
Llamas on the Web: Memory-Efficient, Performance-Portable, and Multi-Precision LLM Inference with WebGPU
Source: arXiv:2605.20706 · Published 2026-05-20 · By Reese Levine, Rithik Sharma, Nikhil Jain, Abhijit Ramesh, Zheyuan Chen, Neha Abbas et al.
TL;DR
This paper addresses the challenge of running large language models (LLMs) efficiently and portably within web browsers, leveraging WebGPU for GPU acceleration. Existing browser-based LLM inference frameworks suffer from high memory overhead, limited cross-device performance portability, and insufficient quantization format support, constraining the usability and scalability of LLMs in browsers. The authors introduce LlamaWeb, a WebGPU backend for llama.cpp that overcomes these limitations by employing static memory planning to minimize memory usage, designing a tunable kernel library for performance portability across heterogeneous GPUs, and implementing templated GPU kernels that support many quantization formats prevalent in llama.cpp.
LlamaWeb is extensively evaluated on 16 devices from 8 vendors using 10 LLMs and 4 model weight formats. Compared to existing browser-based frameworks like WebLLM and Transformers.js, LlamaWeb reduces peak memory consumption by 29–33% and improves decode throughput by 45–69% across diverse GPUs. Compared to other llama.cpp backends, LlamaWeb achieves competitive or better GPU inference performance on some devices, while running fully inside browsers. This work thus significantly advances the state of browser-based LLM inference by enabling efficient, portable, and extensible support for GPU-accelerated inference across many hardware and quantization formats, unlocking broader deployment of LLMs on client devices without native installs.
Key findings
- LlamaWeb reduces peak memory usage by 29–33% across multiple devices, browsers (Chrome and Safari), and OSes compared to other browser-based LLM frameworks (Sec. 5).
- LlamaWeb yields a 45–69% improvement in decode throughput over WebLLM and Transformers.js across GPUs from four separate vendors (Sec. 6).
- LlamaWeb supports 23 model weight formats including 21 quantization formats, enabling execution of 177,691 models on Hugging Face GGUF format, vastly more than WebLLM (400) and Transformers.js (41,632) (Table 1).
- Kernel-level tuning based on empirical search across GPUs and models provides a 41% speedup over manually chosen kernel parameters, improving performance portability (Sec. 3.2).
- During inference, matrix multiplication dominates prefill phase runtime (92.6% @ KV-cache=0), while matrix-vector multiplication dominates decode (89.9%), guiding kernel optimizations (Table 2).
- LlamaWeb’s static memory planning allocates all model and intermediate buffers upfront, preventing dynamic allocations that can cause browser tab crashes under memory pressure (Sec. 3.1).
- LlamaWeb’s WebGPU shader templates tightly integrate quantization dequantization routines, allowing flexible and performant support for basic, k-quant, and i-quant formats (Sec. 3.3).
- Prefill throughput lags competitors by 21–51%, indicating room for future improvements in kernel specialization or scheduling during prompt processing (Sec. 6).
Threat model
The adversary is not explicitly modeled, as this work focuses on enabling efficient, portable LLM inference in untrusted, heterogeneous client environments. The main assumption is that the browser and device provide standard WebGPU capabilities without malicious interference, and memory/performance constraints are the primary challenges rather than security or adversarial evasion.
Methodology — deep read
The paper targets the threat model of deploying LLM inference engines on user devices via web browsers where memory and performance constraints vary widely, but adversarial threats are not the focus — instead the goal is to reliably run LLMs across diverse consumer devices with constrained GPU and memory resources.
Data for evaluation was collected from 16 devices representing 8 GPU vendors, covering 10 different LLMs and 4 model weight formats. Models come from the open-weight llama.cpp ecosystem using GGUF format with quantization variants, including basic q4_* formats and k-quant/i-quant styles. Browser support was tested across Chrome and Safari to capture variety in WebGPU implementations.
LlamaWeb’s implementation extends llama.cpp by adding a WebGPU backend written primarily in C++ with WASM compilation for browsers. It divides functionality into a runtime execution scheduler and a kernel library, with the kernel library generating WebGPU (WGSL) compute shaders via templated code specializing kernels for data type (f32, f16, quantized formats), device features (e.g., subgroup matrix multiplication), and tiling/vectorization parameters. Kernel compilation happens at runtime but caches pipelines for efficiency.
Memory management is statically planned: all buffers for model weights, KV cache, intermediate states, and kernel parameters are allocated once at load time to prevent runtime fragmentation and crashes. Weight loading streams asynchronously from browser persistent storage (OPFS) to GPU buffers without materializing large copies in WASM heap, mitigating memory overhead especially on Safari.
Kernel tuning is based on an extensive empirical sweep of thousands of parameter configurations (workgroup size, tile sizes) across four GPUs from different vendors using realistic LLM tensor shapes, selecting parameter sets that maximize average kernel throughput while minimizing worst-case slowdowns. This data-driven approach enables performance portability.
