
DeepWeb-Bench: A Deep Research Benchmark Demanding Massive Cross-Source Evidence and Long-Horizon Derivation
Source: arXiv:2605.21482 · Published 2026-05-20 · By Sixiong Xie, Zhuofan Shi, Haiyang Shen, Jiuzheng Wang, Siqi Zhong, Mugeng Liu et al.
TL;DR
DeepWeb-Bench addresses the challenge of evaluating deep research capabilities of language models, where answering requires massive evidence collection, cross-source reconciliation, and long-horizon multi-step quantitative derivation. Existing benchmarks mostly saturate at simpler retrieval or short synthesis tasks and fail to discriminate the current frontier agent abilities. DeepWeb-Bench introduces 100 complex research tasks structured as 8×8 entity-by-dimension matrices spanning four capability families (Retrieval, Derivation, Reasoning, Calibration). Each cell requires precise sourcing with provenance labels and cross-source agreement status to support auditable scoring.
Evaluation of nine leading language model configurations reveals that retrieval is not the main bottleneck, accounting for only about 12-14% of errors, while over 70% arise from derivation and calibration failures involving multiple-step composition or hallucinated precision. Stronger models mostly fail due to incomplete derivation, while weaker ones hallucinate precise answers without sufficient evidence. Models also demonstrate domain specialization with cross-model correlations around 0.61 and high per-case variance up to 18.8 percentage points. The benchmark dataset, rubric, source provenance, and evaluation code are publicly released to promote transparent and fine-grained evaluation for advancing deep research agents.
Key findings
- Retrieval failures account for only 12-14% of errors across tested models, while derivation and calibration failures exceed 70%.
- Strongest model, Codex CLI + GPT-5.5, achieved overall score of 33.37% versus weakest Kimi K2.6 at 16.79%, showing a 16.58 point spread.
- Derivation dimensions (50% of total) score about 26.10% overall, retrieval dimensions (12.5%) score highest at 32.83%.
- Strong models’ dominant failure mode is incomplete derivation (31% of failures), weak models’ is hallucinated precision (38%).
- Cross-model Spearman rank correlation across 100 tasks averages ρ = 0.61, meaning models fail differently on tasks.
- Per-case disagreement across models can reach 18.8 percentage points; hardest tasks involve reconciling non-standardized financial disclosures.
- Each reference answer cites on average 3.2 distinct URLs and 2.4 independent publishers per cell, with 2.8 derivation steps per derivation-type cell.
- Human validation on 200 sampled cells shows κ = 0.82 agreement with the automated GPT-5.5 scoring rubric.
Threat model
The adversary is a language model tasked with delivering accurate deep research findings from open web sources using constrained browsing tools. It cannot perform unrestricted internet browsing or external agent collaboration, and must act within fixed query budgets and time limits. The benchmark tests the model's susceptibility to errors in multi-step numerical derivation, evidence reconciliation, and hallucinated reporting rather than targeted malicious attack.
Methodology — deep read
Threat Model & Assumptions: The benchmark assumes a language model agent tasked with completing deep research assignments over open web data. The adversary here is effectively the model's inability to properly perform evidence retrieval, multi-step derivation, cross-source calibration, and prevention of hallucinated precision when evidence is insufficient. Models have the same tools for web search, page reading, and PDF reading with budgets (200 tool calls and 30 minutes per task). Native browsing tools of host CLIs are disabled to ensure uniform access.
Data: DEEPWEB-BENCH comprises 100 tasks covering six domains (Technology, Energy & Materials, Industrials & Transport, Consumer, Finance, Healthcare & Pharma). Each task involves an 8x8 matrix (entities × analytic dimensions), amounting to 6,400 scoring cells. Dimensions are partitioned into four families: 1 Retrieval, 4 Derivation, 1 Calibration, 2 Reasoning per task. Each cell’s reference answer includes precise numerical values or justified ‘not available’ markers with multi-step derivation chains linked to multiple authoritative sources (avg 3.2 URLs, 2.4 publishers per cell). Human experts crafted the tasks and references.
Architecture / Algorithm: The benchmark evaluates nine existing state-of-the-art language model configurations, including Codex CLI + GPT-5.5 and eight Claude Code CLI hosted models (Claude Opus 4.7, Claude Sonnet 4.6, DeepSeek V4 Pro/Flash, GLM 5.1, Qwen 3.6 Plus, MiniMax M2.7, Kimi K2.6). The models utilize benchmark-provided web search, page reading, and PDF fetch tools without internet browsing extensions. Model outputs must produce quantitative answers with derivation and provenance.
Training Regime: Not applicable; this is an evaluation benchmark without training. Models are frozen and tested in single isolated sessions per task with fixed computational and toolcall budgets.
Evaluation Protocol: Each cell is scored independently by an automated GPT-5.5 grader applying a four-level rubric ([1, 0.5, 0.25, 0]) depending on precision, partial correctness, relevance, or failure. ‘Not available’ cells scored based on justified abstention. The primary metric is mean cell score averaged over all tasks for each model. A stratified human validation of 200 cells confirmed automated grader consistency (κ = 0.82). Failure mode annotation on 500 failed cells categorizes errors (e.g., hallucinated precision, incomplete derivation).
Reproducibility: The authors publicly release the full benchmark dataset, including source provenance labels, derivation chains, rubrics, evaluation code, and full reference record. Model outputs and environment settings per run are documented. However, actual model weights are closed source.
