
CaptchaMind: Training CAPTCHA Solvers via Reinforcement Learning with Explicit Reasoning Supervision
Source: arXiv:2605.19538 · Published 2026-05-19 · By Pengcheng Wang, Haoxiang Liu, Yang Dai, Xiangxiang Zeng, Guanhua Chen, Baotian Hu et al.
TL;DR
This paper addresses the long-standing gap in scalable training-based solvers for modern CAPTCHAs, which require complex multi-step visual reasoning and interaction. Prior approaches mostly rely on prompting closed-source large vision-language models, which are costly and limited in controllability, while supervised fine-tuning on small datasets has yielded poor results. The authors introduce CaptchaBench, a novel large-scale programmatically generated CAPTCHA benchmark consisting of 16,000 annotated samples across eight diverse task categories representative of real-world commercial CAPTCHA services. This dataset contains fine-grained region and process-level annotations enabling supervision of model reasoning steps. Evaluation of existing SOTA methods on CaptchaBench reveals consistent failure on tasks demanding detailed visual reasoning and precise region-level comparisons.
Motivated by these insights, the authors propose CaptchaMind, a two-stage training framework that first performs supervised fine-tuning to establish basic skills, then applies reinforcement learning with explicit reasoning process supervision. By explicitly supervising intermediate reasoning steps via predicted bounding-box regions and rewarding correct attention to task-relevant visual elements, CaptchaMind substantially improves reasoning accuracy. It achieves 82.9% average success rate on CaptchaBench across all eight tasks and 71.0% on real-world CAPTCHA instances, outperforming all prior open-source and closed-source baselines by large margins. Ablations confirm the critical role of explicit reasoning supervision and multi-step feedback rewards for complex tasks. Qualitative analysis shows CaptchaMind attends precisely to discriminative visual details missed by baselines. Overall, the study establishes training-based CAPTCHA solving as plausible with intermediate reasoning supervision and releases a benchmark and code to seed future research.
Key findings
- CaptchaBench contains 16,000 synthetic CAPTCHA samples spanning 8 task categories with region/process-level annotations enabling reasoning supervision.
- Human discrimination study shows synthesized CAPTCHAs are visually indistinguishable from real-world CAPTCHAs (mean classification accuracy 51.04%, chance level).
- Existing methods achieve <55% average success rate on CaptchaBench; closed-source VLMs and agent methods struggle on fine-grained visual detail tasks like connect_icon.
- Supervised fine-tuning (SFT-only) improves average success rate to 68.1%, but still fails on tasks requiring precise region-level attention (e.g., connect_icon 49.0%, image_select 14.0%).
- CaptchaMind, trained with RL and explicit process supervision, achieves 82.9% average success rate across all 8 tasks, improving connect_icon accuracy from 49.0% (SFT) to 71.0%.
- On real-world CAPTCHA screenshots, CaptchaMind attains 71.0% success rate, validating strong sim-to-real generalization despite unseen variants/styles.
- Ablations show removing reasoning process supervision drops connect_icon accuracy from 71.0% to 56.0%; removing feedback rewards reduces multi-step task performance.
- High task success correlates strongly with region identification rate; episodes with >60% region identification yield 91% success.
Threat model
The adversary is an automated intelligent agent attempting to solve CAPTCHAs by analyzing visual scene inputs and performing allowed interactions (clicking, dragging, typing, bounding box selection) to produce correct answers. The adversary cannot access proprietary closed-source API solutions and must solve CAPTCHA tasks within limited interaction steps. They do not have capabilities to bypass anti-bot detection mechanisms outside the CAPTCHA challenge itself.
Methodology — deep read
Threat Model & Assumptions: The adversary is assumed to be an AI agent attempting to solve modern complex CAPTCHAs requiring visual and spatial reasoning and interaction with the interface. The adversary can observe CAPTCHA images, task instructions, and perform actions including clicking, dragging, typing, and bounding box drawing. The adversary does not have access to closed-source proprietary CAPTCHA-solving APIs and must solve tasks within limited steps. The focus is on solving the CAPTCHA challenges from visual/process signals rather than bypassing higher-level behavioral or anti-bot mechanisms.
