
A Multi-Source Framework for Relational Validation of Large Language Models Using Expert-Curated Encyclopedic Sources
Source: arXiv:2605.22636 · Published 2026-05-21 · By Moses Boudourides
TL;DR
This paper addresses a fundamental gap in evaluating Large Language Models (LLMs): their ability to reproduce the relational structure of domain knowledge rather than just isolated facts. The authors introduce a multi-source, three-layer relational validation framework that compares LLM-induced knowledge graphs to expert-curated encyclopedic graphs across ten specialized domains such as philosophy, political science, psychoanalysis, and history. The framework measures alignment at the graph, node, and edge levels to diagnose how well an LLM reproduces expert-validated conceptual relationships.
Applying this framework to GPT-4-generated graphs revealed a consistent and significant relational deficit. While the LLM typically recognizes domain-specific concepts, it fails to reconstruct the curated network of relations connecting them. This failure is strongest in highly specialized domains where structural similarity and link recovery can approach zero, indicating that GPT-4’s internal representations do not align with nuanced conceptual architectures. The findings uncover a blind spot in current benchmarks, which mostly probe factual recall and local accuracy but do not capture relational fidelity. The paper argues for relational validation as a complementary evaluation paradigm critical for deploying LLMs in high-stakes scenarios that require deep, structured domain understanding.
Key findings
- Across 10 specialized encyclopedias, the average Semantic-Structural Similarity (SSS) Index measuring graph-level alignment between expert and LLM-induced graphs is only 0.0618, indicating poor global structural concordance.
- Node-level centrality correlations (In-Degree, Out-Degree, Betweenness, PageRank) between GPT-4 and expert graphs average 0.1467 Spearman rho, showing weak preservation of concept importance and influence.
- Edge-level link recovery (F1-score) averages just 0.0384, with recall extremely low (near zero) in most domains, indicating GPT-4 produces far fewer expert-curated cross-references than expected.
- Two domains—Grainger (Roman recipes) and Ness (American Social Movements)—exhibit complete relational failure with zero structural similarity and zero link recovery.
- Precision is generally higher than recall, suggesting GPT-4’s relational assertions are conservative and mostly correct when made but miss the majority of expert edges.
- Relational fidelity is highly domain-dependent, with stronger performance in broadly known fields and severe deficits in esoteric or highly specialized knowledge areas.
- Relational omission is structured and non-random, disproportionately affecting relations framing concepts in broader context over direct definitional links.
- Standard factual accuracy metrics do not correlate with relational coverage; models can recognize terms yet fail to reconstruct their conceptual networks.
Threat model
The paper does not explicitly define a traditional security threat model; rather it conceptualizes the challenge as validating an LLM's internal knowledge fidelity against expert relational structures. The 'adversary' is the structural misalignment or omission present within the LLM's knowledge representation, with the assumption that the model cannot produce relations beyond its learned representations. The evaluation assumes no malicious or purposeful deception by the LLM.
Methodology — deep read
Threat Model & Assumptions: The study assumes a black-box LLM (GPT-4) queried to return cross-referenced concepts for given domain-specific terms. The adversary here is conceptualized as the LLM’s internal knowledge representation missing the expert-curated relational structure. No direct adversarial attacks are modeled; the focus is on evaluating factual versus relational knowledge fidelity.
Data: Ten expert-curated encyclopedias were selected to represent diverse, specialized academic domains including the Cambridge Foucault Encyclopedia, Encyclopedia of Hate Groups in America, Encyclopedia of Conspiracy Theories, International Encyclopedia of Nonviolent Action, Lacanian psychoanalysis dictionary, and Roman Recipes by Apicius among others. For each encyclopedia, the lists of unique concepts (nodes) and their cross-references (edges) were extracted to construct ground-truth directed knowledge graphs.
Architecture/Algorithm: The LLM was prompted for each term with a standardized question asking which other entities would be referenced in an encyclopedia entry. Responses were used to build LLM-induced directed graphs under a conservative explicit-mention extraction criterion—only relations explicitly named in the output count as edges. This avoids semantic inference or paraphrase resolution.
