
DocOS: Towards Proactive Document-Guided Actions in GUI Agents
Source: arXiv:2605.18048 · Published 2026-05-18 · By Jingjing Liu, Ziye Huang, Zihao Cheng, Zeming Liu, Jiahong Wu, Yuhang Guo et al.
TL;DR
The paper addresses a critical limitation in current GUI agents: their dependence on static parametric knowledge from pre-training or instruction tuning, which hampers their ability to solve long-tailed, application-specific tasks requiring explicit procedural knowledge. To overcome this, the authors propose the novel paradigm of Proactive Document-Guided Action, where agents autonomously search online documentation in dynamic web environments and use retrieved instructions to guide GUI interactions. They introduce DocOS, a new benchmark suite with 817 high-quality, multi-step desktop tasks across 20 applications that explicitly tests an agent's ability to navigate browsers, find relevant documentation, comprehend instructions, and faithfully ground them into correct GUI actions. Extensive evaluation with state-of-the-art GUI agents reveals two major bottlenecks: difficulty reliably locating relevant information during proactive document search, and poor grounding of retrieved instructions to exact actions. These limitations cause low overall task completion rates despite partial navigation successes. This work systematically exposes the gap between current GUI agents and robust self-evolving agents capable of handling dynamic, long-tailed tasks via document-guided interactions.
Key findings
- DocOS contains 817 tasks spanning 20 applications, balanced across Easy (265), Medium (298), and Hard (254) difficulty levels (Table 2).
- Evaluated agents achieve low average Task Completion Rates (TCR), e.g., UI-TARS-1.5-7B obtains 17.31% TCR on Medium tasks, dropping on harder tasks (Table 3).
- Target URL Inclusion (TUI) scores are higher (e.g., Qwen3-VL-8B with 42.23% avg TUI), showing agents reach relevant documentation domains but fail to identify precise actionable pages.
- With access to external documents, GUI agents improved task completion by 2.59% to 7.66% relative depending on model (Table 4), confirming documents aid execution.
- Providing Oracle Documents (perfect instructions) boosts some models’ performance notably (up to +10.78%), suggesting document retrieval accuracy is a major bottleneck (Table 5).
- Strong models like UI-TARS-1.5-7B and Qwen3-VL-8B exhibit only modest gain from Oracle docs (~4%), indicating difficulty in grounding or filtering long instructions.
- Success rates drop sharply with increasing task steps; near perfect for single-step tasks with docs but nearly 0% for tasks requiring >4 steps (Fig 3).
- Common failure modes include imprecise localization within documents, reliance on unofficial or incomplete sources, executing tasks without retrieval, and incorrect action grounding.
Threat model
The adversary is not explicitly modeled in this work, as the paper focuses on agent capability evaluation rather than security adversaries. The implicit assumption is agents operate in an open dynamic web environment with access to official documentation but no malicious interference or adversarial manipulation of documents or interaction environments.
Methodology — deep read
The study defines a two-phase task paradigm for GUI agents in a partially observable Markov decision process (POMDP) framework: (1) Proactive Knowledge Retrieval, in which the agent browses online resources to find relevant official documentation; (2) Document-Grounded Execution, where the agent uses the retrieved document context to complete the original user instruction via precise GUI interactions.
The researchers curate the DocOS benchmark by integrating manual task construction, automated crawling of authoritative documents, and a rigorous three-stage filtering pipeline ensuring semantic consistency, unambiguity, and executability. The final dataset contains 817 high-quality desktop tasks categorized by complexity and spanning 20 real-world applications.
Six recent state-of-the-art GUI agents are tested, including Qwen3-VL-8B and UI-TARS-1.5-7B, using a combination of multi-GPU inference on RTX 4090 hardware. Each task is evaluated over two main metrics: document search performance (Target URL Inclusion, Hierarchical Path Progress) and task execution success (Task Completion Rate). Agents have 15 steps for browsing/document retrieval and 50 steps for task execution.
The evaluation involves comparing agent performance (a) using only internal parametric knowledge, (b) with retrieved documents, and (c) provided with ground-truth oracle documents to isolate bottlenecks. Error analyses on failed cases categorize issues into imprecise document localization, retrieval of unofficial or incomplete sources, premature execution, and failure to accurately ground instructions.
By decomposing Proactive Document-Guided Action into search and execution, the methodology allows fine-grained diagnostic evaluation revealing distinct challenges in autonomous document retrieval versus document-conditioned GUI action grounding. Reproducibility is ensured via public release of datasets and code.
A representative example: For the task "Create a run configuration from a python template" in PyCharm, the agent must first execute web search steps to locate the official Run/Debug Configurations documentation and then correctly follow instructions therein by navigating PyCharm's UI. This end-to-end workflow rigorously tests an agent's ability to bridge external knowledge into GUI control.
Technical innovations
- Propose Proactive Document-Guided Action paradigm enabling GUI agents to autonomously retrieve and utilize procedural documents from dynamic web environments rather than relying solely on static parametric knowledge.
- Design and release DocOS, a comprehensive benchmark integrating interactive desktop environments with real web navigation and document comprehension demanding multi-step task execution.
- Introduce dual evaluation metrics separating document retrieval quality (Target URL Inclusion, Hierarchical Path Progress) from task execution accuracy (Task Completion Rate) to identify distinct bottlenecks.
- Apply a rigorous multi-stage data curation and validation pipeline incorporating semantic consistency, unambiguity checks, and executability validation to ensure task and document quality.
Datasets
- DocOS — 817 tasks — curated interactive desktop tasks with official documentation across 20 applications
Baselines vs proposed
- UI-TARS-1.5-7B: Avg TCR = 17.31% vs with Oracle Document: 17.98% (+3.87%)
- MAI-UI-8B: Avg TCR = 10.96% vs with Oracle Document: 12.04% (+9.85%)
- Qwen3-VL-8B: Avg TCR = 4.23% vs with Oracle Document: 4.44% (+4.96%)
- GELab-Zero-4B-preview: Avg TCR = 4.36% vs with Oracle Document: 4.83% (+10.78%)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.18048.