Data: CaptchaBench consists of 16,000 programmatically generated CAPTCHA samples, evenly split into 8,000 training and 8,000 RL-training samples, plus 1,600 test samples (200 per 8 tasks). Tasks reflect real CAPTCHA service challenges (GeeTest, hCaptcha), divided into image-switching, multi-step interaction, and single-step decision categories. The synthetic data pipeline produces detailed region-level bounding box annotations capturing key visual elements and process-level annotations recording interaction trajectories. No manual annotation is required. A human discrimination study confirms high visual fidelity.
Architecture and Algorithm: CaptchaMind builds on the Qwen2.5-VL-7B vision-language base model. The problem is formulated as a Partially Observable Markov Decision Process (POMDP) with observations comprising the CAPTCHA image, instructions, and interaction history. Actions include click, drag, type text, and bounding_box (to expose intermediate reasoning). A policy π_θ is trained to predict actions given states.
Training proceeds in two stages: first, supervised fine-tuning (SFT) on behavior cloning from the annotated dataset to learn basic tool usage and multi-step reasoning patterns, incorporating chain-of-thought (CoT) reasoning data for select tasks. Second, reinforcement learning (RL) optimizes the policy using the GRPO algorithm with 8 rollout samples per prompt, sampling episodes from all tasks.
Key novelty: The RL phase integrates explicit reasoning process supervision by rewarding correct grounding of task-relevant visual regions at intermediate bounding box prediction steps. This is operationalized by rewarding the agent each time it identifies at least 50% of ground-truth regions with bounding boxes above an IoU threshold of 0.8. Additionally, multi-step interaction feedback rewards guide intermediate progress, and a final outcome reward signals task completion success.
Evaluation Protocol: Performance is measured by task success rate (percentage of tasks successfully solved within step limits). The evaluation includes comparisons against closed-source large VLM APIs (Claude variants, GPT-5, Gemini-3), agentic prompting methods (Oedipus, Halligan), GUI interaction agents, and SFT-only models. Experiments involve both in-domain evaluation on CaptchaBench test samples and cross-dataset/real-world evaluation on manually annotated CAPTCHA screenshots from commercial services. Ablations test the effect of removing various training components.
Reproducibility: Authors release code and data at https://github.com/AlibabaResearch/captcha-mind. The dataset and environment simulator enable process-level supervision and reproducible training. Qwen2.5-VL-7B base model details and training hyperparameters are documented in appendices.
Technical innovations
- CaptchaBench: The first large-scale CAPTCHA dataset with 16,000 samples and detailed region/process-level annotations enabling learning of intermediate visual reasoning.
- Explicit reasoning process supervision during reinforcement learning, directly rewarding accurate grounding of task-relevant visual regions at intermediate bounding box steps.
- Two-stage training pipeline combining supervised fine-tuning on behavior cloning with targeted RL to optimize both tool use and reasoning accuracy.
- Multi-level reward design integrating process-level region grounding rewards, interaction feedback rewards for multi-step tasks, and final outcome rewards to guide learning.
Datasets
- CaptchaBench — 16,000 samples (8,000 train, 8,000 RL train, 1,600 test) — programmatically generated synthetic CAPTCHA dataset with region/process annotations
- Real-world CAPTCHA dataset — 100 annotated CAPTCHA screenshots from commercial services (GeeTest, hCaptcha) — collected for evaluation
Baselines vs proposed
- Closed-source VLMs (Claude-4-Sonnet): Avg success rate = 47.4% vs CaptchaMind: 82.9%
- Closed-source VLMs (GPT-5): Avg success rate = 33.6% vs CaptchaMind: 82.9%
- Agentic methods (Halligan): Avg success rate = 54.7% vs CaptchaMind: 82.9%
- Agentic methods (Oedipus): Avg success rate = 51.9% vs CaptchaMind: 82.9%
- GUI Agents (GUI_R1_7b): Avg success rate = 6.5% vs CaptchaMind: 82.9%
- SFT-only training: Avg success rate = 68.1% vs CaptchaMind: 82.9%
- Ablation - without reasoning process supervision (w/o RPS): Avg success = 78.9% (connect_icon drops from 71.0% to 56.0%)
- Ablation - without feedback reward (w/o FBR): Avg success = 80.0% (multi-step task scores drop)
- Ablation - RL-only (no SFT warm-up): Avg success rate = 25.6% vs CaptchaMind: 82.9%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.19538.
