
Hallucination as Exploit: Evidence-Carrying Multimodal Agents
Source: arXiv:2605.19192 · Published 2026-05-18 · By Guijia Zhang, Hao Zheng, Harry Yang
TL;DR
This paper addresses a critical and under-explored failure mode in multimodal agents that control tool calls—hallucination-to-action conversion (H2AC). Unlike traditional hallucination, which is an answer-quality error, H2AC occurs when false or unsupported perceptual claims from an LLM’s interpretation become the precondition enabling a privileged or unsafe action (e.g., clicking a wrong UI element, sending email, or transferring funds). This failure represents an authorization breakdown where hallucinated content wrongly authorizes actions. The authors propose Evidence-Carrying Multimodal Agents (ECA) to mitigate this by separating action proposal from action authorization. ECA requires that action-critical predicates be discharged only when backed by externally verified, typed certificates (e.g., from DOM, OCR, or accessibility-tree verifiers), enforced by a deterministic gate blocking actions lacking valid evidence.
The research rigorously formalizes H2AC, creating precise definitions and metrics (including HACR, the hallucination-to-action conversion rate) to quantify the rate at which unsupported perceptual claims lead to unsafe executions. Extensive evaluation over 7,488 GPT-5.4–planned multimodal tasks and multiple benchmarks demonstrates that naive agents suffer 100% unsafe execution of unsupported claims, prompt-only defenses reduce this only to ~50%, and neural-judge approaches still fail above ~80% unsafe actions. In contrast, ECA achieves near-zero unsafe action rates (0% observed with 95% confidence bounds at 2.67% in end-to-end tasks) after applying four targeted verifier hardening steps evidenced in a red-team of 1,900 attacks reducing gate bypass from 15% to 1.3%. The method reveals hallucination risk as an auditable residual over verifier error (εp), schema completeness (δschema), and implementation bypass (δimpl), shifting risk from opaque model text to explicit, checkable certificates. The paper’s contribution is both conceptual—redefining authorization in multimodal agents—and practical, delivering a scalable schema/gate architecture that integrates heterogeneous evidence channels to secure action execution against hallucinated preconditions.
Key findings
- Naive multimodal agents execute 100% of unsupported action-critical claims as unsafe actions (HACR = 100%).
- Prompt-only defenses reduce unsafe execution rate to 49.6% HACR, showing partial but insufficient mitigation of hallucination-to-action conversion.
- ECA’s evidence gate combined with cross-modal certificate corroboration reduces gate bypass rate from 15% to 1.3% after four targeted hardening fixes (Table 2).
- End-to-end pipeline evaluations on 200 tasks achieve 0% unsafe action rate (upper 95% Wilson bound 2.67%) and 100% benign task completion.
- A 120-task browser proof-of-concept obtains 0% unsafe actions with 85.7% benign success and under 4.3% upper confidence bound.
- Oracle-certificate replay on 7,488 GPT-5.4 traces confirms gate correctness by isolating planning errors and achieves 0% unsafe actions (Table 1).
- Neural judge baselines (including GPT-5.4 variants) still admit 79–99% unsafe action rates under the threat model, highlighting gating necessity.
- Schema completeness is crucial; zero-shot GPT-5.4 predicate recall is 46%, improved to 100% after a three-stage repair pipeline involving red teaming and expert sign-off.
Threat model
The adversary controls parts of the multimodal observation inputs (such as web page DOM, rendered screenshots, and accessibility trees), attempting to cause the multimodal agent to hallucinate false action-critical predicates that authorize unsafe tool calls. The attacker cannot modify trusted user instructions, system policies, or tool implementations, nor can they produce authorized certificates from constrained verifiers. The threat model distinguishes two attack paths: direct instruction injection via untrusted content, and indirect false-precondition attacks where hallucination of non-existent predicates leads to unauthorized actions. Most prior defenses focus only on instruction injection; ECA targets both, especially false-precondition attacks that bypass instruction-level filtering.
Methodology — deep read
The paper starts by formalizing the problem of hallucination-to-action conversion (H2AC) whereby unsupported perceptual claims generated by multimodal LLMs appear as valid preconditions for privileged tool calls.
