
Who, Why, and How: Disentangling the Effects of Moderation Source, Context, and Language on Post-Removal Behavior
Source: arXiv:2605.16204 · Published 2026-05-15 · By Siyi Zhou, Lindsay Young, Marlon Twyman, Emilio Ferrara
TL;DR
This study investigates how the source of content moderation (automated bots, individual human moderators, or collective modteam accounts), the type of content violation, and the linguistic style of removal explanations together influence user behavior following content removal on Reddit. Using a massive dataset of nearly 12 million moderation actions involving over 9 million users across 61,000 subreddits from 2021 to 2025, the authors apply probabilistic behavioral classification and statistical modeling to disentangle these complex interactions. Contrary to common assumptions, bot moderation leads to the highest user compliance and lowest self-censorship, while modteam moderation induces the strongest self-censorship — suggesting institutional and depersonalized authority drives behavioral withdrawal.
The analysis reveals violation severity critically moderates these effects: linguistic styles that encourage compliance in routine cases (e.g., detailed explanations and personal address) may backfire with serious violations, where prosocial framing and emotional emphasis are more effective. Of hundreds of linguistic interactions tested, only 33 survive rigorous multiple testing correction, mainly involving harmful or illegal content. Overall, the work advances the HAII-TIME framework by integrating violation salience as a key moderator of agency cue processing and provides empirical grounding for adaptive, context-specific moderation message design that balances platform governance goals with user engagement.
Key findings
- Bot moderation produces the highest compliance and lowest self-censorship compared to modteam and personal human moderation (e.g., mean self-censorship modteam vs bot difference = 0.085, p < .0001).
- Modteam moderation yields the strongest self-censorship effects and lowest compliance across all violation types.
- Violation severity strongly influences behavior: harmful/illegal content moderation leads to highest self-censorship (M=0.145), highest resistance (M=0.097), and lowest compliance (M=0.765), significantly different from all other categories (p < .0001).
- Linguistic strategies effective in routine contexts (elaborated explanations, community-scale appeals, direct personal address) can backfire under high-severity violations; prosocial and emotionally emphatic messages become more effective with serious violations.
- Of 480 linguistic interaction tests examined, only 33 survive false discovery rate correction, concentrated on harmful/illegal and formatting violations.
- Behavioral resistance post-moderation is low overall (median resistance near zero), with significant variation driven by a small subset of users particularly for harmful content.
- Probabilistic behavioral classification via sigmoid mappings captures self-censorship, resistance, and compliance on a continuum rather than binary categories.
- User behavioral adjustments differ systematically by moderator source and violation context, supporting a nuanced theory of distributed agency in content moderation.
Threat model
n/a — The paper does not focus on adversarial threat models or security attacks but studies user behavioral responses to content moderation as a platform governance mechanism.
Methodology — deep read
Threat Model & Assumptions: The study conceptualizes users being moderated on Reddit as the target population, with moderators as agents of platform governance. Moderators include automated bots, individual humans, and collective modteam accounts. The adversary model is not adversarial hacking but concerns users responding strategically or reactively to moderation interventions. The threat is unintended behavioral withdrawal (self-censorship), resistance (continued violations), or compliance following content removal. The assumption is that users perceive moderator identity (source) and message style as social/agency cues influencing post-moderation behavior.
Data: The dataset comprises 11,795,036 moderation events linked to 9,285,410 unique users across 61,261 subreddits on Reddit between January 2021 and December 2025. Data were collected by identifying moderator comments explicitly describing content removals referencing users via regex matching usernames (/u or /u/). Moderation events were categorized into three moderator sources by username heuristics: bot accounts (usernames containing 'bot' or 'auto'), modteam collective accounts (usernames containing 'modteam'), and personal human accounts (no automation signals). Removal explanations were extracted and verified via manual annotation. Violation reasons were labeled via iterative keyword snowballing and manual thematic categorization covering various rule violations.
