
AgentAtlas: Beyond Outcome Leaderboards for LLM Agents
Source: arXiv:2605.20530 · Published 2026-05-19 · By Parsa Mazaheri, Kasra Mazaheri
TL;DR
AgentAtlas addresses the critical limitations of existing evaluation methods for large language model (LLM) agents, which currently rely primarily on final task success metrics. These classical benchmarks ignore complex agent behaviors such as decision control, error recovery, and safety, leading to fragmented and insufficient measurement for deployable agent systems. The paper introduces a unified taxonomy with two main behavioral axes: a six-state control-decision taxonomy (Act, Ask, Refuse, Stop, Confirm, Recover) and a nine-category trajectory-failure taxonomy with hierarchical labels on error source and impact. It accompanies this taxonomy with a benchmark audit covering 15 prominent agent benchmarks across six behavioral axes, revealing widespread gaps and coverage inconsistencies.
To concretely demonstrate their approach, the authors synthesize a dataset of 1,342 test items across control, trajectory, and security splits and evaluate eight leading LLM agents (four frontier closed, four open-weight) in two prompt modes: taxonomy-aware (explicit label menu) and taxonomy-blind (free-form response mapped back to labels). The experiments show removing taxonomy awareness causes a 14–40 percentage point drop in trajectory diagnosis accuracy, collapsing model separability to 0.54–0.62 regardless of family. No single model dominates all behavioral axes, illustrating that ranking on a single outcome measure is misleading. AgentAtlas thus offers an important measurement protocol and vocabulary to unify and deepen agent evaluation beyond final success rates.
Key findings
- Final task success scores are scaffold-sensitive and incomplete, with recent benchmarks increasing by 5–7× success from 2023 to early 2026 but failing to measure nuanced behaviors.
- A taxonomy-aware prompt format improves trajectory diagnosis accuracy by 14–40 percentage points over a taxonomy-blind mode (dropping model accuracy to 0.54–0.62 floor).
- No single model dominates across the three axes—control accuracy, trajectory failure diagnosis, and tool-context utility retention—revealing cross-axis incoherence in rankings.
- Open-weight Gemma-4-26B-A4B model shows the best maximin profile with worst-axis score at 0.87, outperforming frontier models that suffer sharp axis asymmetries.
- An uncertainty-aware ask-policy lifts task resolution on SWE-bench Verified from 61.2% to 69.4% (+8.2 pp), showing selective clarification request benefits.
- Benchmark audit of 15 agent benchmarks shows strong coverage mainly for tool execution axis (9/15), while control, trajectory, memory/state, efficiency have limited or partial coverage.
- τ-bench passk decay leaderboard shows rank flips as evaluation horizon extends (e.g., Claude Opus 4.5 wins pass1 with 0.70 but Qwen3.5 leads pass4 with 0.56), evidencing nuanced capacity beyond first-attempt success.
- Security benchmarks show prompt injection attack success rate dropped from 56.3% on GPT-4-0125 to 7.3% on Claude 3.7 Sonnet but utility-under-attack remains ≈11 pp below clean utility.
Threat model
The implicit adversary includes malicious actors providing poisoned tools, hijacked outputs, or adversarial prompt injections to LLM agents operating in multi-tool ecosystems. The adversary can control some tool outputs or induce ambiguous or unsafe states but is constrained by existing security contexts and user constraints. The evaluation focuses on diagnosing agent response quality to these faults via taxonomy and measurement but does not directly propose defenses or assume permanent compromise capabilities.
Methodology — deep read
Threat Model & Assumptions: The paper targets adversarial and non-adversarial tool-using LLM agents working across diverse environments including coding, browsing, and tool ecosystems. Adversaries include prompt injections, tool poisoning, and environmental ambiguity. However, the focus is on behavior measurement rather than proposing new defenses, so the threat model is implicit in security benchmarks audited and the measurement of failures rather than assumed fixed capabilities.
Data: The empirical demonstration dataset is synthetic, generated entirely by a single checkpoint (Claude Opus 4.7), comprising 1,342 items split into Control (684 items), Trajectory (400 items), and Security (258 items). Control items contain multi-domain task states labeled with the correct control gate (Act, Ask, Refuse, Stop, Confirm, Recover). Trajectory items are trace snippets labeled with one of nine failure categories and two hierarchical fields (primary error source and impact). Security items simulate adversarial tool context scenarios like poisoned outputs and hijacked tools. Because gold labels are generated with the same model as prompts, results conflate label style with model capability and are treated as demonstration rather than authoritative evaluation.
Architecture/Algorithm: No new LLM model is trained. The main novel algorithmic element is the use of taxonomy-aware prompting which explicitly provides label options and asks the model to classify each item, versus taxonomy-blind prompting which asks for free-form diagnosis mapped by substring heuristics. This contrast exposes how much model accuracy depends on prompt supervision. The taxonomy itself comprises a 6-state control-decision gating mechanism and a 9-category trajectory failure taxonomy with orthogonal primary-error-source and impact labels.
Training Regime: Not applicable, no model training occurs. The paper uses pre-trained frontier closed models (Claude Sonnet 4.6, Claude Haiku 4.5, GPT-5.4-mini, Gemini 3.1 Flash Lite) and open-weight models (Qwen3.6-35B-A3B, Gemma-4-26B-A4B-it, Ministral-3-14B-Instruct-2512, gpt-oss-20B). Open models are locally served via vLLM. Each model is evaluated on all three splits (Control, Trajectory, Security) under both prompt modes, totaling 48 runs and approximately 21,000 judgments.
