22041},
year={ 2026 },
url={https://arxiv.org/abs/2605.22041}
}