Algorithm & Architecture: The core analytic framework uses probabilistic behavioral classification. Behavioral outcomes (self-censorship, resistance, compliance) are modeled via sigmoid functions on behavioral metrics to assign continuous probability scores instead of binary labels, avoiding threshold sensitivity. Self-censorship is operationalized via log ratio change in posting frequency before vs. after moderation, with decision boundary set at the 5th percentile of monthly log-ratio to indicate extreme posting reduction. Resistance is defined as persistently elevated re-moderation rate post first removal above the 95th percentile. Compliance is defined as absence of both self-censorship and resistance probabilities. Linguistic features from removal explanations are extracted using LIWC (Linguistic Inquiry and Word Count) and reduced by Principal Component Analysis (PCA) to address dimensionality and collinearity.
Training Regime: Not applicable in the sense of model training as this is an observational study. However, statistical analyses include one-way ANOVA for behavioral differences across moderator types, Kruskal-Wallis tests for violation category effects, and ordinary least squares (OLS) regressions incorporating PCA-derived linguistic feature components and their interactions with source and context. False discovery rate corrections were applied to control for multiple comparisons.
Evaluation Protocol: Statistical significance of group differences was evaluated via ANOVA with post-hoc corrections and Kruskal-Wallis tests. Regression models were used to estimate the association of linguistic factors with behavioral outcomes. Behavioral probability distributions and interaction effects were interpreted considering effect sizes and p-values, referencing figures such as Table 1 and Figure 2 for behavioral patterns across moderator types and violation categories. The large sample size enabled detection of statistically significant but substantively small differences, especially in resistance. Cross-validation was not applicable as this is descriptive analysis of naturalistic data.
Reproducibility: The paper does not specify code or dataset public release; the Reddit data may be accessible via public Reddit APIs but labeling heuristics and annotations may not be released. The moderator classification relies on heuristic username rules, acknowledged to potentially incur classification noise. Thus, exact reproducibility may be limited without access to annotated data and code. The probabilistic classification methods and statistical models are fully described and hence replicable in principle given similar data.
Concrete Example: For a user whose content was removed for a harmful content violation by a modteam account: the user’s posting frequency changes are measured via log ratio before and after removal; re-moderation rate is recorded; the removal explanation text is analyzed with LIWC and projected onto PCA components; behavioral probabilities (self-censorship, resistance, compliance) are computed via sigmoid functions; these are aggregated across all users and moderation events to detect statistically significant trends and interaction effects by moderator source and violation severity. This comprehensive approach enables nuanced interpretation of how moderator identity, violation type, and message language jointly shape post-moderation behavior.
Technical innovations
- Application of Human–AI Interaction Theory of Interactive Media Effects (HAII-TIME) to model content moderation as distributed agency communication shaping behavioral adaptation.
- Use of probabilistic behavioral classification via sigmoid mapping to model self-censorship, resistance, and compliance as continuous rather than binary outcomes.
- Decomposition of moderator source effects into bot, modteam, and personal moderators distinguished by heuristic username classification to capture differing agency signals.
- Integration of violation severity as a contextual moderator influencing the effectiveness and risks of different linguistic strategies in moderation explanations.
- Employment of PCA-reduced LIWC linguistic features to robustly analyze high-dimensional explanatory text style effects and their interactions with moderator source and violation context.
Datasets
- Reddit moderation events — 11,795,036 events involving 9,285,410 users across 61,261 subreddits — collected from public Reddit platform data Jan 2021 to Dec 2025
Baselines vs proposed
- Bots vs Modteam: self-censorship mean difference = -0.085 (p < .0001), compliance higher by 0.078 for bots
- Bots vs Personal accounts: self-censorship mean difference = -0.072 (p < .0001), compliance higher by 0.045 for bots
- Modteam vs Personal accounts: self-censorship difference = +0.013 (p < .0001), compliance differences negligible
- Violation categories: harmful/illegal content self-censorship mean = 0.145 vs formatting violations mean = 0.081 (p < .0001), compliance inversely 0.765 vs 0.878
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.16204.
