
PromptDecipher: Supporting AI Tutor Authoring Through Editable Simulated Interactions
Source: arXiv:2605.16605 · Published 2026-05-15 · By Miina Koyama, Ruiwei Xiao, John Stamper
TL;DR
PromptDecipher addresses the critical gap in AI tutoring chatbot authoring where educators, despite creating content, fail to systematically test and refine bot behavior before deployment. Unlike existing platforms that require teachers to write or edit abstract system prompts—an often unfamiliar and opaque task—PromptDecipher restructures the workflow around interactive, editable simulated chats. Educators directly correct undesirable bot responses in targeted test scenarios, triggering an automated pipeline that infers pedagogical intent, proposes precise prompt rewrites, and validates changes against regression tests before permitting publication. This approach embeds quality assurance into the authoring cycle and scaffolds educators’ dual roles as learning designers and QA engineers.
The system's novelty lies in using direct response correction as the primary authoring act rather than prompt text editing, resulting in a more intuitive interface aligned with teachers' expertise in giving corrective feedback. PromptDecipher also integrates automated verification to prevent regressions in previously passed test cases, ensuring stability and reliability. A formative study of 121 instructor-authored chatbots revealed near absence of systematic testing, motivating this design. The system is scheduled for deployment in a large "AI for Educators" MOOC, allowing evaluation of whether this correction-based workflow improves test coverage and bot quality at scale. Full code, prototype, and demos are publicly available.
Key findings
- In a formative study of 121 instructor-created chatbots, virtually none engaged in systematic testing prior to deployment, revealing a critical gap in authoring practice.
- PromptDecipher’s correction-based workflow requires at least one QA cycle—edit, prompt rewrite, regression validation—before bot publication, enforcing continuous testing.
- The Reverse Prompting Pipeline uses an LLM to infer pedagogical intent from a teacher’s edited bot response, enabling targeted, minimally invasive prompt rewrites.
- Automated regression verification evaluates updated prompts against all previously passed test cases, flagging failures to prevent degradation of bot behavior.
- PromptDecipher supports selecting different student profiles (e.g., struggling learner, off-topic input) to simulate varied interaction scenarios for robust testing.
- The system was designed and is being deployed in an AI for Educators course comprising hundreds of higher education instructors, providing a large user base for further study.
- A live prototype, anonymized codebase, and interactive demo are publicly accessible, supporting reproducibility and practitioner adoption.
Threat model
The threat model focuses on the risk of poorly specified or insufficiently tested AI tutoring chatbots being deployed to learners, leading to suboptimal or potentially harmful instructional interactions. The adversary is effectively the lack of expertise and QA rigor by educators, rather than external attackers. Malicious adversaries or prompt injections are out of scope.
Methodology — deep read
The authors start with a threat model where the adversary is not a malicious actor but the risk of low-quality AI tutors reaching students due to teacher inexperience in prompt engineering and lack of systematic testing. Teachers do not know how to specify AI behavior explicitly and rarely test bots before deployment, creating risk for learner outcomes.
Data comes from a formative study analyzing 121 chatbots created by instructors in a large online AI-for-Educators MOOC. The study documented teachers' authoring practices, showing a systemic lack of testing. No sensitive or private datasets were used; the data is mainly authoring session logs.
The core architecture of PromptDecipher is a web-based authoring interface linked with a Reverse Prompting Pipeline. The teacher interacts with a live simulated student chat using multiple student profiles representing typical interaction scenarios.
When the teacher edits a bot response, the system uses an LLM to compare the original and corrected responses. It infers the teacher’s pedagogical intent (e.g., prompting for eliciting student thinking instead of direct answers) and generates a minimal, targeted modification of the underlying system prompt. This is surfaced to the teacher for review.
Next, the revised system prompt is applied and the bot’s responses are automatically re-evaluated across all previously passed test cases to detect regressions (failures due to the prompt change). The teacher must review and resolve any flagged regressions before proceeding.