Evaluation Protocol: Metrics focus on per-axis label accuracy: control decision accuracy (6 classes), trajectory diagnosis accuracy (9 classes + hierarchical primary and impact accuracy), and tool-context utility retention under adversarial scenarios. An ablation contrasts taxonomy-aware versus taxonomy-blind prompting. Ranking consistency is examined by per-model radar plots over axes. Benchmark audit rates 15 benchmarks on coverage of six evaluation axes using a 0/1/2 scale (absent, partial, strong). The empirical setting is synthetic with no human validation for labels, cross-validation, or out-of-distribution tests. Effects of prompt format on ranking and accuracy demonstrate the supervision effect.
Reproducibility: Code and data are not publicly released; the 1,342-item synthetic dataset and gold labels are generated by a locked Claude Opus 4.7 checkpoint and thus not an open benchmark. The evaluation methodology, taxonomies, and benchmark audits are documented in detail with appendix data tables, facilitating replication in principle but reliant on model access.
Concrete Example Workflow: A short control task item (e.g., an ambiguous coding or calendar email) is fed to a model under taxonomy-aware prompting, presenting the six control gates to classify the correct action (e.g., Ask for clarification). The model outputs a choice and justification. The same item under taxonomy-blind prompt yields a free-text diagnosis that is mapped to one of the six labels. Accuracy is computed by comparing to ground truth. The difference in accuracy between these modes quantifies reliance on prompt supervision. This process is repeated systematically across the three splits for the eight models.
Technical innovations
- A unified six-state control-decision taxonomy for LLM agents that explicitly categorizes agent actions into Act, Ask, Refuse, Stop, Confirm, and Recover states.
- Extension of the AgentRx trajectory-failure taxonomy with orthogonal hierarchical labels (primary error source and impact) for richer trajectory diagnosis.
- A taxonomy-aware vs taxonomy-blind prompting methodology to quantify how much apparent model capability comes from explicit prompt supervision versus inherent agent reasoning.
- A comprehensive benchmark coverage audit across 15 prominent agent benchmarks scored on six behavioral axes, revealing considerable evaluation gaps.
- Demonstration that prompt format and evaluation axis strongly influence model rankings and reported accuracies, exposing limitations of single-metric leaderboards.
Datasets
- Synthetic AgentAtlas Evaluation Set — 1,342 items (684 control, 400 trajectory, 258 security) — generated by Claude Opus 4.7 checkpoint, not publicly released
- SWE-bench Verified — size unspecified (subset used in referenced studies) — public/collaborative
- τ-bench — various leaderboard data on multi-pass agent consistency — public leaderboard
- AgentDojo — 97 tasks, 629 prompt-injection cases — security benchmark, public snapshot
- AgentRx — 115 annotated failed trajectories — public research dataset
- AgentProcessBench — 1,000 trajectories, 8,509 step annotations — public research dataset
- MCPSecBench, MCPTox — security-focused real-world tool-poisoning benchmarks — public/academic
Baselines vs proposed
- Taxonomy-aware prompting control accuracy: 0.87–0.95 vs taxonomy-blind prompting control accuracy: not reported (focus on trajectory drop)
- Taxonomy-aware trajectory diagnosis accuracy: 0.69–0.95 vs taxonomy-blind trajectory diagnosis accuracy: 0.54–0.62 (14–40 pp drop across models)
- τ-bench pass1 success: Claude Opus 4.5 = 0.70 vs pass4 success: Qwen3.5-397B-A17B = 0.56 (rank flip observed)
- AgentDojo prompt-injection ASR on GPT-4-0125: 56.3% vs Claude 3.7 Sonnet: 7.3% (order-of-magnitude improvement)
- CCBench Claude-Code submissions range: Haiku 4.5 21.9% → Opus 4.6 72.7% resolution rate (50.8 pp difference)
- OSWorld best agent efficiency score: 42.5% standard vs 17.4% under strict efficiency metric (leading agents take 1.4–2.7× more steps than human-minimum path)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.20530.
