
Automated Root-Cause Subclassification and No-Code Fix Generation for Invalid Bug Reports
Source: arXiv:2605.17561 · Published 2026-05-17 · By Mahmut Furkan Gon, Emre Dinc, Tevfik Emre Sungur, Eray Tuzun
TL;DR
This paper addresses the challenge of automatically subclassifying invalid bug reports by their root causes and generating corresponding no-code fixes—resolutions that do not require source code changes. Invalid bug reports, which make up a significant portion of total reports (e.g., about 22% in Eclipse), impose wasted effort on developer and customer support teams when misclassified or unresolved manually. Prior work has focused mostly on detecting invalid bugs but has not tackled fine-grained subclassification or automated resolution. The authors create a standardized taxonomy of invalid bug report root causes (including Faulty Configuration, External Dependencies, Feature Requests, Non-reproducibility, Questions, Working as Designed, and Wrong Version) and develop a novel curated benchmark from the popular Brave browser GitHub repository consisting of 8,289 invalid reports thoughtfully relabeled with root cause subclasses and paired no-code fixes. They evaluate multiple methods to perform invalid subclass classification and natural language no-code fix generation, comparing vanilla large language models (LLMs), retrieval-augmented generation (RAG), and agentic web search (an autonomous LLM-guided deep web navigation approach). Results from their IssueSupport framework show that RAG slightly outperforms vanilla LLMs and agentic web search for invalid subclass classification with a weighted F1 around 0.66, while agentic web search delivers the best no-code fix generation quality with a 68.9% success rate according to a Judge LLM. Certain subclasses such as Non-reproducibility and Feature Request are classified with very high F1 up to 0.85, but the Wrong Version subclass remains challenging (0.00-0.29 F1). The study demonstrates automated end-to-end root cause subclassification coupled with actionable no-code fix suggestion can help streamline bug triage and improve customer support by reducing manual effort and speeding issue resolution.
Key findings
- The proposed taxonomy defines 7 root cause-based invalid bug report subclasses: External System & Dependency Issues, Faulty Configuration, Feature Request, Non-reproducible, Question, Working as Designed, and Wrong Version.
- RAG achieves highest invalid subclassification weighted F1-score of 0.66, slightly better than vanilla LLMs (0.65) and agentic web search (0.64).
- At subclass level, Non-reproducibility subclass reaches 0.85 F1, Feature Request and Question achieve 0.79 F1, while the Wrong Version subclass is hardest with 0.00–0.29 F1 range.
- Agentic web search yields highest Judge LLM success rate for no-code fix generation at 68.9%, outperforming RAG (64.4%) and vanilla LLMs (64.9%).
- No-code fix success rates peak at 87.4% for the Working as Designed subclass and 72.2% for Question subclass.
- Incorporating root cause subclass information improves no-code fix generation performance compared to fix generation without subclass priors.
- The dataset comprises 8,289 invalid bug reports from the Brave browser GitHub repository, relabeled manually with root cause subclasses and aligned no-code fixes.
- Automated filtering removed duplicate, stale, and irrelevant labels, focusing the curated benchmark on actionable invalid bug reports for analysis.
Threat model
The adversary is the user submitting bug reports that may be invalid due to misunderstanding, misconfiguration, or outdated versions, not a malicious attacker actively trying to subvert the system. The system assumes access to the textual content of bug reports and project documentation but does not defend against adversarial inputs or data poisoning attacks. The objective is automated triage and resolution assistance rather than security enforcement.
Methodology — deep read
Threat Model & Assumptions: The adversary is implicitly the untrusted or noisy bug report submitter whose reports may be invalid for various root causes (e.g., misunderstanding, environment issues, external dependency failures). The system assumes access to the bug report textual data and prior labeled examples but does not consider adversarial manipulation or evasion attacks. The goal is to accurately subclassify invalid reports to root causes and generate no-code fixes.
Data: The primary data source is the GitHub repository of the Brave browser, selected for popularity (20,000+ stars), volume (40,000+ issues), and explicit invalid bug report labeling. The full dataset extracted consisted of 38,789 closed bug reports as of January 2026, with 8,289 labeled invalid based on project labels. From these, certain labels such as duplicates, stale reports, and no-milestone were filtered out to create a high-quality manually curated benchmark specifically relabeled with the proposed standardized root cause taxonomy in Table II. This benchmark serves as gold-standard ground truth for invalid subclasses and aligned no-code fixes.