The training regime and hyperparameters relate only to the underlying LLMs used (OpenAI, Anthropic, Google APIs) and are managed externally. PromptDecipher's innovation is in the frontend interaction, prompt diff generation, and regression test orchestration rather than model training.
Evaluation uses metrics such as pass/fail on predefined test scenarios simulating diverse student profiles. The baseline is untested or opportunistic prompt editing by instructors from the formative study. Statistical comparisons or controlled trials will be possible after deployment in the MOOC.
All code is anonymized but made available for reproducibility. The system demo, anonymized datasets, and source code links are provided. Future papers are expected to report large-scale quantitative evaluation results after deployment.
A concrete example: the teacher selects the 'struggling learner' profile; the bot responds with a direct answer. The teacher edits the response to first ask a guiding question instead, submits the correction. The system detects intent "ask guiding question rather than answer directly" and proposes a prompt rewrite adding instructions for this behavior. The updated prompt is tested across all other profiles to check no regressions occur. Once all test scenarios pass, the bot can be published with confidence in its improved, consistent behavior.
Technical innovations
- Reversing traditional prompt engineering by centering authoring on direct correction of chatbot responses rather than abstract prompt text editing.
- Automated pipeline that infers pedagogical intent from teacher corrections using LLM-based diff analysis and produces targeted minimal prompt rewrites.
- Regression verification mechanism that automatically validates prompt updates against a suite of previously passed test scenarios to prevent behavioral regressions.
- Integration of diverse simulated student profiles to provide context-specific testing and robustness checks across multiple learner types.
Datasets
- 121 instructor-authored AI tutoring chatbots — formative analysis dataset collected from an AI for Educators MOOC — not publicly available
Baselines vs proposed
- Baseline (teacher prompt editing without systematic testing): near 0% of bots underwent systematic test correction.
- PromptDecipher enforced authoring flow mandates ≥1 correction and regression test cycle before publication, ensuring 100% testing coverage prior to deployment.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.16605.
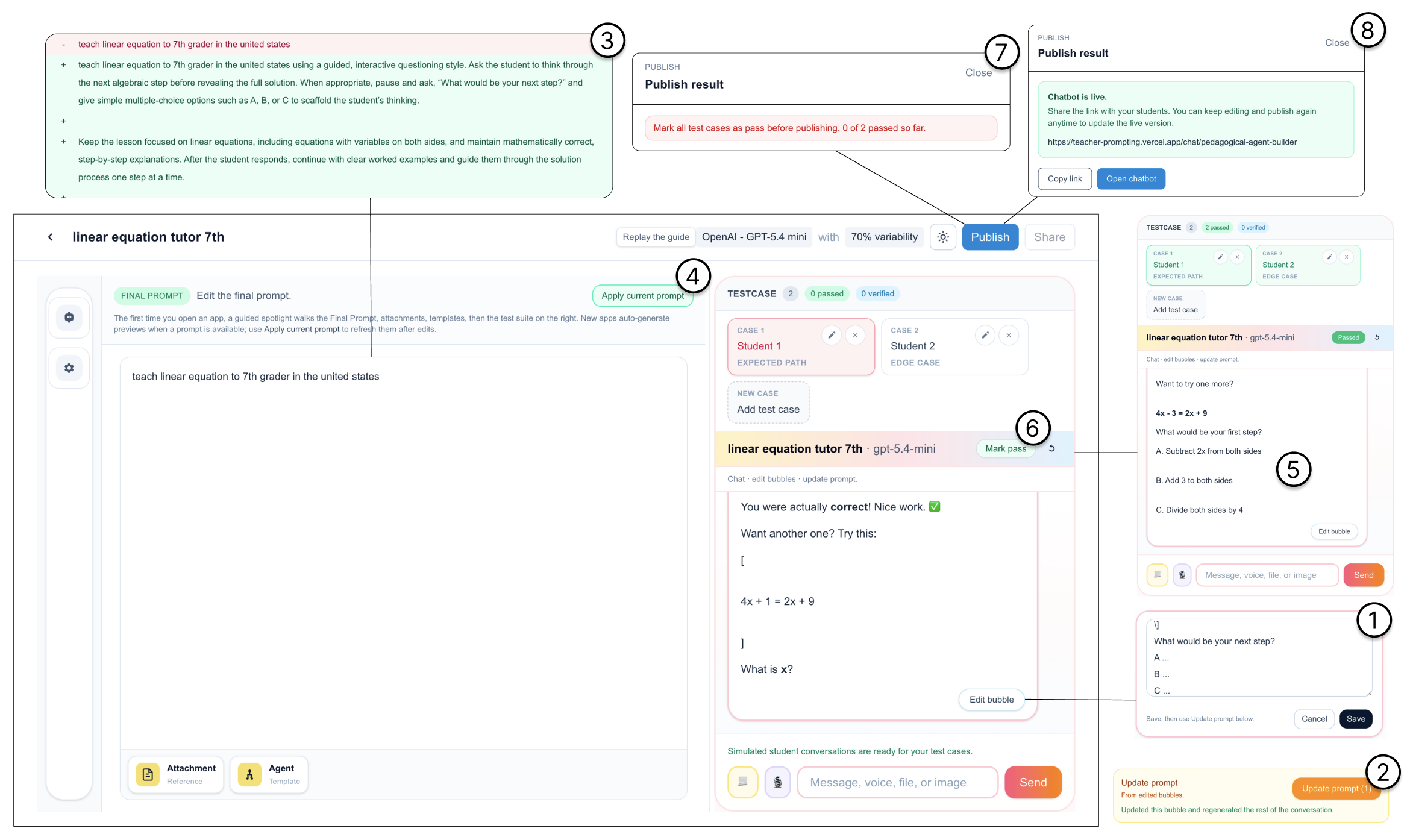
Fig 1: The PromptDecipher workflow. (1) A teacher edits an unsatisfactory bot response in the test case chat. (2) The system