Example: For a task requiring the per-vehicle gross profit of an EV manufacturer, the model must retrieve many financial figures (segment revenue, margin %, vehicle deliveries) from multiple authoritative sources labeled T1 or T2, reconcile conflicts, and perform accurate multi-step arithmetic. The grading rubric awards 1 point when the final value and derivation align with references within tolerance, 0.5 for roughly correct magnitude/direction but out of tolerance, 0.25 for partially relevant attempts, or 0 for hallucinations or unsupported answers.
Technical innovations
- Introduction of a structured 8x8 matrix task format that decomposes deep research into independently graded cells across four capability families.
- A four-level source-provenance annotation system (T1-T4) coupled with cross-source agreement labels enabling auditable evidence and scoring.
- An evaluation rubric separating retrieval, derivation, reasoning, and calibration failures to pinpoint specific bottlenecks.
- Demonstration that multi-step derivation and calibration, not retrieval, dominate failures in frontier deep research tasks, guiding future research focus.
Datasets
- DEEPWEB-BENCH — 100 tasks, 6,400 cells — curated multi-domain open-web sources with expert-curated provenance and derivation metadata
Baselines vs proposed
- Codex CLI + GPT-5.5: overall score = 33.37% vs Kimi K2.6: 16.79%
- Retrieval score ranges from 26.21% (Kimi K2.6) to 37.84% (Codex CLI + GPT-5.5)
- Derivation score ranges from 15.36% (Kimi K2.6) to 32.55% (Codex CLI + GPT-5.5)
- Calibration score ranges from 16.39% (Kimi K2.6) to 34.16% (Codex CLI + GPT-5.5)
- Reasoning score ranges from 15.13% (Kimi K2.6) to 32.38% (Codex CLI + GPT-5.5)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.21482.
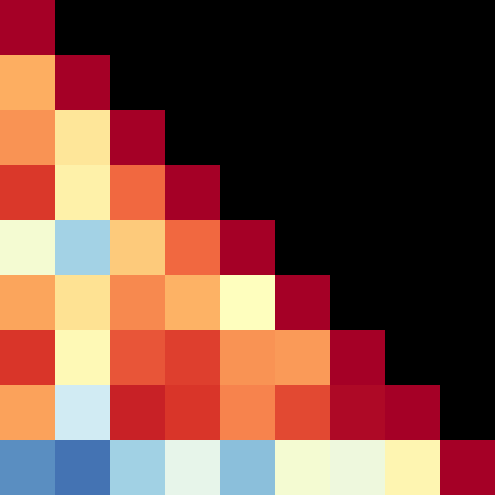
Fig 3: Fine-grained score variation across the 100 tasks. (a) Pairwise Spearman rank correlation

Fig 7: Per-domain performance heatmap. Energy & Materials is the hardest domain (cross-model
Limitations
- Overall absolute scores are low (max ~33%), reflecting high task difficulty but leaving much headroom.
- Evaluation limited to nine models; results may vary for other architectures or future models.
- No adversarial or dynamic content evaluation; the benchmark uses static tasks and closed evaluation rubric.
- The reliance on GPT-5.5 automated grading, although validated, may embed grader model biases.
- Limited direct analysis of model tool usage strategies or broader multi-agent collaboration effects.
Open questions / follow-ons
- What novel training or prompting methods can specifically improve multi-step numerical derivation accuracy?
- How can models be better calibrated to abstain from answering when evidence is insufficient, reducing hallucinated precision?
- Can the benchmark be extended to incorporate real-time updating web content or adversarial source manipulations?
- How might multi-agent collaborative approaches fare on these complex multi-source reconciliation tasks?
Why it matters for bot defense
For practitioners in bot defense and CAPTCHA design, DeepWeb-Bench offers a rigorous, multifaceted evaluation framework of language model capabilities for open-web research. This is valuable because it highlights that retrieval alone is not the limiting factor—bots or automated agents can acquire raw evidence well, but struggle with complex multi-document numerical synthesis and calibrated answering. Defensive mechanisms could thus focus on detecting or challenging multi-step reasoning and cross-source validation steps, which remain brittle in state-of-the-art models. The benchmark's provenance and calibration dimensions provide auditability and transparency, important for understanding bot confidence versus hallucination risks.
Additionally, the benchmark’s domain specialization findings suggest that bot capabilities vary widely by content area, implying that domain-specific CAPTCHA or bot-challenge designs could exploit observed weaknesses in numerical derivation or calibration. Practitioners designing robust CAPTCHA systems or bot defenses targeting AI research assistants may benefit from adopting similar multifactor challenge approaches that test retrieval, derivation, reasoning, and calibration in combination rather than relying on simple evidence recognition tasks.
Cite
@article{arxiv2605_21482,
title={ DeepWeb-Bench: A Deep Research Benchmark Demanding Massive Cross-Source Evidence and Long-Horizon Derivation },
author={ Sixiong Xie and Zhuofan Shi and Haiyang Shen and Jiuzheng Wang and Siqi Zhong and Mugeng Liu and Chongyang Pan and Peilun Jia and Baoqing Sun and Xiang Jing and Yun Ma },
journal={arXiv preprint arXiv:2605.21482},
year={ 2026 },
url={https://arxiv.org/abs/2605.21482}
}