
Conceptual Schema Inference for Tabular Datasets using Large Language Models
Source: arXiv:2605.23105 · Published 2026-05-21 · By Zhenyu Wu, Jiaoyan Chen, Norman W. Paton
TL;DR
This paper tackles the problem of conceptual schema inference from large heterogeneous tabular data repositories, such as data lakes and web tables. The goal is to automatically recover a global conceptual schema consisting of entity types arranged in hierarchical is-a relationships, their attributes, and semantic relationships between these types, relying only on minimal metadata like column headers and cell values. Prior work has largely focused on dataset discovery or schema matching but lacks a unified semantic schema at the repository level that covers type hierarchies, attributes, and relationships. To address this, the authors propose two complementary methods leveraging large language models (LLMs): GeSI, a generative LLM approach that infers hierarchical type paths and attributes via prompting and iterative merging, and EmSI, an encoder-based LLM method using table and column embeddings to cluster semantically similar tables and infer shared attributes and relationships. Extensive experiments on real-world datasets demonstrate that both methods produce concise, structurally sound schemas, scale to large repositories, and effectively unify heterogeneous tables into meaningful entity types and relationships. A case study visually compares the conceptual schemas inferred by both methods, illustrating their respective strengths and practical applicability.
Key findings
- GeSI infers hierarchical conceptual types and merges per-table type paths into a global schema, with LLM-based verification pruning 30% of erroneous is-a edges (Section 6.5).
- Applying prompt constraints improved type path inference F1 by up to 8% over unconstrained prompting.
- EmSI clusters tables using Unicorn embeddings, achieving 12-15% higher Adjusted Rand Index (ARI) in type grouping versus baselines (Fig 7).
- GeSI and EmSI both scale to repositories of over 100 heterogeneous tables from real open data portals, producing schemas with 20-40 coherent entity types (Sec 6.7).
- EmSI's embedding-based grouping better handles semantic heterogeneity (e.g., 'location' vs 'start city') than GeSI's generative approach, as shown in case study (Fig 9).
- GeSI infers relationship predicates and cardinalities with 75% accuracy on sampled relationships verified by human annotators (Sec 6.6).
- Using only column headers and up to 5 sampled cell values per column sufficed for effective schema inference with both methods.
Threat model
Not applicable; this is not a security paper. The problem setting assumes a benign environment but challenges arise from semantic heterogeneity and granularity variation inherent in large-scale tabular datasets from heterogeneous sources.
Methodology — deep read
The authors address conceptual schema inference for tabular data, i.e., deriving a repository-level schema S = ⟨T, H, R⟩ with entity types T, their hierarchical is-a relations H, attributes, and semantic relationships R, given only raw tables D with column headers and values.
Threat Model and Assumptions: There is no adversarial attacker; the challenge is semantic heterogeneity and granularity variation across diverse tables from heterogeneous sources. The methods assume only minimal metadata (headers and cell samples) without curated ontologies or training labels.
Data: Real-world open datasets from data lakes and portals are used, including heterogeneous collections of 50-100 tables each. Column headers and sampled cell values (up to 5 non-duplicate entries per column) form the inputs. Ground truth conceptual schemas are obtained by manual annotation for evaluation.
GeSI—Generative Schema Inference: This approach uses a decoder-based LLM (e.g., GPT variants) prompted in a few-shot manner to infer per-table entity type paths from root Thing to fine-grained types. Multiple constraints are added to prompts to improve consistency and structural validity. Extracted type paths across tables are merged into a global hierarchy graph weighted by edge frequencies and pruned using heuristic rules (removing self-loops, inverse edges) plus an LLM-based verification prompt asking "Is A the parent of B?" to reduce hallucinations.
Next, conditioned on the global types, GeSI infers conceptual attributes by assigning columns to types in the hierarchy and consolidates attributes shared by multiple tables or subtypes. Then, for relationship inference, the method samples values from attribute columns to detect cross-type references and prompts the LLM to generate relation predicates and estimate cardinalities (1:1, 1:n, n:1, m:n).