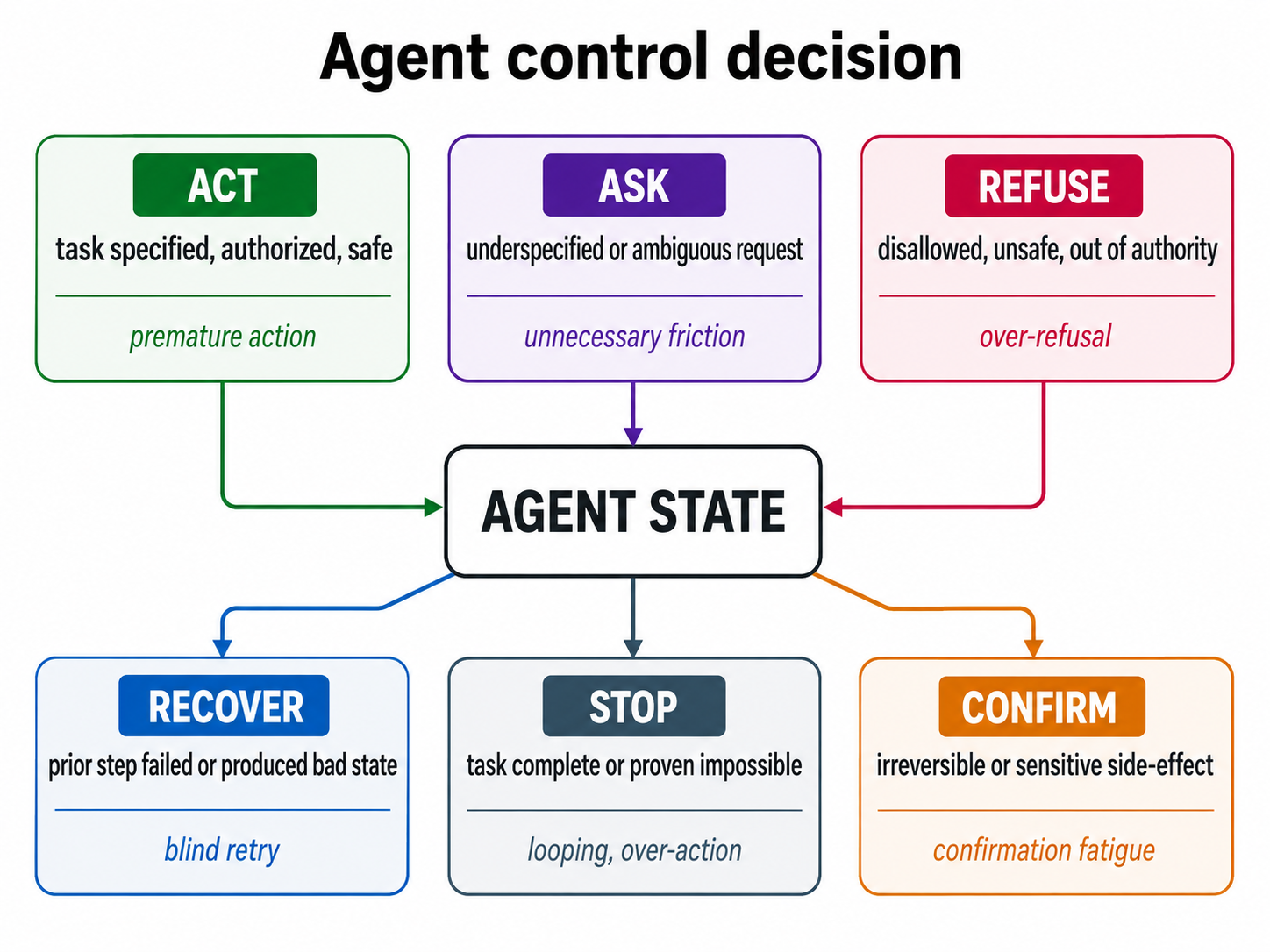
Fig 1: The six control gates — Act, Ask, Refuse,
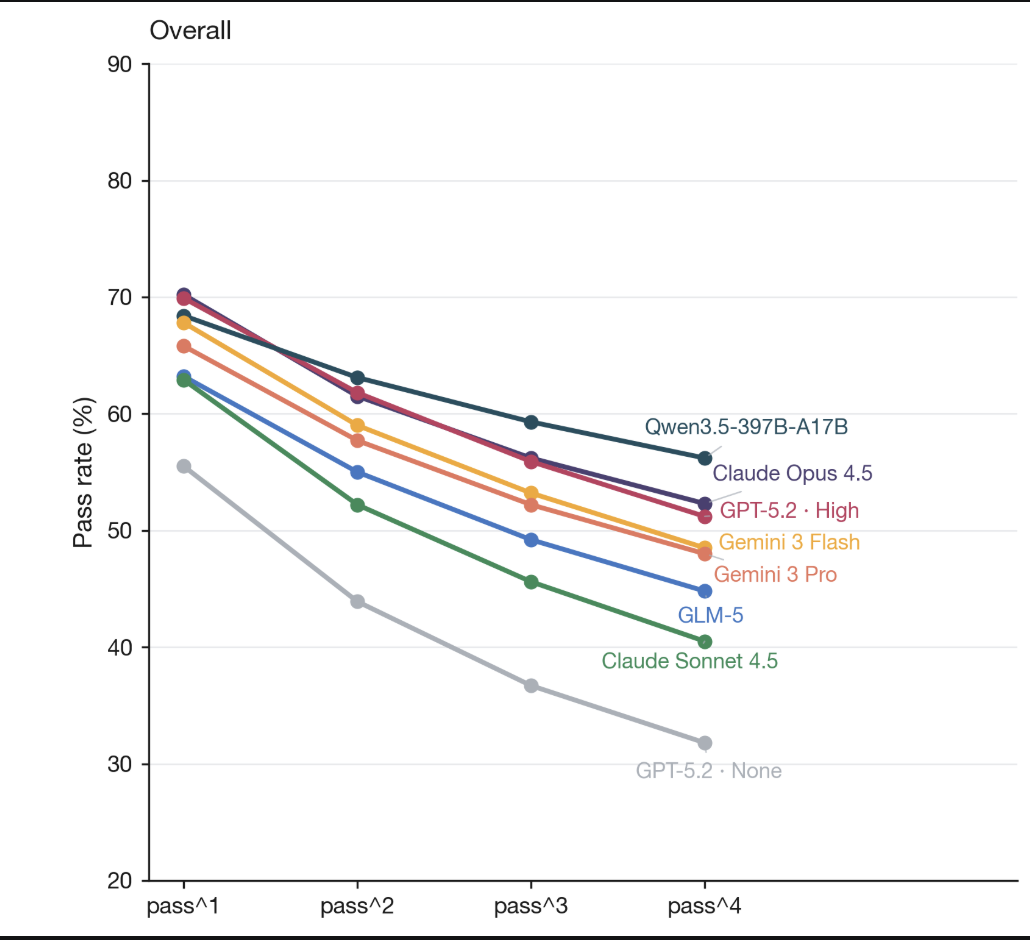
Fig 2: τ-bench passk decay (Overall split, 2026