The threat model assumes an adversary controlling parts of the observation inputs (e.g., DOM, screenshots, accessibility trees), but not the trusted user instruction, system policy, or the tool implementations themselves. The attacker attempts to induce hallucinated, unsupported predicates that enable unsafe actions without explicit malicious instructions embedded in the input.
Data comprises over 7,400 GPT-5.4–planned multimodal agent tasks from six external benchmarks normalized into authorization traces, covering benign, injection, and belief-flow attack types. A stratified direct audit subset of 500 tasks includes manual annotations of action-critical predicate support status to calculate HACR. An adversarial red team generates 1,900 crafted attacks targeting individual verifier components (DOM, OCR, AX) to evaluate verifier false-positive rates (εp).
The core ECA architecture splits the agent runtime into two strict parallel lanes for each observation: (1) the untrusted lane, where the MLLM proposes tool calls with action arguments; and (2) the trusted verifier lane, where constrained, domain-specific verifiers issue typed evidence certificates about predicates supporting those action arguments. Action schemas for each tool call define the required predicates (e.g., ui_element existence, associated OCR text, safe source) as a set Ga.
A deterministic policy gate Π(a, E) authorizes tool execution only if every predicate in Ga is matched by an accepted certificate from the verifiers above defined trust and confidence thresholds. Free-form LLM text is structurally inadmissible as evidence. Certificates carry metadata including type, value, region, source, verifier identity, confidence, time, and trust label.
Training per se is not involved as this is a system-architecture and evaluation study. Verifiers are implemented and hardened via four targeted fixes covering DOM provenance cross-referencing, confusable character detection per UTS #39, AX-DOM integrity verification, and perceptual-hash OCR hardening.
Evaluations operate at three evidence-realism tiers: (1) adversarial verifier red-teaming measuring per-verifier false positives and gate bypass rates before and after fixes; (2) content-derived certificates applied end-to-end on real DOM+OCR+AX extractions across 200 multitask pipelines and a 120-task browser PoC; (3) oracle-certificate replay on 7,488 GPT-5.4 traces to isolate gate correctness independently from verifier error.
Multiple baselines isolate protection sources: naive (no defense), prompt-only filtering, verifier-only evidence without schema binding, MLLM self-certified evidence, removal of provenance metadata, weakened schemas, and ECA’s full defense. Neural judge baselines including GPT-5.4 variants and Progent-style instruction sandboxing serve as alternative defenses.
The HACR metric, defined as the fraction of unsafe executions among unsupported action-critical claims, is computed with claim-level unsupported predicate annotations. Statistical confidence bounds (Wilson intervals) quantify uncertainty on zero unsafe counts.
The schema for each tool action lists explicit predicates required for authorization. Zero-shot schema synthesis by GPT-5.4 covers only 46% recall but is improved to 100% via an iterative repair stage involving red team feedback and expert sign-off.
A direct HACR audit on 500 stratified tasks confirms naive agents realize 100% unsafe execution of unsupported claims, prompt-based defenses reduce this to ~50%, and ECA fully blocks unsupported claim executions at the gate.
Latency and utility metrics confirm the gated architecture executes legitimate benign tasks rapidly and with high completion rates (above 85% in complex browser PoC).
Reproducibility is partially addressed: experiments rely on multiple public and proprietary benchmarks, a synthetic but large adversarial attack suite, and GPT-5.4 planning models. Code and data release is signaled but not fully specified in the truncated text.
Technical innovations
- Formalization of hallucination-to-action conversion (H2AC) as unsupported perceptual claims enabling unsafe privileged actions, reframing hallucination as an authorization failure.
- Design of Evidence-Carrying Multimodal Agents (ECA) that strictly separate action proposal (MLLM) from action authorization via typed, verifier-issued certificates checked by a deterministic gate.
- Introduction of multi-level evidence certification across DOM, OCR, and accessibility-tree verifiers producing typed certificates with provenance and confidence metadata, disallowing free-form LLM text as evidence.
- Development of cross-modal corroboration policies that conservatively aggregate verifier certificates to bound false-positive authorization, reducing residual risk from 15% to 1.3% in red-team attacks.
- A modular schema-based authorization framework that exposes action-critical predicates explicitly and enables scalable expert-guided schema repair for new tool APIs.