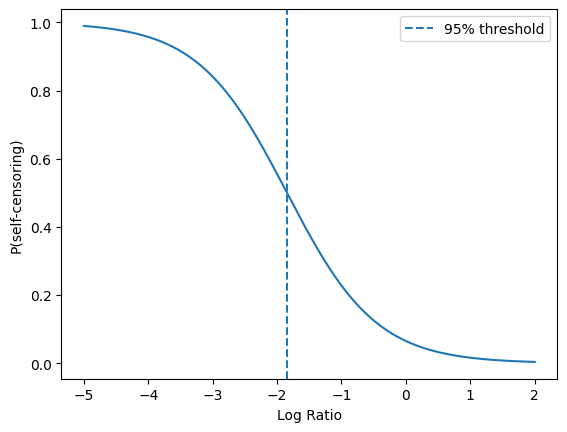
Fig 1: Sigmoid-based probabilistic classifiers for self-censorship, resistance, and compliance.
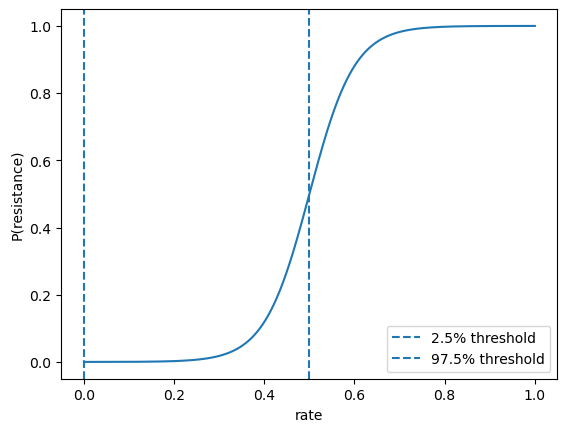
Fig 2: Mean probability of user behavior trajectory after moderated by different source for different
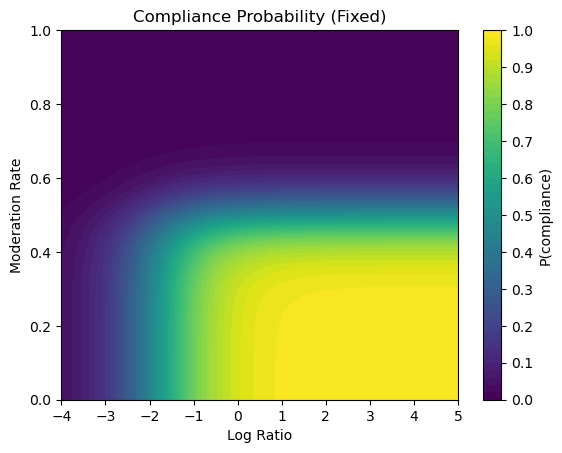
Fig 3 (page 7).