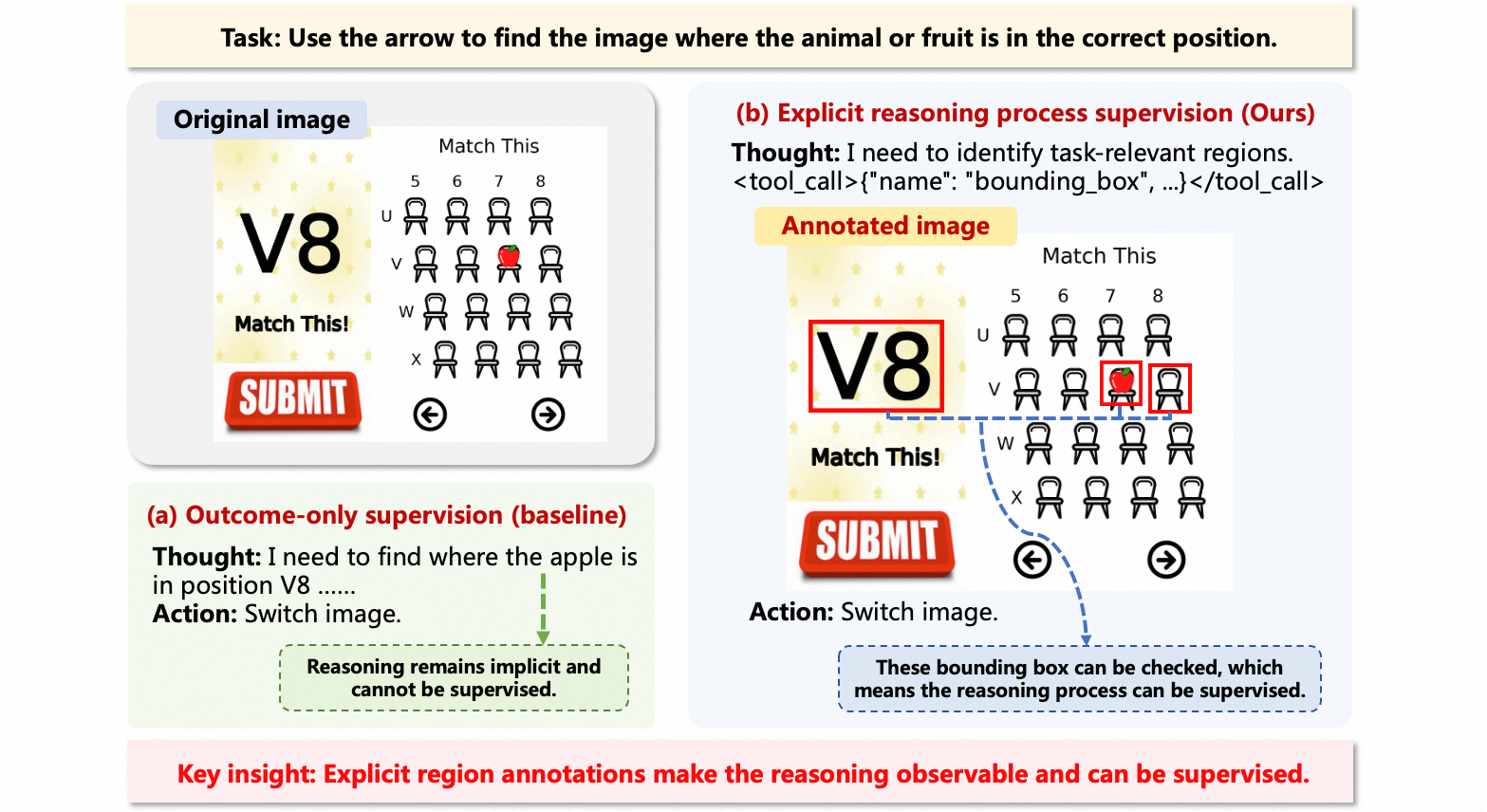
Fig 1: Outcome-only supervision (baseline) vs. explicit reasoning process supervision (ours). In the baseline ap-
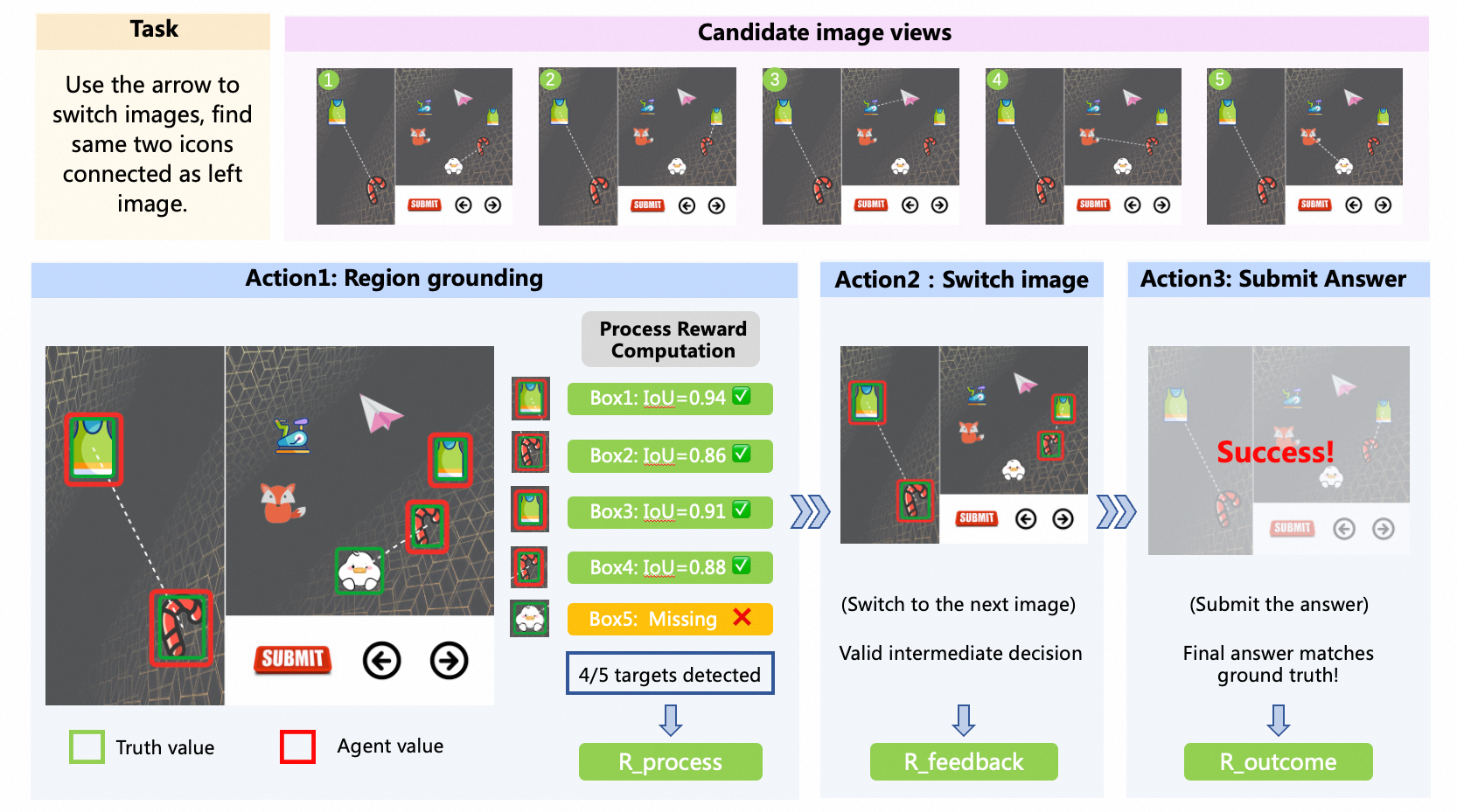
Fig 3: An illustrative training trajectory showing how explicit reasoning steps are supervised at different stages

Fig 5: Qualitative comparison on connect_icon (left) and dice_count (right). Baseline models make errors by

Fig 6: Examples of image-switching tasks.

