
TTP: A Hardware-Efficient Design for Precise Prefetching in Ray Tracing
Source: arXiv:2605.16253 · Published 2026-05-15 · By Yavuz Selim Tozlu, Anshul Naithani, Huiyang Zhou
TL;DR
This paper addresses the major memory latency bottleneck in GPU ray tracing workloads, specifically during Bounding Volume Hierarchy (BVH) traversal. The authors propose a novel hardware prefetcher called Tree Traversal Prefetcher (TTP) that leverages the per-thread traversal stacks already present in hardware ray tracing units to generate highly accurate prefetches. By monitoring the stack push/pop behavior during depth-first search (DFS) traversal of the BVH tree, TTP triggers prefetches when a sequence of node pops indicates upward traversal, where the addresses of the next nodes to be accessed are already available and highly predictable. This avoids speculative address prediction and wasted bandwidth. Evaluation on the cycle-level simulator Vulkan-sim 2.0 shows that TTP achieves an average 1.48x speedup (up to 1.89x) over the baseline with minimal hardware overhead. TTP achieves an average L1 prefetch accuracy of 98.92% and coverage of 31.54%, closely matching the observed speedups. The prefetcher outperforms prior treelet-based prefetchers while requiring simpler hardware changes. TTP also supports breadth-first search (BFS) traversal with a different prefetching strategy. Results show consistent reductions in L1 and L2 read misses, modest power increase (1.35x), and 8.7% overall energy savings due to reduced runtime.
Key findings
- TTP achieves a geometric mean speedup of 1.48x over baseline ray tracing, with up to 1.89x speedup on certain scenes (Figure 10).
- Average L1 cache prefetch accuracy is 98.92%, indicating most prefetched blocks are actually used.
- Coverage—the ratio of L1 miss reduction over baseline L1 misses—is 31.54% on average (Figure 14).
- L1 and L2 RT read misses reduce by 28.28% and 40.01%, respectively, across scenes (Figure 13).
- TTP introduces an 18.22% average increase in DRAM bandwidth utilization but no increase in total memory data volume (Figure 2).
- Energy consumption drops by 8.7% on average compared to baseline due to reduced execution time (Figure 10).
- Compared to the Treelet prefetcher, TTP achieves higher speedups with simpler hardware and no custom BVH layout changes (Section V).
- Perfect upward traversal cache hits (assuming ideal prefetching) would yield up to 1.79x speedup, close to TTP’s results (Figure 11).
Methodology — deep read
Threat Model & Assumptions: The adversary is not applicable here as this is a hardware acceleration and prefetching design for ray tracing workloads. The focus is on memory latency challenges caused by unpredictable BVH traversal patterns during ray tracing on GPUs with specialized RT units. The prefetcher assumes access to the hardware traversal stacks maintained per thread within the RT units and that traversal follows depth-first search (DFS) or breadth-first search (BFS) over large BVH trees representing 3D scenes.
Data: They use 16 benchmark scenes from Lumibench, with tree sizes ranging from 0.2MB to 1.7GB and varying depths of the BVH tree. Simulations run mostly at 128x128 resolution path-tracing; one large scene (park) ran at 64x64 due to runtime constraints. Scenes include both procedural geometry and triangle meshes, representative of real ray tracing workloads.
Architecture / Algorithm: The core idea is the Tree Traversal Prefetcher (TTP) which instruments the existing per-thread traversal stack in the RT unit. For DFS traversal, TTP tracks sequences of consecutive pops from the stack, indicating upward traversal. It uses a 2-bit finite state machine per thread to determine how many next nodes in the stack (top-k nodes) to prefetch, increasing prefetch counts with longer pop streaks (up to 16). Prefetch addresses come directly from the stack entries, avoiding address prediction. For BFS traversal, TTP prefetches N upcoming nodes from the traversal queue.
This design requires minimal hardware: a 2-bit FSM per thread and pointers/indexes to read traversal stack entries. Prefetch requests are issued with lower priority than demand loads, and large nodes are split into 32B chunks for cache line granularity.
Training Regime: Not applicable as this is a hardware design evaluated via cycle-level simulation.
Evaluation Protocol: They extended Vulkan-sim 2.0 GPU simulator to model RT units with and without TTP. Baseline is default RT unit with no prefetching. Metrics are simulation cycles (speedup), cache miss rates (MPKI), power and energy estimated via integrated GPUWattch framework. They run ablations on prefetch aggressiveness, cache sizes (32KB, 64KB, 128KB), arbitration policies, BFS vs DFS traversal, and compared against the state-of-the-art Treelet prefetcher.
