
From Runnable to Shippable: Multi-Agent Test-Driven Development for Generating Full-Stack Web Applications from Requirements
Source: arXiv:2605.17242 · Published 2026-05-17 · By Yuxuan Wan, Tingshuo Liang, Jiakai Xu, Jingyu Xiao, Yintong Huo, Michael R Lyu
TL;DR
TDDev addresses a core bottleneck in AI-driven full-stack web application generation: the gap between runnable code and functionally correct, shippable apps. State-of-the-art coding agents typically produce runnable prototypes but fail to meet functional specifications over 70% of the time, primarily because correctness must be validated through deployment and dynamic browser interactions rather than static code inspection or terminal outputs. TDDev automates the entire test-driven development loop for web apps across three stages: (1) generating structured acceptance tests from natural-language requirements before coding; (2) deploying the app and validating it via simulated browser interactions using an LLM-guided Playwright agent; and (3) translating browser-observed failures into actionable repair reports for the coding agent. This closed feedback loop enables autonomous iterative refinement without human intervention.
The authors conduct the first controlled empirical study of test-driven development strategies for web app generation, evaluating four development protocols (Non-TDD, Agentic, Whole-Project, Incremental) across two coding agents, two backbone LLMs, and two benchmarks (WebGen-Bench and ArtifactsBench). Results demonstrate a consistent 34–48 percentage point improvement in generation accuracy when leveraging TDD infrastructure over the baseline. Moreover, the best TDD protocol depends on the coding agent's generation style: holistic code generators achieve maximal gains with agentic (low-enforcement) TDD, while incremental (high-enforcement) TDD benefits conservative extenders. Mismatch between protocol and style eliminates improvements and drastically increases token consumption. A user study confirms that TDDev replaces previously necessary manual developer interventions with autonomous feedback-driven refinement, shifting effort from prompt engineering to closed-loop code repair.
Key findings
- TDDev’s test generation module covers 91.9% of ground-truth WebGen-Bench features, producing on average 12.4 generated tests per app versus 6.2 reference tests.
- The browser-based testing agent achieves 87.5% overall accuracy in test verdicts, detecting 100% of injected defects with zero false positives but 25% false negatives on correct apps (conservative failure mode).
- TDD infrastructure improves final generation accuracy (acc@K) by 34–48 percentage points compared to a no-TDD baseline across agents, models, and benchmarks.
- Incremental TDD enforcement delivers the best performance for coding agents that extend existing code conservatively, while agentic (low-enforcement) TDD is optimal for holistic code generators.
- Mismatching the enforcement protocol to model style abolishes TDD benefits and can multiply token usage up to 25-fold due to wasted repair iterations.
- Multiple feedback rounds incrementally improve generation accuracy, with gains saturating after 3–5 repair cycles.
- Acceptance tests derived via persona-based soap opera scenarios enable concrete, diverse, and user-centric coverage from vague natural-language requirements.
- The LT-enabled acceptance test driving is fully automated, eliminating human-in-the-loop intervention otherwise needed to interpret browser failures and direct iterative repair.
Threat model
The adversary is represented implicitly as the inherent challenges posed by non-deterministic web app implementations and incomplete observability of failures without human mediation. There is no explicit malicious attacker model, but the system assumes the coding agent must autonomously detect and repair functional deviations without human prompts, while the testing agent must reliably detect failures from limited rendered state. The framework does not address active adversarial interference or poisoning of requirements or tests.
Methodology — deep read
The authors define a closed-loop Test-Driven Development (TDD) framework, TDDev, for generating full-stack web applications from high-level natural language requirements. The process has three automated stages:
Requirement Concretization / Acceptance Test Generation:
- Starting with a vague natural language requirement, the system uses an LLM to instantiate realistic user personas and goals (inspired by soap opera testing).
- For each persona-goal, the LLM generates detailed acceptance tests consisting of a feature description, ordered browser interaction steps (clicks, inputs, navigations), and expected observable outcomes on the rendered UI.
- This yields a structured, executable test suite before any code is written, providing an unambiguous development target.
Interactive Validation:
- After the coding agent generates application source, TDDev deploys the app locally and uses Playwright with Chromium to open the app URL.
- A testing agent, implemented as an LLM controller, reads the browser's accessibility tree at each interaction step along with test context and history.
- The LLM generates Playwright actions step-by-step, executing them to simulate realistic user interactions that verify each acceptance test.
- The agent returns a test verdict (Pass, Fail, Partial) once sufficient evidence is observed or maximum steps are reached.
- By generating actions on rendered content at runtime, the agent adapts to structural and UI variations across runs.
Failure Translation:
- When tests fail, TDDev summarizes the full interaction trajectory and natural language failure explanation into a structured repair report.
- The report precisely identifies which step failed, observed deviations, and partial progress, providing actionable feedback for the coding agent’s repair cycle.
