
GS-QA: A Benchmark for Geospatial Question Answering
Source: arXiv:2605.22811 · Published 2026-05-21 · By Majid Saeedan, Muhammad Shihab Rashid, Ahmed Eldawy, Vagelis Hristidis
TL;DR
This paper addresses the challenge of evaluating geospatial question answering (GeoQA) systems by introducing GS-QA, a comprehensive benchmark designed specifically for questions involving spatial reasoning over structured geospatial data and external sources. Unlike prior benchmarks, GS-QA comprises 2,800 question-answer pairs generated from 28 carefully designed templates that cover a rich set of spatial predicates (e.g., nearest neighbor, range, directional, ‘towards’ filtering) and diverse output types (entity names, coordinates, counts, distances, directions, and aggregated areas/lengths). Importantly, GS-QA includes multi-source reasoning questions that require synthesizing spatial data from OpenStreetMap (OSM) with external factual information from Wikipedia, reflecting realistic use cases where answers depend on multiple heterogeneous sources.
The authors created a structured relational reference database with PostGIS from OSM data for the entire US and developed parameterized SQL query templates to automatically generate unambiguous question-answer pairs with guaranteed correctness. To assess current capabilities, they implemented nine LLM-based GeoQA baselines integrating three LLMs (GPT-4o, Claude Sonnet 4.6, Ministral-3) and evaluated approaches including direct prompting, retrieval-augmented generation, and text-to-SQL. Their extensive experiments demonstrate acceptable accuracy for simple spatial predicate questions returning entity names but reveal significant performance degradation on complex spatial predicates, numeric outputs, and multi-source reasoning questions. Thus, GS-QA highlights the gaps in existing GeoQA methods and establishes a challenging benchmark to drive further research in spatial reasoning and multi-source QA.
Key findings
- GS-QA consists of 2,800 questions from 28 templates, covering a wide range of spatial predicates including nearest neighbor, range, direction, towards filtering, intersects, and output types such as entities, locations, distances, directions, counts, and aggregated area/length.
- The multi-source questions require synthesizing spatial data from OSM with factual information from Wikipedia, increasing task complexity.
- Nine LLM-based baselines using GPT-4o, Claude Sonnet 4.6, and Ministral-3 were implemented with direct prompting, retrieval-augmented generation, and text-to-SQL methods.
- LLMs perform reasonably well on simple spatial predicates with entity name outputs but accuracy drops significantly for numeric answers (distances, counts, areas) and complex spatial predicates (directional, towards).
- Existing methods struggle with multi-source reasoning questions requiring fusion of spatial and non-spatial data, showing low baseline performance on GS-QA overall.
- The automated SQL query templates allow deterministic answer generation enabling scalable, repeatable benchmark creation and updates as underlying OSM data changes.
- Spatial evaluation metrics such as distance error and angular error complement text-based QA metrics to assess geospatial output quality.
- GS-QA is more comprehensive than prior GeoQA benchmarks (GeoQuestions201/1089, MapQA) in spatial predicate coverage, multi-source reasoning, output variety, and question scale.
Threat model
The paper does not explicitly define an adversarial threat model, as its focus is on evaluating GeoQA system capabilities rather than security under attack. The implicit assumption is that the system has access to the reference geospatial and external data, and adversaries are not modeled as actively trying to subvert or manipulate answers.
Methodology — deep read
The methodology centers on building a robust geospatial QA benchmark with broad spatial reasoning and output diversity. First, the threat model implicitly assumes an open-domain setting where adversaries are not explicitly modeled — the focus is on system capability rather than adversarial resistance.
The reference data is constructed from OpenStreetMap (OSM) extracts covering the entire USA (GeoFabrik extract dated February 2, 2024) converted into a PostgreSQL/PostGIS relational database. This structured approach supports deterministic SQL-based query answering, multi-source integration (linking entities with Wikipedia pages), and flexible querying. The database includes points of interest (restaurants, hotels, hospitals), parks, water bodies, roads, and administrative boundaries, with selected common attributes (name, address components, Wikipedia links, amenity type) to support question generation. Table statistics detail millions of records across these geographic object types.
Questions are generated from 28 manually designed templates that combine spatial predicates (nearest neighbor, range, direction, towards, intersects), output types (entity name, location, direction angle, distance, count, area/length, external facts), and natural language variants. Placeholders in templates are systematically substituted with database entities and parameters, paired with parameterized SQL queries that produce deterministic answers. This template-driven generation enables scalable, unambiguous, and repeatable dataset expansion. A comprehensive verification procedure ensures question validity and unambiguous answers.
Multi-source questions add complexity by requiring synthesis of data retrieved from both the geospatial PostGIS database and external, unstructured Wikipedia data, necessitating multi-step retrieval and reasoning for correct answers.
To evaluate GeoQA performance, the authors implement nine baselines spanning three LLMs — GPT-4o, Claude Sonnet 4.6, and Ministral-3 — with three inference approaches each: direct prompting (zero-shot/one-shot), retrieval-augmented generation (RAG) that retrieves relevant database or Wikipedia text segments as context, and text-to-SQL translation to execute actual queries against the PostGIS database. Models generate answers in open-ended formats.
