
DocQT: Improving Document Forgery Localization Robustness via Diverse JPEG Quantization Tables
Source: arXiv:2605.19688 · Published 2026-05-19 · By Kylian Ronfleux-Corail, Guillaume Bernard, Mickaël Coustaty, Nicolas Sidère
TL;DR
This paper addresses a critical gap in document manipulation localization (DML) systems deployed in real-world operational pipelines, particularly in insurance workflows. While current models show strong accuracy on public benchmarks, they fail to generalize well due to a fundamental mismatch in the JPEG compression distributions seen during training versus deployment. Specifically, training pipelines typically augment data using only the narrow subset of JPEG quantization tables derived from standard libjpeg quality factors, whereas operational documents undergo compression using a highly heterogeneous set of quantization tables sourced from diverse devices, scanners, and software. To isolate this factor, the authors curate DocQT, a large dataset of 859 distinct luminance quantization tables derived from a MAIF operational corpus, representing realistic compression heterogeneity. They compare two model architectures: FFDN, which explicitly conditions on the quantization table at input, and Mesorch, which does not. Both are trained under classical standard quality factor augmentation (Standard-QT) and the proposed operationally calibrated augmentation (Real-QT) sampled from DocQT. Evaluations on multiple public benchmarks under three recompression conditions (no recompression, Standard-QT recompression, Real-QT recompression) demonstrate that training with Real-QT significantly improves localization accuracy and reduces false positives on authentic operational documents—but only for models like FFDN that explicitly incorporate quantization table inputs. This shows that common augmentation schemes underestimate true compression diversity, and explicit quantization table conditioning is a key architectural inductive bias to improve robustness for real-world document forgery localization.
Key findings
- MAIF operational corpus exhibits 859 distinct luminance JPEG quantization tables, whereas public benchmarks such as DocTamper and T-SROIE contain only a single quantization table.
- FFDN model trained under Real-QT augmentation achieves a 14.5 percentage point increase in pixel-level F1 score on DocTamper-Test (0.853 vs 0.708) compared to Standard-QT training when evaluated under Real-QT recompression.
- Mesorch model, which lacks explicit quantization table input, shows negligible performance difference between Real-QT and Standard-QT training under Real-QT evaluation (0.704 vs 0.703 F1).
- Real-QT training reduces pixel-level false positive rate on authentic MAIF operational documents significantly compared to Standard-QT, but only for models ingesting the quantization table (FFDN).
- Standard quality factor augmentation (uniform random between 30 and 100) fails to adequately capture the diversity of operational compression profiles encountered in insurance document workflows.
- FFDN-Real achieves the highest localization performance on multiple DocTamper subsets (Test, FCD, SCD) across all evaluation recompression conditions.
- Evaluation under no forced recompression (Orig.) consistently yields highest localization scores, showing that artificial recompression degrades accuracy but Real-QT training mitigates this effect better.
- Training data includes 120,000 DocTamper images plus crops from Find-it, Find-it Again, T-SROIE, and negative authentic samples from MAIF operational dataset but excludes RTM to test out-of-distribution forgeries.
Threat model
The adversary is a document forger applying pixel-level manipulations to administrative images that are then compressed using a variety of heterogeneous JPEG pipelines unknown to the detection system. The adversary cannot control or standardize the JPEG quantization table used in compression but aims to evade detection by exploiting compression artifacts. The defender faces a distribution mismatch challenge due to operational JPEG quantization table diversity. No assumptions are made about the adversary's access to the detection model internals or about the forgery intent.
Methodology — deep read
The study's threat model concerns a document forgery detection system deployed in an operational setting where images have undergone various unknown JPEG compressions with potentially diverse quantization tables. The adversary is a forger attempting pixel-level document manipulations; no assumptions are made about their knowledge of the compression parameters. The key challenge is generalizing detection models trained with limited compression diversity to real-world heterogeneous pipelines.
The authors construct DocQT, a dataset of 859 unique luminance JPEG quantization tables extracted from the MAIF operational corpus comprising authentic insurance documents. This set represents the empirical distribution of quantization tables found in practice, beyond the standard libjpeg-based tables typically used in augmentation.
Two recompression pipelines control JPEG quantization table distributions during training and evaluation: Standard-QT applies random quality factors from 30 to 100 with OpenCV (standard libjpeg quantization tables); Real-QT uses tables sampled from DocQT representing real operational compression diversity.
Two contrasting model architectures are studied: FFDN, which explicitly inputs the JPEG quantization table as a conditioning vector to a Frequency Perception Head, harnessing double-quantization residual patterns in the DCT domain; and Mesorch, which processes pixel and DCT domain features via a CNN and transformer branch but without explicit quantization table input, relying on implicit learning of compression artifacts.
Training data includes 120,000 DocTamper images plus 5,000 crops from each of Find-it, Find-it Again, and T-SROIE training sets, supplemented by 400 crops from FUNSD and authentic negative samples from MAIF. RTM is excluded from training to serve as an out-of-distribution test. Data augmentation applies flips, rotations, brightness/contrast changes, and Gaussian blur but preserves forensic artifacts.