Development Protocols:
- Four protocols vary in TDD enforcement level:
- Non-TDD baseline: agent receives only requirements, no automated test or retry loop.
- Agentic TDD: agent has deploy/test tools and TDD workflow instructions but controls when to run and repair.
- Whole-Project TDD: agent implements full app, then iterates deploy-test-repair on whole suite.
- Incremental TDD: strict TDD discipline; one feature tested and fixed at a time with regression checks.
Data:
- WebGen-Bench: 101 functional web app generation tasks; experiments sample 50.
- ArtifactsBench: additional 100 tasks used for cross-dataset evaluation.
Coding Agents:
- ClaudeSDK: production-capable SDK with an Anthropic Claude Sonnet 4.6 LLM.
- OpenCode: open-source terminal-based agent supporting any OpenAI-compatible model.
Backbones:
- Claude Sonnet 4.6 (primary)
- Qwen-3.5-397B (cross-model study)
Evaluation Metrics:
- Test coverage compares generated acceptance tests against ground-truth feature annotations.
- Testing agent accuracy measured by agreement with known verdicts on fixture apps.
- Generation accuracy acc@k computes the percentage of tests passed or partially passed within k repair attempts.
- Token consumption for cost analysis.
Experimental Setup:
- Conducted on MacBook Pro with M-series CPU, using Playwright + Chromium for browser simulation.
- Fixed random seeds for reproducibility.
One example end-to-end process:
- Input: "a food distribution web app"
- Acceptance tests generated by identifying personas like coordinators posting food and recipients searching.
- Each persona goal expanded into interaction steps (e.g., posting a product).
- Agent first implements feature code given these tests.
- App deployed locally.
- Testing agent navigates rendered app, clicks buttons, fills forms according to acceptance test steps.
- Any deviation produces failure report.
- Agent uses failure report to iteratively repair code until tests pass.
Reproducibility:
- TDDev code, data, and evaluation fixtures released openly.
- Framework modular to support different agents through an MCP server interface.
Technical innovations
- Integrating acceptance test generation directly from vague natural language requirements using an LLM-driven persona and soap opera test scenario approach.
- Introducing an LLM-controlled browser testing agent that interacts stepwise with the live deployed app by reading accessibility trees and generating Playwright commands dynamically.
- Automated failure translation converting browser interaction trajectories and verdicts into structured, actionable repair reports for coding agents.
- A modular TDD framework supporting multiple levels of external enforcement (incremental, whole-project, agentic) allowing controlled empirical study of TDD strategies across diverse coding agents and backbones.
Datasets
- WebGen-Bench — 101 web application tasks — public dataset with human functional annotations
- ArtifactsBench — 100 dynamic web UI generation tasks — public benchmark for cross-dataset evaluation
Baselines vs proposed
- Non-TDD baseline: acc@K = approx. 28-33% vs TDDev TDD protocols: acc@K = 62-81% (34-48 points improvement)
- Incremental TDD vs Whole-Project TDD: incremental outperforms whole-project on conservative code extenders by ~5-10 points; reverse holds for holistic generators
