
WebGameBench: Requirement-to-Application Evaluation for Coding Agents via Browser-Native Games
Source: arXiv:2605.17637 · Published 2026-05-17 · By Wenyu Zhang, Guoliang You, Tianlun, Haotian Zhao, Tianshu Zhu, Haoran Wang et al.
TL;DR
WebGameBench introduces a new benchmark for evaluating coding agents by assessing their ability to convert structured game requirements into fully functioning browser-native games. Unlike prior code-generation benchmarks that evaluate at the source code or test level, WebGameBench tests delivered interactive applications through real browser runtime interactions. This approach leverages browser-native games as a compact but behaviorally rich testbed encompassing input handling, spatial reasoning, rule execution, state transitions, and restart logic. The benchmark provides a closed-loop pipeline where agents synthesize code from frozen Structured WebGame Specifications, the generated artifact is built and deployed locally as a browser-accessible URL, and a runtime evaluator interacts with the deployed game to assign quality labels based on actual gameplay behavior. Experimental evaluation across 111 tasks, 12 agents, and 14 configurations shows a clear performance hierarchy: the top agent configuration attains a 76.9% usable rate (EXCELLENT or USABLE) but only a 20.2% excellent rate, revealing a substantial gap between minimum usability and comprehensive spec fulfillment.
By validating runtime evaluation labels against human gameplay review on a subset, the authors demonstrate reasonable alignment under the usable-rate criterion. However, exact three-way label agreement remains challenging due to subtle runtime defects and granularity of judgment. The dataset comprises seven gameplay families, with difficulty stratification based on structural and logical complexity, enabling detailed analysis of failure modes. Overall, WebGameBench shifts application evaluation away from surrogate signals towards direct delivered application runtime assessment in a reproducible and scalable manner, providing a new lens on coding agent progress for interactive application delivery.
Key findings
- The best coding agent configuration, opus-4-7, achieves a usable rate of 76.9% but only a 20.2% excellent rate on 111 browser-native game tasks.
- Difficulty stratification shows usable rate drops from ~75% for easier tasks (D1/D2) to only 12.6% on the hardest tasks (D4).
- Runtime evaluator and human gameplay judgments align with 85.0% accuracy and 82.9% macro-F1 at the usable vs unusable boundary (Ruse label) under high reasoning effort.
- Exact three-way label agreement (EXCELLENT/USABLE/UNUSABLE) is lower at 50.0% accuracy due mainly to evaluator downgrading human EXCELLENT labels to USABLE.
- Among 14 agent configurations spanning 12 models, usable rates range widely from 38.3% to 76.9%, showing clear capability gaps.
- Runtime evaluation diagnoses critical interactive failures (input handling, state transitions, rule execution) that are missed by static build logs or screenshots.
- The curated 111-task benchmark covers seven gameplay families and is annotated with functional points along behavior, spatial, and temporal complexity axes.
- Buildability and page load success alone are insufficient metrics, as many artifacts load but fail key runtime behaviors required by the specification.
Threat model
The adversary is a coding agent tasked with producing a browser-native game application from a frozen structured specification under a fixed development and deployment protocol. The agent must deliver an application that satisfies all specified interactive runtime behaviors. The evaluator acts as an independent verifier by performing scripted interactions in a real browser environment. There is no active adversarial manipulation of the evaluation environment, network, or specification by the agent; the threat assessment focuses on the agent's functional correctness and application delivery capability rather than hostile attacks.
Methodology — deep read
Threat Model & Assumptions: The benchmark simulates a scenario where a coding agent receives a frozen structured web game specification (σ) describing all functional requirements (gameplay goals, input controls, rules, state transitions, terminal and restart conditions). The agent must generate a browser-native application meeting these requirements. The adversary is the coding agent limited by the workspace and no external services, evaluated on its ability to deliver a correct playable game artifact. The runtime evaluator is a code model controlling a real browser and interacts with the deployed app to verify requirement satisfaction. There is no direct adversarial attack but rather assessment of correct implementation.
Data: The dataset contains 111 browser-native game tasks synthesized from public game taxonomies and user requests. Specifications are frozen Structured WebGame Specifications detailing objectives, input, spatial layouts, states, rules, and feedback. Tasks span seven gameplay families (Puzzle, Action, Shooting, Strategy, Casual, Board/Card, Racing). Difficulty is annotated by structural scale (S1-S4) and logical depth (L1-L4) axes, combined into a D-level from D1 (easiest) to D4 (hardest). Each specification is annotated with 1000s of functional points decomposed into behavior, spatial topology, and temporal state complexity. Seeds from public portals are normalized to exclude IP/assets. The dataset reflects a broad coverage of gameplay mechanisms and difficulties suited for requirement-to-application evaluation.