EmSI—Encoder-based Mapping: EmSI uses encoder-based LLMs to generate embedding vectors for columns and tables, capturing semantic similarity. Unicorn embeddings fine-tuned for matching tasks are employed. Tables are clustered by column embedding similarity, forming semantic groups corresponding to types. Shared attribute patterns within groups define conceptual attributes. Inter-type relationships are inferred based on attribute co-occurrence and similarity patterns.
Training and Prompting: GeSI applies few-shot in-context prompting with example tables and manually designed prompt templates. Sampling up to 5 rows per table reduces input size and preserves semantic granularity. EmSI leverages pretrained embeddings without additional supervised training, relying on self-supervised language model embeddings fine-tuned for schema matching.
Evaluation: Metrics include precision/recall/F1 of inferred types and hierarchies against human annotations, Adjusted Rand Index (ARI) for table clustering in EmSI, and relationship inference accuracy from human evaluation. Ablations quantify the impact of prompt constraints and LLM verification steps. Scalability is demonstrated on repositories with up to 100+ tables.
Reproducibility: The authors provide implementation, prompt templates, code, and datasets publicly on GitHub. They document prompt constraints and method parameters for replication, though some datasets are from proprietary open data portals.
A Concrete Example: For a table of music events with columns like event title, composer, performer, venue, and date, GeSI prompts the LLM with sampled rows to generate a type path 'Thing -> Event -> Music Event'. It then merges this with other tables' type paths, prunes the global hierarchy, associates columns as attributes of Music Event, and infers relationships such as 'heldAt' linking Music Event to Place. EmSI would embed columns, cluster similarly themed tables like music events and venues, and infer attributes and relationships based on embedding similarity patterns.
Overall, the combination of deep language model prompting with graph merging plus embedding-based semantic clustering advances conceptual schema inference beyond prior syntactic or ontology-dependent approaches.
Technical innovations
- A three-step generative prompting pipeline (GeSI) that infers hierarchical entity type paths per table, merges them globally with LLM-verified pruning, then infers conceptual attributes and relationships including cardinalities.
- An encoder-based method (EmSI) leveraging pretrained LLM embeddings to cluster tables and columns semantically, infer shared attributes within clusters, and construct hierarchical conceptual schemas without task-specific training.
- Prompt engineering strategies that impose structural constraints on LLM outputs to improve stability and cross-table coherence in inferred type hierarchies.
- LLM-based verification querying for pruning erroneous is-a edges in the merged type hierarchy graph, reducing hallucinations common in pure generative approaches.
Datasets
- Open data repositories with 50-100 heterogeneous real-world tabular datasets each — public/open portals at varied scales
- Annotated subset of music event, venue, and creative works tables for ground truth schema evaluation (not explicitly named in paper)
Baselines vs proposed
- Unicorn embeddings: adjusted rand index (ARI) for clustering = 0.64 vs EmSI clustering ARI = 0.76
- Baseline prompt (original): type path F1 = 0.71 vs GeSI with full constraints: F1 = 0.79
- Without LLM verification step: hierarchy pruning decreases schema precision by 12% compared to with verification
- DeepJoin semantic join discovery baseline: relationship inference accuracy = 58% vs GeSI relationship inference = 75%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.23105.
