
MambaGaze: Bidirectional Mamba with Explicit Missing Data Modeling for Cognitive Load Assessment from Eye-Gaze Tracking Data
Source: arXiv:2605.22775 · Published 2026-05-21 · By Amir Mousavi, Mohammad Sadegh Sirjani, Erfan Nourbakhsh, Mimi Xie, Rocky Slavin, Leslie Neely et al.
TL;DR
This paper addresses the problem of real-time cognitive load assessment using eye-tracking data, which suffers from significant challenges of missing data due to blinks and tracking failures, and the need to efficiently model long temporal dependencies with low latency for edge deployment. The authors propose MambaGaze, a novel framework that explicitly models missing data uncertainty by augmenting raw inputs with observation masks and time-deltas (XMD encoding), combined with a bidirectional selective state space model (Mamba-2) that captures temporal context from both past and future efficiently with linear complexity. Evaluated on two public cognitive load datasets, CLARE and CL-Drive, under subject-independent leave-one-subject-out cross-validation, MambaGaze outperforms strong baselines including CNN, Transformer, ResNet, and VGG by 4–12 percentage points in accuracy. Edge deployment benchmarks on NVIDIA Jetson devices demonstrate feasibility with real-time inference speeds of 43–68 FPS and power consumption below 7.5W, supporting wearable use cases. This work bridges missing data awareness and efficient long-range temporal modeling for practical cognitive load classification from eye-gaze data.
Key findings
- MambaGaze achieves 76.8% accuracy on CLARE and 73.1% on CL-Drive using LOSO evaluation, outperforming CNN baseline by +6.5 pp and +4.1 pp respectively.
- The bidirectional Mamba-2 architecture enables linear time complexity O(T) in sequence length vs. quadratic complexity O(T^2) of Transformer, facilitating edge deployment.
- XMD encoding incorporating observation masks and time-deltas explicitly models missing data uncertainty, improving representation of sparse eye-tracking sequences.
- Class imbalance optimization techniques (positive class weighting, threshold tuning, post-hoc calibration) combined raise LOSO accuracy to 77.9% on CLARE (+7.6 pp over raw baseline).
- MambaGaze attains real-time inference speeds of 43–68 FPS across NVIDIA Jetson AGX Orin, Orin NX, and Orin Nano with power consumption ≤7.5 W.
- On CLARE dataset under LOSO, MambaGaze improves macro-F1 score to 55.4%, beating CNN (55.5%) and Transformer (52.1%) baselines, indicating better balanced classification.
- Ablation studies show threshold optimization in class imbalance handling yields largest individual accuracy gain (+10.7 pp on CLARE).
- MambaGaze maintains stable performance between LOSO and K-fold cross-validation, indicating generalization to unseen subjects.
Threat model
n/a — the paper does not define an explicit adversarial threat model but rather addresses natural missing data patterns in eye-tracking sequences from physiological and technical artifacts such as blinks and tracking failures. The focus is on robust classification under data uncertainty rather than adversarial attack resistance.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly modeled in terms of attack capabilities; rather the paper addresses challenges in real-world eye-tracking data collection for cognitive load monitoring. The system must handle missing data from natural causes like blinks and tracking failures and operate on edge hardware under latency and power constraints. There is no adversarial attack evaluation.
Data: Two public cognitive load datasets are used: CLARE (20 subjects, multitasking tasks, eye-tracking at variable rates resampled to 50 Hz) and CL-Drive (15 subjects in simulated driving). Labels are self-reported cognitive load scores on a 1–9 scale, binarized into low (1–4) and high (5–9) classes at 10-second intervals. Data is segmented into fixed 10-second windows (T=500 timesteps at 50 Hz) with 10 canonical eye-tracking features per frame (pupil diameter, gaze x/y, velocity, acceleration, fixation, saccade, blink, distance). Data preprocessing includes time synchronization, deduplication, forward-fill interpolation, and participant-specific z-score normalization relative to resting baseline recordings.
Architecture / Algorithm: Input features are augmented by the XMD encoding: raw values, binary observation masks indicating actual measurements vs interpolations, and log-scaled time-deltas since last observation, tripling input dimensionality (F=10 → 3F=30). Mamba-2, a state space model with selective input-dependent parameterization enabling content-adaptive filtering, processes the sequence in both forward and backward directions separately with L layers, residual connections, and layer normalization. Context vectors from both directions are aggregated via learned additive attention pooling to adaptively weight temporal contributions. A lightweight classification head with sigmoid activation produces binary cognitive load predictions.