Architecture / Algorithm: Each coding agent is given identical input (frozen specification) and workspace template using a browser-native development stack (React, TypeScript, Vite, Tailwind) to generate source artifacts. Generation attempts produce zipped project workspaces which are locally built and served as a browser-accessible URL. The runtime evaluator is a Codex-based large language model controlling Chrome via Playwright. It plans interactions based on the specification, performs browser actions (click, keyboard, navigation), observes page state, and collects evidence like screenshots, logs, and runtime states. It uses a structured evaluation prompt to verify accessibility, input handling, spatial mapping, rule execution, state transitions, score changes, terminal and restart behavior in a real browser environment.
Training Regime: Not applicable to benchmark design as agents are pre-existing models run under a fixed evaluation protocol. The runtime evaluator specifically uses Codex CLI 0.115.0 with GPT-5.4 backend and XHigh reasoning effort configuration. Each artifact is evaluated in a single two-hour rollout without fixed step limits.
Evaluation Protocol: Evaluation labels are EXCELLENT (full requirement satisfaction), USABLE (playable main path with minor defects), or UNUSABLE (failure to complete core loop or load app). Usable rate aggregates EXCELLENT+USABLE samples, while excellent rate counts EXCELLENT only. Coverage is percentage of attempts yielding valid labels. Cross-model and cross-configuration comparisons are made on 111 tasks with 14 configurations from 12 agents. A human-reviewed subset (43 artifacts) is used to assess alignment between runtime evaluator and human gameplay judgments under the Usable rate criterion. Statistical metrics reported include label agreement, accuracy, and macro-F1 score under multiple reasoning efforts.
Reproducibility: The benchmark uses frozen publicly derived specifications and a defined workspace template. Generation attempts and deployment are standardized. Runtime evaluator uses a fixed Codex model and Playwright. Code and corpus status is described as closed but the specification schema and benchmark protocol are disclosed. Artifacts and evaluation evidence are logged to allow traceability. Human review is documented for quality validation. The paper does not state full public code release but provides thorough dataset and protocol descriptions.
Example Workflow: For a given game task, the coding agent receives the frozen Structured WebGame Specification as input and generates a React/TypeScript source project matching the spec and build constraints. This artifact is built locally and exposed at a localhost URL. The Codex-based runtime evaluator opens the URL in Chrome via Playwright, interacts by simulating user inputs and observes gameplay behavior, score updates, rule firing, state transitions, and restart correctness. It collects screenshots and console logs as evidence. Based on this observable runtime evidence and the specification, it assigns one of three quality labels. This end-to-end process fully closes the loop on from requirement to delivered interactive application runtime behavior.
Technical innovations
- Introduction of requirement-to-application evaluation framework that measures coding agent success by delivered interactive application's runtime behavior in a real browser, rather than only code correctness or build success.
- Use of browser-native games as a compact yet behavior-dense substrate capturing interaction, spatial, rule, and state complexities enabling a unified delivery and runtime evaluation protocol.
- A linearly stratified difficulty annotation (D1-D4) combining structural scale and logical depth designed to predict implementation risk and interpret model failure modes.
- A Codex-based runtime evaluator that performs structured browser interaction and scripted verification of delivered applications producing evidence-grounded, three-way quality labels.
- Closed-loop benchmark pipeline connecting frozen structured specifications, standardized code generation, local building/deployment, and interactive live evaluation accessible by URL.
Datasets
- WebGameBench corpus — 111 browser-native game tasks — synthesized from public browser game taxonomies and user requests, frozen Structured WebGame Specifications.
Baselines vs proposed
- opus-4-7: usable rate = 76.9% vs other, e.g., gpt-5-5 usable rate = 63.6%
- opus-4-7: excellent rate = 20.2% vs hy3-xhigh excellent rate = 6.6%
- KL difference among agents spans from 38.3% (kimi-k2.5) to 76.9% (opus-4-7) usable rate
- D1 difficulty subgroup: usable rate ~73.7% pooled; D4 subgroup: usable rate ~12.6%
- Runtime evaluator accuracy on human-reviewed set: usable/not usable at 85.0% (XHigh) reasoning effort
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.17637.
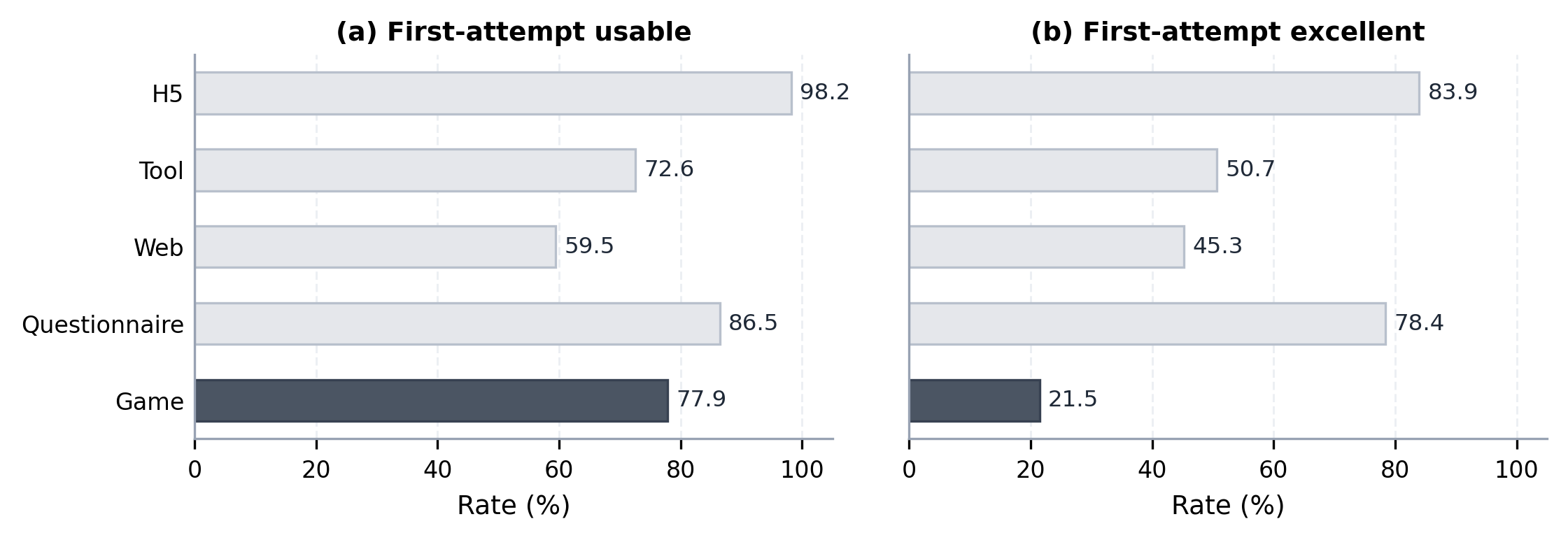
Fig 1: Pilot study on browser-native artifacts. We use ‘Opus 4.6’ to compare H5, Tool, Web,