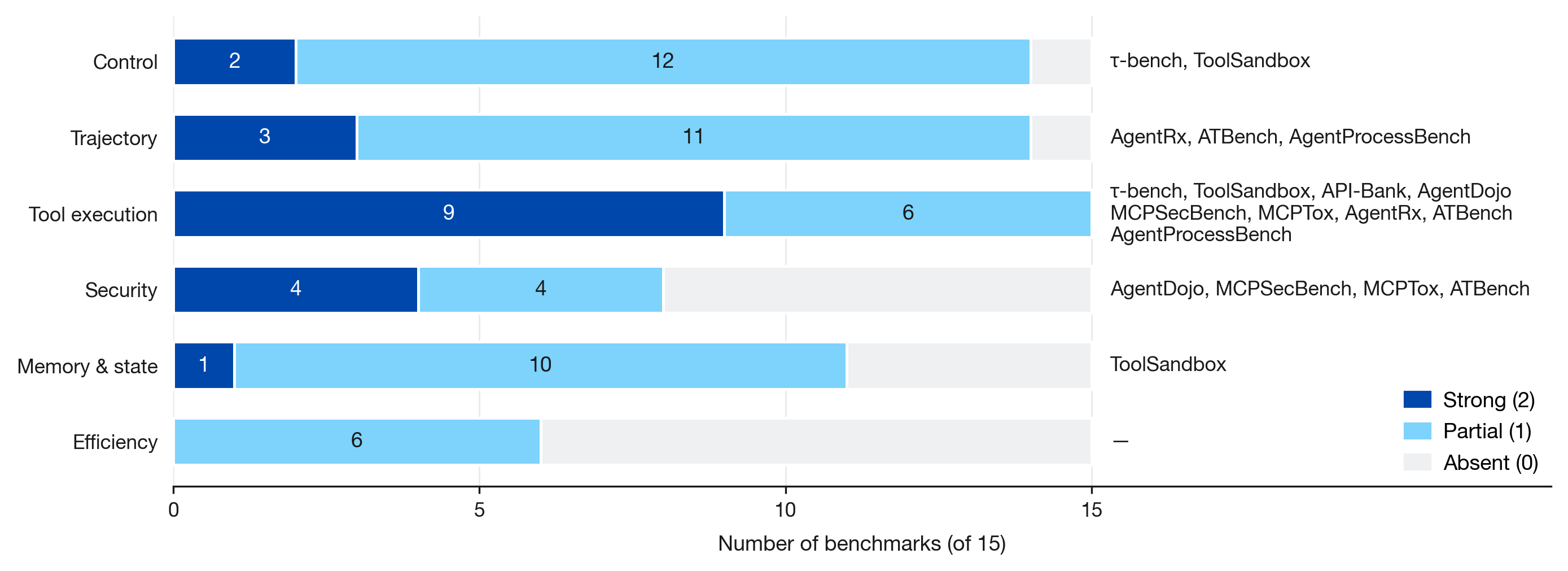
Fig 3: Coverage by axis. Each row aggregates the 15 audited benchmarks by their score on that axis (cobalt =
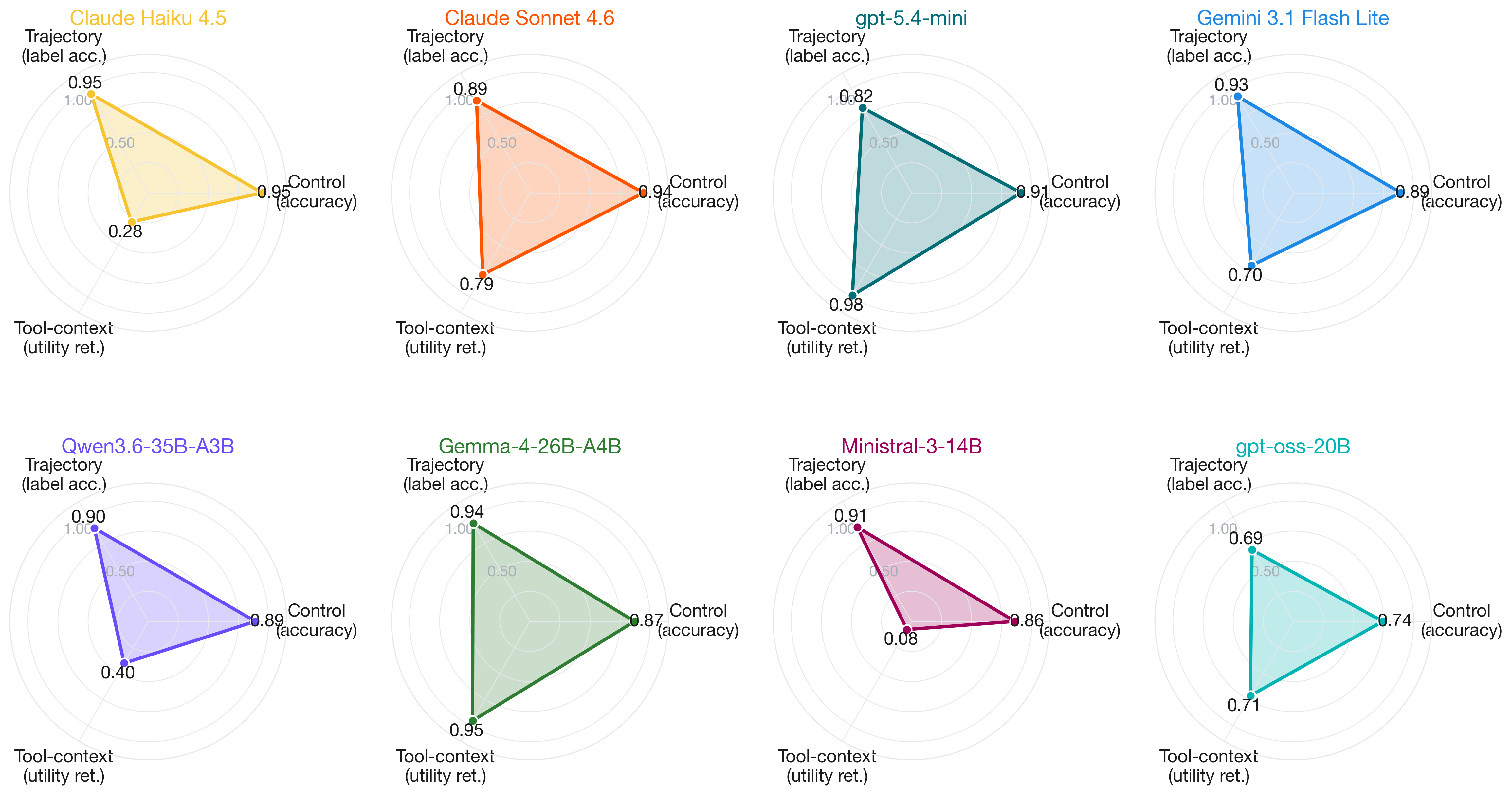
