
SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?
Source: arXiv:2605.15777 · Published 2026-05-15 · By Kean Shi, Zihang Li, Tianyi Ma, Zengji Tu, Jialong Wu, Xinbo Xu et al.
TL;DR
This paper addresses the challenge of evaluating Computer-Using Agents (CUAs), which extend large language models (LLMs) beyond language reasoning to real-world interaction with complex graphical user interfaces (GUIs) and web applications. Existing benchmarks for CUAs rely on simplified, isolated, or short-horizon tasks that fail to reflect the long-horizon, multi-application, and domain-specific workflows commonly encountered in professional environments. To overcome these limitations, the authors introduce SaaS-Bench, a comprehensive benchmark grounded in 23 deployable open-source SaaS platforms from six professional domains, with 106 tasks that require long-horizon reasoning, multi-application coordination, and multimodal evidence integration.
SaaS-Bench tasks average over 100 interaction steps and are verified through weighted checkpoints using database state, string matches, and LLM-judged outputs, allowing measurement of both strict task completion and partial progress. Extensive evaluation of representative LLM-based CUAs shows low end-to-end completion rates under 4%, revealing key failure modes such as planning, state tracking, error recovery, and cross-application context maintenance. These results demonstrate that current agents are far from capable of reliably executing real-world professional workflows in complex SaaS environments, highlighting substantial gaps and providing a useful standard for future research.
Key findings
- SaaS-Bench includes 106 tasks spanning 23 real SaaS systems in six professional domains with an average task length exceeding 100 interaction steps.
- 93.4% of tasks involve coordination across two or more SaaS applications, with 50% involving three applications, emphasizing multi-app complexity.
- Even the strongest tested agent, Claude Opus 4.6, achieved only 43.2% overall checkpoint score and 1.9% resolved (full end-to-end) task completion.
- Other agents like GPT-5.4 High and Qwen 3.6 Plus scored lower, with resolved scores below 4% and checkpoint scores under 40%.
- Pass@3 evaluation improved scores by roughly 8 percentage points, indicating notable execution instability and error recovery challenges.
- Failure analysis showed Entity Missing (70.2%) was the dominant checkpoint failure mode, with additional failure modes including value mismatch and backend/API exceptions.
- Tasks involving more distinct applications or longer operation lengths exhibited significantly decreased agent success rates (down from ∼53% to under 20%).
- Checkpoint pass rates decline monotonically over the course of tasks, with late-stage checkpoints passing as low as ~13-14%, evidencing degraded long-horizon capability.
Threat model
The adversary model considers autonomous large language model-based agents attempting to interact with SaaS workflows purely through UI actions. Agents cannot bypass UI constraints via direct database queries, backend APIs, or file system access. They must operate under realistic SaaS UI conditions with dynamic states, multi-application coordination, and domain rules. This models the challenge of CUAs working under least-privilege browser-only environments without insider knowledge or privileged system access.
Methodology — deep read
The study is set in the threat model of evaluating autonomous Computer-Using Agents (CUAs) operating solely through browser UI interactions on real SaaS platforms. Agents cannot directly access databases, backend APIs, file systems, or verification tools and must rely on observable UI contents and actions such as clicking, typing, and navigation.
The benchmark environment comprises 23 deployable real open-source SaaS systems across six professional domains (Software Engineering, Business Operations, Healthcare, Team Collaboration, Agriculture, Media). Systems are dockerized for reproducible deployment with locked versions, seeded realistic data, and resettable initial states to avoid task contamination. Data population uses either LLM-generated realistic fake data or imported open-source datasets, guided by analysis of each SaaS's database schema and UI structure.
106 professional workflow tasks were created using a four-stage pipeline: starting with domain-specific occupational role task seeds; LLM-based iterative Builder-Challenger-Refiner synthesis of task templates and instantiations; expert static checks of task validity, professionalism, cross-application coordination, and verifiability; and execution checks with manual expert inspection and verifier alignment. Tasks span text-only and multimodal input modalities, with 74 text-only and 32 multimodal, covering long-horizon workflows averaging over 100 steps and multiple SaaS apps per task.
Agents tested include several state-of-the-art LLM-based CUAs (Claude Opus 4.6, GPT-5.4 High, Qwen 3.6 Plus, etc.). Agents operate in a unified execution framework 'browser-use' that supports standardized browser actions without privileged access. Metrics are weighted checkpoint scores (partial progress) and resolved scores (strict all-checkpoint completion). Verification methods include automated database/API state checks, string/structural content matching, and LLM-based open-ended output evaluation.
Multiple runs produce pass@1, pass@2, and pass@3 evaluations to measure consistency and robustness. Error analysis breaks down failure modes by action type and domain. Correlations between task complexity dimensions (apps involved, operation steps, checkpoint count) and agent performance are analyzed.
The entire environment, tasks, and evaluation framework are publicly available for reproducibility. However, some multimodal tasks rely on multimodal data assets that require appropriate handling during execution. The prompt inputs to agents include only task descriptions, URLs, and credentials without additional ground truth or reference solutions.
Concrete example: For a Business Operations expense reimbursement workflow spanning HRMS, finance, and CRM SaaS apps, an agent must approve claims, create bills/payments across apps, and log completion tasks via browser UI actions. The benchmark verifies database states and final outputs to ensure correctness, exposing subtle errors like date mismatches that cause checkpoint failures.
Technical innovations
- Development of a large-scale, realistic SaaS-based benchmark (SaaS-Bench) spanning 23 deployable real SaaS applications across six professional domains, enabling multi-application, long-horizon evaluation unreachable in prior benchmarks.
- Introduction of an iterative human-LLM hybrid Builder-Challenger-Refiner pipeline that combines LLM synthesis with expert review to generate realistic, executable, and verifiable professional workflows grounded in actual SaaS environments.
- Use of weighted checkpoint-based verification combining objective database/API state checks, content-string matching, and LLM-based judgement for rigorous task completion scoring beyond simple end-to-end success.
- Deployment of a unified browser-based execution framework enforcing agents to operate solely through realistic UI interactions without backend access or privileged API calls, ensuring credible CUA evaluation.
Datasets
- SaaS-Bench Tasks — 106 tasks — synthesized on 23 real open-source SaaS applications across six professional domains (Software, Business, Healthcare, Teamwork, Agriculture, Media)
- Generated/Imported SaaS Data — varied sizes per SaaS — synthetic LLM-generated data or open-source real datasets for SaaS population
Baselines vs proposed
- Claude Opus 4.6: overall checkpoint score = 43.2%, resolved score = 1.9% vs GPT-5.4 High: 37.0%, 3.8%
- Claude Opus 4.6 pass@1 vs pass@3: ∼8 percentage points overall improvement in checkpoint score
- Qwen 3.6 Plus: checkpoint score = 29.9%, resolved score = 1.9%
- Kimi K2.5: 27.7%, 0.0%
- Gemini 3.1 Pro: 27.1%, 0.0%
- Doubao Seed 2.0 Pro: 27.1%, 1.9%
- Claude Sonnet 4.6: 23.3%, 0.9%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.15777.