Reproducibility: Code is released on GitHub at github.com/yavuz650/vulkan-sim, including TTP implementation. The benchmark scenes come from Lumibench. Their implementation of Treelet prefetcher is cloned from the publicly available repository. Simulation configurations are detailed in Table III.
Concrete Example: In DFS traversal, a series of pushes corresponds to downward traversal, which is difficult to predict. But when the traversal changes to popping nodes consecutively (going back up the tree), the addresses of the next nodes to be read are already on the stack. TTP detects this pop streak and prefetches these nodes proactively. For instance, if the thread pops node P then immediately pops node O, TTP prefetches node O when node P is popped, reducing memory latency for that access. This leads to high prefetch accuracy (>98%) and substantial reduction in execution stalls waiting for memory.
Technical innovations
- Leverages the per-thread traversal stack in RT units to generate precise prefetch addresses without speculative prediction, exploiting the traversal stack’s push/pop behavior.
- Introduces a lightweight per-thread 2-bit finite state machine to detect upward traversal (pop streaks) and dynamically adjust prefetch aggressiveness up to 16 lookahead nodes.
- Supports both DFS and BFS BVH traversal modes with tailored prefetching strategies, unlike prior treelet-based prefetchers requiring custom BVH layouts.
- Requires minimal hardware additions integrated directly into the existing RT unit’s warp buffer and traversal stack mechanism, yielding almost no hardware overhead.
Datasets
- Lumibench — 16 scenes ranging from 0.2MB to 1.7GB BVH tree size — public benchmark for ray tracing
Baselines vs proposed
- Baseline (no prefetcher): normalized speedup = 1.0 vs TTP: 1.48 geometric mean speedup (up to 1.89x peak)
- Treelet prefetcher [19]: speedup less than TTP (exact values not specified, TTP outperforms Treelet consistently)
- Baseline L1 RT read misses: MPKI = 100% baseline vs TTP: 28.28% reduction
- Baseline L2 RT read misses: MPKI = 100% baseline vs TTP: 40.01% reduction
- Baseline energy consumption normalized to 1.0 vs TTP: 0.91 (8.7% energy savings)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.16253.
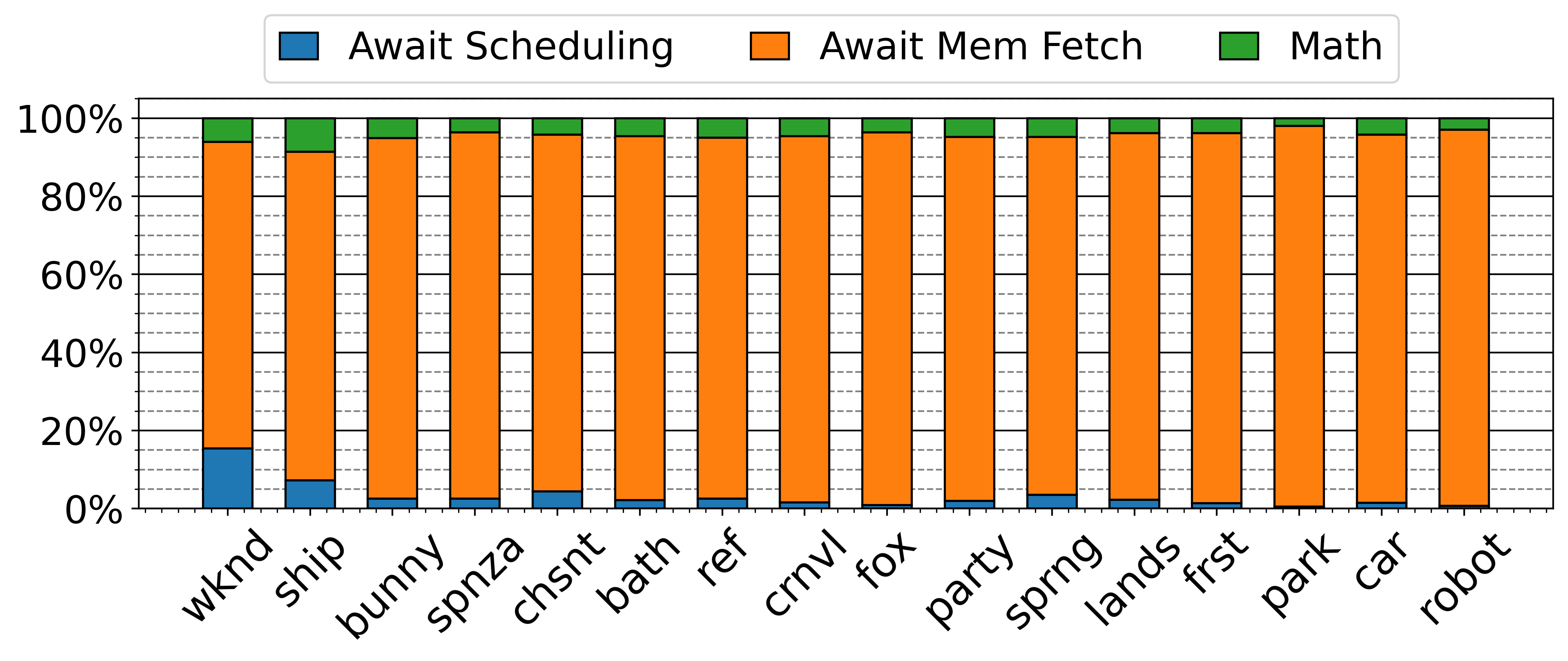
Fig 1: Thread status distribution in an RT unit. Threads may be waiting for
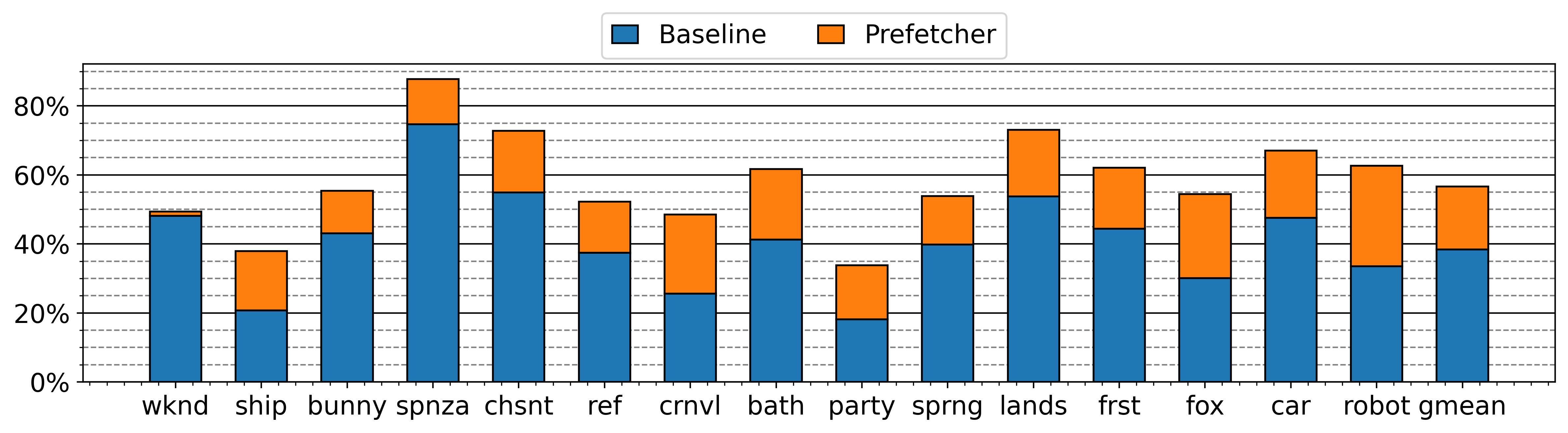
Fig 2: DRAM activity with and without (i.e., baseline) TTP.