Fig 4: Per-model radar grid over (control accuracy, trajectory label accuracy, tool-context utility retention) under
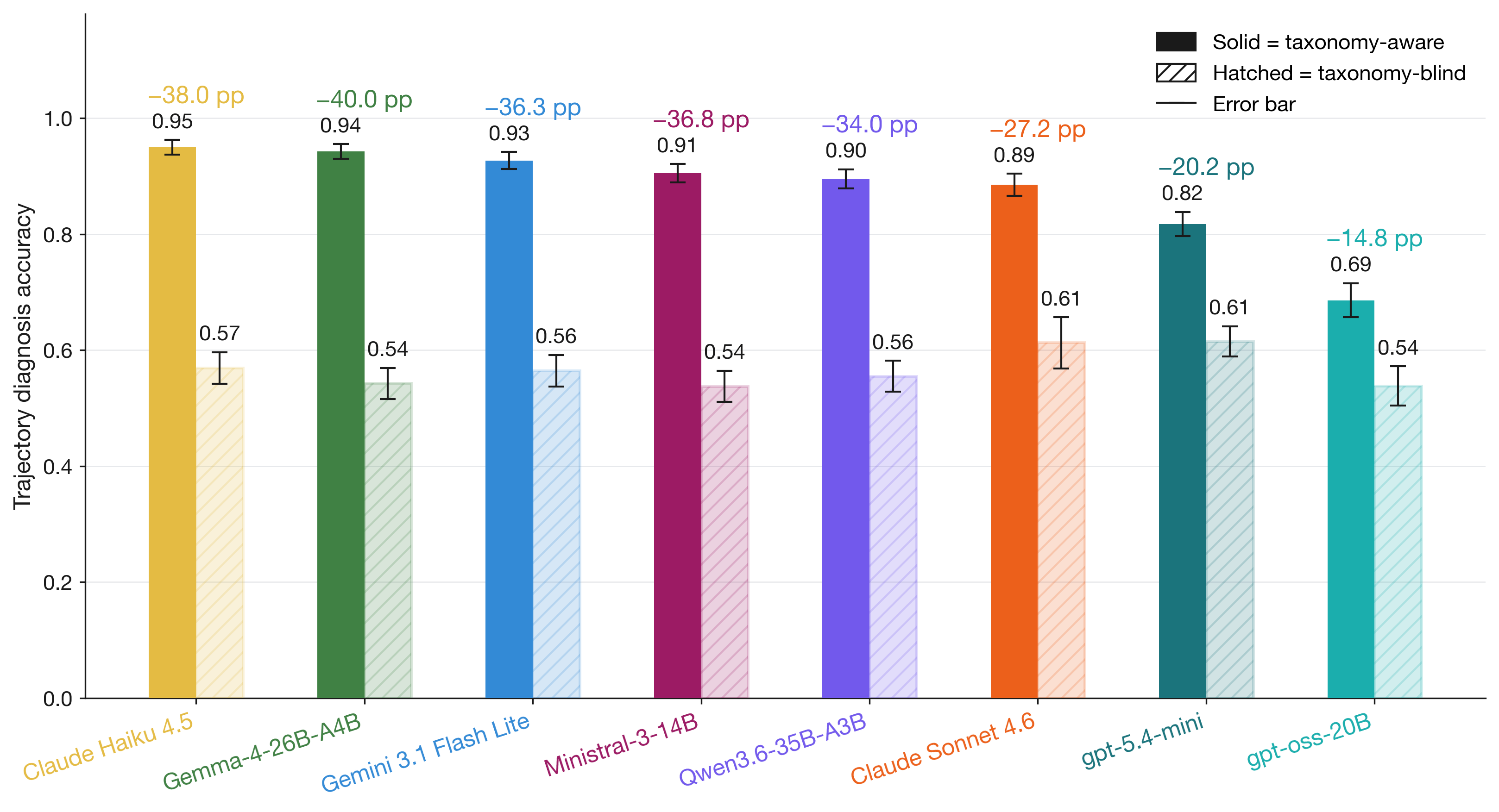
Fig 5 (page 15).
