
PersonaFingerprint: Measuring Persona Inference on Modern Websites with LLM-Driven Browsing
Source: arXiv:2605.15962 · Published 2026-05-15 · By Chuxu Song, Hao Wang, Richard Martin
TL;DR
This paper introduces and rigorously studies persona fingerprinting, a novel privacy risk where an adversary infers a user's behavioral persona (e.g., browsing style) solely from encrypted network traffic metadata on modern websites. Unlike traditional website fingerprinting that identifies the site visited, persona fingerprinting aims to distinguish who is browsing based on interaction patterns captured via packet lengths, directions, and inter-arrival times in fixed-length packet windows. To overcome scarce labeled data and the complexity of modern web interactions, the authors develop an LLM-driven multi-agent browsing framework that generates controlled, persona-conditioned browsing sessions across ten popular, highly-interactive websites and fifteen canonical personas plus an open-world category. Using these large-scale synthetic traces, they show persona inference reaches approximately 84% accuracy in mixed-site settings, with per-site macro-F1 scores typically between 0.78 and 0.91. Importantly, they demonstrate that standard website fingerprinting encoders already incidentally encode persona signals that can be extracted cheaply via representation probing. Joint multi-task training further amplifies persona leakage while maintaining high site-classification accuracy. These results reveal that current encrypted web traffic leaks sensitive information beyond sites visited, including user behavior patterns and identity attributes, posing new privacy challenges for encrypted browsing systems.
Key findings
- A website-only classifier achieves about 93% average site classification accuracy across 10 modern interactive sites using 1,000-packet windows.
- Per-site persona fingerprinting classification reaches between approximately 75% and 92% accuracy and 0.78 to 0.91 macro-F1 scores on five representative platforms.
- Mixed-site persona inference across all sites and personas achieves around 84% classification accuracy.
- A lightweight multi-task training objective balancing site and persona losses can boost persona accuracy to about 80% while retaining site classification accuracy near the 93% baseline.
- Representation probing shows that freezing a site-only encoder and training a small MLP probe recovers a 20–30 point absolute persona accuracy gain over random-feature baselines.
- Open-world experiments reveal non-trivial misattribution rates: unseen personas can be confused as one of the known 15 canonical personas, implying privacy risk amplification.
- LLM-driven multi-agent browsing produces persona-conditioned trace data with high behavioral consistency and diversity, supporting realistic, controlled large-scale evaluation.
Threat model
A passive network adversary positioned to observe encrypted traffic metadata (packet sizes and timing) on anonymized/tunneled channels like Tor or VPNs. The adversary cannot decrypt payloads, access URLs, cookies, or client-side identifiers, nor segment traffic into page loads. The adversary attempts to infer the user’s persona (behavioral browsing style) from fixed-length windows of encrypted traffic metadata, assuming no active intervention or injection.
Methodology — deep read
Threat Model & Assumptions: The adversary is a passive network observer on encrypted, anonymized channels like Tor or VPNs, able to see packet lengths (signed by direction) and inter-arrival times but not application payloads, URLs, cookies, or client-side identifiers. The adversary cannot segment traffic into page loads due to continuous background content fetching and modern single-page application designs.
Data: To generate rich, labeled data at scale, the authors build a two-agent LLM-driven browsing framework. One agent is an LLM-based decision module prompted with a structured persona profile (background, goals, content preferences) and observing page screenshots plus action history, producing high-level natural-language browsing instructions. The other agent is a computer-use module that translates those instructions into concrete DOM interactions (clicks, scrolls, keystrokes) on real websites, capturing packet-level encrypted traffic traces. They cover 10 popular websites (Amazon, YouTube, Reddit, LinkedIn, etc.) and 15 canonical personas plus an open-world label aggregating unseen personas. Each (site, persona) pair yields roughly 5,000 non-overlapping fixed-length windows of 1,000 consecutive packets, resulting in an approximately 800,000 sample dataset.
Architecture/Algorithm: Traffic windows are sequences of packet length (with direction) and inter-arrival time pairs. A shared 1D CNN encoder processes these sequences to produce compact vector representations. On top of this encoder, separate softmax classifiers predict site labels and persona labels. The persona classifier is trained in two settings: per-site (persona prediction conditioned on known site) and mixed-site (persona prediction pooled across sites, no site knowledge). Closed-set (15 personas) and open-world (adding unseen persona class) are evaluated.