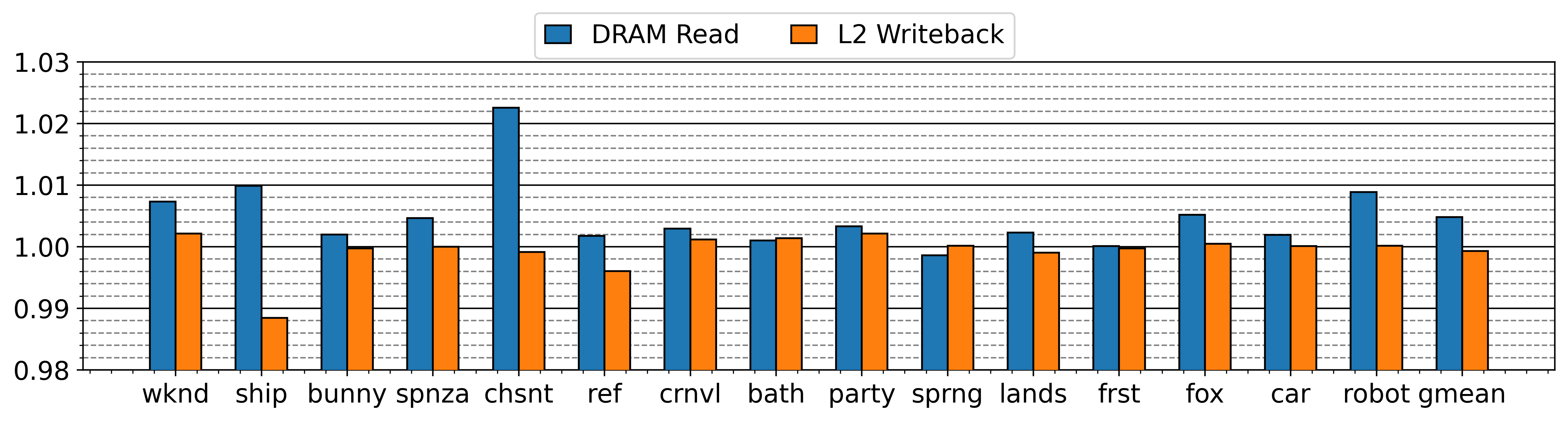
Fig 3: Simplified BVH structure for Stanford Bunny. The green arrow
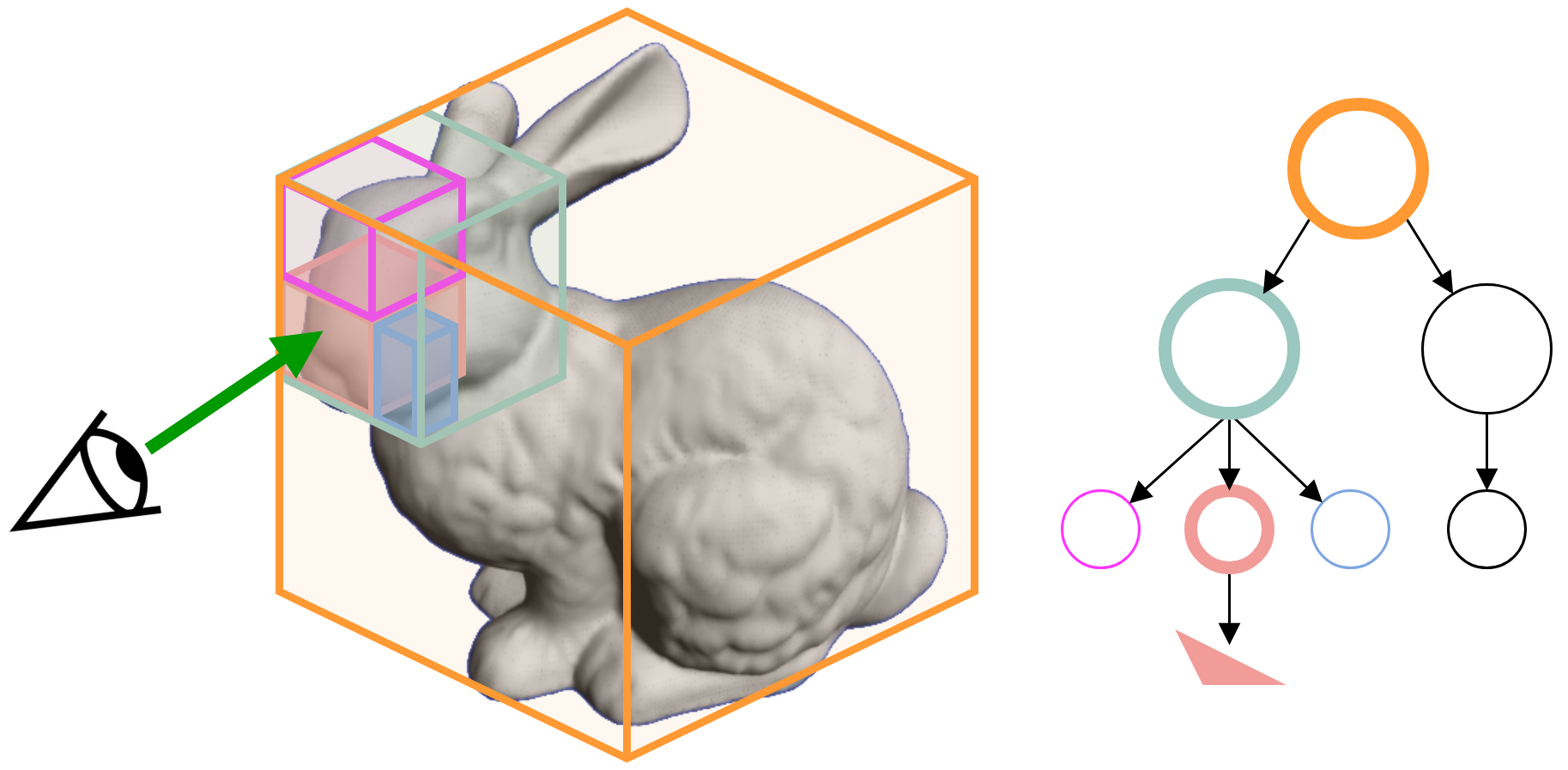
Fig 4: Diagram of the GPU model used in