
For How Long Should We Be Punching? Learning Action Duration in Fighting Games
Source: arXiv:2605.20911 · Published 2026-05-20 · By Hoang Hai Nguyen, Kurt Driessens, Dennis J. N. J. Soemers
TL;DR
This paper addresses the challenge of action timing in reinforcement learning (RL) agents playing fast-paced fighting games, specifically Street Fighter II - Special Champion Edition using the FightLadder framework. Traditional RL setups fix the decision frequency at a constant frame skip, trading off between unrealistic frame-perfect reactions (low frame skip) and poor responsiveness (high frame skip). The authors propose augmenting the RL agent's action space to jointly predict both which action to take and how long to execute it (i.e., the frame skip dynamically). They train agents with proximal policy optimization (PPO) against scripted built-in bots, comparing fixed, random, and learned frame skip strategies.
The experiments reveal that while agents can learn frame skip selection policies, they tend to select consistently high frame skip values, effectively making fewer decisions per second. High frame skip values simplify learning by enabling exploitative repetitive action patterns that are easy to execute against the scripted bots, leading to strong performance but poor generalization to other opponent characters. Fixed high frame skips perform similarly well to learned adaptive frame skips. The findings caution about evaluation biases when using susceptible scripted opponents and motivate future research into more robust training environments and constraints on decision frequency.
Key findings
- Agents autonomously selecting frame skip mostly pick high values (e.g. 16 or greater) regardless of game state (Fig. 4).
- Fixed frame skip of 16 or 60 achieved 100% win rate against Ryu (trained opponent) versus 89% for fixed 8 and 74% for fixed 4 (Table 1).
- Learned adaptive frame skip performance matches but does not surpass well-chosen fixed frame skip values.
- Agents trained against a single character using high frame skip exploit repetitive action loops that defeat scripted bots but generalize poorly to new opponent characters (Table 2).
- Finetuning agents on new opponents partially recovers performance but not fully, especially for stronger characters (Table 3).
- Agents strongly prefer repeatedly executing a small subset of combo moves rather than varying strategies (Fig. 6 and 7).
- Combining action and frame skip into a joint output head was less effective than separate heads due to combinatorial explosion.
- Training ran for 10 million timesteps with PPO, showing stable learning curves and steady improvement against training opponent (Fig. 3).
Threat model
The adversary is the in-game opponent characters controlled by built-in scripted AI with fixed, non-adaptive policies. The adversary cannot adapt to the agent's strategy or change their policy during training or evaluation. The RL agent has no access to internal opponent state, only raw pixel observations. Attackers cannot interfere with game mechanics or manipulate observations or rewards.
Methodology — deep read
Threat Model & Assumptions: The environment is the fighting game FightLadder (Street Fighter II - Special Champion Edition) running at 60 FPS. The adversary is any in-game opponent (scripted bots) with fixed policies. The agent observes stacked pixel frames (12 frames, stride 8) and must select actions at discrete decision points. The agent cannot access internal game states beyond pixels. The agent is trained via single-agent RL with PPO to maximize damage dealt while minimizing damage taken.
Data: Training data consists of gameplay experiences generated by running 8 parallel instances of the environment for 10 million timesteps. Observations are stacked frames forming tensor inputs. Rewards are shaped to incentivize damage to opponents and winning. Opponents during training are built-in scripted bots controlling the Ryu character at levels 1-8. Evaluations include matches against various unseen opponent characters.
Architecture / Algorithm: The policy network uses a CNN backbone from FightLadder with PPO optimization. For frame skip selection, two architectures are tested: (a) Separated head - two independent output heads predict standard action and frame skip discretely; (b) Combined head - a single output head predicts joint action-frame skip tuples. Frame skip values come from discrete sets (e.g., {4,6,8,10,12,14,16,32}). Actions include combinations of motion and attack plus special fixed combos.
Training Regime: Training uses PPO with a batch size of 1024, 20 epochs per update, learning rate decayed from 2.5e-4 to 2.5e-6, entropy coefficient 0.01, discount factor 0.94. Experience collected in parallel environments (8 copies). Reward shaping annealed for dense and aggressive coefficients from 3.0 and 1.0 to 1.0 and 0.0 respectively. Training spans 10 million timesteps.
Evaluation Protocol: Agents play 100 post-training evaluation games against the Ryu scripted AI at difficulty levels cycling from 1 to 8 to measure win percentage and episodic reward. Additional tests evaluate generalization to unseen opponent characters over 20 games each. Evaluation policies mainly select maximum probability actions to favor exploitation. Performance metrics reported include win percentage with 95% Agresti-Coull confidence intervals, episodic reward, and action distribution statistics.
Reproducibility: The work uses the open-source FightLadder environment, and standard PPO implementation with modifications for adaptive frame skip. The paper does not explicitly mention public release of code or weights. Data is generated online from environment interactions rather than fixed datasets.