- Agentic TDD vs Incremental TDD: mismatched enforcement leads to up to 25x increase in token usage and loss of accuracy gains
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.17242.

Fig 1: Overview of TDDev. Requirements are first converted into acceptance tests. The coding agent then implements the
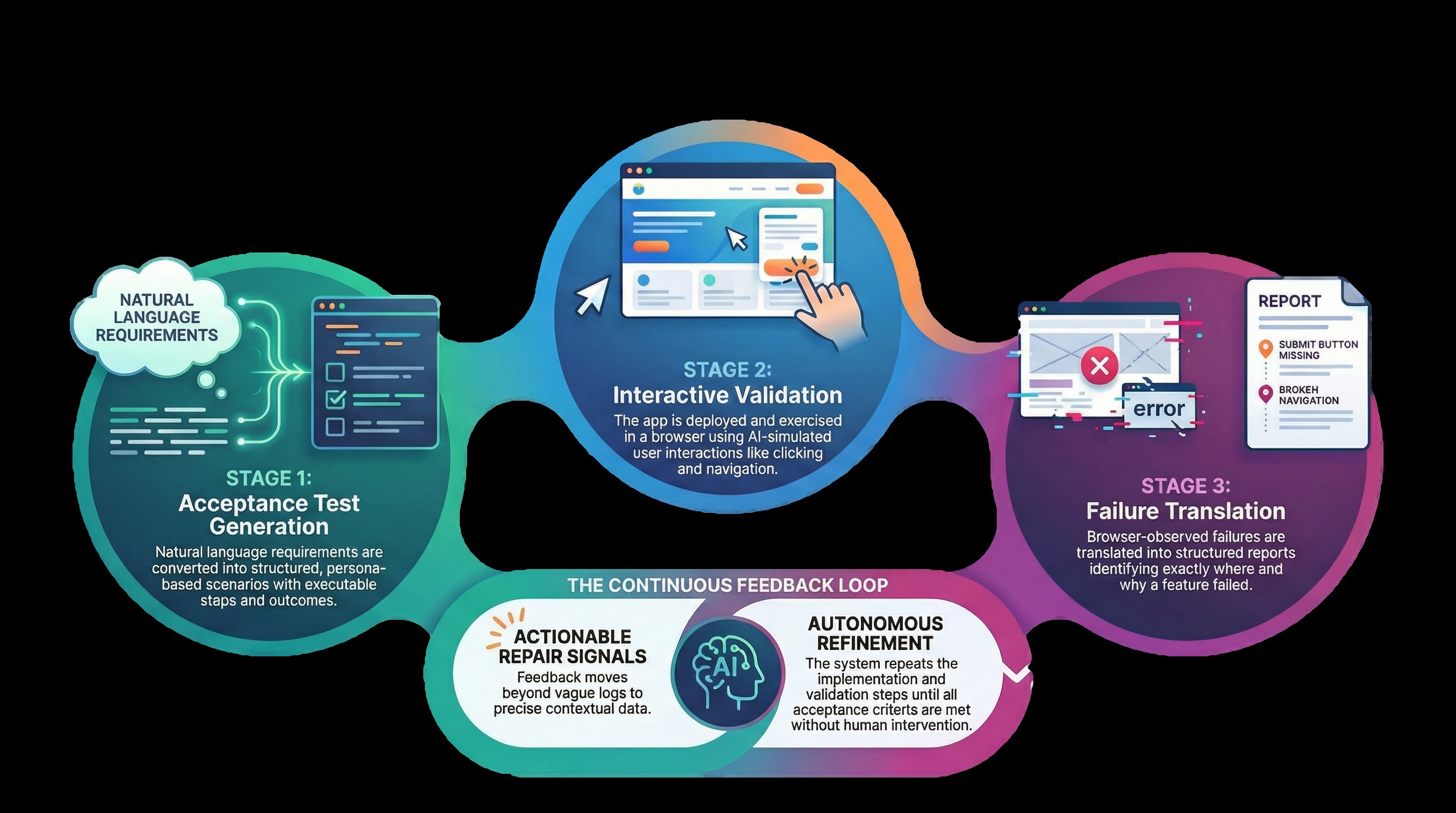
Fig 2 (page 4).

Fig 3 (page 4).

Fig 4 (page 4).
Limitations
- Test generation coverage misses features requiring detailed operational or UI walkthrough knowledge not inferable from high-level instructions (e.g., site-wide navigation).
- Testing agent occasionally produces false negatives on correct apps due to selector mismatches or conservative string-matching.
- Evaluation restricted to two coding agents and two backbone models; generalizability to other LLMs or architectures remains to be seen.
- Experimental budgets and iteration counts are limited (max 5 feedback rounds), leaving longer-term convergence unexplored.
- No adversarial evaluation against sophisticated attackers attempting to fool or bypass test-driven agents.
- Browser simulation relies on Chromium and accessible tree snapshots; real-world browser diversity or UI complexities might pose challenges.
Open questions / follow-ons
- Can the TDDev framework extend to multi-agent collaborative development scenarios where multiple agents generate different app modules concurrently?
- How will TDDev perform with larger, more complex applications requiring richer UI semantics, asynchronous interactions, or third-party API integration?
- Can the test generation stage be improved using richer domain knowledge or user behavior telemetry to bridge coverage gaps in structural or navigation features?
- What adaptations are needed to support adversarial robustness against malicious input or agents attempting to subvert the TDD process?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, TDDev provides a compelling example of closing the feedback loop in autonomous system generation through meaningful, interpretable acceptance criteria and runtime environment validation. The approach of translating high-level intent into structured interaction scripts that an agent can autonomously execute and verify parallels challenges in validating complex bot behaviors against intended security policies. TDDev’s integration of browser-level interaction modeling and failure abstraction into actionable repair signals could inspire novel bot detection or countermeasure systems that dynamically verify client-side behavior through simulated scenarios rather than static heuristics or network-level signatures. Additionally, the differentiation between incremental versus holistic enforcement protocols highlights the need to match enforcement strategies with the behavioral style of adversaries or clients in a security context to optimize detection and remediation cost versus effectiveness.
Cite
@article{arxiv2605_17242,
title={ From Runnable to Shippable: Multi-Agent Test-Driven Development for Generating Full-Stack Web Applications from Requirements },
author={ Yuxuan Wan and Tingshuo Liang and Jiakai Xu and Jingyu Xiao and Yintong Huo and Michael R Lyu },
journal={arXiv preprint arXiv:2605.17242},
year={ 2026 },
url={https://arxiv.org/abs/2605.17242}
}