
Deep Reinforcement Learning for Flexible Job Shop Scheduling with Random Job Arrivals
Source: arXiv:2605.22773 · Published 2026-05-21 · By Yu Tang, Muhammad Zakwan, Efe Balta, John Lygeros, Alisa Rupenyan
TL;DR
This paper addresses the challenging Flexible Job Shop Scheduling Problem (FJSP) where jobs arrive randomly over time, and scheduling decisions must be made dynamically and quickly. Traditional Mixed-Integer Linear Programming (MILP) methods are computationally intractable for large-scale or dynamic instances due to combinatorial explosion and uncertainty from random job arrivals. The authors propose a novel event-based deep reinforcement learning (DRL) framework using Proximal Policy Optimization (PPO) with lightweight multi-layer perceptrons (MLPs) that select among established dispatching rules rather than directly assign jobs to machines. This reduces action space complexity and improves training stability.
The DRL agent observes state vectors summarizing current job statuses, machine availabilities, and global context, and takes actions only at discrete events (job arrivals or operation completions). Experiments on both synthetic homogeneous and heterogeneous job/machine datasets show the DRL agent matches or outperforms heuristic dispatching rule combinations and a strong event-triggered MILP baseline called AT-MILP, especially on heterogeneous datasets with varied job lengths and machine speeds. The results highlight that the DRL approach better adapts to complex, stochastic environments while keeping inference efficient for near-real-time scheduling.
Key findings
- The DRL method consistently matches or outperforms the Best Heuristic in Hindsight (Best HH) across all tested job arrival rates in homogeneous datasets (Table III).
- AT-MILP achieves the lowest makespan on homogeneous datasets but struggles on heterogeneous datasets, especially at high job arrival rates (Table IV).
- On heterogeneous datasets, DRL reduces the average makespan by 40-160 units compared to AT-MILP and heuristic baselines, notably when λ=0.2 or 0.05 (Table IV).
- Training stabilizes after approximately 3000 rollouts with a steady increase in mean episodic reward, indicating convergence (Fig 2).
- Action space is comprised of 10 dispatching rule combinations formed by 5 job sequencing and 2 machine routing rules, simplifying training and increasing interpretability.
- AT-MILP’s optimization time limit is capped at 60 seconds for online applicability, showing a trade-off in computational cost versus schedule quality.
- The DRL agent observes the first 40 arrived, unfinished jobs padded with large values when fewer jobs have arrived, maintaining fixed input dimensionality.
Threat model
The adversary is implicitly modeled as randomness in job arrivals, which are exogenous and unknown at scheduling times. The RL agent must operate under partial observability and stochastic dynamics without foresight of future arrivals. The adversary cannot interfere by corrupting observations or actions, nor modify job processing times or machine availabilities; only randomness in arrivals challenges the scheduler.
Methodology — deep read
Threat model & assumptions: The problem is modeled as a Markov Decision Process (MDP) with partial observability due to unknown future job arrivals. The environment is stochastic because job arrivals are random according to a Poisson process. The agent cannot foresee future job arrivals and must schedule dynamically with causal info. Processing times are deterministic, and setup/transport times are neglected.
Data: Synthetic datasets emulate job shop environments with six machines and various job arrival rates (λ = 0.02, 0.05, 0.2). Two dataset types are created: homogeneous jobs/machines with uniformly sampled processing times and machine compatibility; and heterogeneous datasets including short and long jobs, one fast machine amid slower machines with penalties and machine bottlenecks. Jobs initially exist (n_ini) and later arrive (n_add). All arrival times are generated from exponential interarrival times (Poisson arrivals). Multiple independent test runs are done.
Architecture/algorithm: The DRL agent uses the Proximal Policy Optimization (PPO) algorithm with actor-critic architecture. Both actor and critic networks are lightweight MLPs with two hidden layers of 256 and 128 neurons and ReLU activations. The input state vector concatenates job states (next operation indices, next available times) for the first 40 arrived unfinished jobs, machine next-free times, average processing times, current makespan, and event time. The action space consists of 10 composite dispatching rule pairs (from 5 sequencing and 2 machine routing rules). The agent outputs a softmax probability over these actions to sample a scheduling rule at each event.