Evaluation metrics include peak browser memory usage during inference, decode throughput (tokens/sec) on GPUs, kernel-level performance profiling, output numerical accuracy (NMSE). Baselines include WebLLM and Transformers.js browser frameworks, as well as native llama.cpp backends (Metal, CUDA, HIP). Inference workloads separate prefill (processing prompt tokens) and decode (autoregressive token generation) phases.
Reproducibility is supported as all LlamaWeb code (~8.4k lines C++, 11k lines WGSL kernels) is open source and fully integrated into the llama.cpp codebase with 100+ PRs. Model data uses publicly available Hugging Face GGUF weights. Exact runtime measurements are extensively documented across browsers and devices.
A concrete end-to-end example is running Llama3 2 1B q4_k format model in Chrome on an Apple M3 GPU: Using static memory allocation, weights asynchronously streamed into GPU buffers, kernels compiled with specialized parameters, decode throughput improved 45–69% vs WebLLM, with 29–33% less memory usage recorded. Time is profiled showing matrix multiplications dominate prefill phase while matrix-vector kernels dominate decode phase execution time.
Technical innovations
- Static memory planning and fixed-size parameter buffer allocation reduces runtime GPU memory overhead and fragmentation in the browser environment, preventing crashes under tab memory limits.
- A templated WebGPU kernel library enables performance portability by allowing device- and format-specific kernel specialization including support for subgroup matrix instructions when available.