Fig 7: Examples of multi-step interaction tasks.

Fig 8: Examples of single-step decision tasks.

Fig 7 (page 12).

Fig 8 (page 12).
Limitations
- Real-world evaluation focuses on visual reasoning; does not address behavioral verification, dynamic rendering, or broader anti-bot detection used in web deployments.
- Reward function hyperparameters such as IoU threshold (0.8) and coverage (50%) were selected via preliminary experiments, with only limited sensitivity analysis; exhaustive tuning remains future work.
- Baseline methods Oedipus and Halligan required re-implementation or adaptations due to lack of open-source code, possibly introducing slight discrepancies in comparisons.
- CaptchaMind’s performance drops from 82.9% on synthetic data to 71.0% on real-world CAPTCHAs, indicating some sensitivity to distributional shift and unseen style/variant diversity.
- The environment and tasks focus on static images and interaction sequences; does not model dynamic or anti-bot defenses employed on websites.
Open questions / follow-ons
- How well does explicit intermediate reasoning supervision transfer to more dynamic CAPTCHA challenges with behavioral or multi-modal anti-bot signals?
- Can process-level rewards be automatically optimized or adapted dynamically beyond fixed IoU thresholds and coverage levels to better guide training?
- How robust is CaptchaMind to distribution shifts including unseen CAPTCHA styles, fonts, or interaction modalities beyond those synthesized in CaptchaBench?
- What extensions to the approach enable reasoning about temporal or video-based CAPTCHAs or CAPTCHAs with more adversarial obfuscation?
Why it matters for bot defense
This work is highly relevant to CAPTCHA and bot-defense practitioners seeking training-based, scalable CAPTCHA solvers that move beyond brittle prompting or black-box closed APIs. The detailed intermediate reasoning supervision framework and large-scale CaptchaBench dataset provide a foundation for developing and benchmarking CAPTCHA solving agents that can robustly attend to the fine-grained visual details critical for modern CAPTCHA designs. Bot-defense engineers can use insights from the failure modes of prior methods and the success of explicit region grounding to design stronger CAPTCHA variants that better resist training-based solvers. The real-world evaluation demonstrates practical generalization potential, while the open environment and annotations facilitate deeper forensic analysis of solver reasoning. However, practitioners should note that real web CAPTCHA defense also involves behavioral and anti-bot challenges beyond visual reasoning alone, suggesting this approach addresses only one dimension of a multi-layered defense strategy.
Cite
@article{arxiv2605_19538,
title={ CaptchaMind: Training CAPTCHA Solvers via Reinforcement Learning with Explicit Reasoning Supervision },
author={ Pengcheng Wang and Haoxiang Liu and Yang Dai and Xiangxiang Zeng and Guanhua Chen and Baotian Hu and Longyue Wang and Weihua Luo },
journal={arXiv preprint arXiv:2605.19538},
year={ 2026 },
url={https://arxiv.org/abs/2605.19538}
}