Fig 1: An example of a Proactive Document-Guided Action task. The workflow is divided into two distinct phases: Proactive
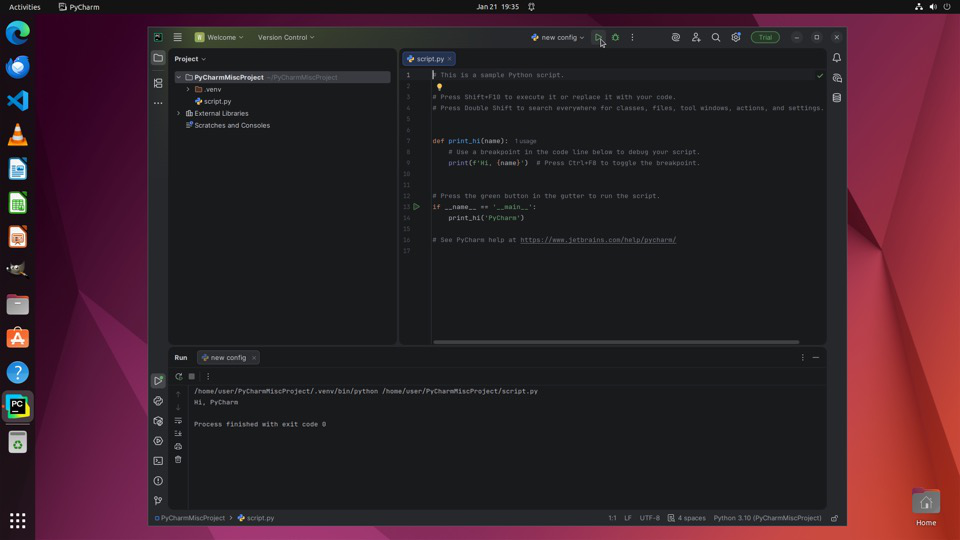
Fig 2 (page 2).

Fig 3 (page 2).

Fig 4 (page 2).

Fig 5 (page 2).