- Integration of quantization-aware kernel design supports 23 model weight formats, including basic, k-quants, and i-quants, enabling broad compatibility with diverse quantization strategies without native hardware support.
- Empirical cross-GPU kernel parameter autotuning selects workgroup and tile sizes that improve throughput by 41% over heuristics, balancing performance portability and peak efficiency.
- Streaming asynchronous weight loading directly into GPU buffers from persistent browser storage (OPFS) without materializing large WASM heap allocations optimizes memory usage during model initialization.
Datasets
- 10 language models from llama.cpp GGUF format — 177,691 compatible models on Hugging Face repository.
- Evaluation collected over 16 devices across 8 major GPU vendors.
- Model weight formats: 4 different quantization formats including q4_k, q4_0, q8_0, and others.
Baselines vs proposed
- WebLLM: decode throughput = baseline; LlamaWeb decode throughput = 54–69% higher
- Transformers.js: decode throughput = baseline; LlamaWeb decode throughput = 54–69% higher
- WebLLM: memory usage = baseline +49%; LlamaWeb memory usage = baseline (29–33% less than WebLLM)
- Transformers.js: memory usage = baseline +41%; LlamaWeb memory usage = baseline
- Native llama.cpp Metal backend (Apple GPU): LlamaWeb performance competitive or better on some devices (exact metrics vary).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.20706.
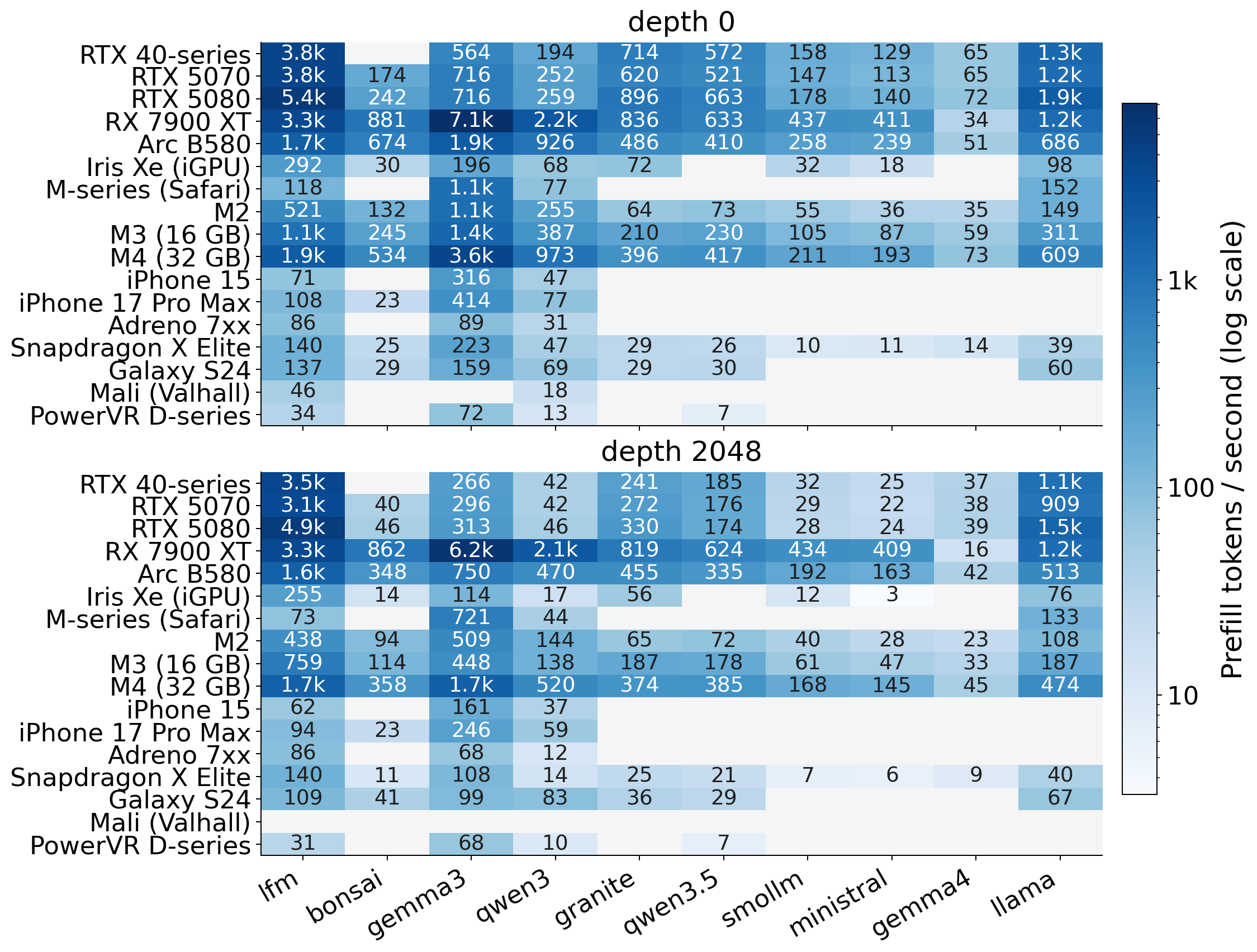
Fig 8: Coverage matrices for the portability and cross-quantization studies. Each cell reports throughput on a shared log
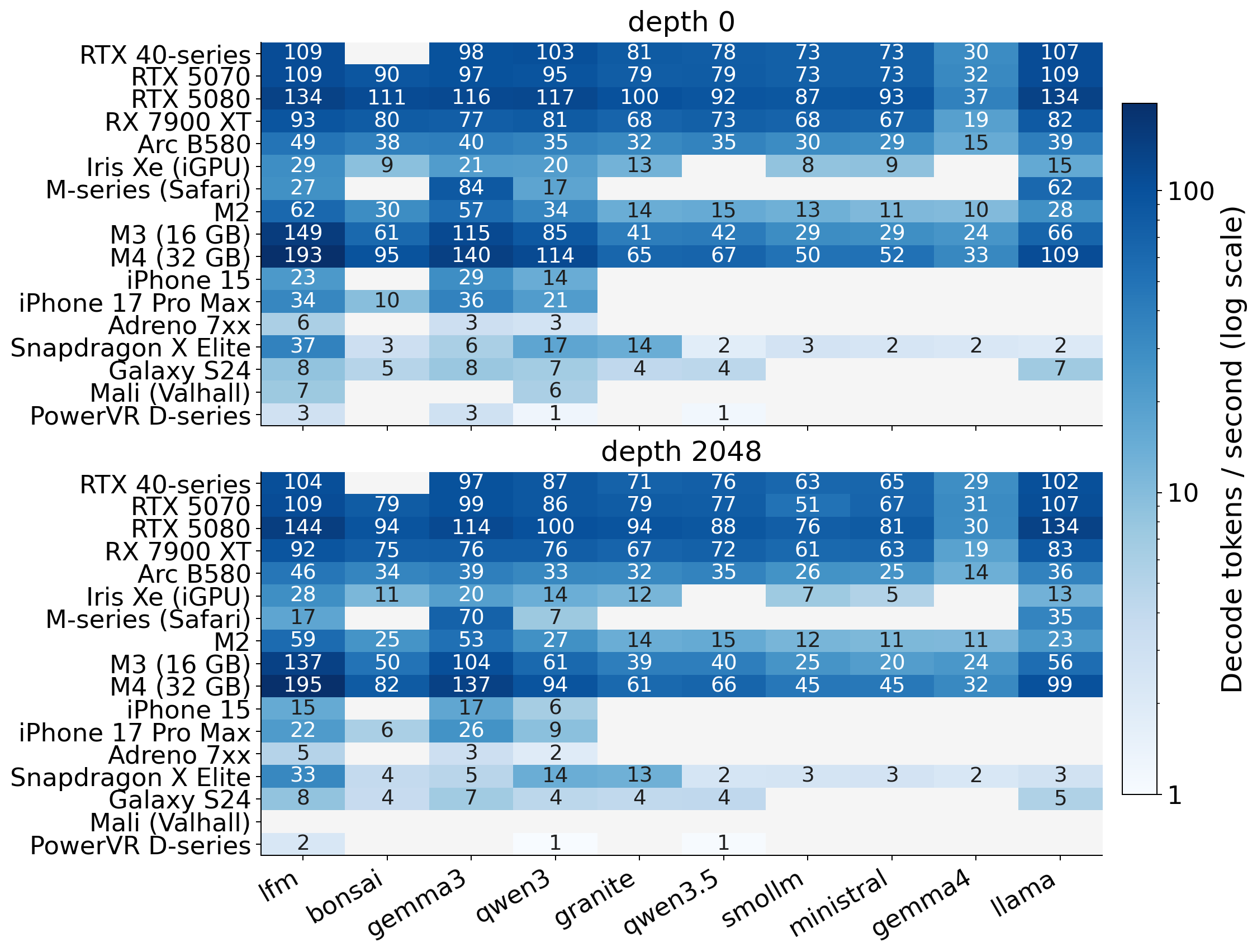
Fig 9: Per-device prefill and decode throughput by model, part 1 of 2.