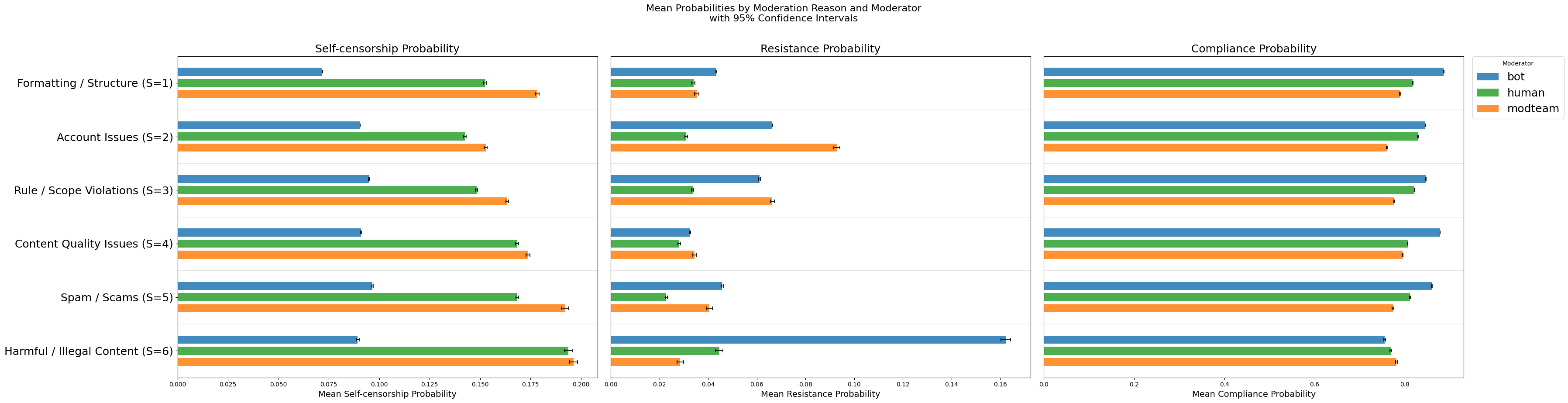
Fig 3: are paradoxically associated with greater subsequent rule-violating behavior. In contrast, Descriptive
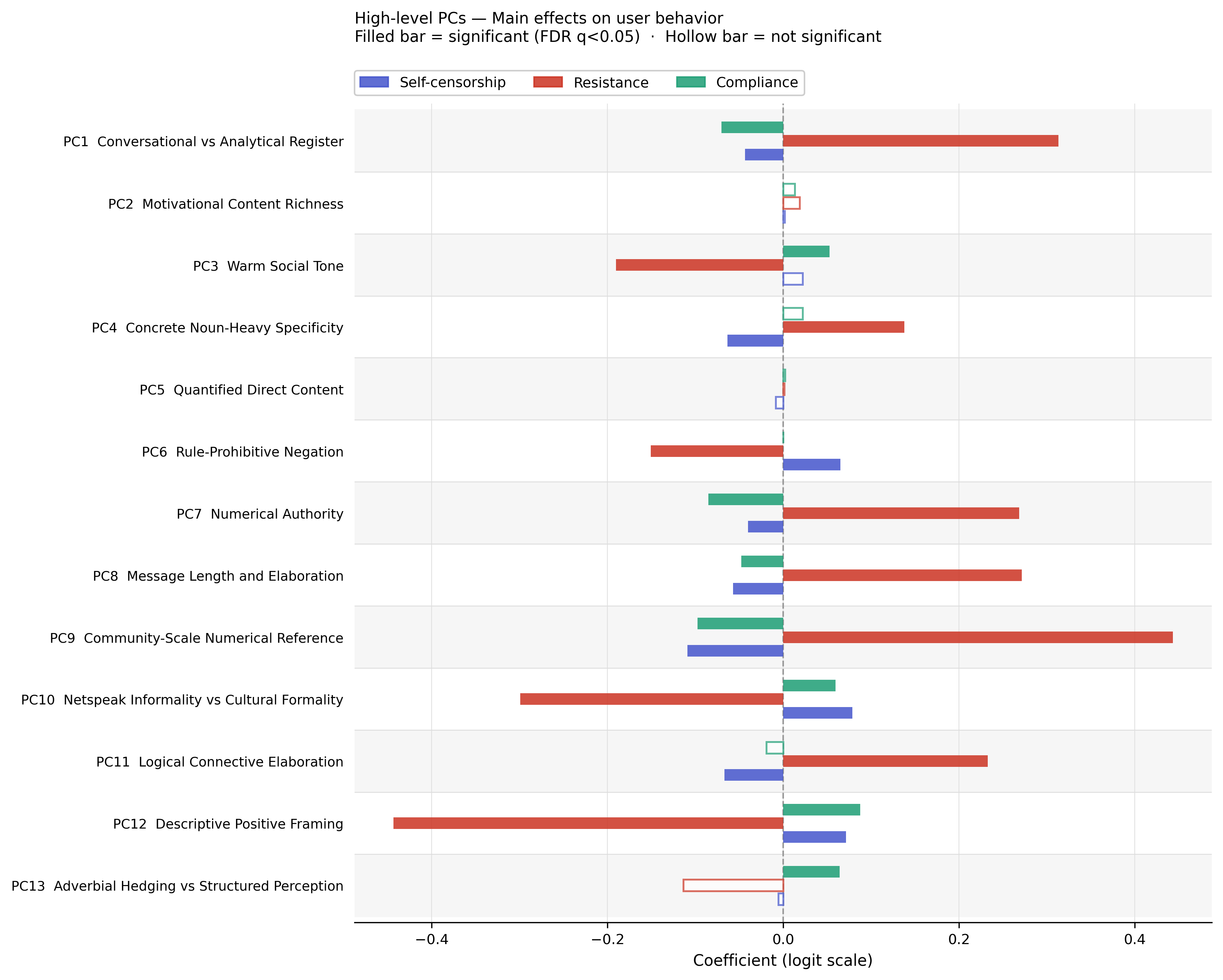
Fig 4: Taken together, these findings suggest that the linguistic style of moderation explanations has mean-
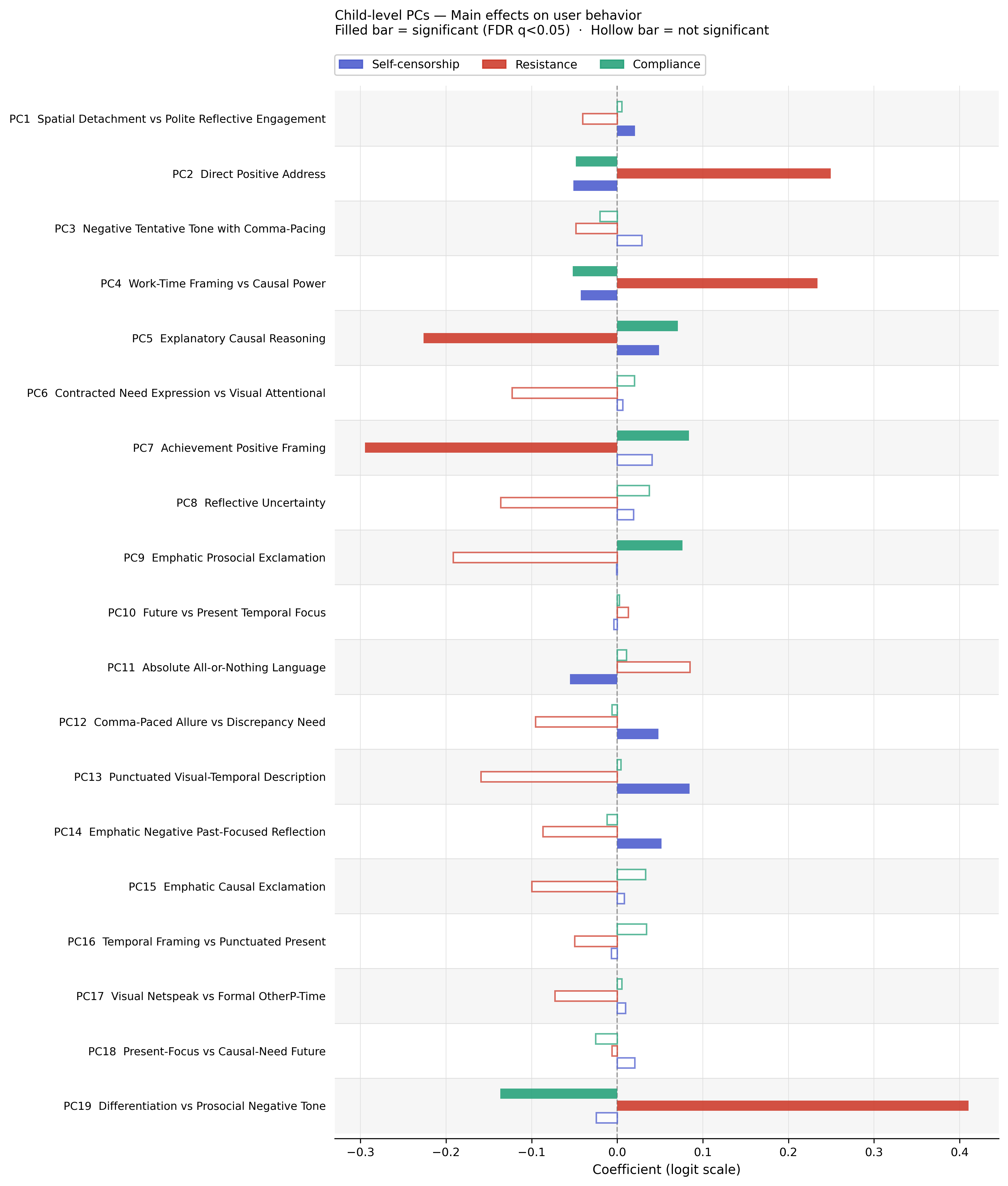
Fig 5: post-moderation behavioral trajectories. Figures 5 and 6 display the effective slopes of high-level (HL)
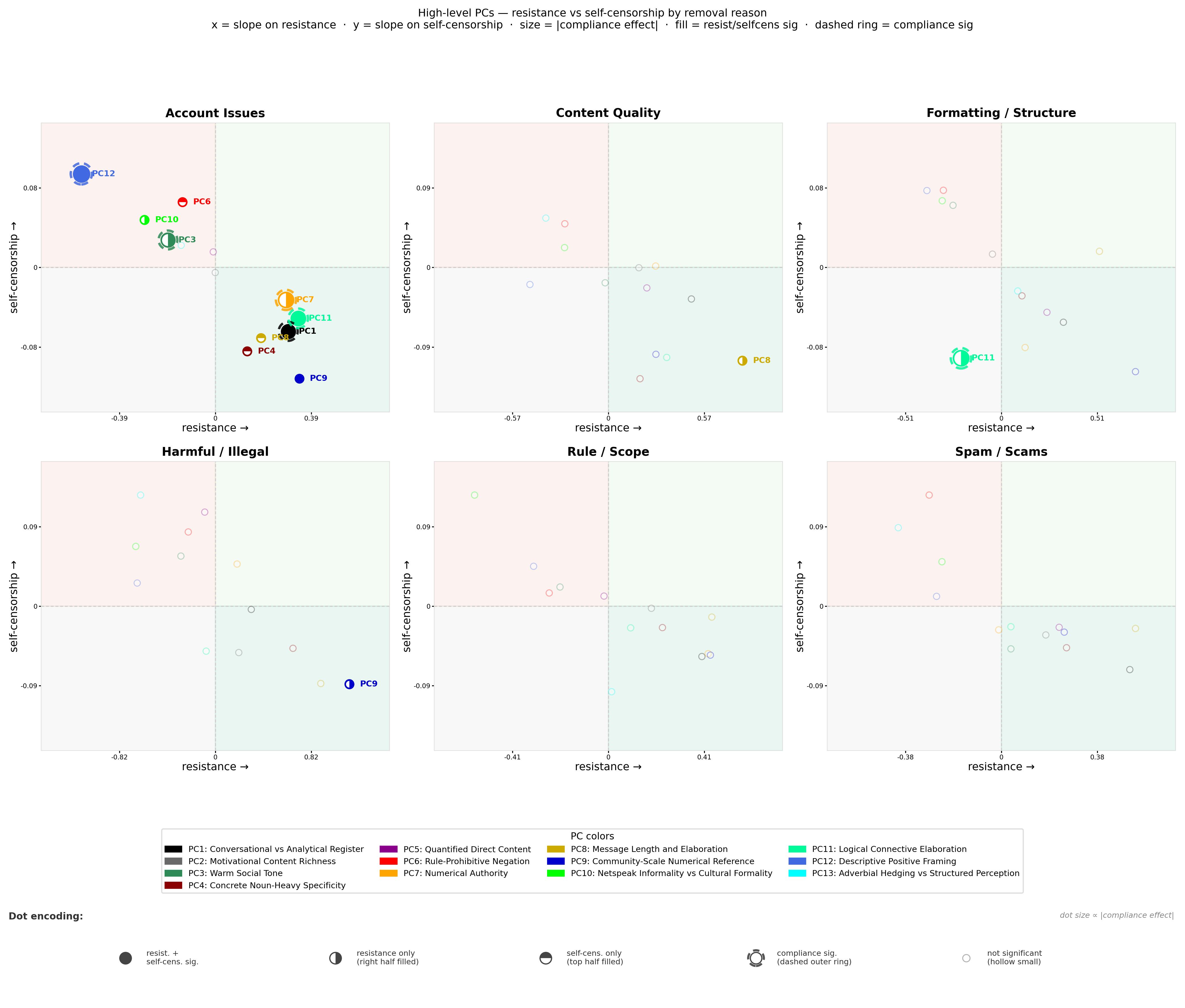
Fig 6: In contrast, Logical Connective Elaboration (HL-PC11) reveals a theoretically important sign rever-
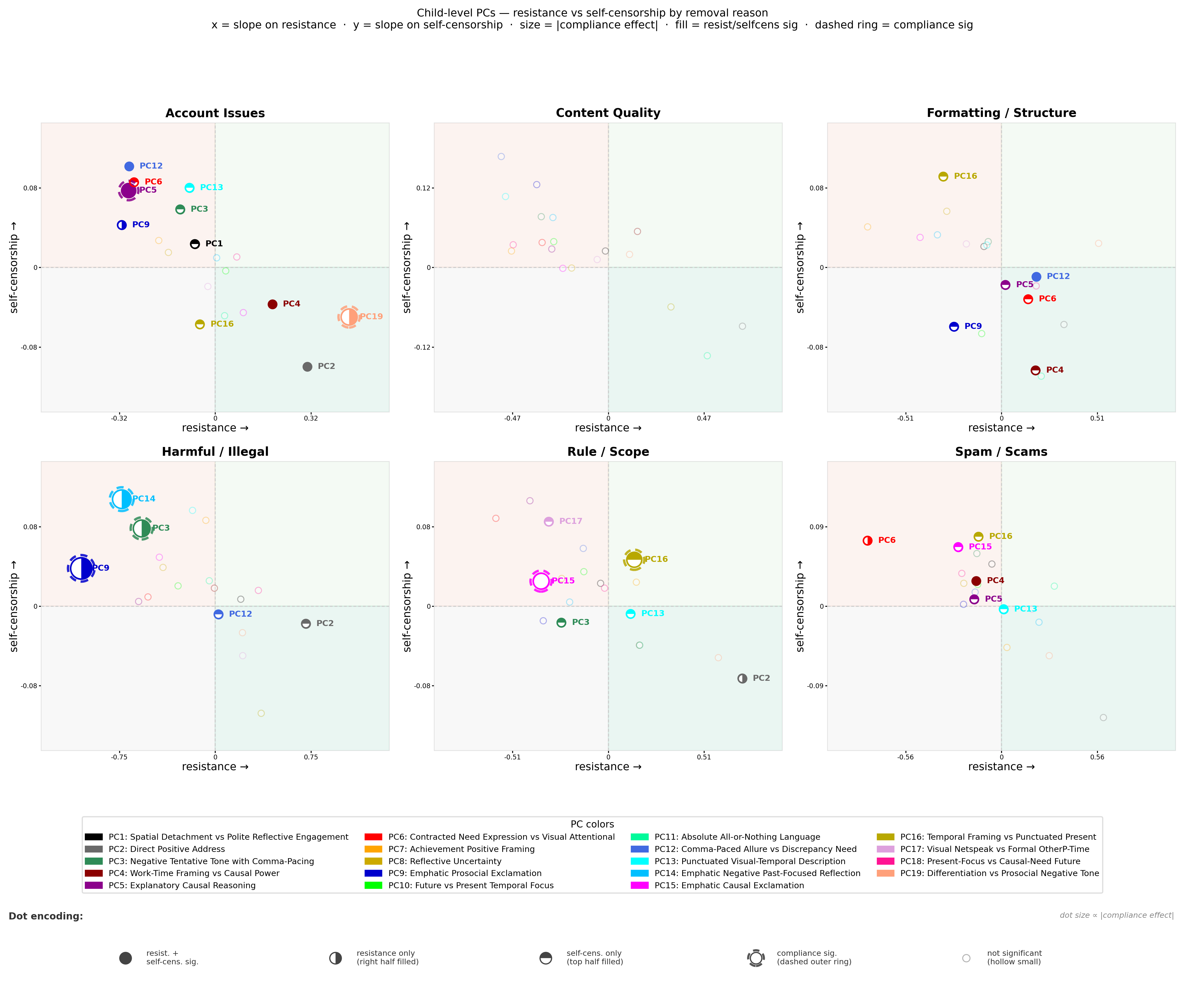
Fig 8 (page 13).
Limitations