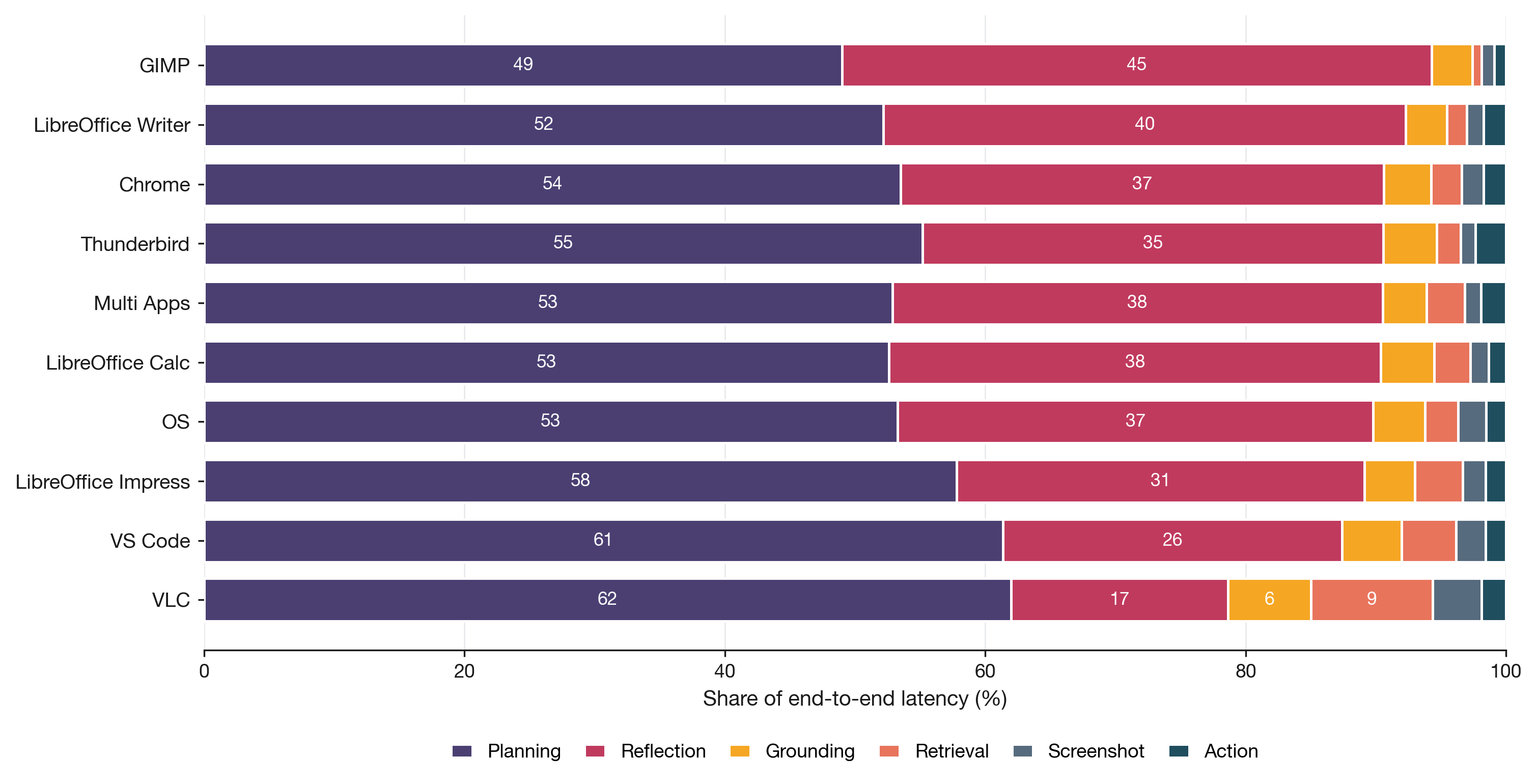
Fig 6 (page 16).