Training Regime: Models are trained using cross-entropy loss. Multi-task training jointly learns site and persona classifiers with a weighted sum of losses. For probing incidental persona leakage, a site-only encoder is first trained, frozen, then a small MLP probe is trained to predict personas from the frozen representation. Train/validation/test splits avoid temporal leakage by splitting at session level (70/10/20). Hyperparameters like batch size, epochs, learning rate, and hardware details are not specified in detail.
Evaluation Protocol: Metrics include top-1 accuracy and macro-F1 for both site and persona classification. Open-world evaluation uses additional precision, recall, F1 for the open-world class and measures of misattribution (fraction of open-world samples wrongly assigned to canonical personas). Baselines include a site-only classifier and a random frozen encoder for probing. Ablations sweep the weight balancing site and persona in multi-task learning. Behavioral diagnostics quantify persona consistency and diversity to ensure generated samples are realistic. No explicit statistical significance tests are reported.
Reproducibility: The paper does not specify public code or data release. The LLM-driven browsing setup and derived datasets appear custom and proprietary. Model architectures and training losses are described clearly but low-level implementation details and random seeds are not detailed.
Concrete Example End-to-End: For persona P5 (price-sensitive shopper) on Amazon, the LLM decision agent receives the persona prompt, page screenshot, and action history, then issues instructions like “filter by price range” or “open top review.” The computer-use agent executes clicks and scrolls, generating encrypted packet captures. Fixed windows of 1,000 packets are extracted, labeled with persona P5 and Amazon site. These labeled windows train a CNN encoder + persona classifier producing about 90% per-site persona accuracy. A frozen site-only encoder plus MLP probe recovers persona information indicating potentially serious privacy leaks even without explicit persona training.
Technical innovations
- Introduction and formalization of persona fingerprinting as a new privacy risk on encrypted web traffic beyond traditional website fingerprinting.