Limitations
- Evaluation metrics and efficacy data from the live deployment in the AI for Educators course are not yet available.
- The formative study data and deployment are limited to higher education instructors, possibly limiting generalizability to K-12 or other educator populations.
- The system currently supports a limited set of predefined student profiles and test scenarios, potentially missing edge cases.
- Prompt rewrite quality depends on the underlying LLM’s ability to accurately interpret pedagogical intent from edits, which may be error-prone.
- No adversarial testing or evaluation against malicious misuse or prompt injection attacks has been reported.
- The approach assumes educators are willing and able to engage in iterative test-correct-verify cycles, which may impact authoring efficiency.
Open questions / follow-ons
- Does the correction-based workflow measurably increase systematic testing rates and improve prompt quality compared to conventional text-prompt editing?
- How well does the Reverse Prompting Pipeline generalize across diverse subject domains, educator expertise levels, and learner profiles?
- Can automatic generation of additional edge-case test scenarios improve detection of subtle or rare failures in bot behavior?
- How can pedagogical guidance integrated into the system improve teachers’ understanding of effective tutoring strategies surfaced through their corrections?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, PromptDecipher exemplifies a human-in-the-loop approach embedding quality assurance directly into iterative authoring workflows. Its method of soliciting direct corrections on observable AI outputs rather than opaque configuration aligns with best practices to reduce error and unintended behaviors in automated agents.
Practitioners building bot-detection or immune chatbot systems can glean insights into how structured testing and regression validation workflows improve robustness and guard against regressions that enable evasions or degrade user experience. The use of simulated user profiles and automated regression tests highlights a practical approach to evolving AI agents safely. Though oriented to education, such correction-driven, scenario-based workflows could be adapted to rigorously test security-related AI systems with high stakes, by enforcing systematic test-and-verify cycles before deployment.
Cite
@article{arxiv2605_16605,
title={ PromptDecipher: Supporting AI Tutor Authoring Through Editable Simulated Interactions },
author={ Miina Koyama and Ruiwei Xiao and John Stamper },
journal={arXiv preprint arXiv:2605.16605},
year={ 2026 },
url={https://arxiv.org/abs/2605.16605}
}