Training Regime: Training optimizes weighted binary cross-entropy loss with dynamic positive class weighting to address class imbalance. AdamW optimizer is used with early stopping based on validation AUC and macro-F1. Threshold optimization and post-hoc calibration are applied on validation folds to improve balanced accuracy. Hyperparameters (epochs, batch size, learning rate) are detailed in appendix but unspecified here. Models are trained from scratch on each fold.
Evaluation Protocol: Leave-one-subject-out (LOSO) cross-validation evaluates generalization to unseen individuals, critical for deployment. Participant-based K-fold CV is used as a secondary protocol. Metrics include accuracy, macro-F1, AUC. Baseline models compared are: CNN, Transformer (for CLARE), ResNet, and VGG (for CL-Drive) trained under same preprocessing and protocols. Ablation studies analyze class imbalance optimizations. Edge deployment latency and power are benchmarked on NVIDIA Jetson platforms (AGX Orin, Orin NX, Orin Nano) measuring inference speed (FPS), latency (ms), and power (W).
Reproducibility: Code availability and dataset licensing are not explicitly stated. Datasets are public. Complete hyperparameters and architectural details are given in appendices. The use of publicly released datasets and established baselines supports reproducibility.
Example end-to-end: Raw asynchronous eye-tracking streams from a participant are preprocessed to 50 Hz with forward-fill interpolation while computing masks and deltas from original timestamps. The resulting XMD tensors (shape: T=500, features=30) feed into bidirectional Mamba-2 layers, producing forward and backward hidden states. Attention pooling generates context vectors that are concatenated and passed through a classification head to predict high vs low cognitive load for the 10-second window. Loss is optimized via weighted binary cross-entropy, with performance assessed on held-out subject in LOSO split. Thresholds are tuned on validation folds, and final models are benchmarked for latency on edge devices.
Technical innovations
- Integration of explicit missing data encoding (values, binary masks, log time-deltas) via XMD input representation to preserve observation reliability in eye-tracking sequences, rather than discarding or imputing uniformly.
- Bidirectional extension of Mamba-2 selective state space model allowing efficient, linear-complexity modeling of long-range temporal context in both forward and reverse directions, improving temporal feature extraction for cognitive load classification.
- Combination of state space modeling with learned attention pooling that adaptively weighs temporal information from bidirectional streams for sequence-level classification.
- Application of class imbalance optimization through automatic positive class weighting, threshold tuning, and post-hoc calibration specifically tailored for cognitive load assessment datasets.
Datasets
- CLARE — 20 subjects — public cognitive load dataset with multitasking protocols and eye tracking
- CL-Drive — 15 subjects — public simulated driving cognitive load dataset with eye tracking
Baselines vs proposed
- CNN (CLARE): Accuracy = 70.3% vs MambaGaze: 76.8%
- Transformer (CLARE): Accuracy = 65.0% vs MambaGaze: 76.8%
- ResNet (CL-Drive): Accuracy = 69.0% vs MambaGaze: 73.1%
- VGG (CL-Drive): Accuracy = 68.5% vs MambaGaze: 73.1%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.22775.