Training Regime: Not applicable—this work evaluates a pre-trained, publicly available LLM (GPT-4) without further fine-tuning.
Evaluation Protocol: The framework compares the LLM-induced graphs with reference graphs at three levels:
- Graph-level: Structural similarity (Quadratic Assignment Problem/spectral methods), relational similarity (degree-normalized coverage ratios), and community similarity (Normalized Mutual Information on Louvain communities).
- Node-level: Spearman correlations on centrality measures (In-Degree, Out-Degree, Betweenness, PageRank).
- Edge-level: Precision, recall, and F1-score treating expert relations as ground truth.
Statistical significance testing details are not reported. Results are aggregated over all nodes and edges. Cases where LLM output graphs were empty (no edges) were reported as NaN or zero.
- Reproducibility: Code and frozen weights are not explicitly mentioned. Data sources are mostly expert-curated encyclopedias, which may not be fully public but are cited with references. Extraction rules and evaluation metrics are fully specified for replication.
Example: For a term in the Cambridge Foucault Encyclopedia, the LLM was prompted to list related terms explicitly referenced in that entry. These named relations were built into a directed graph and compared against the encyclopedia’s editorial cross-reference graph. Metrics showed very limited overlap, illustrating the relational deficit beyond mere term recognition.
Technical innovations
- A three-layer relational validation framework assessing LLM knowledge graph fidelity at the graph, node, and edge levels combining spectral, centrality, and link recovery metrics.
- Use of expert-curated encyclopedic sources as gold-standard relational knowledge graphs, contrasting with prior work relying on automatic or less vetted knowledge graphs.
- Conservative explicit-mention extraction criterion for LLM output to precisely quantify direct relational coverage without semantic inference, avoiding overestimation of relational knowledge.
- Application of network science methods (QAP spectral alignment, Louvain community NMI, rank correlations of centrality) to LLM output evaluation across multiple academic domains.
Datasets
- Cambridge Foucault Encyclopedia — size unspecified — expert-curated
- Encyclopedia of Social and Political Movements — size unspecified — expert-curated
- Encyclopedia of American Social Movements — size unspecified — expert-curated
- Encyclopedia of Hate Groups in America — size unspecified — expert-curated
- Encyclopedia of Conspiracy Theories in American History — size unspecified — expert-curated
- International Encyclopedia of Nonviolent Action — size unspecified — expert-curated
- Encyclopedia of Diversity and Social Justice — size unspecified — expert-curated
- Dictionary of Lacanian Psychoanalysis — size unspecified — expert-curated
- Encyclopedia of Cultural Studies — size unspecified — expert-curated
- Grainger’s Roman Recipes from Apicius — size unspecified — expert-curated
Baselines vs proposed
- No direct model baselines compared; evaluation is against static expert-curated graphs
- Graph-level SSS Index average: 0.0618 (LLM)
- Node-level centrality Spearman rho average: 0.1467 (LLM)
- Edge-level F1-score average: 0.0384 (LLM)
- Domains Grainger and Ness: Structural similarity and link recovery both 0.0 (LLM)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.22636.