this study. Purple blocks indicate the modified components. Redrawn from [39].
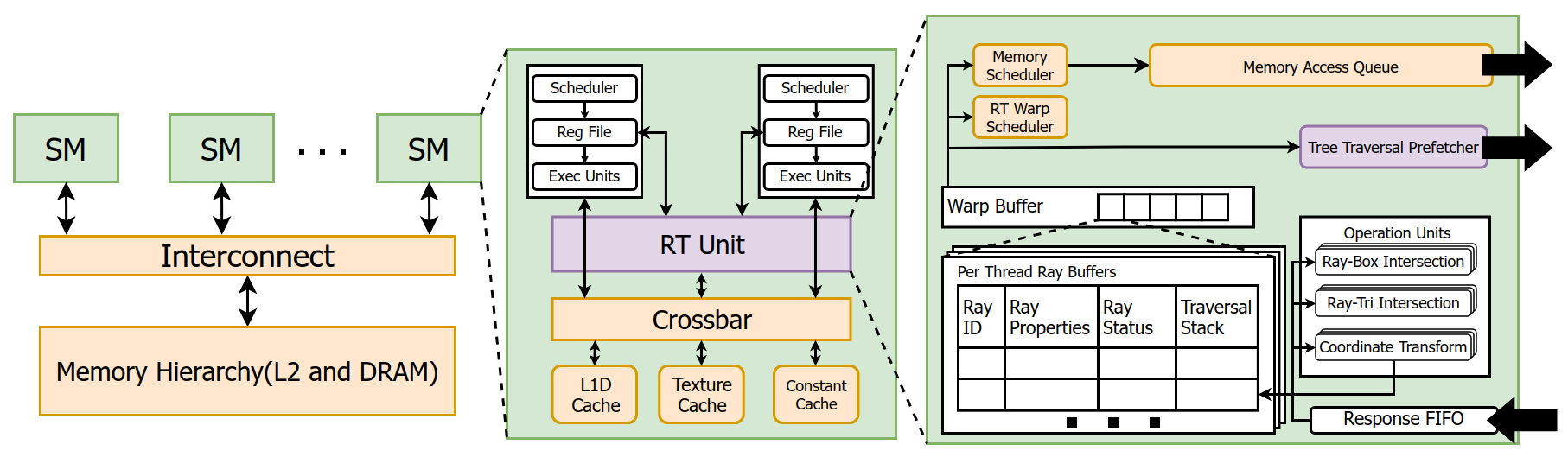
Fig 5: Example DFS BVH traversal and the corresponding traversal stack.