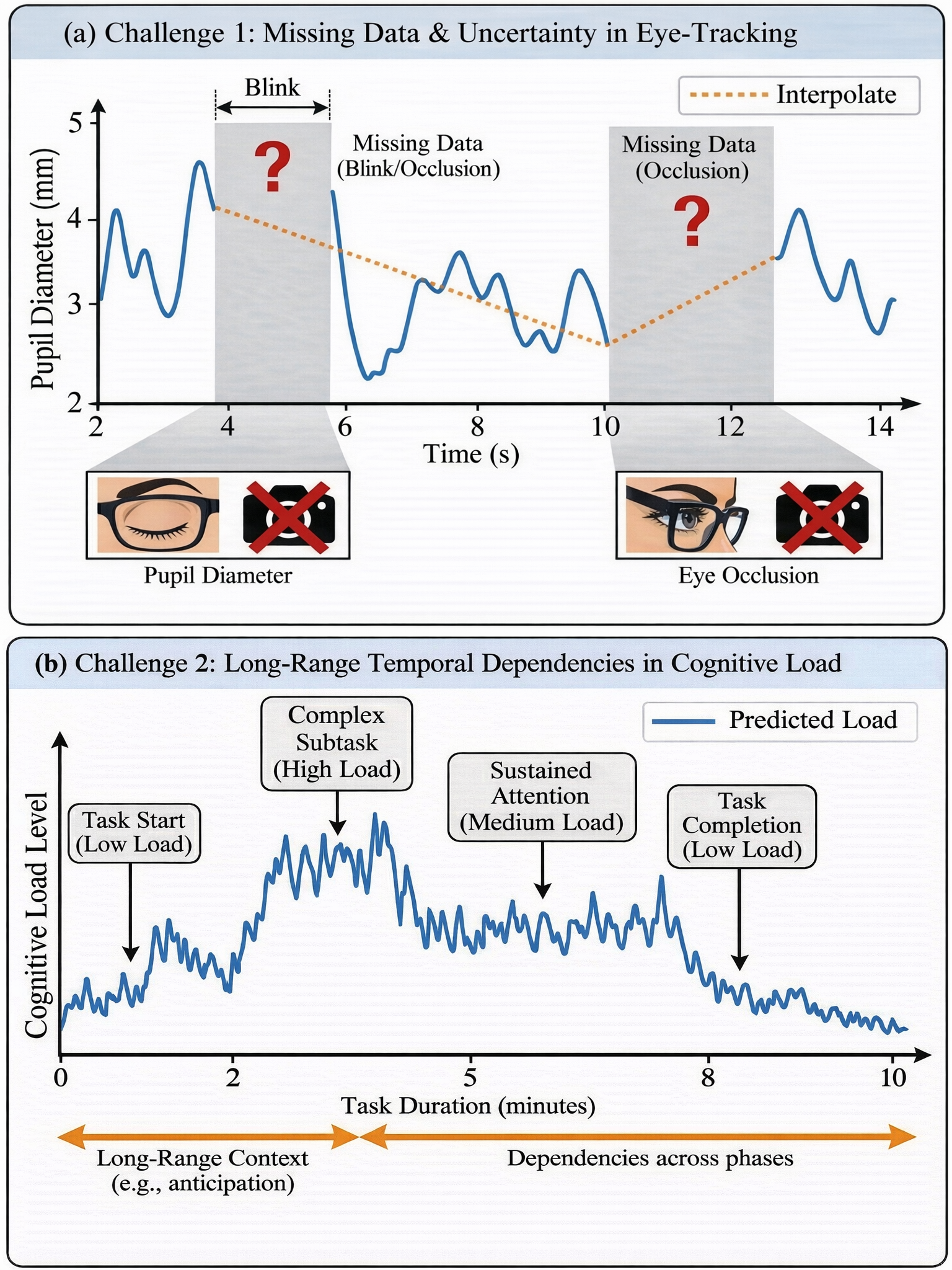
Fig 1: Key Challenges in Real-Time Cognitive Load Assessment
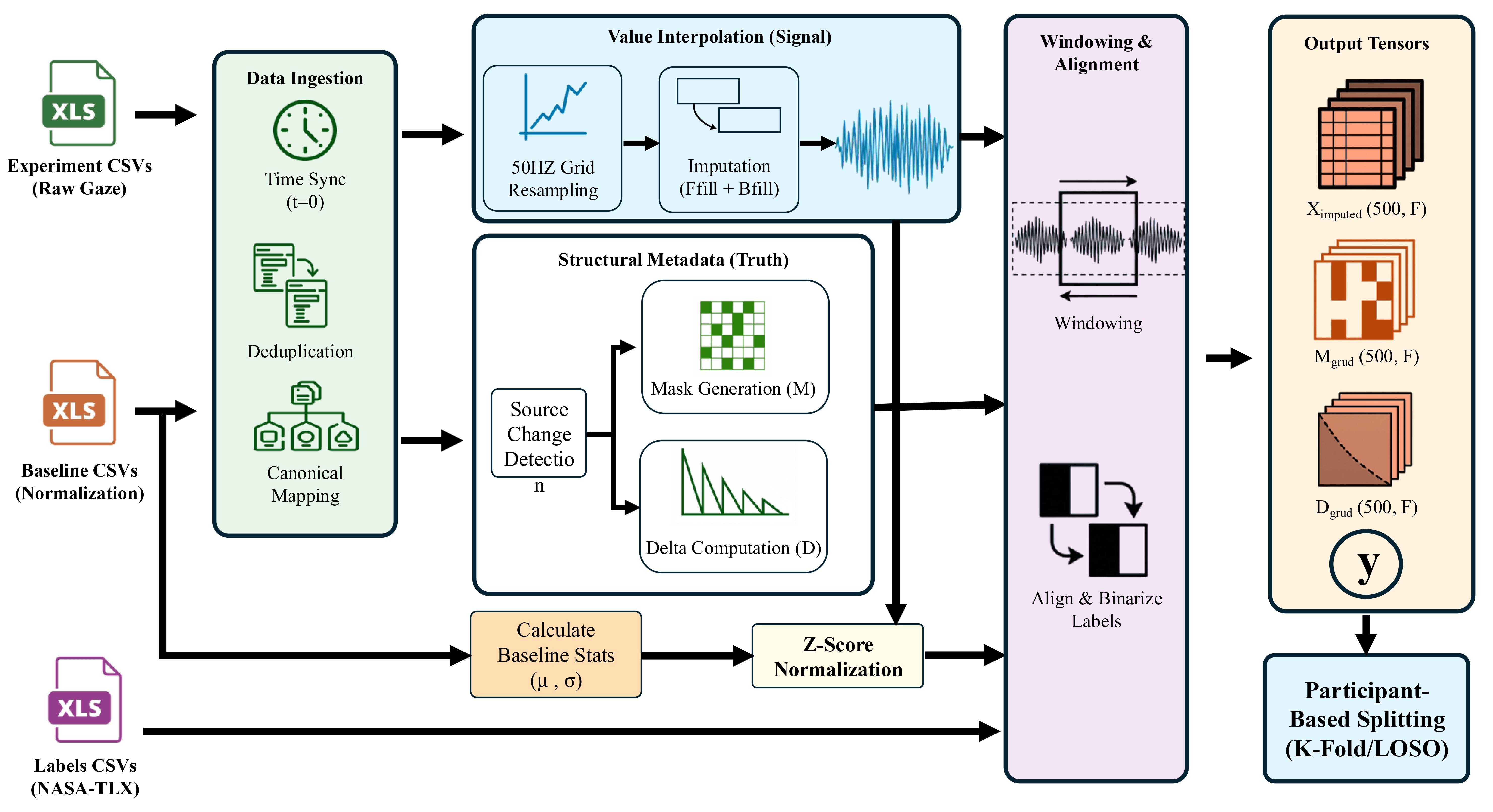
Fig 2: Data processing pipeline. Raw eye-tracking data from experiment, baseline, and label CSVs undergoes time synchronization,
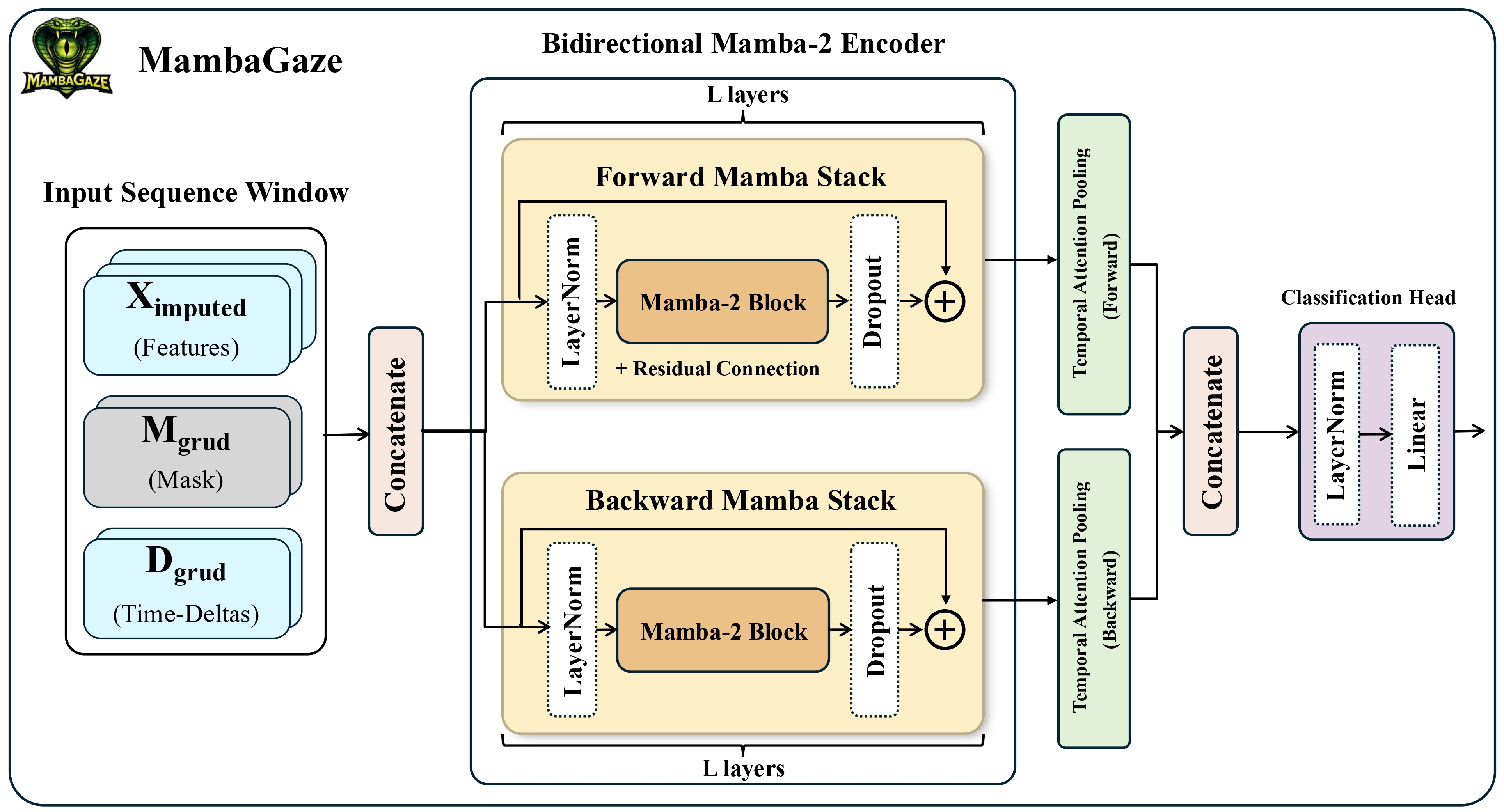
Fig 3: MambaGaze architecture. (a) XMD encoding augments eye-tracking features with observation masks and time-deltas for explicit
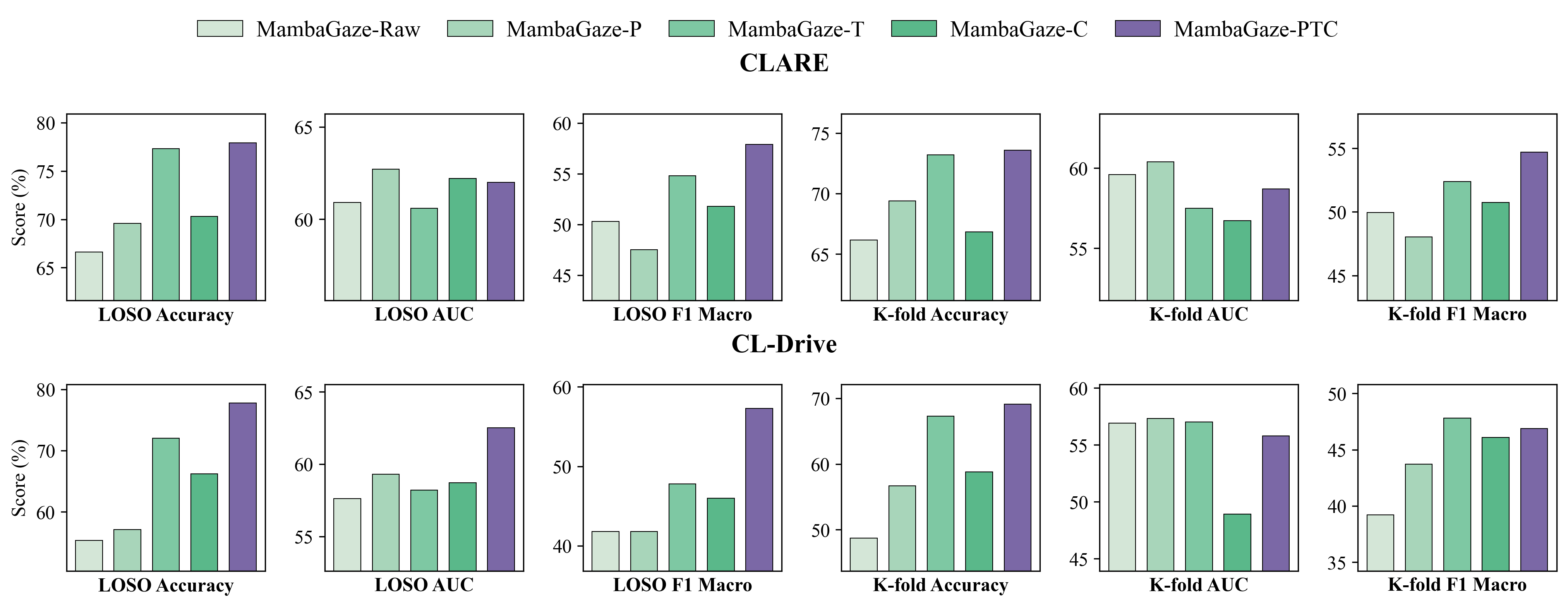
Fig 4: Ablation study on class imbalance optimization techniques across CLARE (top) and CL-Drive (bottom) datasets. Raw: baseline

Fig 5: NVIDIA Jetson Orin edge devices used for deployment
Limitations
- No adversarial robustness or security evaluation; the method assumes missing data arises naturally rather than from attacks.
- Performance improvements over baselines are moderate (~4-12 percentage points) and F1 scores remain modest (~55%), indicating challenges remain in balanced cognitive load classification.