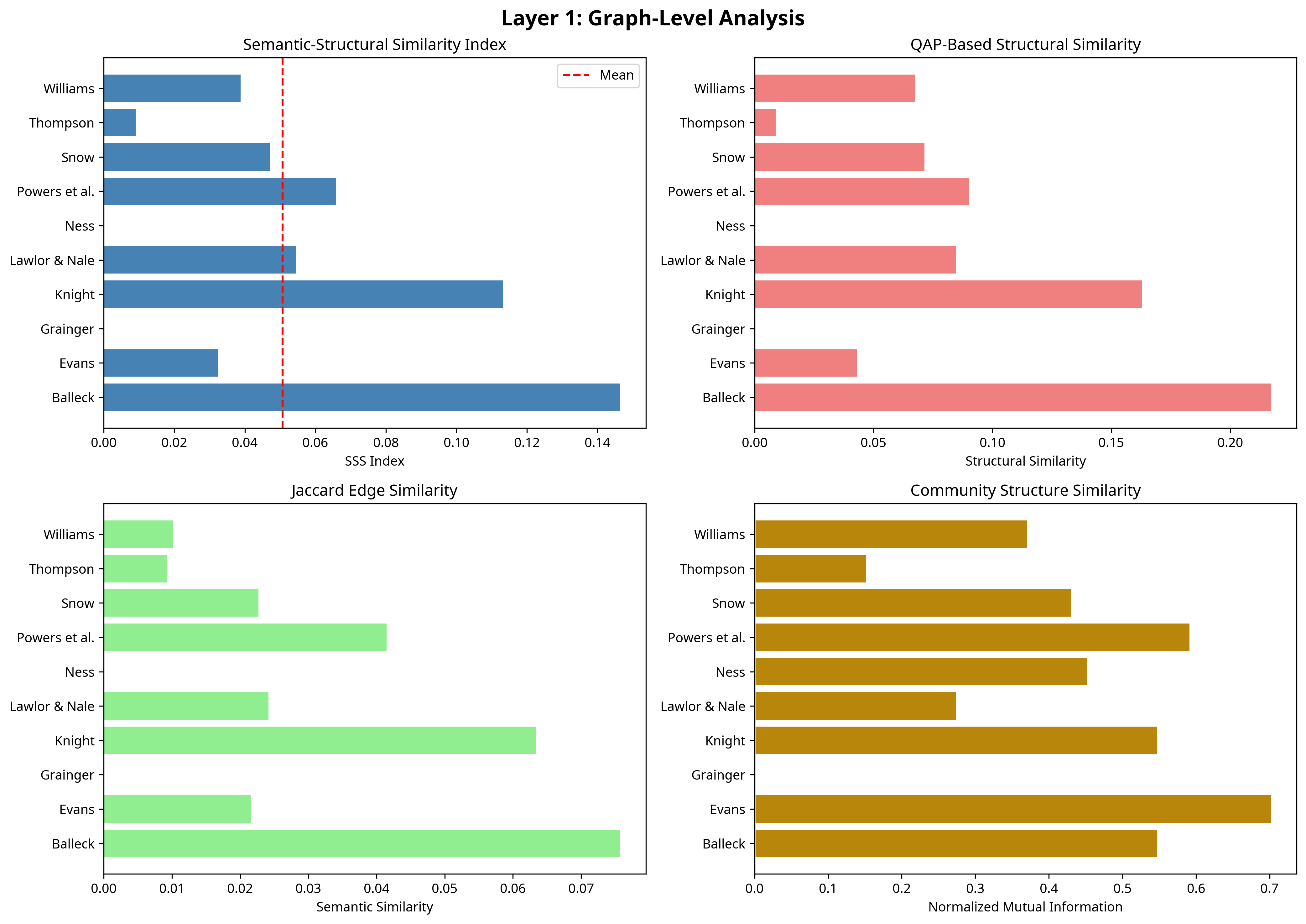
Fig 1: Layer 1 Results: Graph-Level Analysis
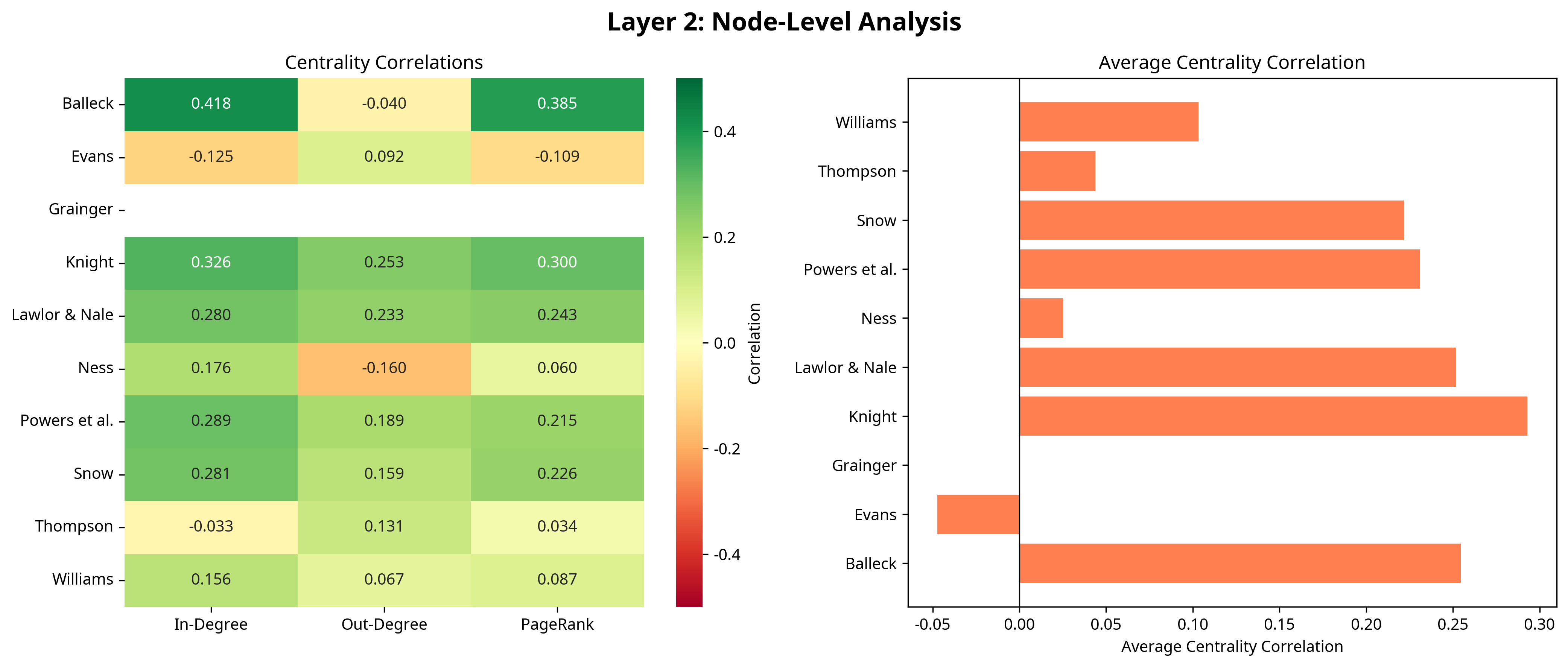
Fig 2: Layer 2 Results: Node-Level Analysis showing centrality correlations.
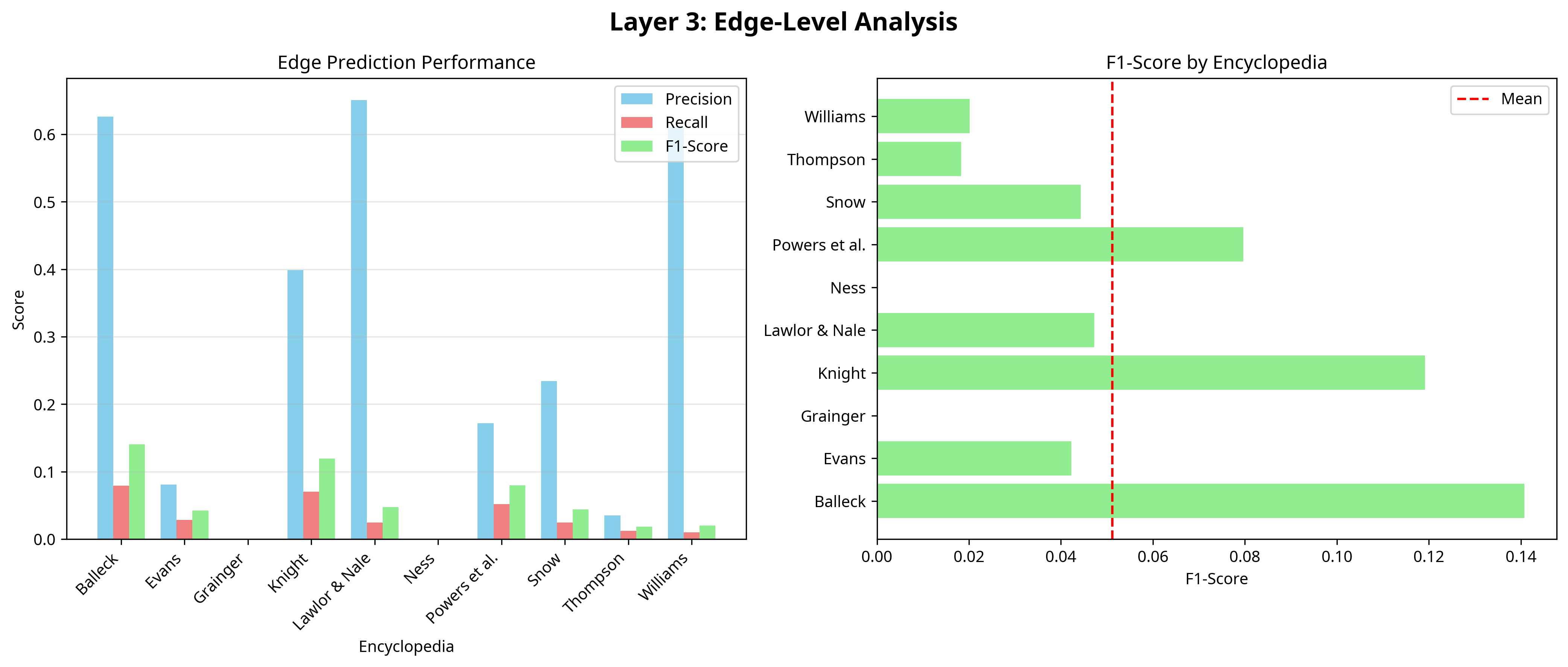
Fig 3: Layer 3 Results: Edge-Level Analysis showing precision, recall, and F1-scores.
Limitations
- The study uses a single LLM (GPT-4); results may not generalize to other models or future versions.
- Extraction methodology is conservative but may undercount relations due to wording variations or implicit references not captured by explicit mention.
- No adversarial or robustness testing against noisy or adversarial prompts.
- Specialized encyclopedias may vary in size and density of cross-references, influencing relational metrics but not controlled or normalized explicitly.
- No fine-grained error analysis on which relation types or concept subsets cause more failures.
- No exploration of integrating relational validation into model training or fine-tuning strategies.