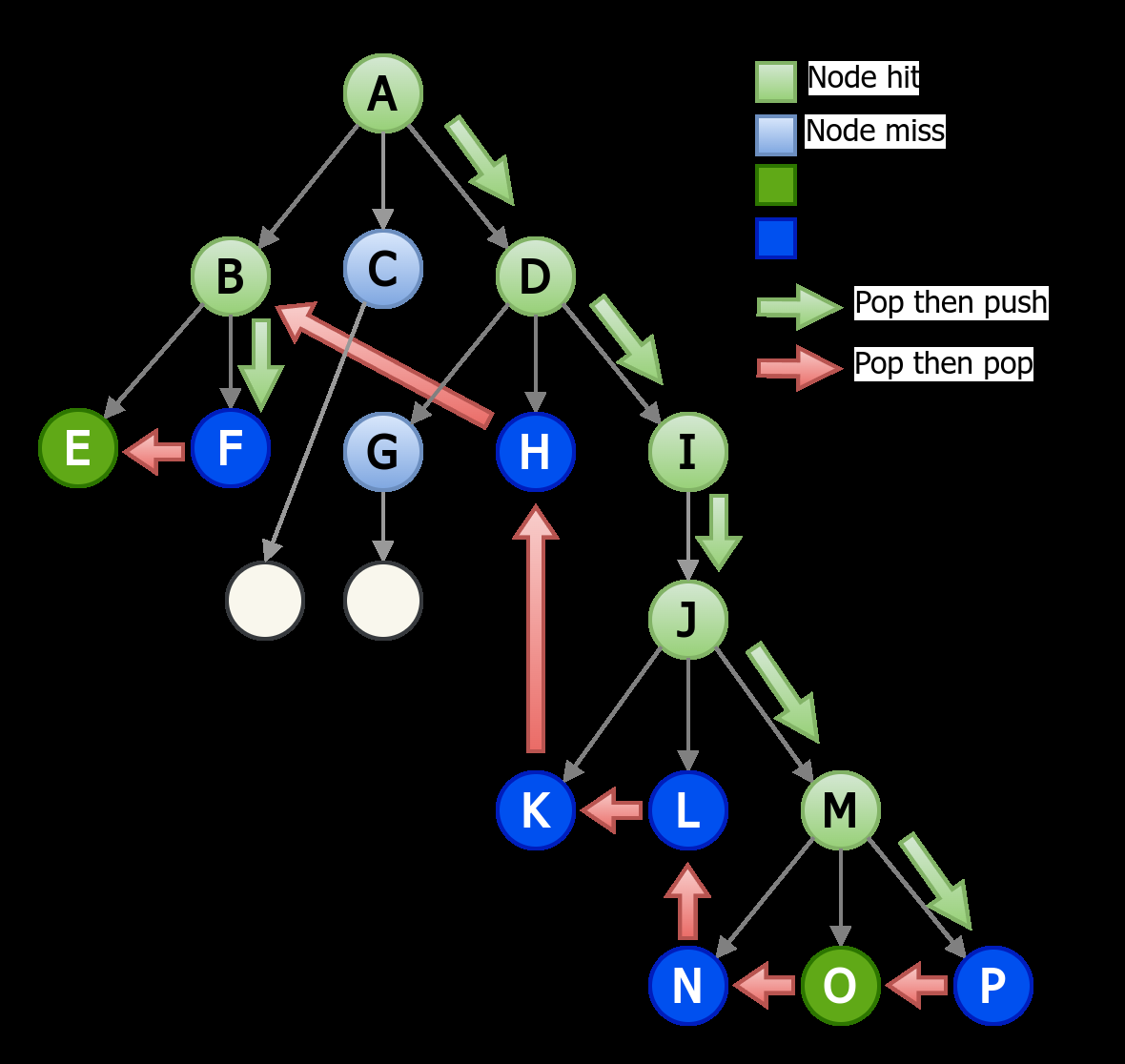
Fig 6: Analysis of pop streaks.