- LLM-driven multi-agent framework generating large-scale, persona-conditioned browsing traces with structured natural-language persona profiles, enabling controlled data collection without human subjects.
- Use of fixed-length encrypted packet windows (length 1000) capturing packet length and inter-arrival time metadata as robust input representation for combined site and persona fingerprinting on modern interactive websites.
- Joint multi-task learning and representation probing techniques demonstrating that persona signals are incidentally encoded in site-only website fingerprinting models and can be amplified cheaply.
Datasets
- Synthetic persona-conditioned encrypted traffic traces — ~800,000 fixed-length packet windows — from 10 real modern websites × 15 canonical personas plus open-world label (generated via LLM-driven browsing agents; not publicly released)
Baselines vs proposed
- Site-only classifier (website fingerprinting): accuracy ~93% vs joint multi-task with persona objective: site accuracy ~93%, persona accuracy ~80%
- Per-site persona classifier: accuracy range 75%–92% across five representative sites vs random baseline (approx. 6.25% for 16 classes)
- Mixed-site persona classifier: accuracy ~84% vs random baseline (~6.25%)
- MLP probe on frozen site-only encoder: raises persona classification by 20–30 absolute percentage points over random encoder MLP probe baseline
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.15962.
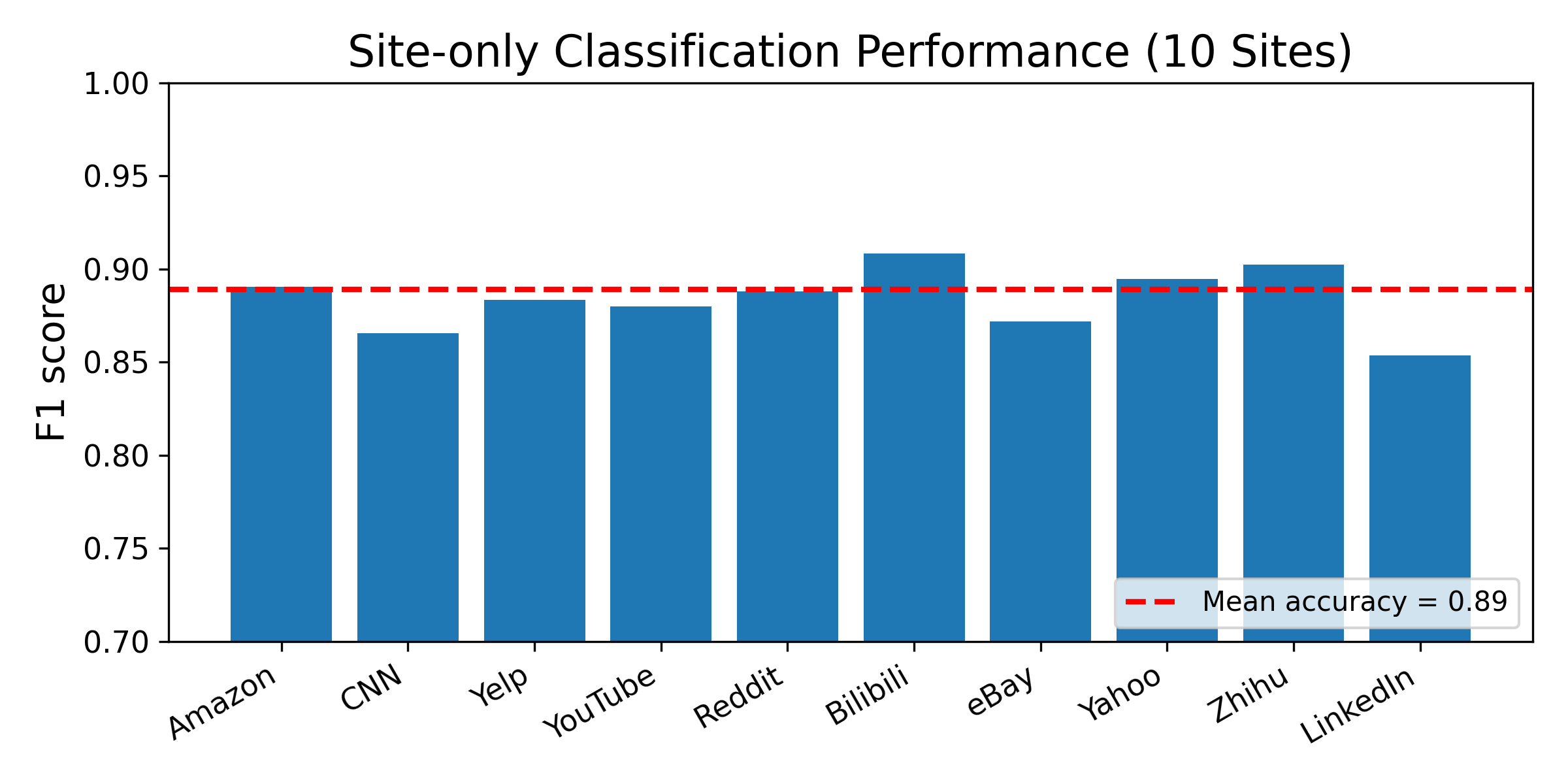
Fig 1: Website fingerprinting baseline: per-site accuracy
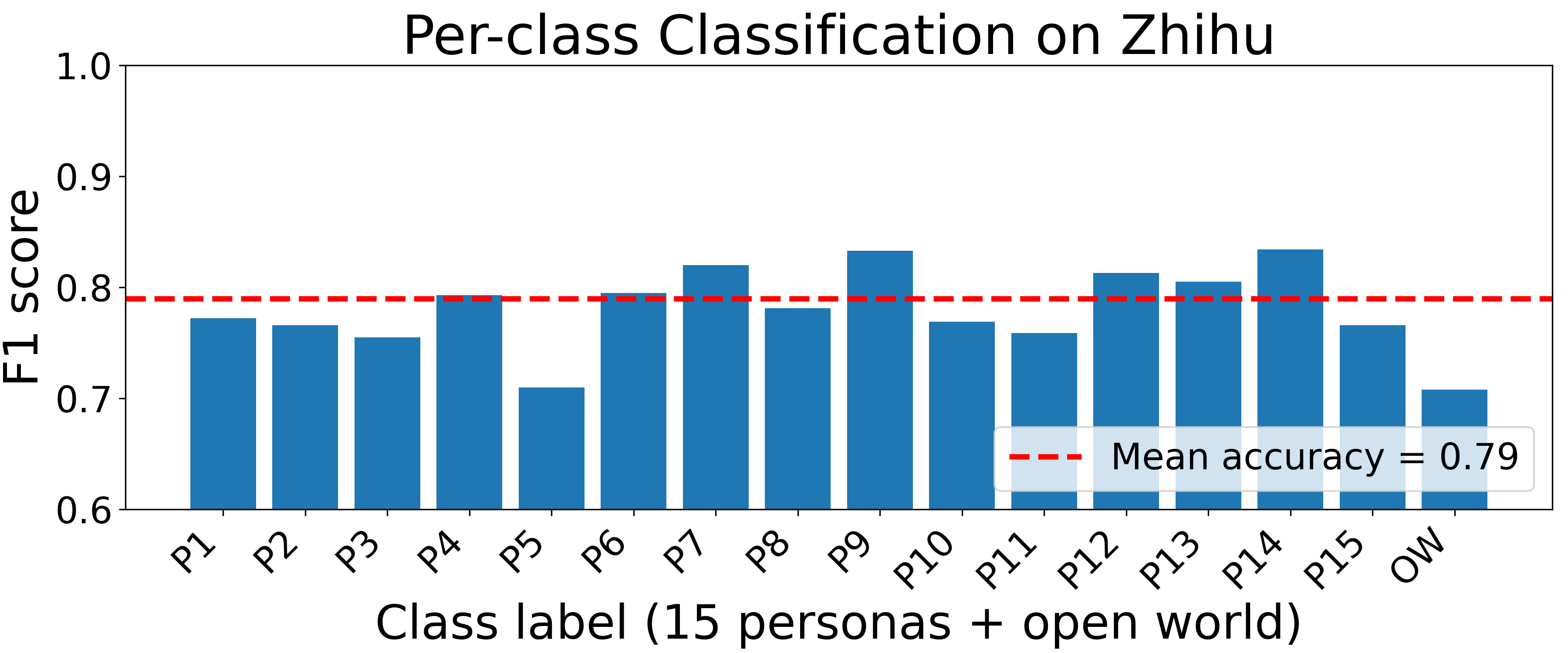
Fig 2: Per-site persona fingerprinting: macro-F1 for each of the fifteen canonical personas and the OW label on all ten websites.
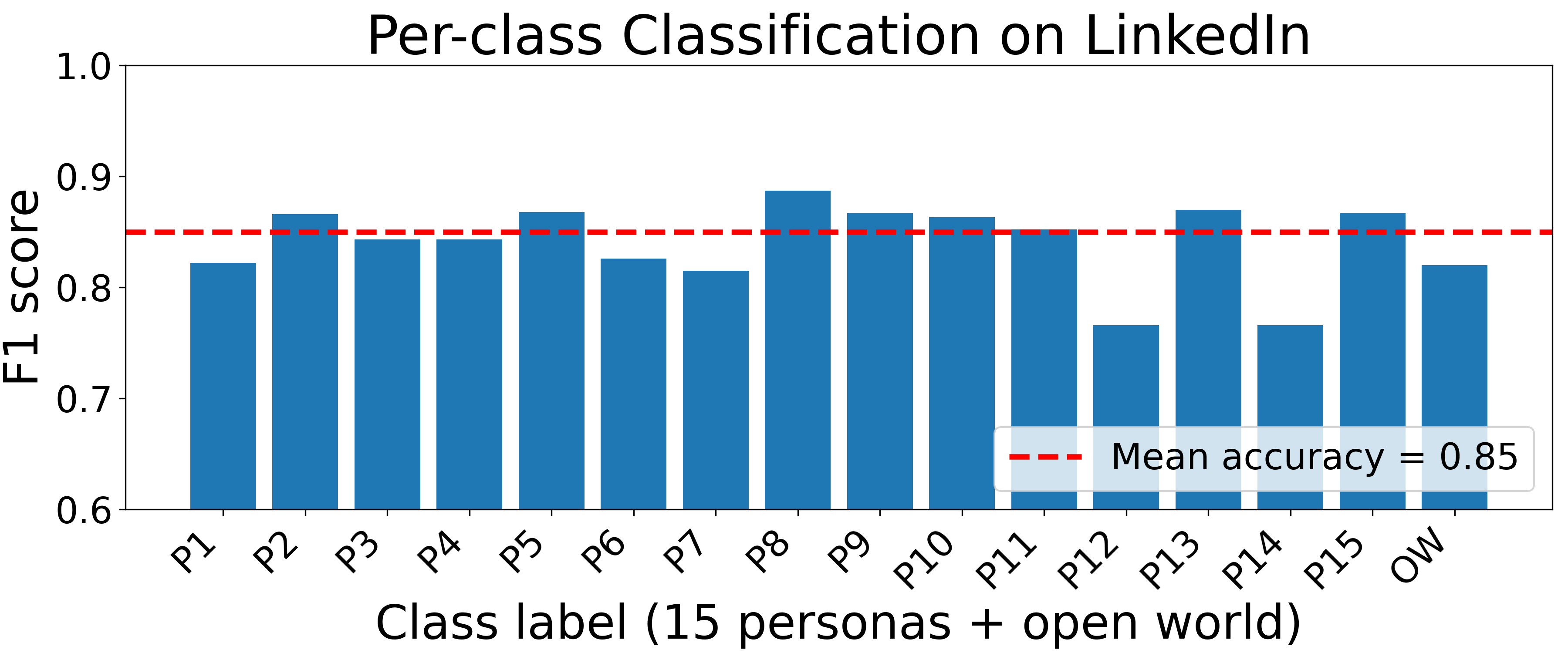
Fig 3: Global persona fingerprinting in an open-world set-
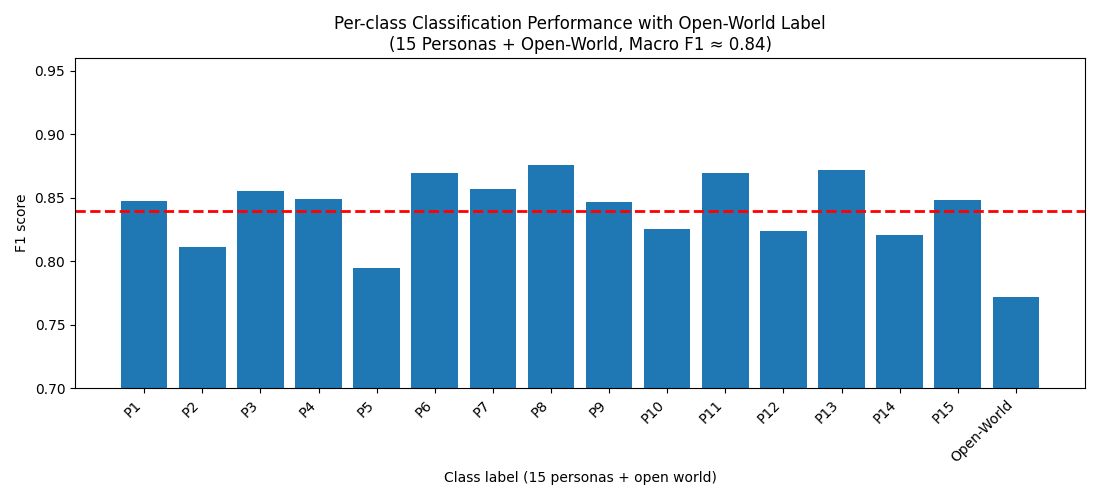
Fig 4: Representation probing: persona classification accu-
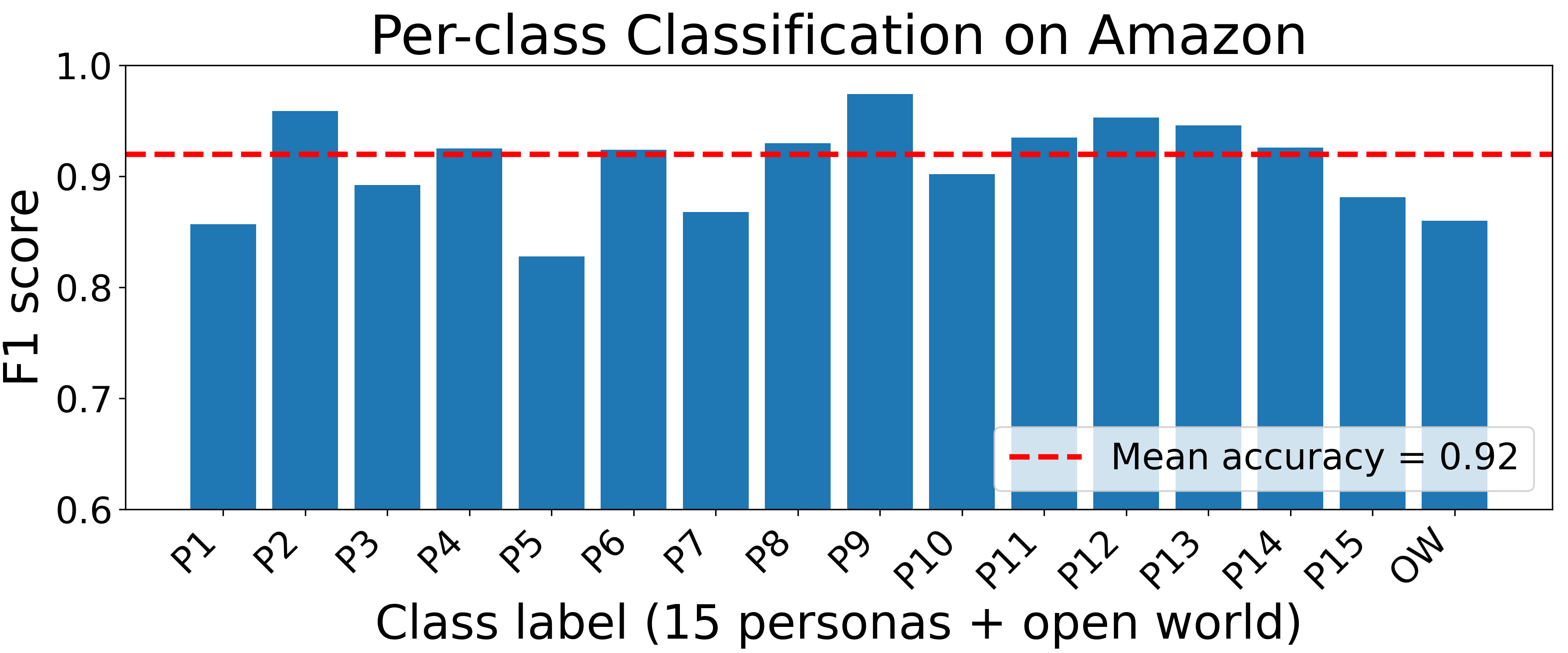
Fig 5: illustrates the trade-off on the mixed-site persona
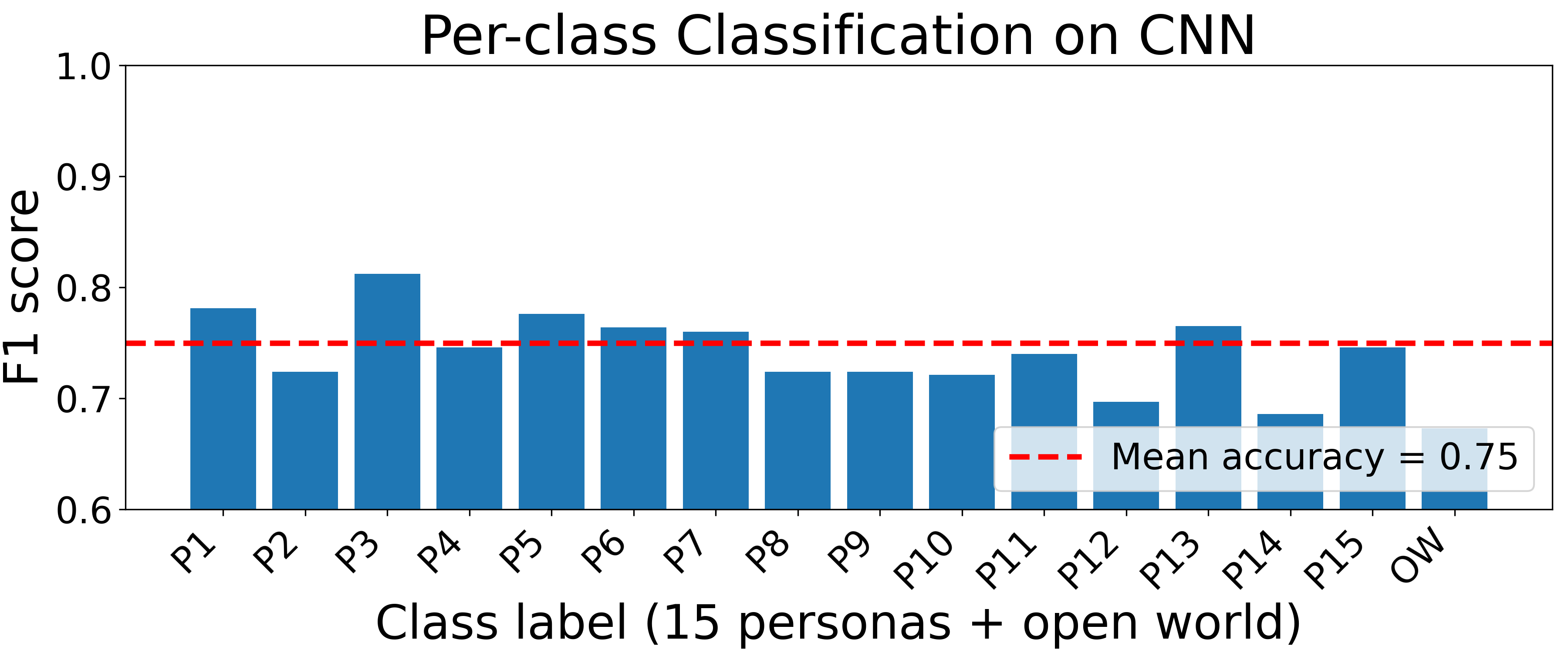
Fig 6: Behavioral diagnostics for a subset of personas
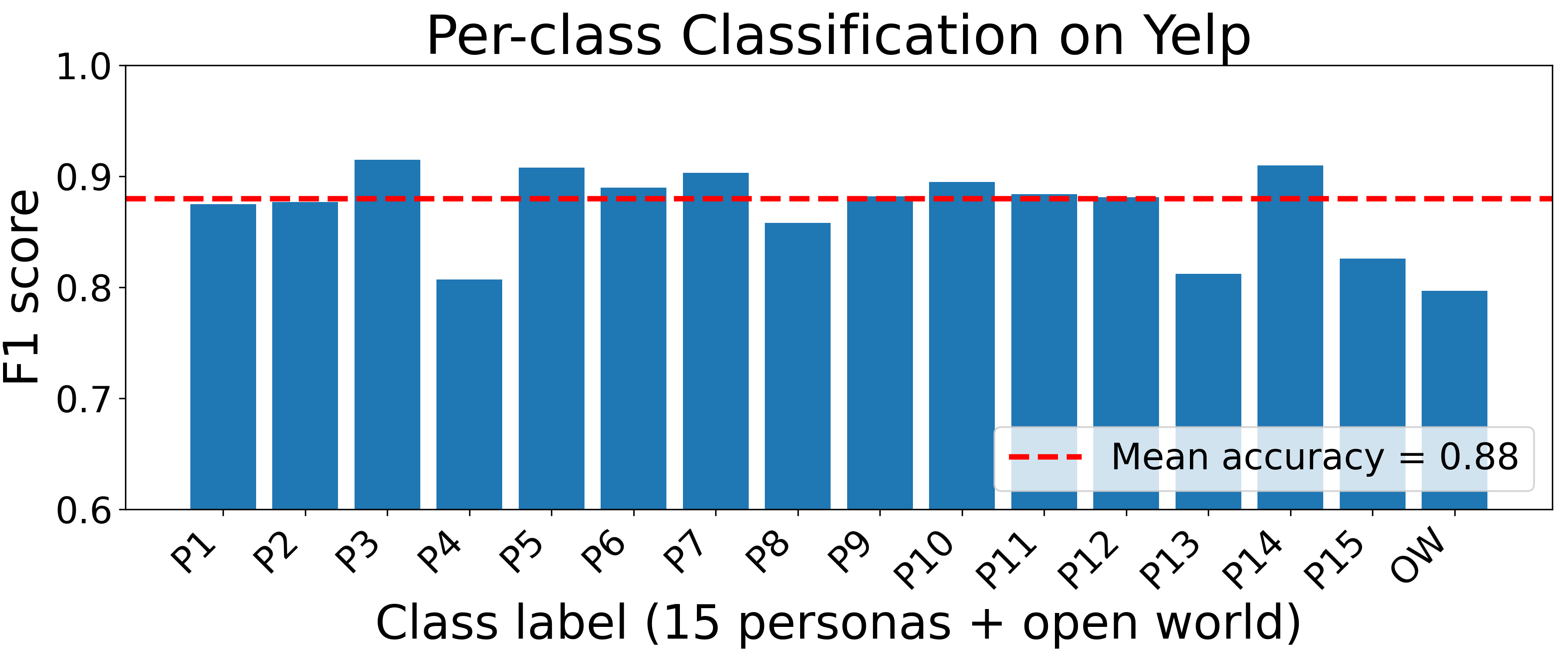
Fig 7 (page 9).