Models are trained under the two pipelines: FFDN-Std and Mesorch-Std use Standard-QT recompression for augmentation; FFDN-Real and Mesorch-Real use Real-QT augmentation with sampled DocQT tables. Training is conducted in the ForensicHub framework. Details on hardware, epoch count, optimizers, and hyperparameters are not fully specified in the source.
Evaluation uses pixel-level F1 and Intersection-over-Union (IoU) on tampered images, along with pixel false positive rate (FPR) on authentic unaltered images. Thresholding is fixed at 0.5 for masks. Evaluations occur under three JPEG recompression scenarios: no forced recompression (Orig.), Standard-QT recompression, and Real-QT recompression. This factorial setup disentangles the effect of quantization distribution mismatch.
Localization results consistently show better FFDN performance under Real-QT training when evaluated on realistic operational quantization tables, confirming the importance of explicit quantization conditioning. Mesorch results remain largely unchanged, highlighting architectural limitations. Reproducibility is supported by public release of DocQT quantization tables and compression scripts; models and full training pipelines are within ForensicHub but not explicitly released here.
In a concrete example, the FFDN-Real model trained on DocTamper plus additional datasets with Real-QT augmentation achieves a pixel-level F1 of 0.853 on DocTamper-Test when assessed on Real-QT recompressed images, substantially outperforming the Standard-QT trained counterpart at 0.708, demonstrating that operationally calibrated quantization distributions improve localization under realistic compression conditions. Mesorch trained similarly achieves only 0.704, showing the explicit input is crucial.
Technical innovations
- Curating DocQT, a large dataset of 859 real-world luminance JPEG quantization tables extracted from an operational insurance document corpus, enabling realistic modeling of compression heterogeneity.
- Demonstrating that explicit conditioning of localization networks on JPEG quantization tables (as in FFDN) yields significantly improved robustness under distribution shifts compared to implicit approaches (as in Mesorch).
- Designing a factorial experimental protocol that systematically controls training and evaluation JPEG recompression pipelines to isolate the impact of quantization table distribution mismatch on document forgery localization.
- Releasing a compression reproduction framework alongside DocQT to allow consistent experiments replicating operational compression profiles.
Datasets
- DocTamper — 150,000 images (120k train, 30k test) — public
- Find-it — 1,180 images, 240 altered — public
- Find-it Again — 988 images, 163 altered — public
- T-SROIE — 986 images (626 train, 360 test) — public
- SROIE — 973 images — public
- FUNSD — 199 images — public
- MAIF operational corpus — 13,455 authentic real documents — proprietary but quantization tables publicly released as DocQT
Baselines vs proposed
- FFDN-Std vs FFDN-Real on DocTamper-Test (Real-QT recompression): F1 = 0.708 vs 0.853
- Mesorch-Std vs Mesorch-Real on DocTamper-Test (Real-QT recompression): F1 = 0.703 vs 0.704
- FFDN-Std vs FFDN-Real on DocTamper-Test (no recompression): F1 = 0.927 vs 0.954
- Mesorch-Std vs Mesorch-Real on DocTamper-Test (no recompression): F1 = 0.751 vs 0.818
- FFDN-Std vs FFDN-Real on FCD subset (Real-QT recompression): 0.630 vs 0.832 F1
- FFDN-Std vs FFDN-Real on SCD subset (Real-QT recompression): 0.604 vs 0.776 F1
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.19688.
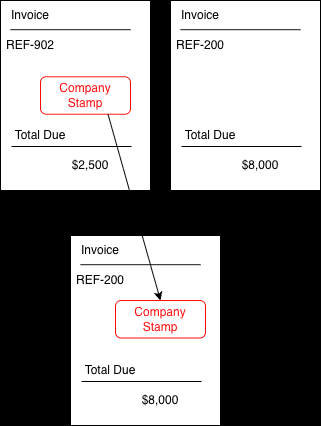
Fig 1: Illustration of the 4 manipulation types considered in document forensics -
Fig 2: Standard libjpeg luminance quantization tables at two quality fac-

Fig 3 (page 7).