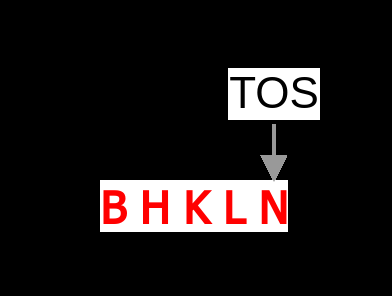
Fig 7: Percentage of RT read misses where the node was in the traversal
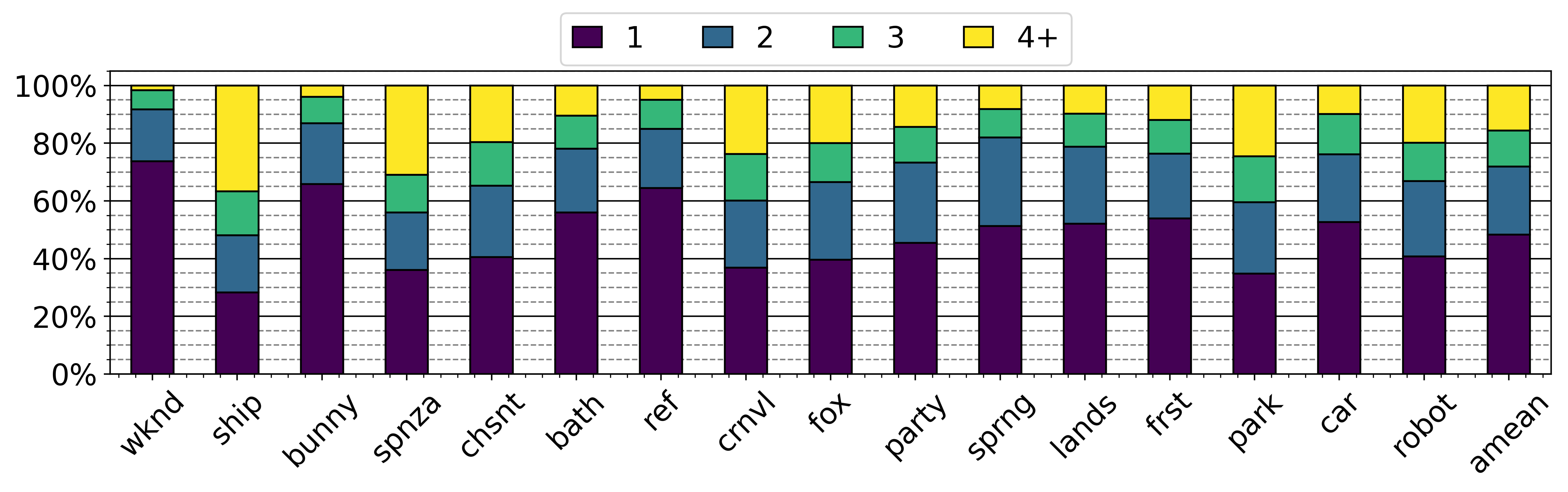
Fig 8: State machine that generates prefetches.
Limitations
- Evaluation performed in simulation with Vulkan-sim; no physical hardware prototype to confirm power/area overhead.
- Park scene benchmark only simulated at reduced 64x64 resolution due to runtime limits, possibly underrepresenting performance on very large scenes.
- No evaluation under adversarial or stress conditions such as dynamically changing scenes or very divergent traversal patterns.
- Limited sensitivity analysis on prefetch aggressiveness parameters; higher aggressiveness might increase bandwidth and energy costs.
- Does not address integration with other performance optimizations such as BVH compression or traversal algorithm variants beyond DFS/BFS.
- Effectiveness may decrease if traversal stack behavior diverges from assumptions (e.g., irregular or non-standard traversal orders).
Open questions / follow-ons
- How does TTP perform on dynamic scenes with frequently updated BVH trees, where traversal stacks may change rapidly?
- Can TTP be combined with other memory optimizations like compressed BVH layouts or cache replacement policies for further gains?
- What is the impact of TTP on energy and power in real hardware, and what are the tradeoffs between prefetch distance and bandwidth?
- Can the prefetching principle extend to other hierarchical data structures and non-ray tracing GPU workloads with irregular memory access?
Why it matters for bot defense
While this paper focuses on GPU hardware for accelerating ray tracing, its detailed analysis of memory latency bottlenecks and precise prefetching based on traversal stack behavior offers valuable insight for bot-defense practitioners dealing with cache and memory performance issues. Similar to BVH traversal, some graph or tree-based algorithms used in bot detection could benefit from hardware or software prefetch strategies that leverage predictable traversal patterns to hide memory latency. The design also highlights the benefits of lightweight hardware state machines working in tandem with existing data structures to improve cache utilization with minimal overhead. However, direct applicability to CAPTCHA systems is limited as the workload and architectural contexts differ. Nonetheless, the methodology of exploiting traversal trends to guide prefetching could inspire approaches to accelerate bot-detection systems reliant on hierarchical or graph-structured data.
Cite
@article{arxiv2605_16253,
title={ TTP: A Hardware-Efficient Design for Precise Prefetching in Ray Tracing },
author={ Yavuz Selim Tozlu and Anshul Naithani and Huiyang Zhou },
journal={arXiv preprint arXiv:2605.16253},
year={ 2026 },
url={https://arxiv.org/abs/2605.16253}
}