
Weasel: Out-of-Domain Generalization for Web Agents via Importance-Diversity Data Selection
Source: arXiv:2605.20291 · Published 2026-05-19 · By Fatemeh Pesaran zadeh, Seyeon Choi, Xing Han Lù, Siva Reddy, Gunhee Kim
TL;DR
WEASEL addresses two critical challenges in training large language model (LLM)-based web agents: out-of-domain generalization and training inefficiency caused by noisy, redundant offline web interaction data. Existing agents fine-tuned on domain-specific trajectories often suffer sharp performance drops when deployed on unseen websites or interaction patterns. WEASEL tackles this by formulating trajectory curation as a fixed-budget subset selection problem that jointly optimizes importance (semantic relevance to the goal) and diversity (coverage across states, websites, and interaction patterns). Its efficient greedy algorithm selects a compact yet informative subset of trajectory steps, pruning irrelevant page content with a target-centered AXTree method and adapting reasoning traces to the model’s style via self-generated rationales. Across diverse datasets (AgentTrek, NNetNav) and zero-shot benchmarks (WebArena variants, MiniWob, WorkArena), WEASEL consistently improves out-of-domain success rates while achieving 9.7-12.5× training speedups compared to full-data fine-tuning. This makes it the first data selection approach explicitly designed to improve both robustness and efficiency for offline web agent training.
Key findings
- WEASEL yields up to +4.8 percentage point improvement in zero-shot success rate transferring from AgentTrek to WebArena-Lite using Qwen3-8B (Figure 1, Table 1).
- Target-centered AXTree pruning reduces input token length by ~68%, achieving 2× training speed-ups while maintaining or improving success rates on WebArena-Lite (Table 3, Figure 3).
- Combining importance and diversity in the subset selection objective achieves 14.5% success rate on WebArena-Lite with Qwen2.5-7B, outperforming importance-only (10.9%) and diversity-only (7.9%) baselines (Table 7).
- The greedy subset selection algorithm is near-optimal, matching the exact optimum in >96% of evaluated trajectories, despite using non-metric semantic distances (Section 3.3).
- Replacing expert reasoning traces with model-generated style-consistent rationales improves stability and out-of-domain generalization, boosting success rates from 17.0% to 21.2% on WebArena-Lite with Qwen3-8B (Table 4).
- WEASEL’s 10K-step curated training subsets match or exceed performance of full 52K-step fine-tuning at roughly 10-12× faster training time across multiple model sizes (Table 1).
- Using the max composition of state and model answer diversity produces the best transfer success rates, with state-only or reasoning-only diversity underperforming (Table 6).
- WEASEL outperforms uniform sampling and LLM-judge based data selection baselines by 3-6% absolute success rate on zero-shot web benchmarks under fixed training budgets (Tables 1 and 2).
Threat model
The adversary is implicit and non-adaptive; the primary challenge is distributional shift arising from novel websites, UI layouts, and interaction patterns unseen during training. The adversary cannot manipulate training data or influence model internals but exposes the agent to domain shifts during deployment, necessitating robustness to new environments. Adversarial attacks, evasion, or poisoning scenarios are out of scope.
Methodology — deep read
The core methodology centers on data curation for offline supervised fine-tuning of web agents represented by expert trajectories from datasets like AgentTrek and NNetNav. Given trajectories τ with sequences of states, actions, interaction histories, goals, and reasoning traces, the fundamental goal is to select a fixed-budget subset J of trajectory steps (|J| = T0 << T) to train an action-and-reasoning prediction policy πθ.
Threat model & assumptions: The agent is offline-trained with no adaptive adversary; the challenge is distribution shift to unseen websites and interaction patterns rather than adversarial attacks.
Data: AgentTrek (52K steps) and NNetNav-Live offline datasets; trajectories contain diverse multi-step browser interactions. Data includes expert actions grounded on AXTree elements and expert reasoning traces. Training and test splits reflect distinct websites and interaction domains.