Training regime: PPO is trained for 1e7 steps using Stable-Baselines3 on an Apple M3 Pro with 12 cores, with rollout sizes of 256, minibatches of 64, learning rate 0.0001, discount factor γ=1, GAE λ=0.95. Entropy coefficient is 0.02 to encourage exploration. Training epochs per update are 3, with a clipping epsilon of 0.2 for the PPO loss. Training stabilizes after ~3000 rollouts.
Evaluation protocol: Agents are evaluated on held-out random job arrival sequences, independently resampled for each test. Metrics reported are average and standard deviation of makespan over multiple runs (5 runs for homogeneous, 15 for heterogeneous). Baselines include the Arrival Triggered MILP (AT-MILP) with 60s solve time per event, Best Heuristic in Hindsight (Best HH) which picks the best of 10 dispatching rule combos after knowing the schedule, and selected single dispatching rules. No cross-validation or adversarial appointments are described. Experiments cover varying job arrival rates and fixed environment configurations.
Reproducibility: Code and datasets are not publicly released; the environment, PPO implementations use standard frameworks like Stable Baselines3. Detailed hyperparameters and dataset generation distributions are reported for reproducibility.
Example end-to-end: At each scheduling event (job arrival or completion), the agent observes the partial system state vector (job operation indices, machine free times, processed jobs) padded to fixed size if needed. It samples an action (dispatching rule pair) via softmax policy over 10 rules to prioritize and assign operations. The environment applies the selected dispatching rule to assign the next operation, updates the schedule and physical time, and computes shaped reward as the decrease in current makespan. Transitions are stored for PPO updates. This process repeats until all jobs finish, and the episode ends with an observed final makespan minimization objective.
Technical innovations
- Event-based DRL formulation for FJSP that triggers actions only at discrete events (job arrivals or operation completions), reducing decision complexity.