Architecture / Algorithms: The IssueSupport framework serves as the core system. It performs invalid subclassification and no-code fix generation through several experimental configurations: vanilla LLM prompting without external context, Retrieval Augmented Generation (RAG) leveraging a vector store of developer wiki pages and similar past invalid bug reports retrieved by dense vector search to provide augmented input context, and agentic web search, which integrates WebThinker—a large reasoning model that interacts autonomously with live web data using a Think-Search-and-Draft architecture to fill knowledge gaps interactively. LLMs tested include proprietary models and open-source alternatives. Classification is performed by prompting LLMs to output one of seven subclass labels. No-code fix generation is done by prompting LLMs (with or without subclass prior information) to produce natural language actionable instructions or explanations.
Training Regime: The study primarily uses zero-shot or few-shot prompting techniques with pretrained LLMs; no traditional LLM fine-tuning or supervised training is reported. The RAG index is constructed over static external knowledge documents. Agentic search uses the WebThinker framework integrated with an LLM backbone capable of chaining thoughts and querying the internet dynamically. Details on epoch counts or batch sizes are not applicable since models are not trained from scratch.
Evaluation Protocol: Invalid subclassification quality is measured using weighted F1-score comparing predicted subclass labels against manual ground truth. No-code fix generation quality is evaluated by: (a) BERTScore to measure semantic similarity between generated fixes and ground truth, and (b) Judge LLM success rate, an automated evaluation using instruction-following judge LLM prompts to assess fix functional correctness based on human-annotated standards. The evaluation includes per-subclass performance analysis and overall system comparisons between vanilla LLM, RAG, and agentic web search configurations. Ablation studies measure no-code fix generation with and without subclass prior information to quantify benefit.
Reproducibility: The authors have released the benchmark dataset curated from the Brave browser repository including invalid bug reports, root cause subclass labels, and no-code fixes. The paper references GitHub for the data source and code artifacts, though specific links or trained LLM checkpoints are not detailed. The reliance on proprietary LLMs and the agentic web search framework may limit full reproduction. However, methodology is clearly described for replication with similar large language models and retrieval pipelines.
Concrete example: For subclassification, a bug report stating "Tabs aren’t visible or clickable after going fullscreen" is classified as Faulty Configuration, matched by the curated label. Using RAG, the system retrieves developer wiki pages describing configuration options and environment setup. The LLM outputs an explanation and generates a no-code fix instructing to "Enable 'Always show toolbar in full screen' option," matching the manual fix. The Judge LLM evaluates the generated text for semantic adequacy and correctness, confirming a successful no-code fix generation.
Technical innovations
- A novel standardized taxonomy for root-cause-oriented invalid bug report subclassification into seven distinct subclasses based on literature synthesis and empirical analysis.
- An integrated multi-step automated framework (IssueSupport) combining invalid bug subclassification and no-code fix generation using vanilla LLMs, retrieval augmented generation, and agentic web search.
- Creation of a curated high-quality benchmark dataset with manual relabeling of invalid bug reports from a large-scale real-world repository (Brave browser) aligned with root cause subclasses and no-code fixes.
- Application of agentic web search (WebThinker) for dynamic, multi-step web retrieval to improve no-code fix generation grounded in live external knowledge beyond static corpora.
Datasets
- Brave Browser Invalid Bug Reports Benchmark — 8,289 invalid bug reports — curated from Brave browser GitHub repository with manual subclass labels and no-code fixes
Baselines vs proposed
- Vanilla LLMs subclassification weighted F1 = 0.65 vs RAG subclassification weighted F1 = 0.66
- Agentic web search subclassification weighted F1 = 0.64 vs RAG 0.66
- Agentic web search no-code fix generation Judge LLM success rate = 68.9% vs RAG 64.4% vs vanilla LLM 64.9%
- Subclass-level subclassification F1: Non-reproducibility = 0.85, Feature Request = 0.79, Question = 0.79, Wrong Version = 0.00–0.29
- Subclass-level no-code fix success rate peaks: Working as Designed = 87.4%, Question = 72.2%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.17561.
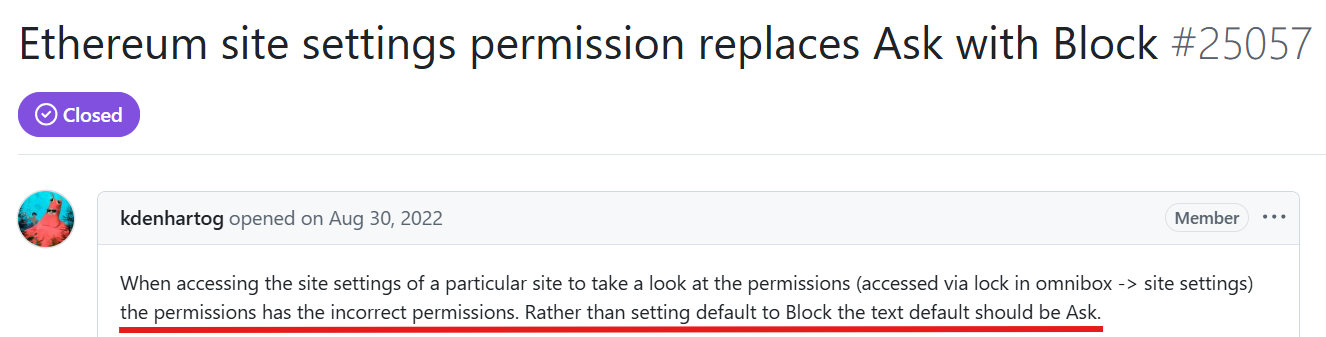
Fig 1: Invalid Bug Report Examples with Different Root
Fig 2 (page 2).