Open questions / follow-ons
- Can integrating relational validation metrics during model fine-tuning improve relational fidelity in specialized domains?
- How do different LLM architectures or training corpus compositions affect relational knowledge representation?
- What role do implicit or inferred relationships (beyond explicit mention) play in relational coverage, and how can extraction methods capture them robustly?
- Can relational validation be extended to multi-modal or grounded knowledge sources for richer evaluation?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this study highlights a critical evaluation gap in LLM benchmarking related to structured domain understanding. While LLMs may appear fluent and factually accurate for many domains, their relational deficits reveal that they might not reliably reproduce conceptual networks foundational for nuanced reasoning or validation tasks. This suggests caution when deploying LLMs in bot-detection systems or CAPTCHAs requiring deep domain expertise or semantic coherence beyond surface text matching.
The proposed framework also offers a methodological template to evaluate whether AI-driven defense systems truly internalize relational features or simply recognize token patterns. Bot-defense engineers could consider incorporating relational validation into their evaluation pipelines to better understand model limitations, especially when modeling human knowledge about security concepts or attack taxonomies. Furthermore, the domain dependence signals the need to tune and validate models carefully according to the specialized knowledge requirements of their security applications.
Cite
@article{arxiv2605_22636,
title={ A Multi-Source Framework for Relational Validation of Large Language Models Using Expert-Curated Encyclopedic Sources },
author={ Moses Boudourides },
journal={arXiv preprint arXiv:2605.22636},
year={ 2026 },
url={https://arxiv.org/abs/2605.22636}
}