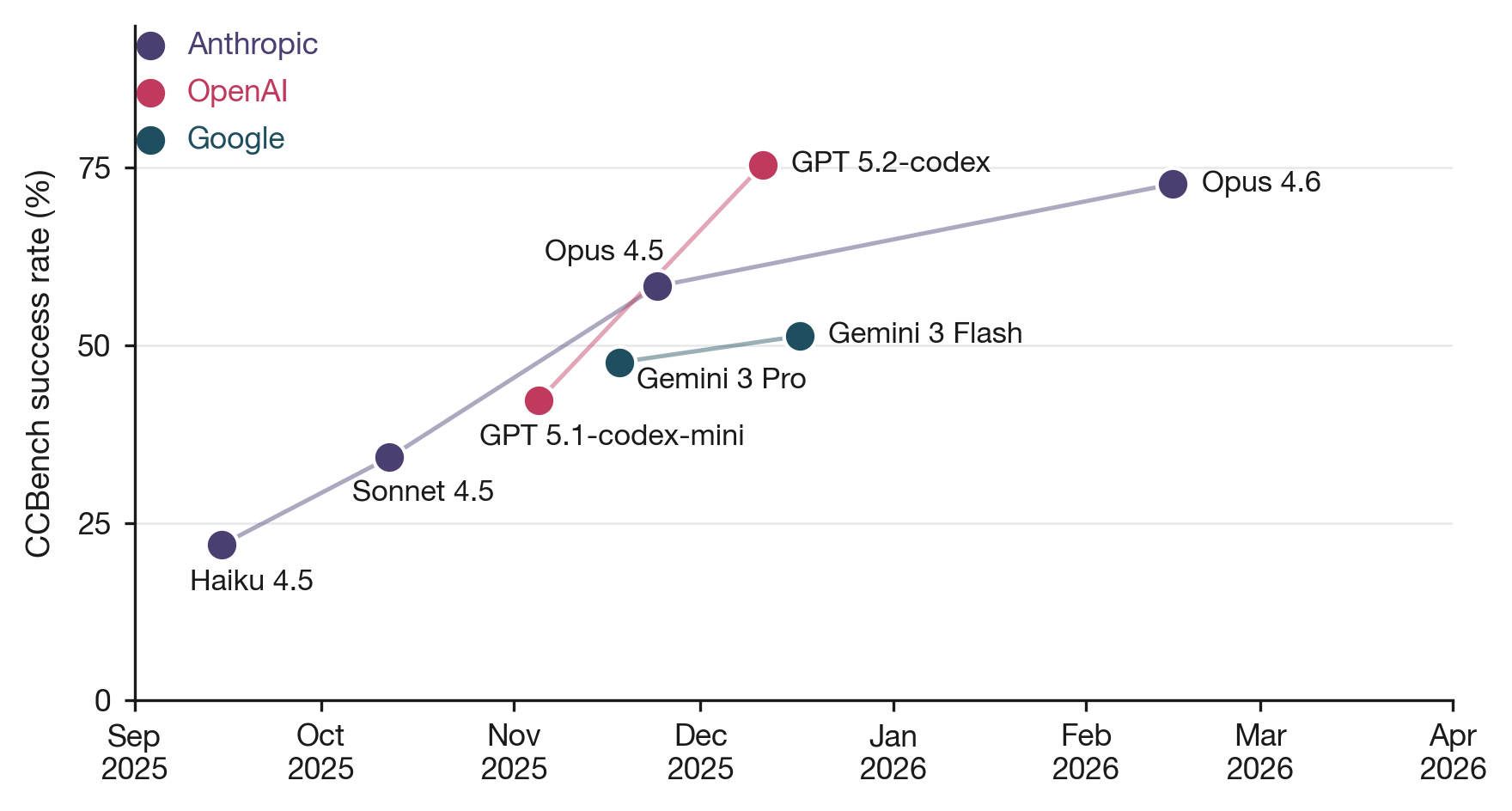
Fig 7 (page 16).
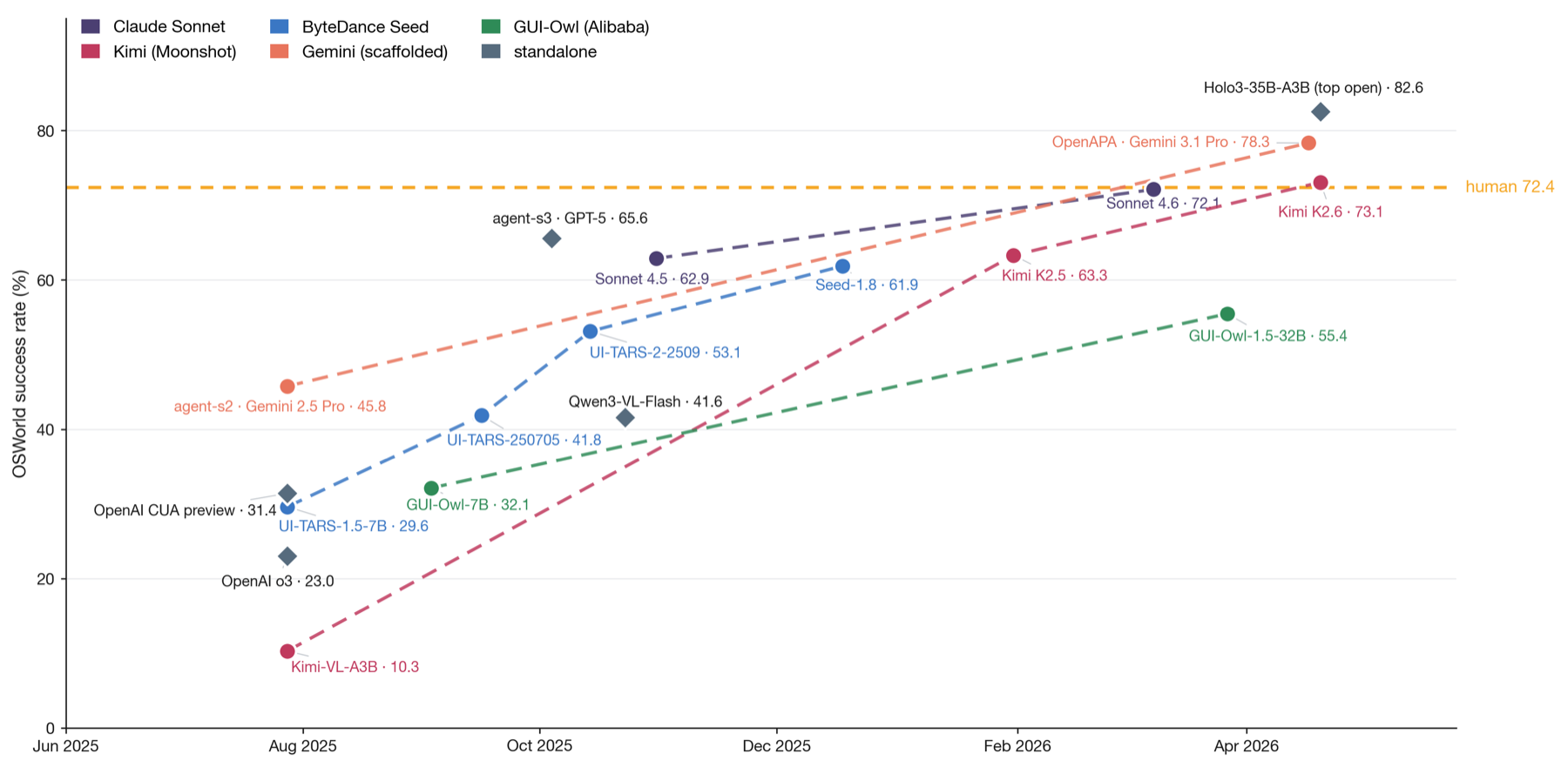
Fig 8 (page 17).
Limitations
- The synthetic evaluation dataset and all gold labels were generated by a single Claude Opus 4.7 checkpoint, conflating 'agreement with gold' and 'agreement with Opus preferences'.
- No human-validated calibration subset for gold labels; absolute accuracy numbers cannot be directly compared to human-annotated benchmarks like HAL or AgentRx.
- Small sample support in some security categories (e.g., only 3 refuse-gold and 7 stop-gold items), limiting security-related analysis resolution.
- The free-form mapping from taxonomy-blind prompts to labels relies on heuristic substring matching and fallback, with an estimated 3–5% mapper error rate possibly inflating accuracy drops.
- Differences in scaffolding, prompt formats, model tooling, budgets, and run environments across benchmark sources limit direct comparability of reported numbers.
- The narrow taxonomy and measurement are demonstrated on a controlled synthetic set, not a general benchmark release; results may not extrapolate to real production environments without further validation.
- Rapidly evolving MCP servers, tools, and policies mean security benchmark results may quickly become stale.
- Trajectory step-boundary ambiguity and labeling conventions limit exact failure localization accuracy (0.09–0.15), treated here as exploratory.
Open questions / follow-ons
- How can multi-generator or human-validated gold label sets improve measurement calibration and disentangle prompt supervision from model capability?
- What automated or learned methods could replace the heuristic substring + fallback approach for free-form diagnosis mapping to taxonomy labels to reduce mapper error?