Algorithm: WEASEL formulates subset selection as maximizing a quadratic objective combining unary importance Φ(t) and pairwise diversity D(i,j). Importance is computed via BERTScore alignment of the goal with each step's web state, quantifying semantic relevance. Diversity measures differences between states or model answers with 1 - BERTScore, combined by max to encourage coverage of heterogeneous contexts and rationales.
The combinatorial NP-hard problem is solved approximately by a greedy algorithm: initialize with the best pair (i1,i2) maximizing their combined importance plus weighted diversity; then iteratively add points maximizing marginal gain until budget T0 is reached.
Target-centered AXTree Pruning: To reduce state sequence length, each web state’s linearized AXTree is pruned to a fixed-size window around the gold action’s target node, preserving only locally relevant nodes. Non-node actions keep a fixed-length prefix. This substantially decreases input lengths, alleviating model context constraints and training cost.
Self-Reasoning Synthesis: For reasoning-native models like Qwen3, style mismatch occurs when fine-tuning on expert traces from other sources. To mitigate this, the model self-generates style-consistent reasoning rationales conditioned on the goal, pruned state, and expert action via prompting, replacing original expert rationales. The policy is then fine-tuned to predict the synthesized trace along with the expert action.
Training regime: Fine-tuning uses 2-4 epochs depending on model size, with batch sizes and learning rates detailed in appendix (not specified here). Hyperparameters are held constant across ablations. Hardware is standard GPU clusters; exact specs not detailed. Multiple model families (Qwen2.5-7B, Gemma3-4B, Qwen3-8B) are trained separately under comparable conditions.
Evaluation: Agents are evaluated zero-shot on out-of-domain benchmarks WebArena-Lite, WebArena, MiniWob, and WorkArena, using GPT-based automated judges measuring success rate (SR). Baselines include full dataset fine-tuning, uniform sampling subsets, and LLM-as-judge selections to isolate WEASEL effects. Ablations test importance vs diversity terms, pruning methods, and reasoning synthesis.
Example: For AgentTrek dataset (52K steps, max 45-step trajectories), WEASEL prunes states per step via target-centered method, then scores steps via BERTScore between goals and states. The greedy algorithm selects 10K steps maximizing the sum of importance plus diversity against previously selected steps. Self-reasoning traces are generated for Qwen3-8B and the policy fine-tuned on this curated subset. The resulting agent attains 14.5% success on WebArena-Lite zero-shot, outperforming 10.9% for importance-only and 7.9% for diversity-only subsets, while reducing training time by over 11×.
Code and datasets are publicly released, permitting reproducibility (https://github.com/fatemehpesaran310/weasel). Detailed hyperparameters and prompts are included in appendices. Some components (the exact AXTree linearization and pruning) rely on prior work but are well explained. Evaluation uses fixed seeds for stability. The greedy algorithm is deterministic given input scores, with empirical validation that results are near-optimal.
Technical innovations
- Formulation of a trajectory subset selection objective combining unary importance (goal-state semantic alignment) and pairwise diversity (max of state and model answer dissimilarities) for web agent training data curation.
- Efficient greedy approximation algorithm to solve the NP-hard max-sum diversification problem on semantic pseudo-distances, demonstrated to be near-optimal empirically.
- Target-centered AXTree pruning method that retains only a local window of DOM nodes around the gold action target, drastically reducing noisy input tokens and accelerating training.
- Self-reasoning synthesis technique where the target model generates style-consistent reasoning traces during fine-tuning to mitigate reasoning style mismatch from expert trace sources.