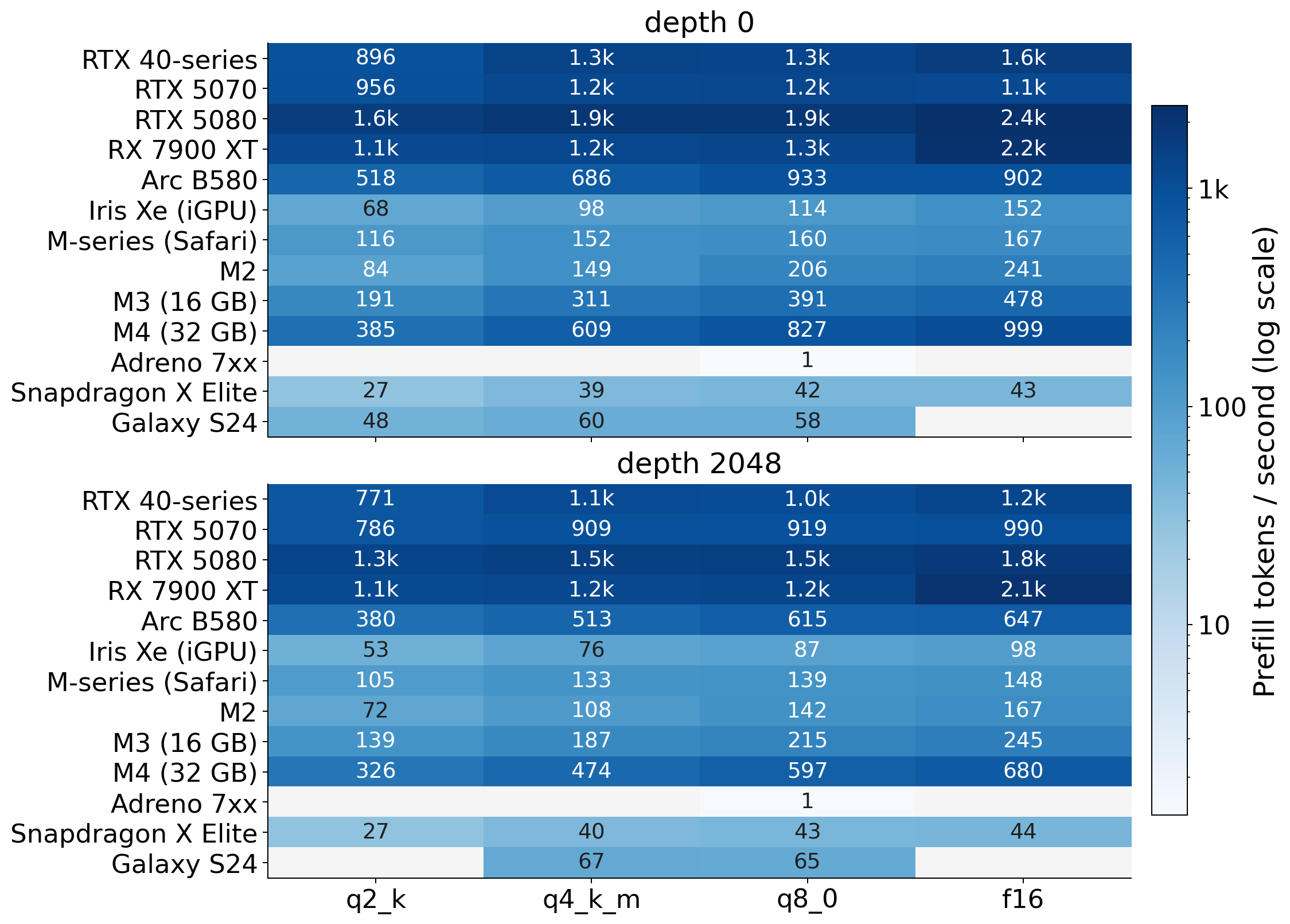
Fig 10: Per-device prefill and decode throughput by model, part 2 of 2.