Concrete example: The Separated (4-16) agent training involved learning to pick from discrete frame skips between 4 and 16 alongside game actions using PPO across 10 million timesteps, improving rewards steadily and converging to a policy strongly favoring high frame skips (~16). Evaluation matches showed 100% win rate versus Ryu but poor transfer to other opponents. The agent's policy over training episodes shifted probability mass toward selecting frame skip 16 repeatedly regardless of game state, illustrating learned exploitative temporal abstraction.
Technical innovations
- Incorporation of discrete, learnable action durations (frame skip values) into the RL agent action space to allow state-dependent decision timings, extending beyond fixed frame skip in typical RL setups.
- Two policy output architectures for joint decision of action and duration: separated heads for actions and frame skip versus combined joint action-frame skip output.
- Systematic empirical analysis contrasting fixed, random, and learned frame skip strategies in a realistic fighting game environment.
- Evaluation identifying that high frame skips provide implicit temporal abstraction enabling easy-to-learn exploitative strategies against scripted opponents.
Datasets
- FightLadder gameplay data from 10 million timesteps training runs — generated on the fly during RL training in open-source FightLadder environment
Baselines vs proposed
- Fixed frame skip 4: win rate against Ryu 74% ± 8.5% vs Fixed 16: 100% ± 2.6%
- Fixed frame skip 8 (default FightLadder): 89% ± 6.4% vs Separated (4-16) learned frame skip: 83% ± 7.4%
- Fixed frame skip 60: 100% ± 2.6% vs Random frame skip (4-16): 80% ± 7.9%
- Combined (4-8) policy head agent: 69% ± 9.0% win vs Separated (4-16,32): 100% ± 2.6%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.20911.
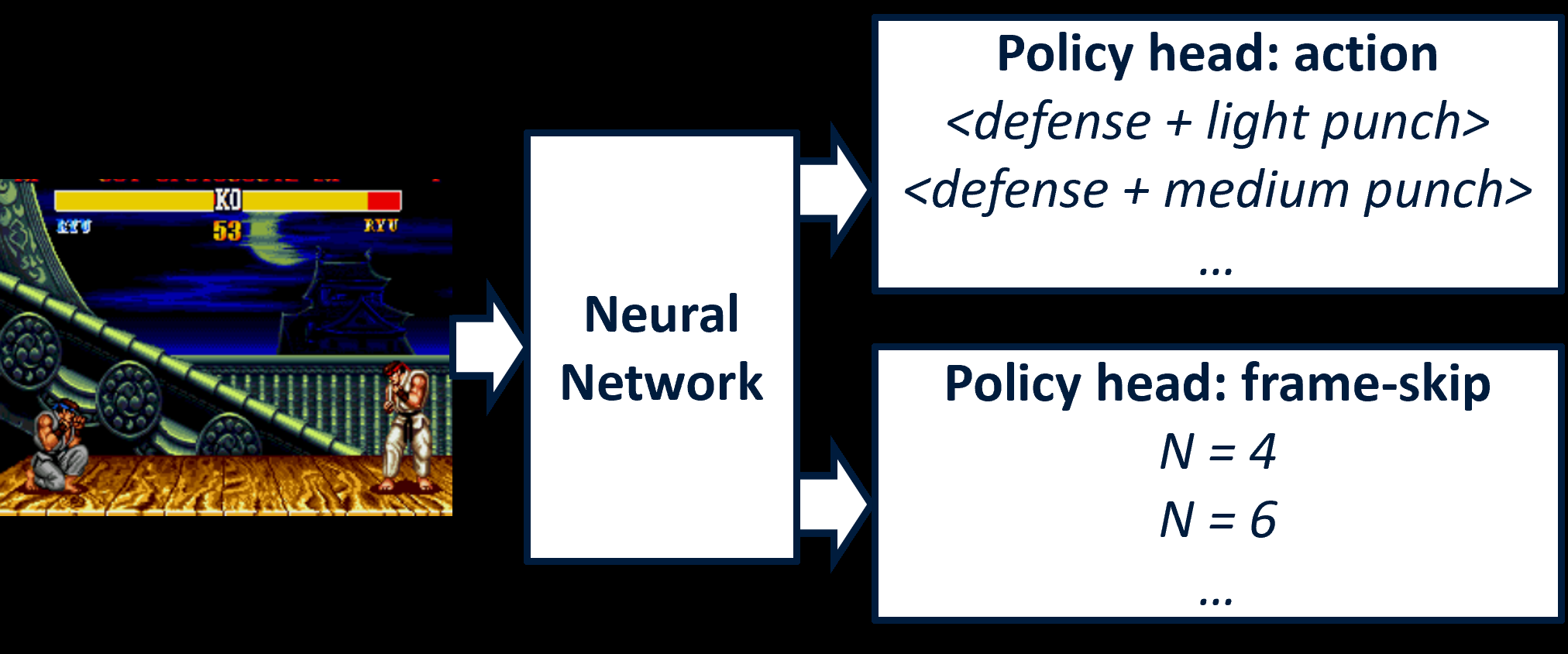
Fig 1: Policy architecture with separate heads. There is one policy head for combina-
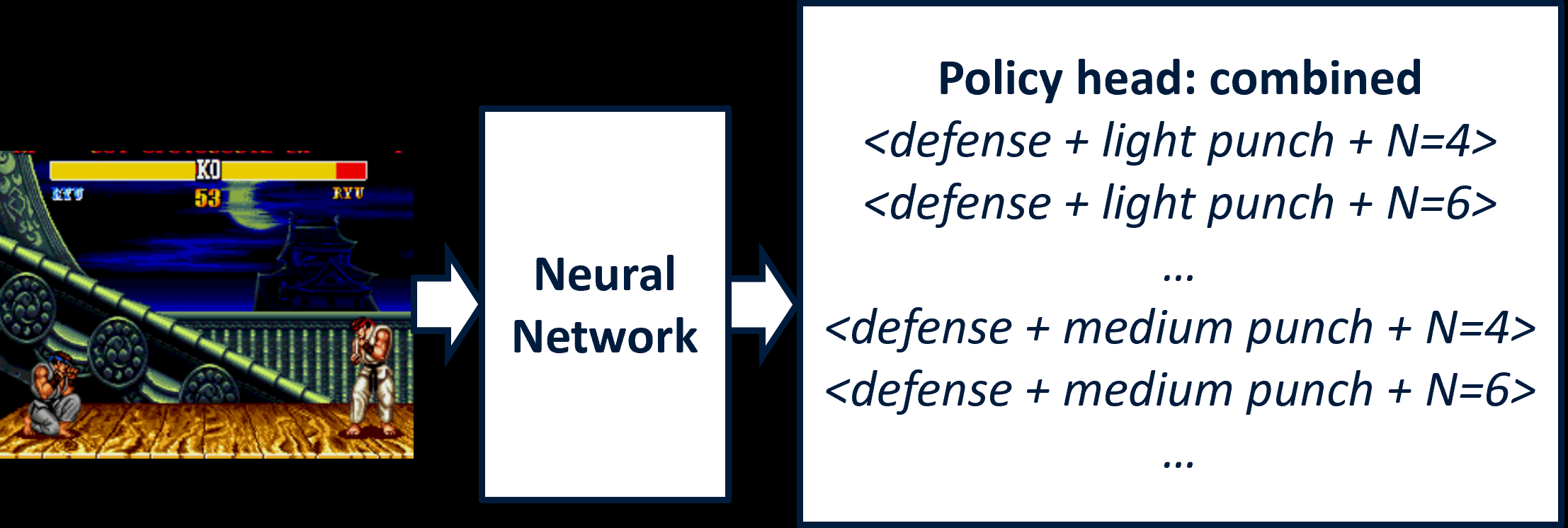
Fig 2: Policy architecture with combined head. Every action is a combination of move-
Limitations
- Evaluation adversaries are built-in scripted bots susceptible to exploitative repetitive strategies; lacks evaluation against stronger, adaptive opponents.
- Learned adaptive frame skip agents showed no clear benefit over well-chosen fixed frame skips in the tested environment and training setup.