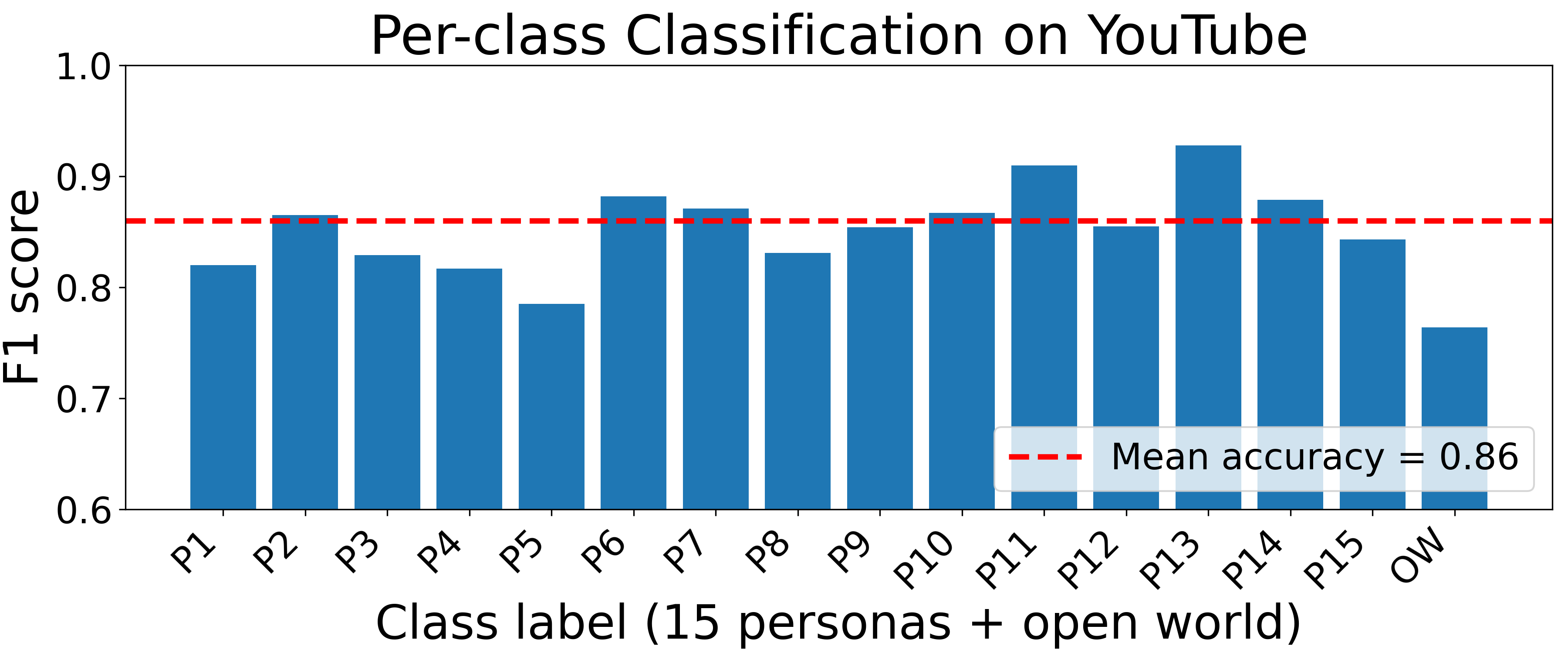
Fig 8 (page 9).
Limitations
- Generated persona behaviors from LLM agents may not fully capture the nuance or variability of real human browsing, limiting ecological validity.
- No evaluation on real user traffic or large-scale human-collected persona-labeled datasets to validate findings in the wild.
- Limited detail on hyperparameter tuning, random seed use, and hardware, impacting reproducibility.
- Open-world label construction and generalization to truly unseen personas is approximate and may not represent real-world diversity.
- No reported robustness or adversarial evaluation examining how attackers may evade persona inference.
- Fixed-length 1,000 packet window abstraction may miss finer-grained temporal signals or longer-term behavior patterns.
Open questions / follow-ons
- How well do persona fingerprinting models transfer to real human browsing traces with natural behavior variability and noise?
- Can effective defenses or traffic obfuscation protocols be developed to mitigate persona leakage without degrading web usability?
- How does persona inference accuracy evolve under adaptive adversaries aware of defenses or applying adversarial machine learning?
- Are there privacy risks beyond persona inference, such as combining multiple sessions or cross-site correlation to deanonymize users?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work signals a new privacy threat vector that encrypted traffic metadata reveals rich behavioral signals beyond site identity. Traditional WFP defenses or network-layer protections may insufficiently guard against persona fingerprinting. Understanding that browsing styles—indicative of user intent, risk posture, or preferences—can be inferred suggests the need for enhanced traffic obfuscation or shaping techniques to blur user behavior patterns. CAPTCHA challenges or bot-detection heuristics could incorporate awareness of persona leakage risks, treating behavioral metadata leakage as a factor in trust models or requiring stronger guarantees against behavioral profiling. The LLM-driven browsing framework may also serve as a useful tool for future attack simulations or robustness testing of privacy-preserving measures.
Cite
@article{arxiv2605_15962,
title={ PersonaFingerprint: Measuring Persona Inference on Modern Websites with LLM-Driven Browsing },
author={ Chuxu Song and Hao Wang and Richard Martin },
journal={arXiv preprint arXiv:2605.15962},
year={ 2026 },
url={https://arxiv.org/abs/2605.15962}
}