- Action space design constrains the DRL agent to select from combinations of well-established dispatching rules rather than direct job-machine assignments, improving training stability and interpretability.
- Modified MILP baseline (AT-MILP) which solves MILPs triggered by job arrivals with frozen past schedules as a strong online adaptive baseline.
- Lightweight MLP architecture enabling practical training of PPO for dynamic, heterogeneous job shop environments with partial observability.
Datasets
- Homogeneous dataset — size varies (6 machines, 20-40 jobs) — synthetic with uniform distributions as per [24]
- Heterogeneous dataset — 6 machines, 20 jobs (5 initial + 15 arrivals) — synthetic with mixed job lengths and machine speeds
Baselines vs proposed
- AT-MILP: makespan = 307 (±14) at λ=0.2 small-scale homogeneous vs DRL: 338 (±18)
- AT-MILP: makespan = 1642 (±14) at λ=0.2 heterogeneous vs DRL: 1478 (±52)
- Best HH: makespan = 378 (±15) vs DRL: 338 (±18) homogeneous small-scale λ=0.2
- Rule 1 (FIFO+MINC): makespan = 396 (±22) vs DRL: 338 (±18) homogeneous small-scale λ=0.2
- Rule 3 (LPT+MIN): makespan = 2014 (±50) vs DRL: 1478 (±52) heterogeneous λ=0.2
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.22773.
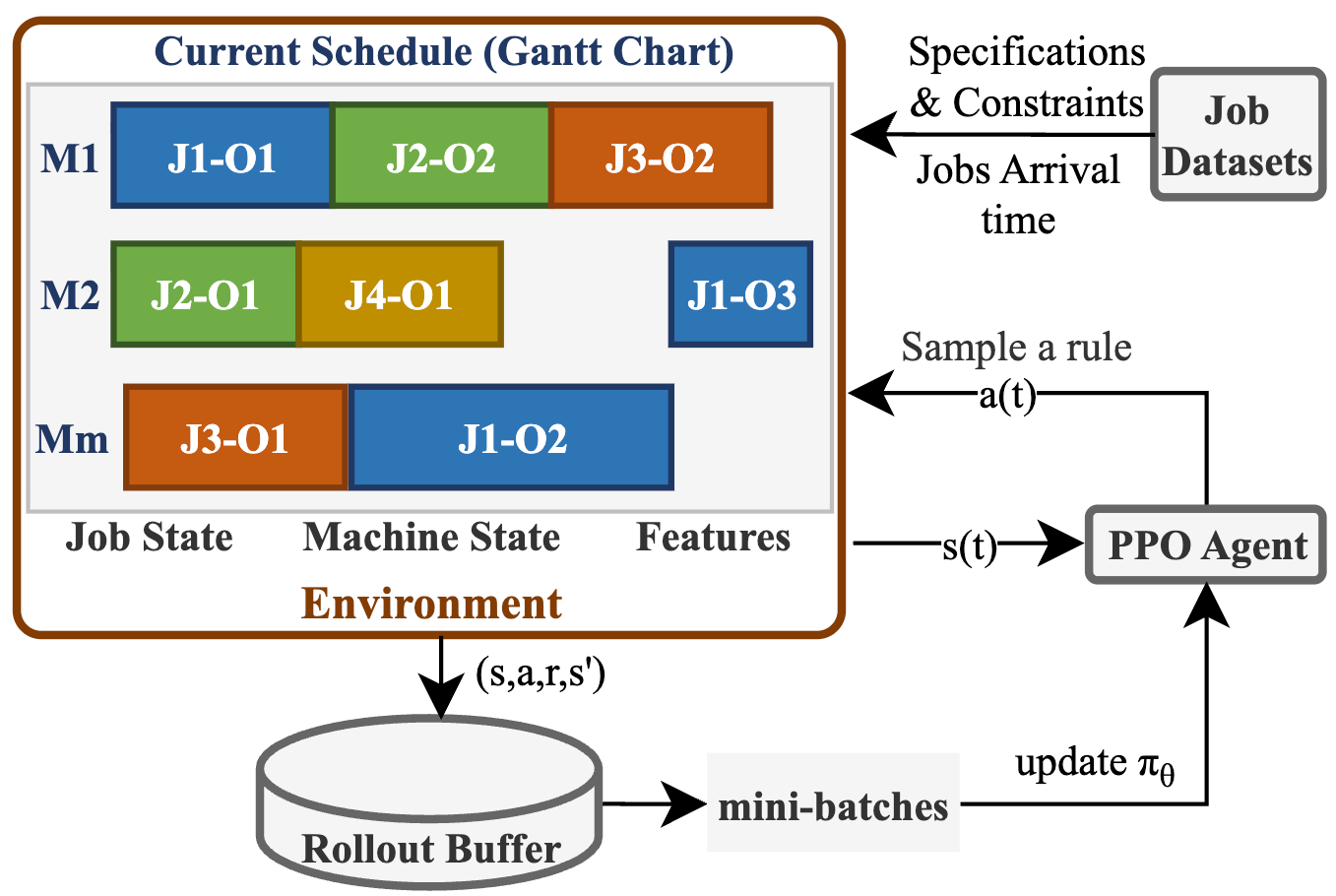
Fig 1: The framework of our DRL for FJSPs with random
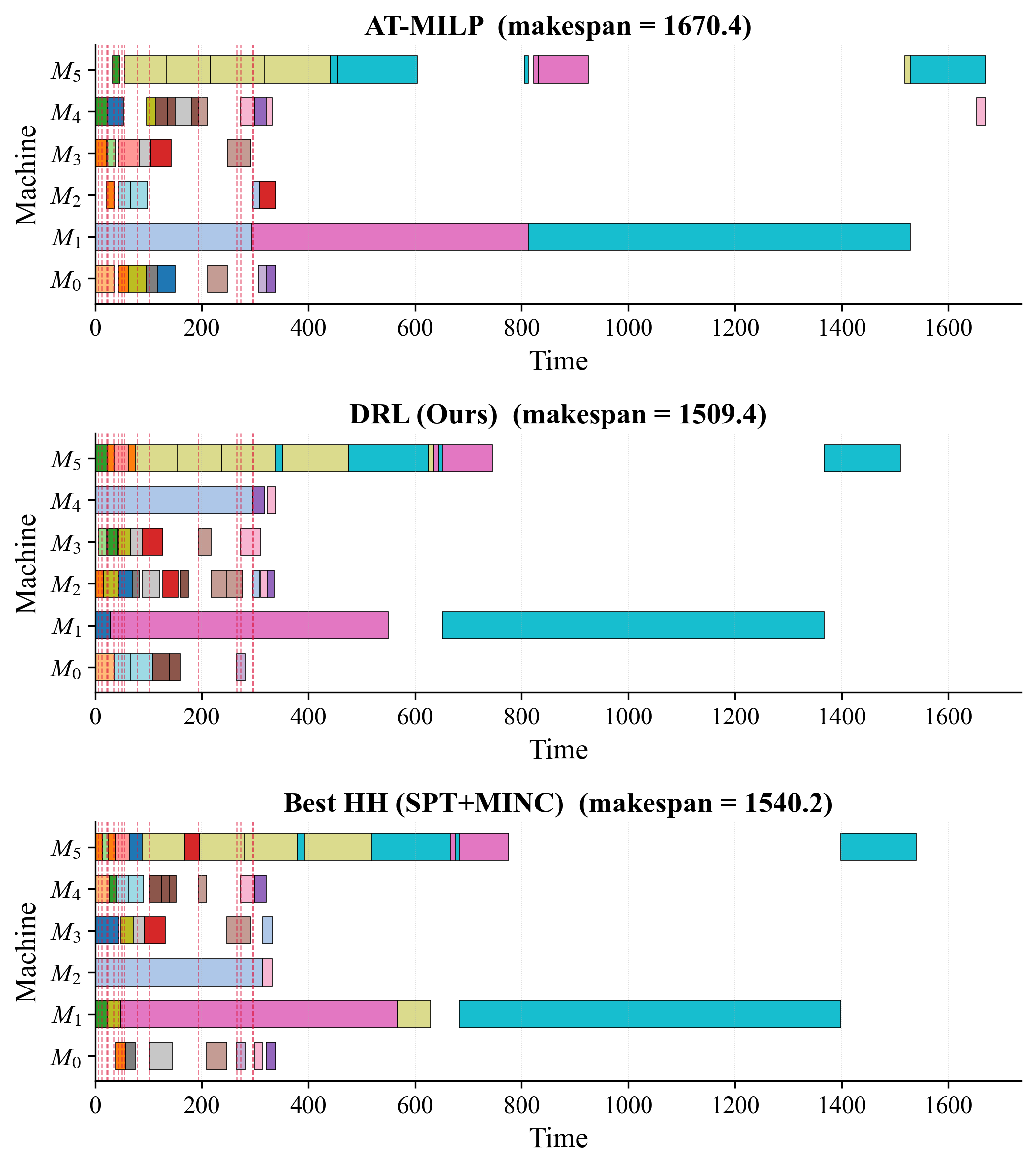
Fig 3: Schedules of three methods on one heterogeneous
Limitations
- No public code or dataset release limiting reproducibility and external validation.
- Evaluation only on synthetic datasets with specific parameter distributions; real-world variability not tested.
- The AT-MILP baseline may be unfairly penalized in heterogeneous datasets due to limited lookahead and greedy rescheduling.
- The fixed input size limit of 40 arrived jobs could limit scalability to very large or highly dynamic shop floors.
- No adversarial or worst-case scenario evaluations testing robustness to extreme or adversarial job arrivals.
- Complexity trade-offs with expanding dispatching rule sets for larger action space are not explored.