- Limited range of frame skip values tested; combined policy head architecture does not scale well with larger frame skip action spaces.
- Poor generalization to unseen opponent characters without extensive finetuning, highlighting overfitting to training opponent behaviors.
- No analysis of impact of longer training durations or use of multi-agent self-play training regimes.
- No code or pretrained models publicly released, potentially limiting reproducibility.
Open questions / follow-ons
- How would adaptive frame skip strategies perform against stronger, adaptive or learning opponents rather than scripted bots?
- Can constraints on maximum decisions per unit time or reaction limits encourage more realistic, human-like timing policies?
- How might continuous (rather than discrete) action duration control affect agent responsiveness and performance?
- Could multi-agent or adversarial training mitigate exploitability of repetitive behaviors facilitated by high frame skip?
Why it matters for bot defense
This work offers insights into the tradeoffs between fixed decision frequency and adaptive timing in RL agents acting in real-time environments. For bot-defense engineers, the finding that agents tend to exploit temporal abstractions by repeating identical actions at high frame skips highlights a potential vulnerability in rule-based or scripted systems that rely on predictable timing windows. Adaptive timing models could be used to mimic or detect more human-like decision rhythms in adversarial settings, but also reveal risks where simplistic agents exploit coarse time granularity. Additionally, the general principle of learning when to act - not just what - might inspire more efficient or robust CAPTCHA challenges that vary timing requirements dynamically. However, since adaptive action duration did not outperform well-chosen fixed timing in this domain, careful evaluation under realistic adversarial conditions is critical before applying such techniques to security-sensitive applications.
Cite
@article{arxiv2605_20911,
title={ For How Long Should We Be Punching? Learning Action Duration in Fighting Games },
author={ Hoang Hai Nguyen and Kurt Driessens and Dennis J. N. J. Soemers },
journal={arXiv preprint arXiv:2605.20911},
year={ 2026 },
url={https://arxiv.org/abs/2605.20911}
}