Fig 3 (page 2).

Fig 2: Overview of Evaluation Benchmark Curation Workflow

Fig 5 (page 7).

Fig 6 (page 7).

Fig 7 (page 7).

Fig 8 (page 7).
Limitations
- The Wrong Version subclass remains challenging to classify reliably, scoring between 0.00 and 0.29 weighted F1, indicating current methods struggle with this subclass.
- The benchmark focuses exclusively on invalid bug reports from a single repository (Brave browser), which may limit generalizability to other projects or domains.
- Evaluation depends largely on automatic metrics and judge LLM assessments for no-code fix quality, which might not fully capture user usefulness or correctness without human-in-the-loop validation.
- The study does not consider adversarially crafted bug reports or robustness under deliberate obfuscation or misinformation.
- No fine-tuning of LLMs reported; performance might improve with supervised training on subclassification or fix generation tasks.
- Agentic web search relies on availability and quality of live web information, which may introduce variability or reliance on external factors.
Open questions / follow-ons
- How can the classification performance on the challenging Wrong Version subclass be improved, possibly through enhanced retrieval or additional external data?
- Can supervised fine-tuning of LLMs with the curated benchmark data improve subclassification and no-code fix generation accuracy over zero- or few-shot prompting?
- How would human-in-the-loop evaluation and end-user feedback impact the quality and adoption of automated no-code fix suggestions in real-world customer support workflows?
- What are the effects of domain adaptation or cross-project transfer learning for invalid bug report subclassification and fix generation across diverse software products?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this research is relevant as it demonstrates advanced root-cause classification and automated response generation workflows using large language models enhanced with retrieval and agentic web search. While not directly related to CAPTCHA, the methodology of subclassification of user-generated reports and generation of context-specific natural language resolutions parallels the challenge of automatically interpreting and guiding human users through complex interactive workflows. The integration of live web search by an agentic LLM to ground output in external data is an especially noteworthy approach for dynamic, real-time response generation. Additionally, the benchmark and evaluation framework contribute best practices for assessing subclass-level classification and natural language generation quality, which could inspire similar evaluation standards in bot-detection or challenge-response systems. Practitioners might consider adapting subclassification plus no-code fix generation pipelines to triage suspicious user interactions or provide actionable hints in automated defense systems.
Cite
@article{arxiv2605_17561,
title={ Automated Root-Cause Subclassification and No-Code Fix Generation for Invalid Bug Reports },
author={ Mahmut Furkan Gon and Emre Dinc and Tevfik Emre Sungur and Eray Tuzun },
journal={arXiv preprint arXiv:2605.17561},
year={ 2026 },
url={https://arxiv.org/abs/2605.17561}
}