Evaluation protocols combine text-based QA metrics (exact match, F1 scores) with geospatially aware metrics such as relative distance error (for coordinate outputs) and angular/azimuth error (for directional outputs). This dual evaluation accounts for semantic and spatial correctness. The benchmark also examines performance variations by question template and output type.
Experiments run on fixed seeds using standard LLM API settings; the paper does not mention code or data release policy explicitly but states GS-QA and baseline results are published. The framework enables automatic answer verification and updating as OSM data evolves, making it future-proof. One concrete example: a question template “Can you suggest a restaurant within 1km from San Diego Zoo?” is instantiated by substituting ‘restaurant’, ‘1km’, and 'San Diego Zoo' from the database, yielding a corresponding SQL query computing the exact set of restaurants within range, providing an unambiguous ground truth answer. Model outputs are then compared against this ground truth with spatial and textual metrics.
Overall, the methodology combines geospatial data engineering, natural language template generation paired with SQL answer computation, multi-source data integration, LLM inference with retrieval and SQL query translation, and specialized evaluation metrics to provide a rigorous end-to-end GeoQA benchmark pipeline.
Technical innovations
- A large-scale, extensible GeoQA benchmark with 2,800 templated questions covering a broad set of spatial predicates, output types, and multi-source reasoning tasks combining OSM and Wikipedia data.
- A relational geospatial reference database built from raw OSM extracts using PostGIS to enable deterministic, SQL-based question answering for spatial predicates including directional and ‘towards’ filters lacking direct GeoSPARQL equivalents.
- Template-based automatic generation of natural language questions paired with executable SQL query templates allowing scalable dataset generation, automatic answer validation, and benchmark updating with fresh OSM data.
- Evaluation methodology combining traditional text-based QA metrics with spatially aware measures (distance error, angular error) to assess geospatial answer quality beyond text matching.
- Implementation of diverse LLM GeoQA baselines integrating direct prompting, retrieval-augmented generation, and text-to-SQL translation to benchmark state-of-the-art language models on spatial reasoning.
Datasets
- GS-QA — 2,800 question-answer pairs — generated from OpenStreetMap (Feb 2024 GeoFabrik extract) and Wikipedia
- OpenStreetMap (USA dataset from GeoFabrik, Feb 2, 2024) — 26.7M points of interest, 5.9M parks, 7.9M water bodies, 36.8M roads, 39k administrative boundaries
Baselines vs proposed
- GPT-4o direct prompting: metric not specified, baseline shows decent results on simple spatial predicates with entity outputs but significant accuracy degradation on complex spatial predicates and numeric outputs
- Claude Sonnet 4.6 RAG approach: similar trends with better performance on entity name outputs but struggles with directional and multi-source questions
- Ministral-3 text-to-SQL: better at exact query answering for some predicates but overall low accuracy on multi-source and complex spatial reasoning templates
- All baselines show low performance on multi-source reasoning questions requiring Wikipedia and OSM data synthesis compared to single-source questions
- Performance per template varies widely, with near neighbor queries outperforming directional and towards filtering by large margins (quantitative numbers unspecified in summary)