Datasets
- AgentTrek — 52,000 trajectory steps — publicly released synthetic web agent trajectory dataset
- NNetNav-Live — 52,000 trajectory steps — real-world browsing interactions with retro-labeling
- WebArena(-Lite) — evaluation benchmark for zero-shot web agent testing on unseen websites
- MiniWob — benchmark of web tasks for agent evaluation
- WorkArena — compositional web agent benchmark
Baselines vs proposed
- Full fine-tuning (52K steps) Qwen2.5-7B: WebArena-Lite SR = 10.9 vs WEASEL (10K steps) = 14.5 (+3.6)
- Pruning + sampling (10K steps) Qwen2.5-7B: WebArena-Lite SR = 9.1 vs WEASEL = 14.5 (+5.4)
- LLM-Judge data selection (10K steps) Qwen2.5-7B: WebArena-Lite SR = 8.5 vs WEASEL = 14.5 (+6.0)
- Full fine-tuning Qwen3-8B: WebArena SR = 18.2 vs WEASEL (10K) = 19.2 (+1.0)
- Pruning strategies comparison (Qwen2.5-7B, AgentTrek 10K subset): Target-centered pruning SR = 10.9 vs Semantic pruning = 9.1 vs Prune-by-Bid = 8.5
- Importance only (Φ) SR = 10.9 vs Diversity only (D) = 7.9 vs WEASEL combined = 14.5 (Qwen2.5-7B WebArena-Lite)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.20291.
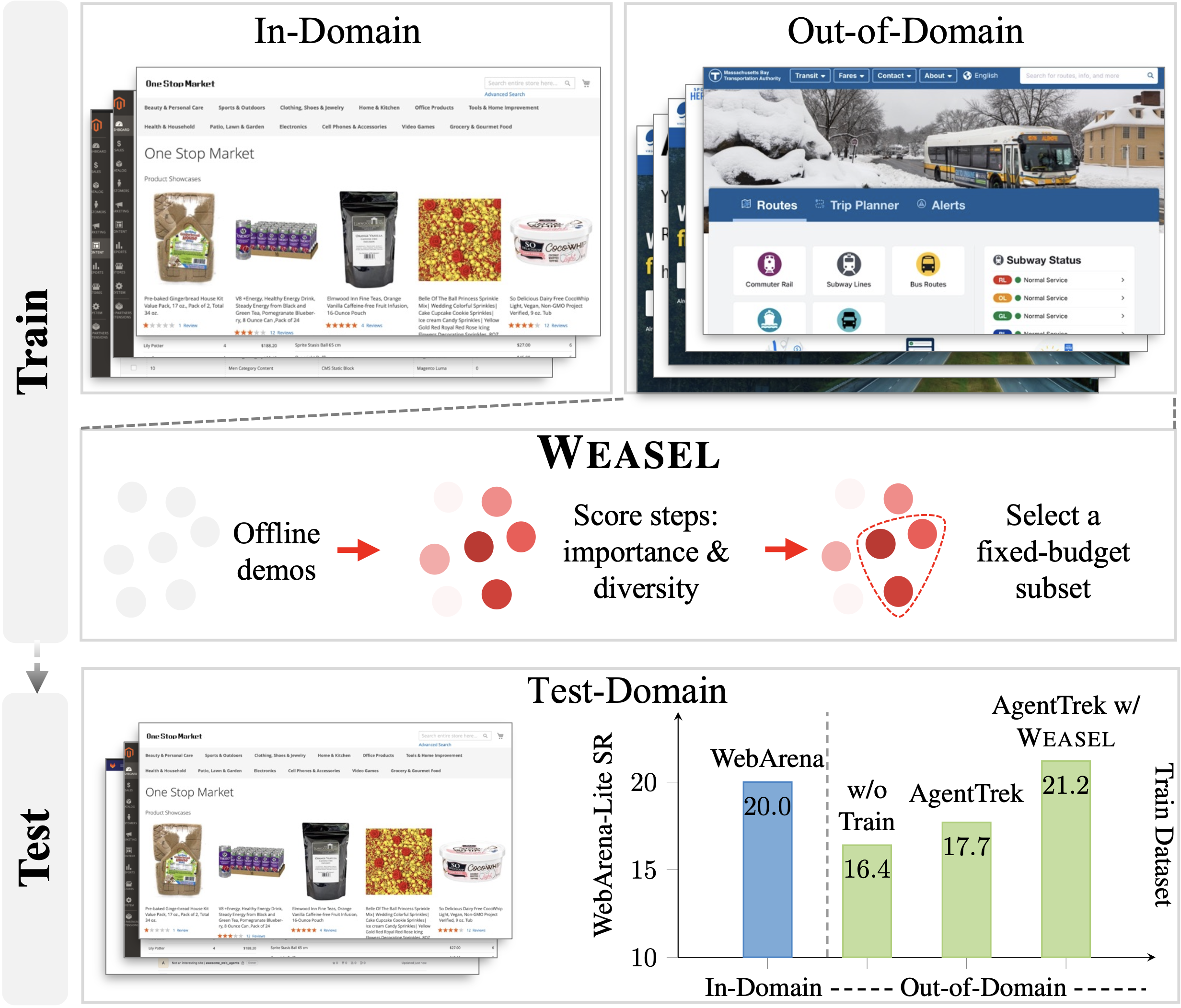
Fig 1: Overview of WEASEL. Conventional trained web agents
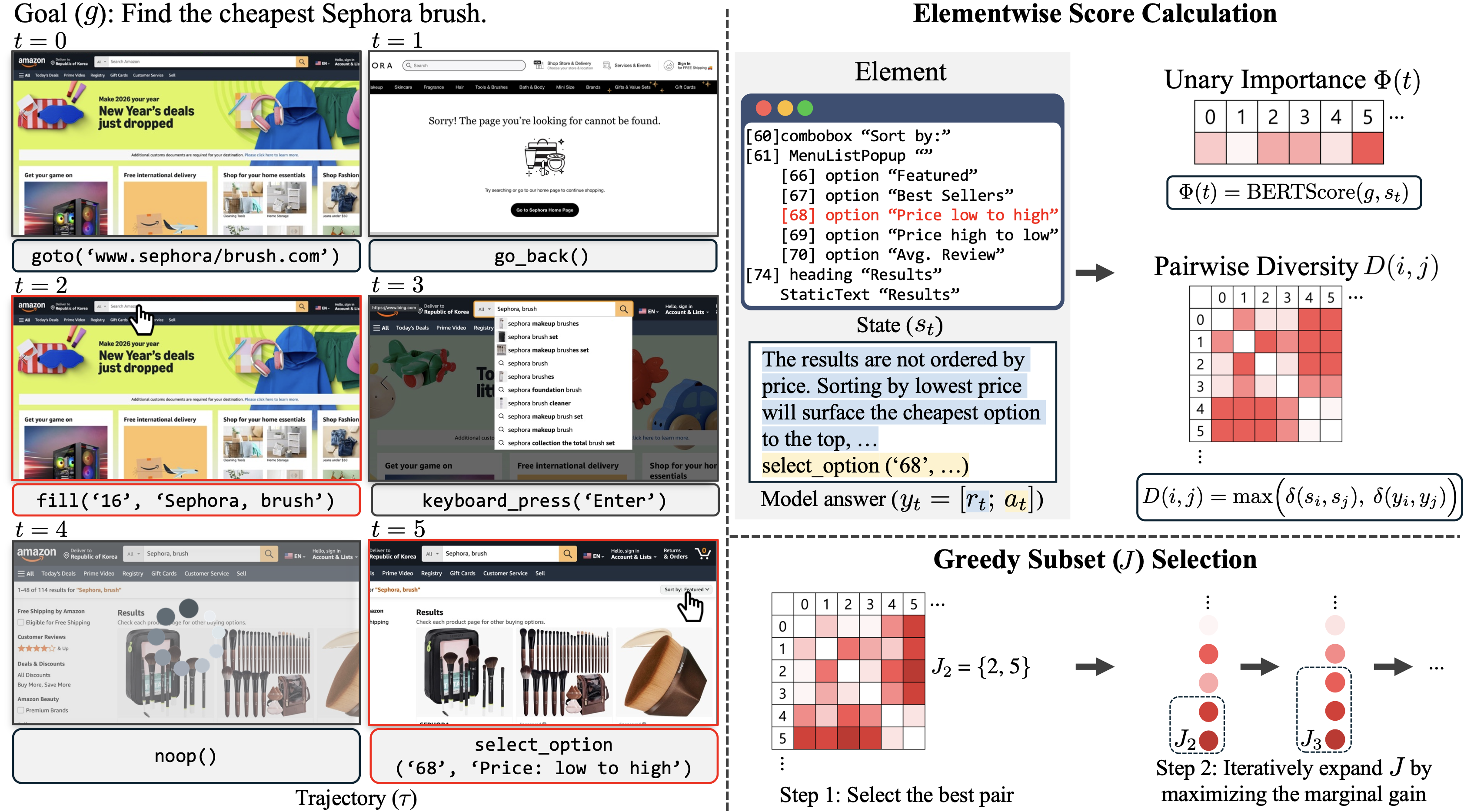
Fig 2: (Left): An example of a curated trajectory after applying WEASEL. Although the original collected data contain noisy steps
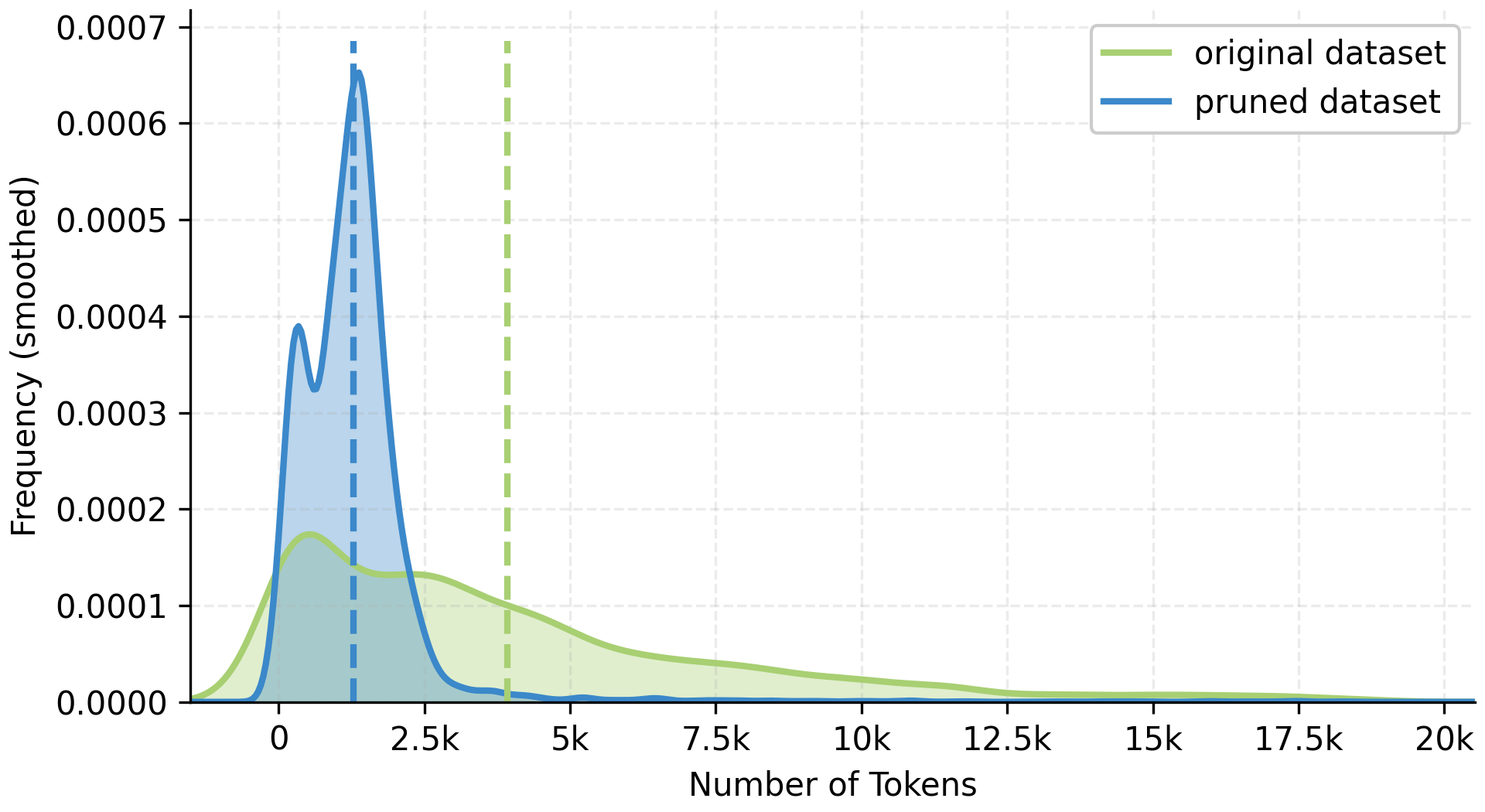
Fig 3: Token distribution of 10K subsamples of AgentTrek (Xu
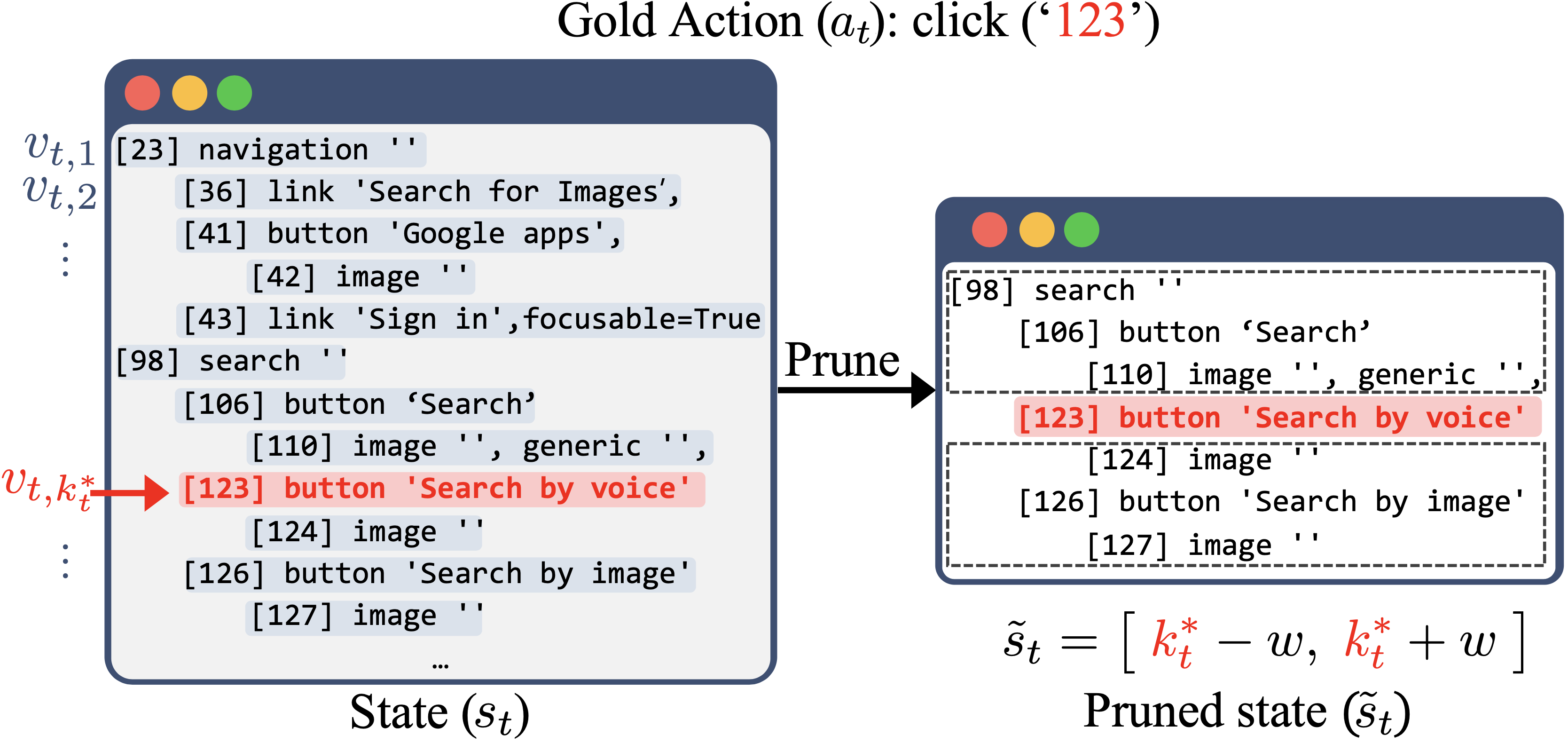
Fig 4: An illustration of Target-centered Pruning. Given a
Limitations
- The subset selection uses semantic pseudo-distances that do not satisfy metric properties, so greedy guarantees are empirical rather than theoretical.
- Target-centered pruning requires action target nodes to be known, limiting applicability where such grounding is unavailable.