- Moderator source classification relies on username heuristics which may misclassify bots or humans, potentially biasing results.
- Observational design restricts causal inference; unmeasured confounders could influence behavioral outcomes.
- Resistance observed is rare and skewed, with median near zero — statistical significance may reflect large sample sizes rather than substantive effect.
- Linguistic analysis focuses on LIWC features and PCA components, potentially missing nuanced or context-specific language patterns.
- No experimental manipulation or randomized controlled trials to confirm causality of linguistic strategy effects.
- Dataset limited to Reddit, which has unique moderation infrastructure, limiting generalizability to other platforms.
Open questions / follow-ons
- How do users’ internal perceptions of moderator agency (beyond heuristic proxies) mediate behavioral adaptation post-moderation?
- Can adaptive moderation messaging dynamically adjust linguistic style or source cues to optimize compliance while minimizing self-censorship?
- How do these findings generalize to other platforms with different moderation norms and user populations?
- What are the long-term effects of different moderation regimes (automated vs human) on community health and user retention?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper underlines the importance of considering how the source identity and linguistic framing of automated interventions influence genuine user behavioral compliance versus disengagement. Automated enforcement is not always perceived negatively; in fact, bot-based moderation elicits higher compliance and less self-censorship than human moderators, suggesting depersonalized, consistent rule enforcement signals may better sustain healthy engagement. This insight cautions against assuming human-like interaction cues inherently improve compliance. Captcha systems or bot defenses embedded in user interactions might similarly benefit from transparent, systematic, and neutral messaging rather than overt human agency signals if the goal is to reduce user friction without inducing withdrawal. Additionally, the role of contextual severity implies that adaptive messaging tailored to the offense or violation type may be necessary to balance enforcement with user experience—a consideration highly relevant for designing layered bot-detection or behavioral verification flows.
Cite
@article{arxiv2605_16204,
title={ Who, Why, and How: Disentangling the Effects of Moderation Source, Context, and Language on Post-Removal Behavior },
author={ Siyi Zhou and Lindsay Young and Marlon Twyman and Emilio Ferrara },
journal={arXiv preprint arXiv:2605.16204},
year={ 2026 },
url={https://arxiv.org/abs/2605.16204}
}