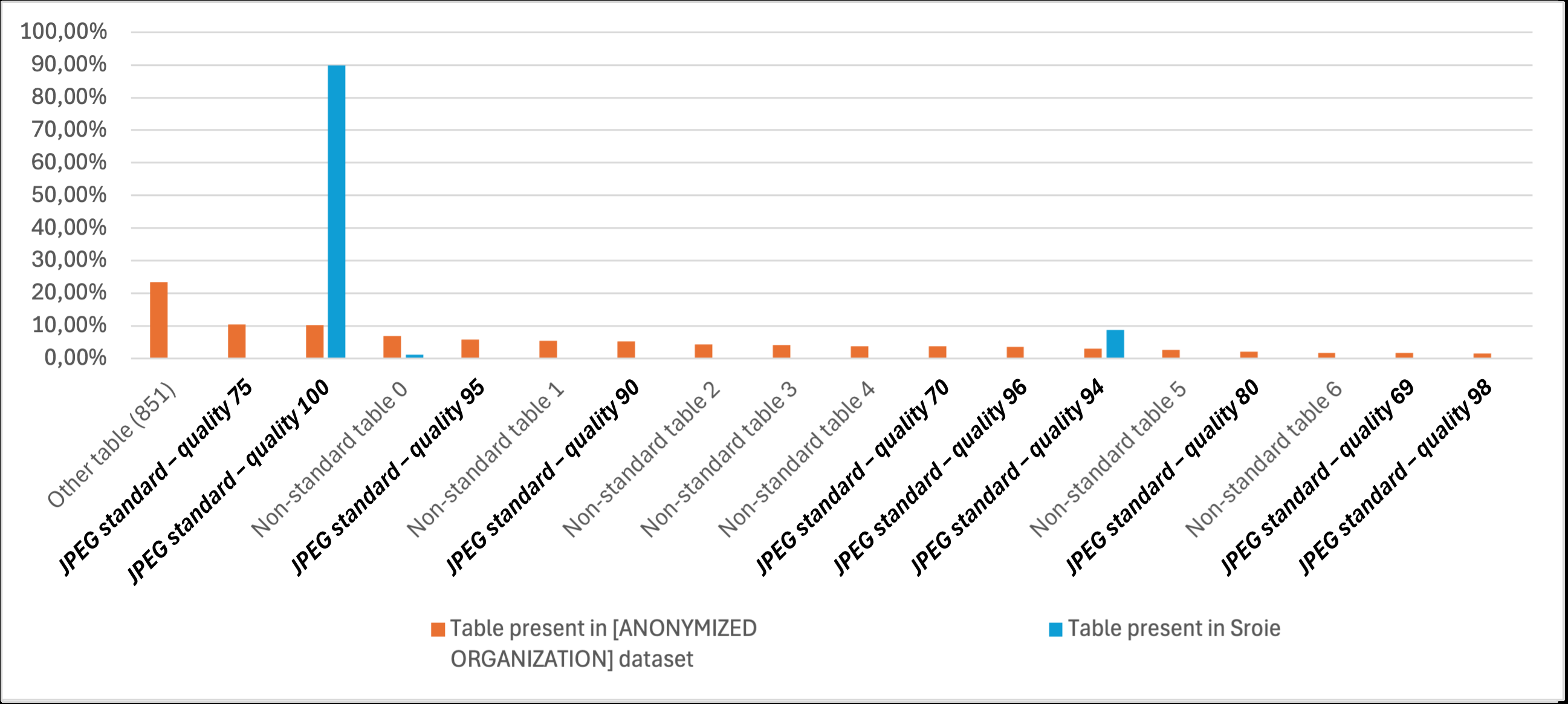
Fig 3: Distribution of the most frequent luminance JPEG quantization tables
Limitations
- The study focuses on luminance JPEG quantization tables; chrominance tables are not explicitly considered though they may also affect compression artifacts.
- Training and evaluation still rely on synthetically recompressed data to control the distribution, which may differ from natural compression artifacts in fully operational environments.
- Hardware and training hyperparameter details are not fully disclosed, impacting reproducibility beyond the quantization data release.
- The study excludes some datasets (e.g., RTM) from training to test generalization, but does not evaluate adversarially crafted forgeries or forgeries specifically targeting compression artifacts.
- Only two model architectures are deeply compared, limiting conclusions about the broader applicability to other recent localization networks.
- The MAIF operational corpus image data is not publicly available, which restricts full replication of the operational pipeline.
Open questions / follow-ons
- How to incorporate or leverage chrominance quantization table variations alongside luminance in forgery localization?
- Can explicit quantization table conditioning benefits be extended or combined with self-supervised or multimodal approaches for improved robustness?
- What is the impact of adversarial compression or forgery attacks explicitly designed to mimic or obfuscate diverse quantization tables?
- How do these findings generalize to non-JPEG or multi-format document pipelines common in operational workflows?
Why it matters for bot defense
Bot-defense and CAPTCHA systems that rely on image forensics or document authentication can benefit from this study by recognizing the crucial impact of JPEG quantization table diversity on model robustness. Systems designed to detect document manipulation should incorporate explicit conditioning on compression metadata or retrain with real operational quantization tables to reduce false positives and improve localization accuracy. The commonly adopted practice of augmenting training data with standard quality factors is insufficient to capture the true heterogeneity of compression in deployment environments and may lead to brittle models. Incorporating explicit JPEG quantization table inputs or their proxies could enhance robustness against the diverse imaging pipelines deployed by adversaries or legitimate users alike. From a deployment standpoint, collecting and utilizing operational compression statistics, as exemplified by DocQT, is recommended to bridge the domain gap. These findings encourage bot-defense engineers to critically evaluate dataset assumptions around image compression and revisit training augmentations toward real-world diversity.
Cite
@article{arxiv2605_19688,
title={ DocQT: Improving Document Forgery Localization Robustness via Diverse JPEG Quantization Tables },
author={ Kylian Ronfleux-Corail and Guillaume Bernard and Mickaël Coustaty and Nicolas Sidère },
journal={arXiv preprint arXiv:2605.19688},
year={ 2026 },
url={https://arxiv.org/abs/2605.19688}
}