- To what extent do taxonomy-aware prompting and the proposed taxonomies generalize across multi-agent or tool-augmented workflows beyond single-agent settings?
- How can the efficiency axis (steps, latency, cost), which currently lacks strong benchmark coverage, be better integrated into multi-axis agent evaluation frameworks?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, AgentAtlas provides a valuable framework to move beyond simplistic pass/fail success metrics for LLM agents that attempt to solve security or interaction challenges. The six-state control-decision taxonomy and nine-category trajectory failure taxonomy can guide more fine-grained analysis of how bot-like agents make decisions, handle uncertainty, recover from errors, refuse disallowed actions, or confirm sensitive steps. This level of behavioral diagnosis helps identify subtle automation faults or detection opportunities invisible to outcome-only scoring.
Moreover, the demonstration that prompt format and evaluation axis meaningfully shift rankings warns CAPTCHA integrators against trusting a single aggregate success metric or leaderboard position when evaluating LLM-based automation attacks. Evaluations that incorporate taxonomy-aware prompting can better isolate genuine agent reasoning from mere prompt supervision, thus improving the reliability of bot detection benchmarks. Finally, the benchmark audit illustrates which existing tools provide appropriate coverage of relevant axes like security and recovery, helping CAPTCHA teams select evaluation suites aligned with real-world adversaries and operational constraints.
Cite
@article{arxiv2605_20530,
title={ AgentAtlas: Beyond Outcome Leaderboards for LLM Agents },
author={ Parsa Mazaheri and Kasra Mazaheri },
journal={arXiv preprint arXiv:2605.20530},
year={ 2026 },
url={https://arxiv.org/abs/2605.20530}
}