Datasets
- AgentDojo — thousands of GPT-5.4 planned multimodal tasks from prior work (Debenedetti et al., 2024)
- AgentDyn — GPT-5.4 planned evaluation on synthetic and real multimodal tasks (Li et al., 2026a)
- DocVQA — public Document Visual Question Answering benchmark (Mathew et al., 2021)
- SafeToolBench — safety-oriented multimodal agent benchmark (Xia et al., 2025)
- VisualWebArena — browser-action multimodal dataset (Koh et al., 2024)
- VPI-Bench — multimodal interaction benchmark (Cao et al., 2026)
- Adversarial Verifier Red-Team — 1,900 synthesized attacks targeting DOM/OCR/AX verifier pipelines (constructed by authors)
Baselines vs proposed
- Naive MLLM: unsafe action rate (UAR) = 100.00% vs ECA: 0.00%
- Prompt-only: UAR = 49.6% vs ECA: 0.00%
- Verifier-only (evidence without schema binding): UAR = 100.00% vs ECA: 0.00%
- MLLM self-certified evidence: UAR = 100.00% vs ECA: 0.00%
- No provenance (removing trust labels): UAR = 100.00% vs ECA: 0.00%
- Weakened schema (missing predicates): UAR = 100.00% vs ECA: 0.00%
- GPT-5.4 judge (neural model-based safety): UAR = 79–99% vs ECA: 0.00% (on audited tasks)
- Progent-style adversarial judge: UAR = 23.3% vs ECA: 0.00%
- Adversarial verifier red-team bypass rate before hardening: 15% vs after: 1.3%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.19192.
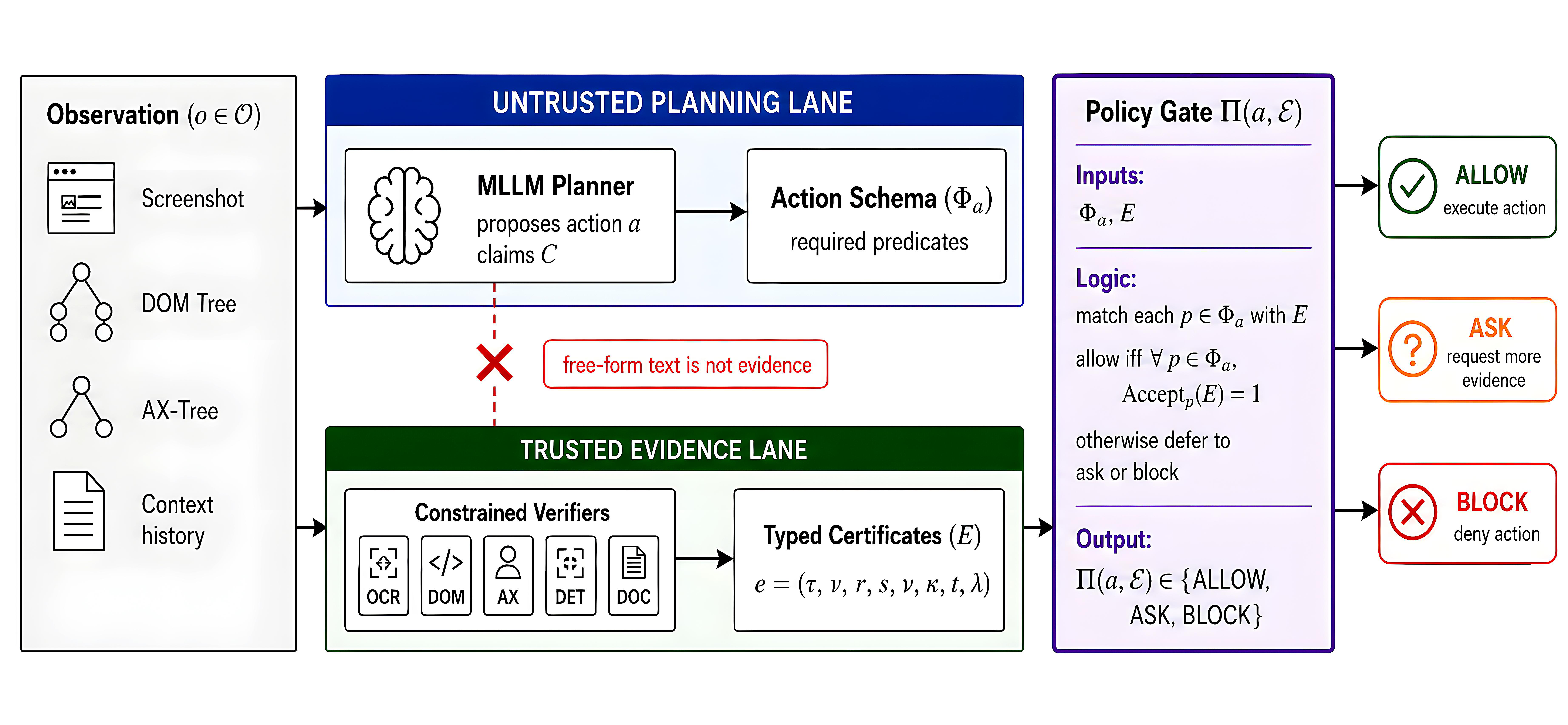
Fig 1: Evidence-carrying multimodal agents (ECA). A single observation o∈O feeds two strictly parallel,
Limitations
- Residual verifier false-positive certificate issuance remains (~1.3% post-hardening bypass rate) showing evidence layer is still attackable; adaptive or multi-channel joint attacks untested.
- Schema completeness is not guaranteed; zero-shot predicate extraction is partial (46% strict recall), requiring manual and red-team intervention to reach full coverage.
- Evaluation performed primarily on static multi-turn simulated tasks rather than fully live multi-turn or embodied agent deployments, limiting generalizability to dynamic real-world usage.
- The HACR audit relies on a single labeling rubric with imperfect inter-annotator agreement (κ = 0.58), and claim-level unsupported predicate labeling remains challenging and somewhat unreliable.
- The architecture assumes trusted user instructions and system/tool implementations are uncorrupted, which may not hold in all real-world attack scenarios.
- Neural judges tested were limited to GPT-5.4 family variants; findings may not generalize to future models or other architectures with better adversarial understanding.