- The datasets used, while public, have limited sample sizes (20 and 15 subjects), potentially limiting generalization.
- No evaluation under distribution shift or real-world noisy conditions beyond missingness patterns is reported.
- Despite achieving real-time speeds on NVIDIA Jetson edge hardware, latency (14.8–23.8 ms) is higher than simpler CNN baselines, which might be a trade-off in some ultra-low-latency applications.
- The approach relies on retrospective future context (bidirectional model), which requires a fixed window and limits instantaneous or streaming online cognition estimates.
Open questions / follow-ons
- How can the approach be extended to online streaming scenarios where future context is unavailable, enabling real-time instantaneous cognitive load monitoring?
- What are the effects of deploying MambaGaze under diverse environmental conditions with more severe noise and variability beyond missing data?
- Can multimodal physiological signals (e.g., EEG, ECG) be integrated with eye-tracking features using similar missingness-aware state space modeling for improved cognitive load assessment?
- How robust is the model against adversarial perturbations or spoofing attacks targeting eye-tracker signals or missing data patterns?
Why it matters for bot defense
From a bot-defense or CAPTCHA perspective, this paper’s core contribution is modeling incomplete, noisy biometric or sensor data (eye gaze) with explicit missing data encoding and efficient temporal sequence modeling. Such techniques could inspire CAPTCHA systems that adaptively evaluate human cognitive or behavioral states from partial data streams during interaction, improving robustness to intermittent observation loss. The use of linear-time bidirectional state space models might inform latency-sensitive implementations of behavioral biometrics on edge or low-power devices. Moreover, explicitly modeling missingness as an informative signal rather than discarding it could enhance detection of bot-like anomalies manifesting as abnormal data gaps or corrupted sensing. However, the demonstrated application focuses on cognitive load assessment rather than direct bot detection or human verification. Practitioners interested in continuous human state inference or implicit authentication from physiological or gaze data may find the XMD encoding plus bidirectional state space modeling a promising architecture to explore. The paper also highlights practical deployment considerations like power and latency metrics important for wearable or embedded bot-defense solutions that must process noisy user signals in real time.
Cite
@article{arxiv2605_22775,
title={ MambaGaze: Bidirectional Mamba with Explicit Missing Data Modeling for Cognitive Load Assessment from Eye-Gaze Tracking Data },
author={ Amir Mousavi and Mohammad Sadegh Sirjani and Erfan Nourbakhsh and Mimi Xie and Rocky Slavin and Leslie Neely and John Davis and John Quarles },
journal={arXiv preprint arXiv:2605.22775},
year={ 2026 },
url={https://arxiv.org/abs/2605.22775}
}