Fig 1: Leaderboard of SAAS-BENCH. We report overall checkpoint scores (bar length) and resolved

Fig 2: SAAS-BENCH provides a realistic benchmark for evaluating CUAs in deployable SaaS environ-

Fig 3 (page 1).

Fig 4 (page 1).
Fig 5 (page 1).
Fig 6 (page 1).

Fig 7 (page 1).
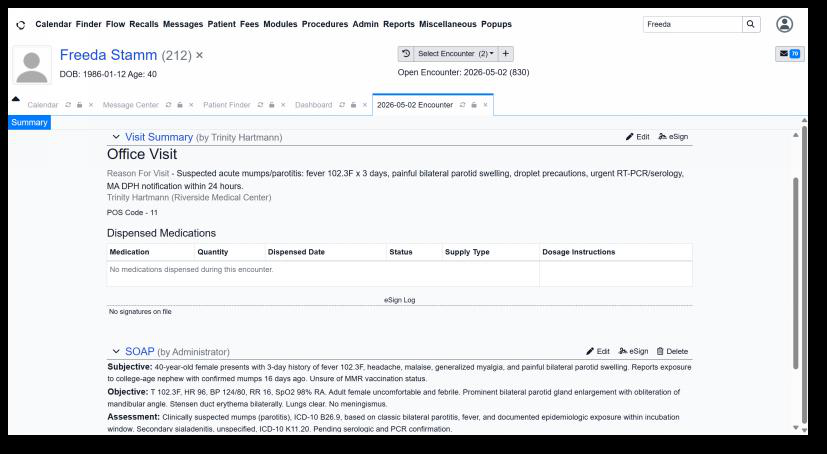
Fig 8 (page 2).
Limitations
- SaaS-Bench currently evaluates only open-source SaaS platforms, which may not fully capture complexities of proprietary enterprise SaaS.
- Agents operate under a browser-use framework without backend access; real-world production agents might leverage APIs or privileged system calls for efficiency.
- Multimodal tasks rely on raw image and document file paths without parsed annotations, potentially limiting agent performance due to insufficient modality understanding.
- Error analysis focuses on checkpoint-level failures but does not incorporate rigorous adversarial attack scenarios or robustness under distribution shifts.
- The prompt design restricts agents to task descriptions and credentials but does not explore multi-turn human-agent interaction or dialogue for error correction.
- The dataset and tasks are domain-focused but may lack coverage of all enterprise verticals or rare edge-case workflows common in practice.
Open questions / follow-ons
- How can CUAs improve long-horizon planning and error recovery to increase resolved task completion beyond the current <4% ceiling?
- What architectural or training modifications can enable more robust multi-application context tracking and state management over hundreds of interaction steps?
- How would incorporating backend API access or hybrid UI+API control impact CUA performance and applicability in real SaaS environments?
- Can multimodal perception models better integrated with LLMs improve performance on multimodal SaaS-Bench tasks involving images and documents?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, SaaS-Bench provides valuable insights into the long-horizon challenges autonomous LLM-based CUAs face when remotely interacting with complex software platforms. The benchmark highlights the current bottlenecks in reliable UI grounding, cross-application coordination, and error recovery which adversaries would need to overcome for fully autonomous abuse at scale. The low end-to-end completion rates suggest practical defenses may still focus on exploiting fragility in multi-step workflows or isolated state dependencies. This also implies that security mechanisms embedded deeply in SaaS workflows, with cross-application verification, could raise the bar against automated misuse. However, the evaluation approach also demonstrates the importance of fine-grained checkpoint verification rather than relying solely on coarse success signals, informing better design of multi-stage CAPTCHA or behavioral validation schemes.
Cite
@article{arxiv2605_15777,
title={ SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows? },
author={ Kean Shi and Zihang Li and Tianyi Ma and Zengji Tu and Jialong Wu and Xinbo Xu and Qingyao Yang and Ruoyu Wu and Weichu Xie and Ming Wu and Jason Zeng and Michael Heinrich and Elvis Zhang and Liang Chen and Kuan Li and Baobao Chang },
journal={arXiv preprint arXiv:2605.15777},
year={ 2026 },
url={https://arxiv.org/abs/2605.15777}
}