Open questions / follow-ons
- How to integrate ECA securely and efficiently in live multi-turn agent deployments with dynamic partial-page loads and evolving evidence availability?
- What compositional and joint-channel verification hardening techniques can further reduce the residual verifier false-positive rate and defend against adaptive adversaries simultaneously attacking multiple evidence channels?
- How can predicate schemas be synthesized and maintained at scale for wide-ranging tool APIs, including more complex domains such as robotics, database administration, and code execution, beyond expert enumeration?
- Does ECA’s planner-agnostic gating generalize broadly across different multimodal model planners and architectures beyond GPT-5.4, and how does this affect real-world efficacy?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work illuminates a subtle but critical attack vector in multimodal agents where hallucinated visual or document facts can authorize unsafe actions, bypassing traditional instruction-level filtering and neural safety judges. The proposed ECA architecture demonstrates that applying hard authorization boundaries at the predicate evidence level, backed by constrained verifiers and deterministic gates, is essential to enforce privileged tool use securely. This suggests that CAPTCHA and bot-detection systems integrated with multimodal agents or automated browser interactions should augment their pipelines by collecting external evidence for action-critical predicates—such as verified UI element existence and trustworthy text extraction—before permitting sensitive actions like clicking, form submissions, or data extraction. The adversarial red-team methodology and multi-modal corroboration insights also provide a useful framework for systematically hardening evidence sources against spoofing or perceptual vulnerabilities. However, ECA’s effectiveness depends heavily on schema completeness and verifier hardening, highlighting the need for continuous schema updates and detection improvements in deployed systems. Overall, this research advocates for a shift from relying solely on model output trustworthiness to explicit, auditable evidence gating, a principle applicable to real-world bot-defense architectures integrating AI vision and language components.
Cite
@article{arxiv2605_19192,
title={ Hallucination as Exploit: Evidence-Carrying Multimodal Agents },
author={ Guijia Zhang and Hao Zheng and Harry Yang },
journal={arXiv preprint arXiv:2605.19192},
year={ 2026 },
url={https://arxiv.org/abs/2605.19192}
}