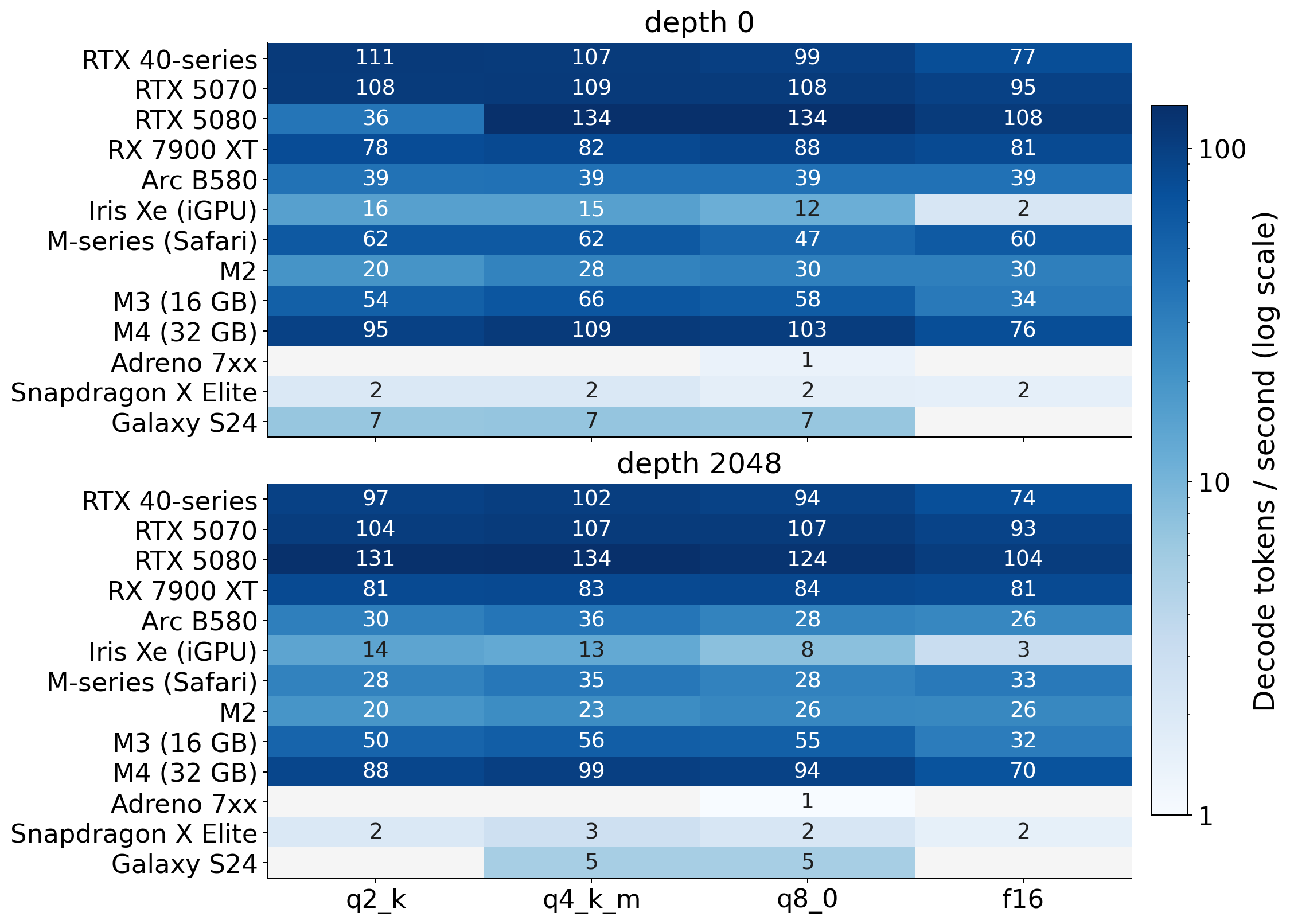
Fig 4 (page 16).