Fig 6 (page 2).
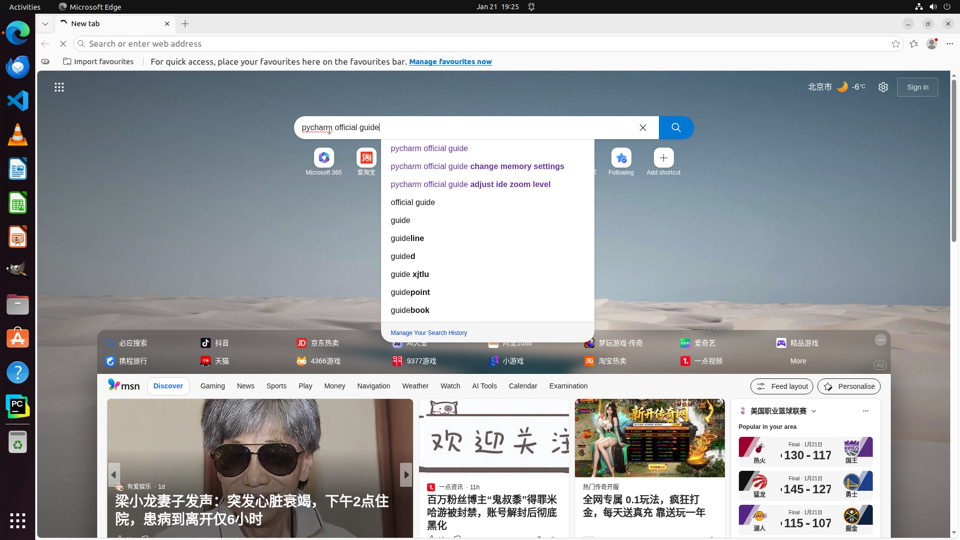
Fig 7 (page 2).
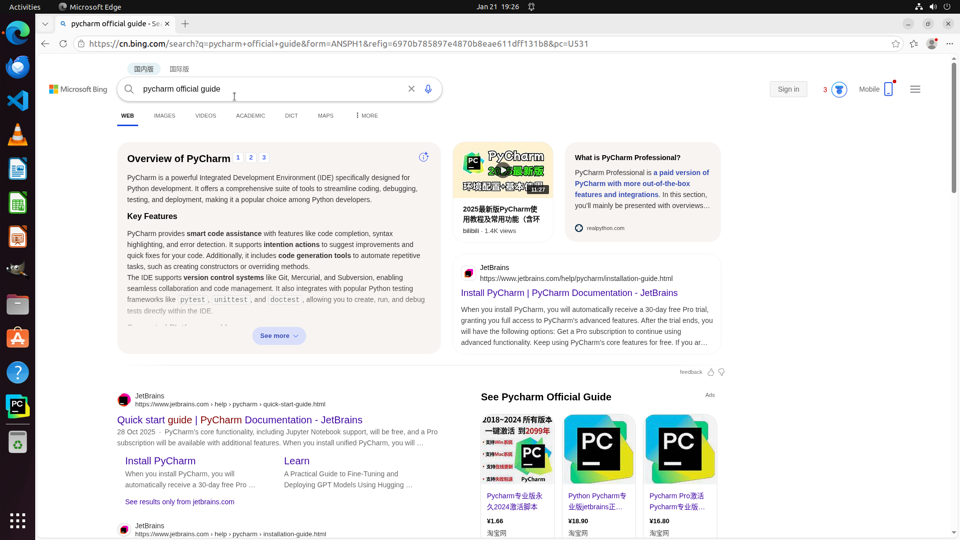
Fig 8 (page 2).
Limitations
- Overall task completion remains low across all tested agents, indicating persistent challenges in both accurate document retrieval and instruction grounding.
- Oracle document experiments reveal that some strong models suffer from difficulty handling lengthy document contexts, suggesting limitations in long-context comprehension.
- The benchmark covers desktop applications mainly on Ubuntu; generalization to other OSes or mobile platforms is unexplored.
- The current evaluation focuses on official documentation, potentially overlooking informal or community knowledge sources which agents may encounter in open web environments.
- No adversarial robustness or adversarial document retrieval attacks were tested; security implications of malicious or misleading documents remain unstudied.
- Human validation covers only about 20% of tasks for clarity and executability, leaving some risk of latent annotation or environment inconsistencies.
Open questions / follow-ons
- How to improve GUI agents' ability to precisely localize relevant procedural information within large, complex official documents?
- What architectural or training modifications can help large models better handle and filter lengthy contextual documents for execution grounding?
- Can retrieval-augmented agents autonomously identify and avoid unreliable or unofficial web sources in open environments?
- How to extend proactive document-guided paradigms to handle multi-modal or community-generated knowledge beyond official docs?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, DocOS illustrates a novel paradigm where autonomous agents proactively seek external documents to handle complex tasks rather than relying on fixed internal knowledge. This approach parallels how sophisticated bots might adapt by retrieving and grounding procedural knowledge in real time to evade detection or mimic legitimate user workflows. The benchmark highlights two critical technical challenges: accurately locating relevant web content among noisy online resources, and faithfully grounding complex instructions into precise interactive steps—both of which represent potential avenues for bot developers to increase automation robustness.
Conversely, defensive systems can use insights from DocOS to design CAPTCHA or interaction tasks that depend on long-tailed procedures requiring dynamic external knowledge retrieval, thus increasing difficulty for bots that do not integrate document-guided reasoning effectively. Evaluating defenses against proactive document-guided agents will need new strategies to detect when bots leverage such external knowledge, making DocOS a foundational research tool to model and benchmark those advanced capabilities.
Cite
@article{arxiv2605_18048,
title={ DocOS: Towards Proactive Document-Guided Actions in GUI Agents },
author={ Jingjing Liu and Ziye Huang and Zihao Cheng and Zeming Liu and Jiahong Wu and Yuhang Guo and Kehai Chen and Yunhong Wang and Haifeng Wang },
journal={arXiv preprint arXiv:2605.18048},
year={ 2026 },
url={https://arxiv.org/abs/2605.18048}
}