- Reasoning synthesis depends on availability of a pretrained base model capable of consistent rationalization; its effectiveness might vary for other architectures.
- Evaluations focus on zero-shot transfer to existing benchmarks; robustness under adversarial website changes or dynamic content is not explicitly tested.
- Experiments primarily use LLMs with sizes ranging 2.5B–8B; scaling behavior to much larger models or lightweight agents remains unexplored.
- Some benchmarks involve simulated web environments; physical browser or live-site deployment effects are uncertain.
- The improvement margins shrink on simpler benchmarks or smaller models, suggesting a dependence on scale and task complexity.
Open questions / follow-ons
- Can the importance-diversity data selection framework be extended to online or reinforcement learning settings for adaptive web agents?
- How does WEASEL perform under adversarially crafted website content or dynamic page changes designed to confuse agents?
- What are the limits of reasoning-style synthesis and its impact on agents pretrained with different architectures or multimodal inputs?
- Can similar target-centered pruning and importance-diversity selection be generalized beyond web agents to other sequential decision-making tasks with large state representations?
Why it matters for bot defense
WEASEL’s approach of curated, diverse training under a fixed budget to improve out-of-domain robustness has direct relevance for bot-defense systems relying on web agents or CAPTCHA solver models. Data efficiency and generalization to unseen web interfaces or interaction scenarios are crucial for maintaining security against evolving automated adversaries. Implementing importance-diversity selection protocols could reduce training costs and mitigate overfitting to known site layouts, fostering resilient detection or interaction agents. Furthermore, the target-centered pruning methodology provides a blueprint for focusing model attention on minimal context around critical action points, potentially reducing vulnerability to extraneous content manipulation by bots. The self-reasoning synthesis technique suggests that style-aligned rationales might improve interpretability and robustness of reasoning-intensive interaction models used in CAPTCHA solving or bot detection pipelines. However, applying WEASEL requires access to annotated trajectories with ground-truth actions and may need adaptation for real-time or adversarial scenarios common in bot-defense settings.
Cite
@article{arxiv2605_20291,
title={ Weasel: Out-of-Domain Generalization for Web Agents via Importance-Diversity Data Selection },
author={ Fatemeh Pesaran zadeh and Seyeon Choi and Xing Han Lù and Siva Reddy and Gunhee Kim },
journal={arXiv preprint arXiv:2605.20291},
year={ 2026 },
url={https://arxiv.org/abs/2605.20291}
}