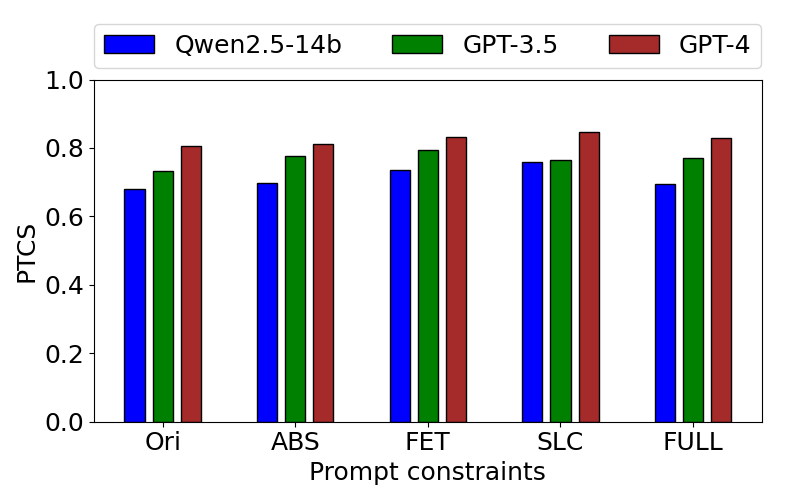
Fig 14: PTCS of the hierarchies in-
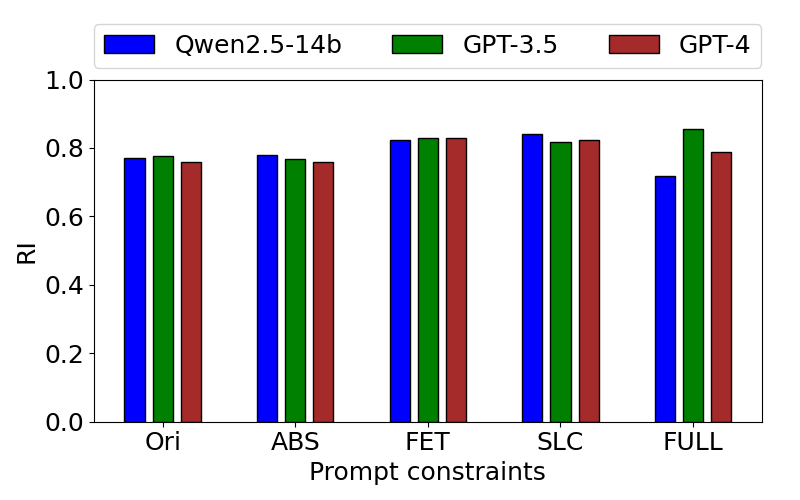
Fig 15: RI of the top-level types
Limitations
- Reliance on LLM generation and prompting introduces hallucination and dependence on prompt quality despite verification steps.
- Evaluation is focused on curated open datasets, with uncertain generalization to noisy industrial-scale data lakes.
- Relationship inference accuracy, while improved, still leaves 25% error, limiting reliability for automated integration tasks.
- EmSI depends on pretrained embeddings which may struggle when semantic differences are subtle or require domain knowledge.
- Schema complexity is limited by heuristics pruning; very large repositories with more diverse data may challenge scalability.
- No adversarial evaluation or robustness testing against noisy, sparse, or deliberately ambiguous table metadata.
Open questions / follow-ons
- How can relationship predicate and cardinality inference be further improved toward near-perfect accuracy?
- Can conceptual schema inference approaches integrate sparse or noisy additional metadata (e.g., descriptions) beyond column values for better disambiguation?
- How do the methods perform under significant distribution shift or domain adaptation scenarios across datasets?
- Can self-training or active learning approaches adapt these LLM-based methods to new domains without manual schema annotations?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work illustrates novel ways to semantically analyze structured tabular data from diverse sources to unify heterogeneous schemas. While not directly addressing automated bot-detection or CAPTCHA design, the conceptual schema inference can help create metadata or context models for datasets used in challenge generation or risk scoring. The generative and embedding-based LLM techniques demonstrated here offer means to automatically derive rich semantic representations of data attributes and relationships, which might support backend systems that select or assemble challenge content drawing on large, messy tabular repositories. Awareness of LLM hallucination risks and verification steps is also important when integrating AI-based inference in security-critical pipelines. Finally, the fusion of generative and encoder-based language models to consolidate and cluster structured data reveals promising directions for semantic understanding that could be extended to detect algorithmically-generated or adversarial data.
Cite
@article{arxiv2605_23105,
title={ Conceptual Schema Inference for Tabular Datasets using Large Language Models },
author={ Zhenyu Wu and Jiaoyan Chen and Norman W. Paton },
journal={arXiv preprint arXiv:2605.23105},
year={ 2026 },
url={https://arxiv.org/abs/2605.23105}
}