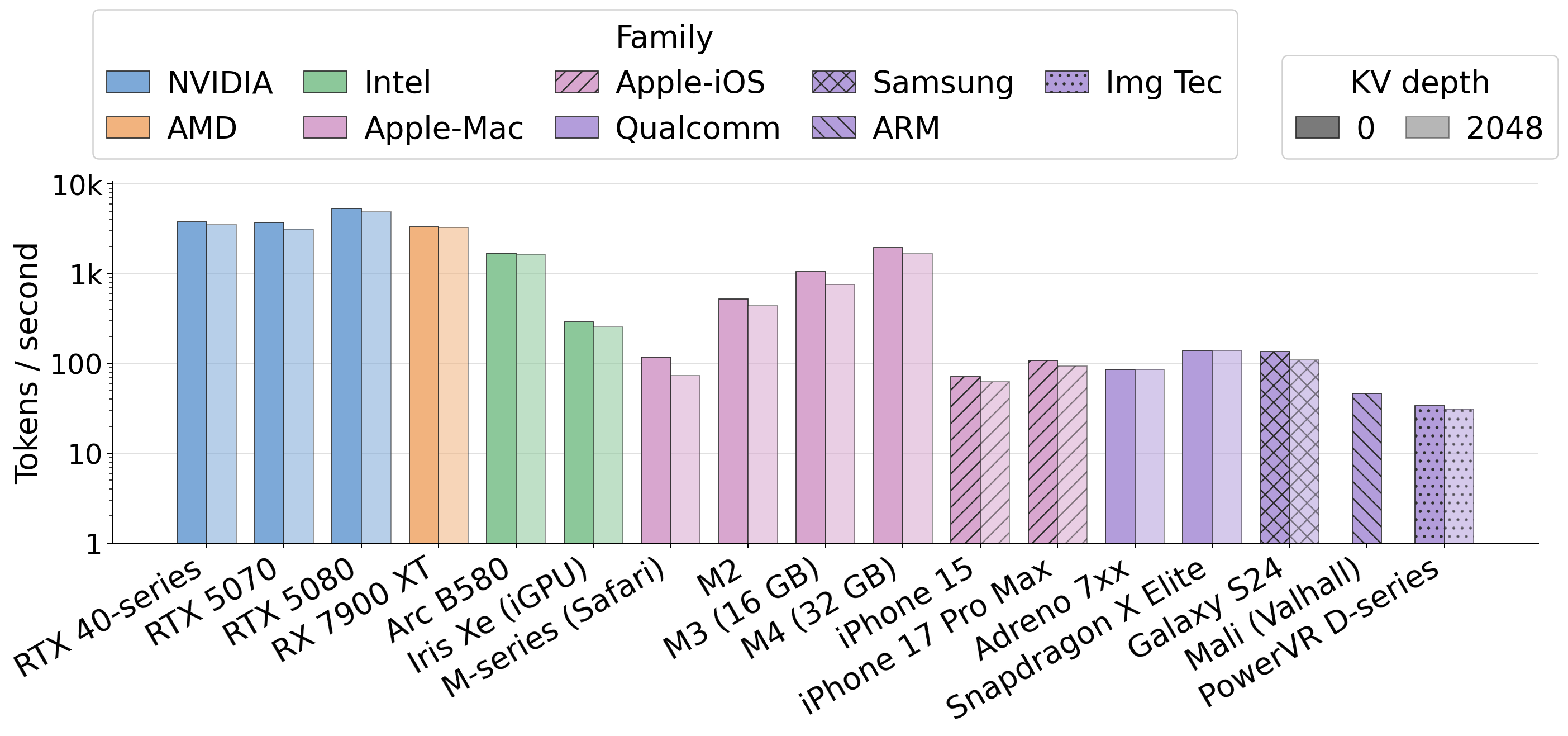
Fig 11: Per-device prefill and decode throughput for llama under different model weight formats.
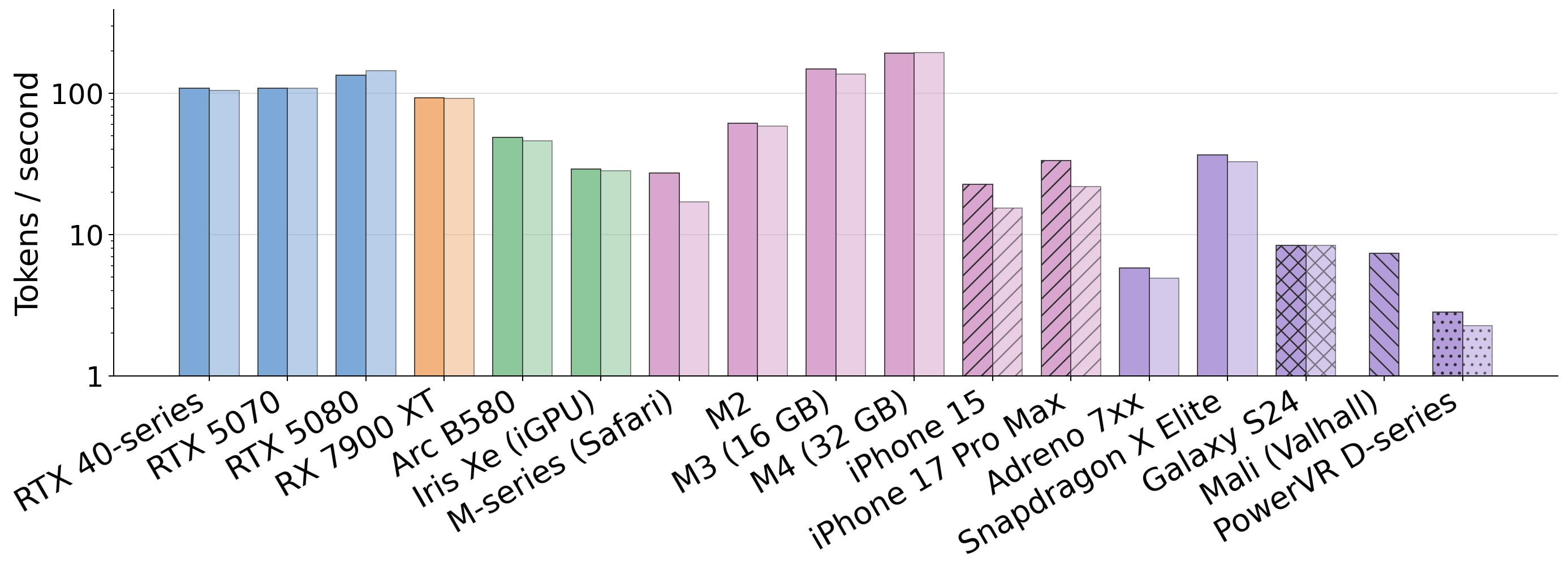
Fig 6 (page 17).