Open questions / follow-ons
- How would the DRL framework perform on real industrial datasets with varied, non-Poisson arrival processes and operational disruptions?
- Can the action space be extended beyond fixed dispatching rules to hybrid or learned heuristics to improve policy expressiveness and scalability?
- How robust is the DRL agent to adversarial or worst-case job arrival patterns and does it generalize to distribution shifts in job/machine types?
- What are the trade-offs in latency and computational overhead between DRL inference and AT-MILP with loosened time limits for larger, more complex job shops?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work illustrates a practical approach to solving highly combinatorial, time-sensitive scheduling problems under uncertainty using event-triggered reinforcement learning with restricted action spaces. The strategy of restricting actions to a manageable set of heuristic rules to simplify learning could inspire similar methods in CAPTCHA challenge generation or adaptive bot detection systems where real-time decisions are needed under stochastic inputs. Moreover, benchmarking against strong MILP baselines demonstrates the value of learning-based methods in heterogeneous environments where classical optimization struggles. The methodology suggests DRL agents can adapt online to dynamic workloads that vary in complexity — relevant for systems needing rapid, policy-driven responses to evolving attack vectors or user interactions. However, the underlying focus on scheduling contrasts with CAPTCHA’s human interaction modalities; thus, adaptation would require domain-specific feature engineering and careful evaluation for usability and security trade-offs.
Cite
@article{arxiv2605_22773,
title={ Deep Reinforcement Learning for Flexible Job Shop Scheduling with Random Job Arrivals },
author={ Yu Tang and Muhammad Zakwan and Efe Balta and John Lygeros and Alisa Rupenyan },
journal={arXiv preprint arXiv:2605.22773},
year={ 2026 },
url={https://arxiv.org/abs/2605.22773}
}