Fig 2: Overview of the WebGameBench pipeline. Each task is defined by a frozen Structured

Fig 3: WebGameBench corpus profile over 111 browser-native game requirements, including

Fig 4 (page 4).

Fig 4: Agreement between the runtime evaluator and human-review labels. The first three

Fig 5: Two representative runtime case studies in the main text. Each task compares Kimi K2.5

Fig 6: Supplementary runtime case studies for the four tasks omitted from the main text. Each
Limitations
- Exact three-way quality labeling (EXCELLENT/USABLE/UNUSABLE) remains challenging with only ~50% agreement between runtime evaluator and human reviewers.
- Benchmark is limited to browser-native games, which may not generalize to arbitrary software applications or non-browser platforms.
- Frozen Structured WebGame Specifications are designed and filtered for feasibility, potentially biasing difficulty and coverage.
- Runtime evaluator uses scripted verification with Codex-based agents, which may miss subtle bugs or complex multi-session behaviors that require more extensive exploration.
- No direct adversarial or robustness evaluation; focus is on baseline coding agent capability differentiation under fixed conditions.
- Source code and training data for some agents may be closed or proprietary, limiting reproducibility of generation experiments.
Open questions / follow-ons
- How to improve fine-grained distinction and reliability of automated runtime quality labeling between EXCELLENT and USABLE states?
- Can the benchmark and evaluation protocol be extended to more complex, asset-rich web applications beyond games or to multi-session interactive settings?
- What architectural or training modifications in coding agents improve delivered application runtime behavior, especially under high D-level difficulty?
- How to integrate multi-modal feedback (e.g., video, audio) or non-browser execution environments into requirement-to-application evaluation?
Why it matters for bot defense
WebGameBench's approach highlights the importance of evaluating automated code generation systems by their delivered application's interactive runtime behavior, not just source code correctness or build success. For bot-defense and CAPTCHA practitioners, this underscores the risk that a system may appear functional at a superficial level yet fail key runtime behaviors critical for user interaction security and usability. The multi-level labeling and runtime evidence package concept provide useful ideas for designing verification protocols that combine automated browser interactions with grounded failure diagnostics. Moreover, the difficulty stratification and functional-point annotation methods could help tailor bot-detection challenges by complexity and behavior type. While WebGameBench focuses on interactive game delivery, the requirement-to-application evaluation paradigm is broadly applicable to understanding how well coding agents can produce robust interactive web artifacts that resist automation or preserve intended interaction semantics.
Cite
@article{arxiv2605_17637,
title={ WebGameBench: Requirement-to-Application Evaluation for Coding Agents via Browser-Native Games },
author={ Wenyu Zhang and Guoliang You and Tianlun and Haotian Zhao and Tianshu Zhu and Haoran Wang and Xiaoxuan Tang and Mingyang Dai and Jingnan Gu and Daxiang Dong and Jianmin Wu },
journal={arXiv preprint arXiv:2605.17637},
year={ 2026 },
url={https://arxiv.org/abs/2605.17637}
}