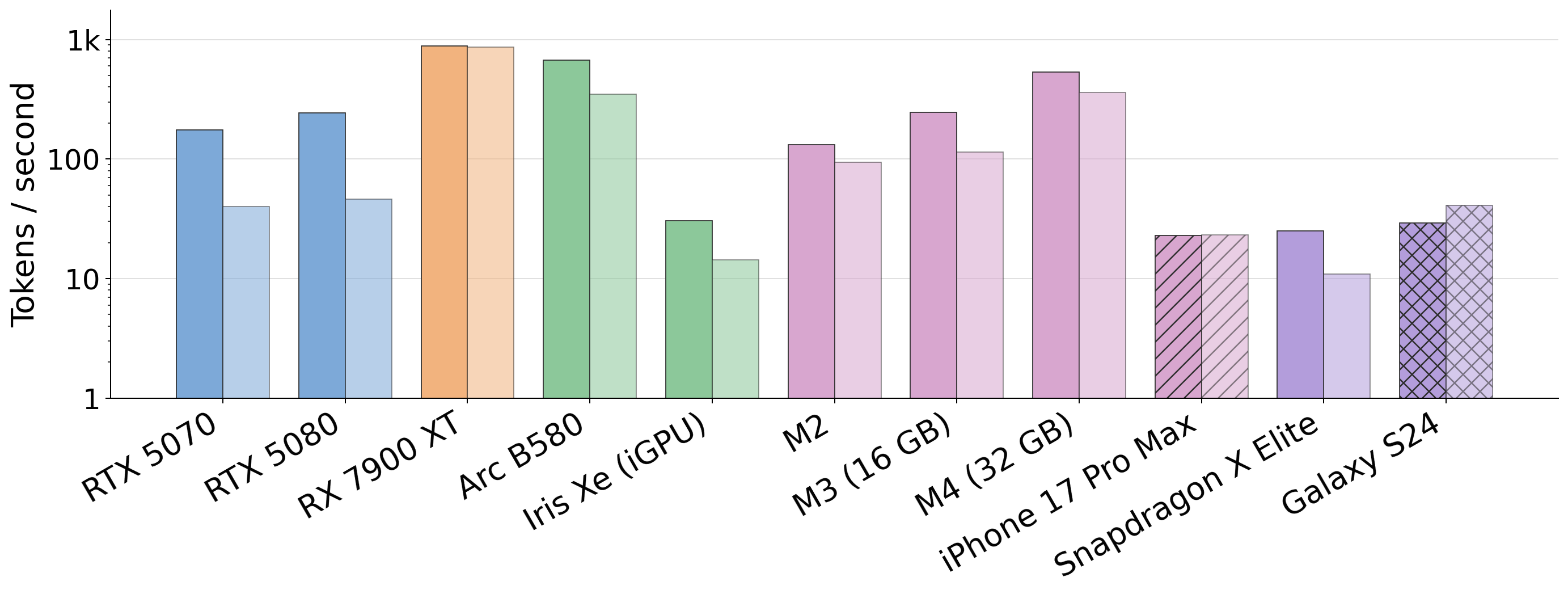
Fig 7 (page 17).