- Spatial metrics such as distance and angular error reveal significant spatial inaccuracies in LLM-generated answers for complex predicates
- MapQA baseline (from related work) performs well on simple predicates but lacks multi-source capabilities compared to GS-QA baselines
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.22811.
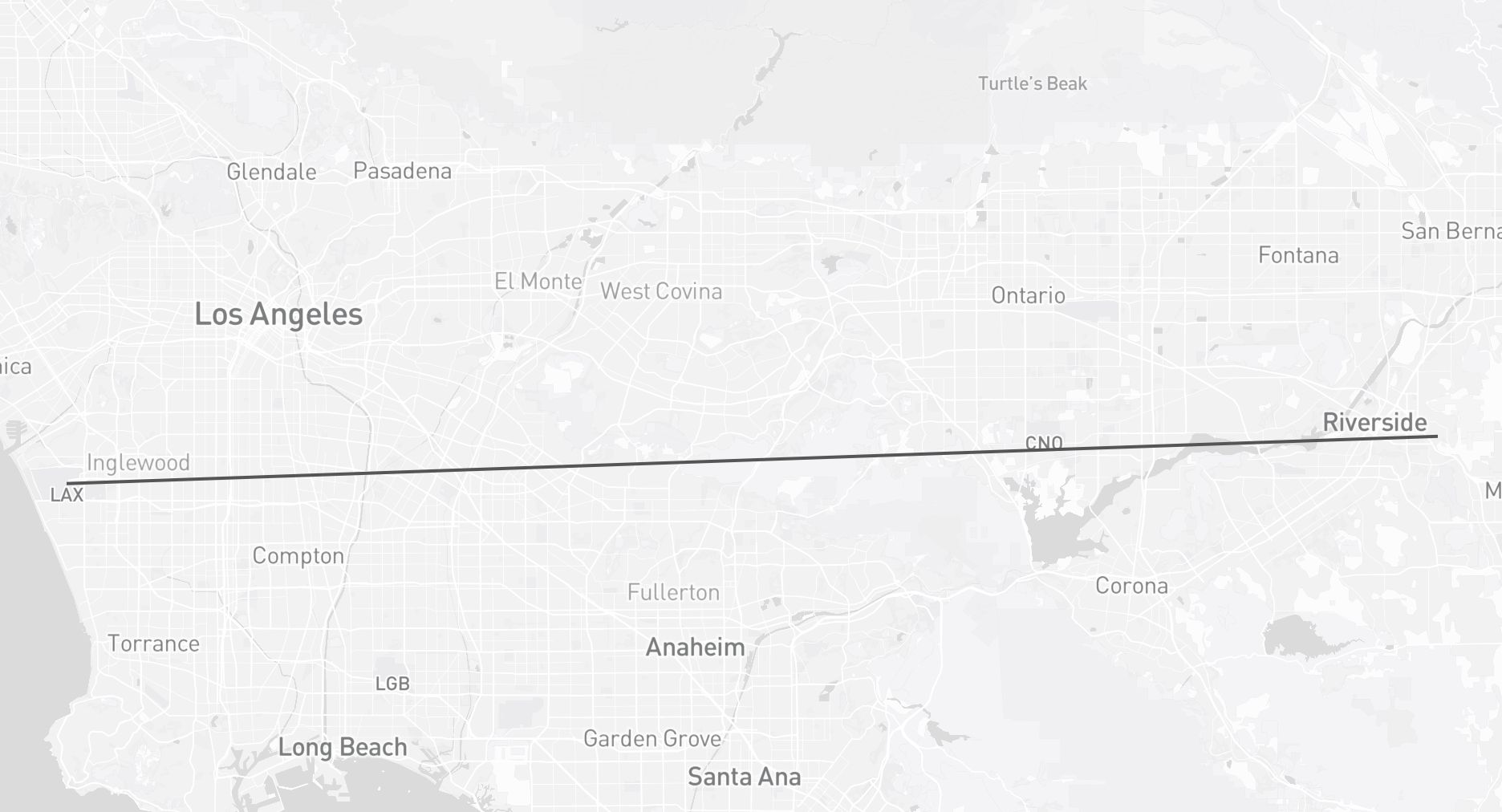
Fig 1: Geospatial Question Answering Example
Fig 2 (page 2).

Fig 3 (page 2).
Limitations
- The benchmark focuses primarily on English questions and US geospatial data, limiting generalization to other regions and languages.
- Multi-source reasoning evaluation uses Wikipedia as the only external non-spatial source, which may not cover all factual needs.
- While broad, the chosen spatial predicates and question templates are a curated subset and do not cover all possible geospatial query types or analytic tasks.
- Baseline LLMs were evaluated primarily on zero-shot or few-shot prompting without fine-tuning on spatial tasks, possibly limiting peak performance.
- The evaluation does not extensively address adversarial or out-of-distribution spatial queries, nor dynamic or time-dependent spatial data updates beyond snapshot updates.
- The question generation relies on underlying OSM data quality and attribute completeness, which may impact answer correctness or coverage.
Open questions / follow-ons
- How can GeoQA systems be improved to better handle complex spatial predicates such as directional and ‘towards’ filters currently challenging for LLMs?
- What architectural or training modifications enable LLMs to effectively perform multi-source reasoning synthesizing spatial and non-spatial heterogeneous data?
- Can including step-by-step spatial reasoning or spatial workflow execution improve open-ended GeoQA accuracy and interpretability?
- How well do GeoQA models generalize to other geographic regions, languages, or real-time dynamic spatial datasets beyond the USA and static OSM extracts?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners focused on authenticating genuine user interaction via spatial reasoning checks or geospatial challenge-response tests, GS-QA provides a rigorous evaluation framework highlighting the strengths and weaknesses of state-of-the-art LLMs in handling complex spatial reasoning tasks. The benchmark’s multi-source questions and advanced spatial predicates such as directional and towards filtering are particularly relevant for designing robust CAPTCHA challenges that resist simplistic generative model responses. The spatially-aware evaluation metrics including distance and angular errors offer nuanced insights beyond text matching, valuable for assessing bot spatial comprehension.
Moreover, the open-ended, multi-modal nature of GS-QA questions aligns with scenarios where CAPTCHA systems might require understanding of spatial context combined with external factual knowledge (e.g., geospatial context plus related encyclopedic facts), exposing existing LLM limitations. Bot-defense engineers can leverage GS-QA insights to design geospatial reasoning tasks that current LLMs struggle with, increasing challenge effectiveness and resistance. Additionally, GS-QA’s scalable, template-driven question generation supports continuous augmentation of spatial reasoning challenges tuned to evolving adversarial capabilities.
Cite
@article{arxiv2605_22811,
title={ GS-QA: A Benchmark for Geospatial Question Answering },
author={ Majid Saeedan and Muhammad Shihab Rashid and Ahmed Eldawy and Vagelis Hristidis },
journal={arXiv preprint arXiv:2605.22811},
year={ 2026 },
url={https://arxiv.org/abs/2605.22811}
}