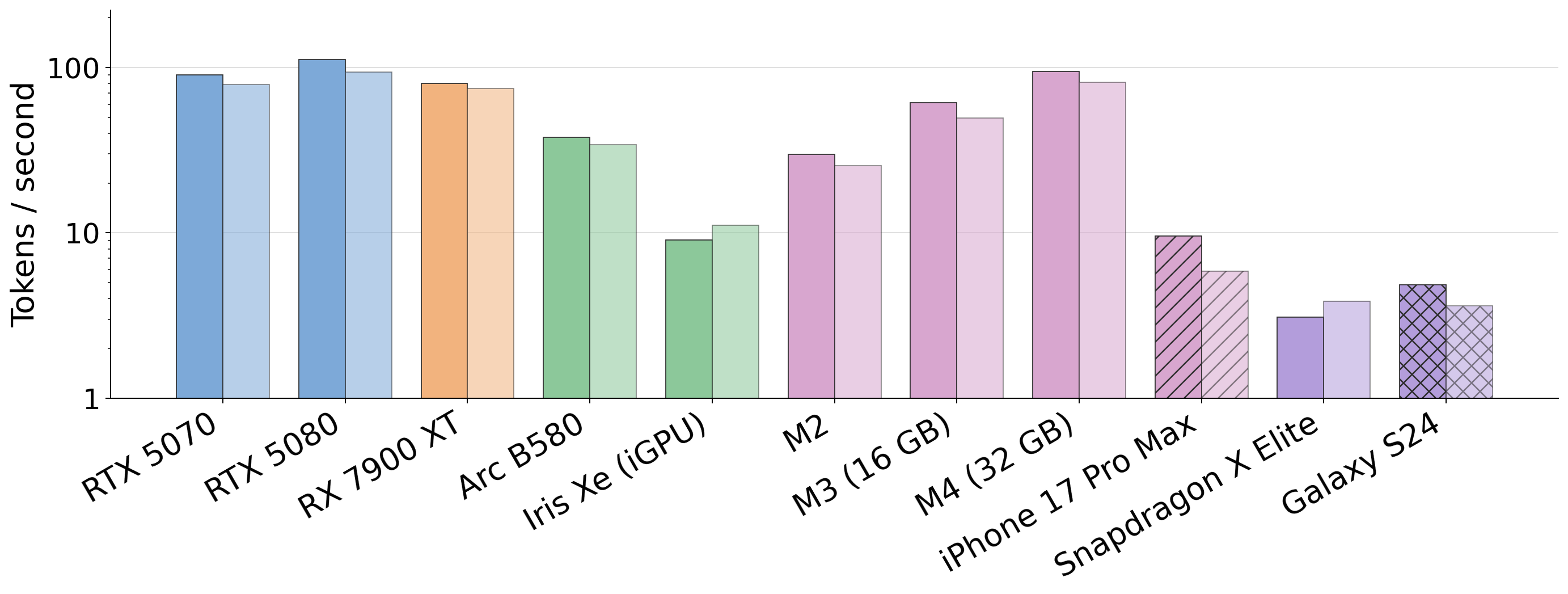
Fig 8 (page 17).
Limitations
- LlamaWeb shows lower throughput during prefill (processing prompts) compared to other browser frameworks by 21–51%, indicating kernel specialization for this phase needs improvement.
- The evaluation lacks adversarial robustness testing or security analysis; it focuses on performance and memory efficiency in benign conditions.
- Dynamic batching or multi-GPU scalability is not addressed — LlamaWeb targets single-GPU, low-latency inference typical in browsers.
- WebGPU limitations, such as lack of push constants and partial feature support in stable browsers, constrain some kernel optimizations.
- Floating-point precision issues (e.g., f16 rounding differences) cause increased numeric error on some devices, requiring relaxed validation thresholds.
- Some hardware-native quantization formats (like bf16, nvp4) are only partially supported via emulation, limiting model compatibility.
Open questions / follow-ons
- How can prefill kernel optimizations be improved to close the performance gap seen during prompt processing?
- Can autotuning be extended to cover a wider range of devices, browser implementations, and workload shapes to improve performance portability further?
- What new quantization formats or mixed-precision schemes can be efficiently supported in WebGPU kernels to improve model size-performance tradeoffs?
- How can WebGPU extensions (e.g., push constants, subgroup matrix instructions in stable browsers) be exploited to further reduce kernel overhead and memory usage?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners aiming to deploy LLM-powered challenges or detection directly in browsers with minimal user friction, LlamaWeb offers a practical solution to efficiently run many open-weight LLMs locally on diverse client GPUs. Its static memory planning avoids crashes due to browser-imposed memory caps, a common cause of degraded UX in heavy client workloads. The support for numerous quantization formats means developers can tailor model size and accuracy to client constraints, critical for latency-sensitive CAPTCHA scenarios.
Similarly, LlamaWeb’s performance portability across heterogeneous hardware via its kernel library reduces the need for device-specific tuning or native apps, simplifying deployment and maintenance. However, practitioners should note that prefill token throughput remains a bottleneck, which might impact responsiveness in tasks requiring long context processing. Overall, LlamaWeb advances the feasibility of integrating lightweight, privacy-preserving LLM inference within browser-based bot detection or CAPTCHA interfaces without requiring external backend calls.
Cite
@article{arxiv2605_20706,
title={ Llamas on the Web: Memory-Efficient, Performance-Portable, and Multi-Precision LLM Inference with WebGPU },
author={ Reese Levine and Rithik Sharma and Nikhil Jain and Abhijit Ramesh and Zheyuan Chen and Neha Abbas and James Contini and Tyler Sorensen },
journal={arXiv preprint arXiv:2605.20706},
year={ 2026 },
url={https://arxiv.org/abs/2605.20706}
}