
MAgSeg: Segmentation of Agricultural Landscapes in High-Resolution Satellite Imagery using Multimodal Large Language Models
Source: arXiv:2605.16179 · Published 2026-05-15 · By Piyush Tiwary, Utkarsh Ahuja, Depanshu Sani, Aishwarya Jayagopal, Sagar Gubbi, Subhashini Venugopalan et al.
TL;DR
This work addresses the challenging problem of segmenting smallholder agricultural landscapes in the Global South using very-high-resolution (VHR) satellite imagery. Such landscapes exhibit high intra-class variance, fragmented plots, and diverse land uses, while labeled training data is scarce. Existing multimodal large language model (MLLM) segmentation methods either rely on heavy decoder heads incurring large overhead, or decoder-free methods that suffer from context length bottlenecks and loss of spatial detail due to mask downsampling. MAgSeg introduces a novel decoder-free MLLM approach that leverages a patch-based instruction tuning dataset format enabling the model to utilize the global context of the full-resolution image, while generating textual mask tokens only for a spatial sub-patch. This overcomes token length constraints without sacrificing high-frequency image details critical for boundary delineation. Additionally, MAgSeg employs a Reinforcement Learning based post-training method, Group Relative Policy Optimization (GRPO), which directly optimizes for pixel-level semantic accuracy (mean DICE), closing the domain gap between the textual tokens and spatial mask accuracy.
Extensive experiments on datasets spanning India, Cambodia, and Vietnam demonstrate that MAgSeg significantly outperforms state-of-the-art decoder-based and decoder-free MLLM baselines by large margins (e.g. +21 mIoU over best baseline on India ALU dataset, +31 mIoU on Cambodia). It achieves these improvements with zero parameter overhead beyond the base LLM, greatly enhancing computational efficiency during training and inference. Qualitative results show much sharper, cleaner instance boundaries than competing methods. Moreover, zero-shot generalization tests from India to Southeast Asia illustrate robust transfer ability due to the generative patch-based training framework. Overall, MAgSeg offers a highly scalable, parameter-efficient, and accurate segmentation framework tailored for complex smallholder agricultural environments in the Global South from satellite data.
Key findings
- MAgSeg achieves +21 mean IoU points improvement over GRES, the closest baseline, on the ALU India dataset for field segmentation.
- On Cambodia, MAgSeg obtains 0.43 mean IoU vs best baseline (GRES) at 0.12 mean IoU, nearly quadrupling previous best results.
- MAgSeg maintains zero parameter overhead beyond the base LLM (0.00%), compared to 9.3%-15.8% overhead for decoder-based baselines.
- MAgSeg’s parameter-normalized training time per token is 1.33×10^-8 seconds, significantly faster than LISA (1.69×10^-8) and GSVA (2.04×10^-8).
- Reinforcement Learning post-training with GRPO improves pixel-level segmentation accuracy, combining with instruction tuning yields best mean IoU.
- Zero-shot transfer from India to Cambodia and Vietnam test sets shows MAgSeg (4B) achieves 0.40 and 0.41 mean IoU respectively, surpassing baselines by 0.10-0.15.
- MAgSeg performs robustly across diverse field sizes (from <100m2 to 5 acres), climatic zones, and ecological regions; notable improvement on small fields <1 acre.
- Decoder-free Text4Seg baseline fails on satellite imagery segmentation (e.g., 0.05 mean IoU fields in India) due to downsampling and token-length constraints.
Methodology — deep read
Threat Model & Assumptions: The adversary here is not traditional but the task assumes complex smallholder agricultural landscapes with fragmented, small fields captured in very-high-resolution satellite imagery. The main challenges addressed include high intra-class variance, distribution shifts across regions, and limited labeled data. There is no security threat model involved; rather, the model must generalize across geographies and scales without catastrophic failure.
Data: Two main datasets were used. (a) ALU Dataset from India with 2009 train, 430 validation, 431 test images annotated with five semantic classes (fields, trees, clouds, ponds, wells). (b) AI4SmallFarms benchmark from Vietnam (1962/90/304 splits) and Cambodia (1860/605/177 splits). Imagery is from very-high-resolution satellite sources (Maxar Worldview, Airbus Pleiades) at approximately 0.5m GSD. Labels are multi-class semantic and instance segmentation ground truth.
Architecture & Algorithm: MAgSeg leverages existing multimodal LLMs (Gemma3 at 4B and 12B parameters) and fine-tunes them in a decoder-free way to produce segmentation masks as text token sequences encoding Run-Length Encoded (RRLE) patch masks. The innovation is the patch-based instruction tuning dataset format: the entire high-res image is input as global context, while the target is generating tokens for a single spatial patch's mask. This avoids context window length explosion. The LLM backbone weights are frozen; only LoRA adapters are trained to efficiently adapt the model.
Post-training uses Group Relative Policy Optimization (GRPO), a reinforcement learning approach that samples multiple mask token outputs per patch, decodes them, and evaluates pixel-level mean DICE score as reward. GRPO then optimizes the model to improve spatial accuracy (pixel alignment) rather than only token likelihood, reducing the domain gap common in textual segmentation approaches.
Training Regime: Supervised fine-tuning trains LoRA adapters on the patch-instruction dataset to predict the RRLE tokens under autoregressive objectives. Subsequently, GRPO post-training refines the model with a RL objective balancing reward (mean DICE) and KL regularization to avoid diverging from the supervised policy. Patch size used is 32x32 pixels. Training is done on 4B and 12B Gemma3 base LLMs comparable to prior baselines (LISA, GSVA, Text4Seg).
Evaluation Protocol: Metrics include instance-wise mean and median IoU per class, False Positive Rate, False Negative Rate, plus a parameter overhead metric measuring additional parameters beyond base LLM. Baselines include decoder-based MLLMs (LISA, GSVA, GRES), decoder-free (Text4Seg), and transformer segmentation models (LAVT). Datasets from multiple countries are evaluated separately, and zero-shot tests assess cross-domain transfer. Ablations evaluate GRPO and inference refinement's impact.
Reproducibility: The paper mentions use of publicly available datasets ALU and AI4SmallFarms, and builds on publicly known models (Gemma3). Details on LoRA training, GRPO algorithms, and mask decoding are given. No explicit code or weight release mentioned. The instruction tuning data format and tokenization approach are described in Appendices.
Example end-to-end: For a given training image, a random 32x32 pixel patch is cropped; its ground truth segmentation mask is converted to a RRLE text token sequence. The full-resolution image together with the patch bounding box and a textual instruction prompt are passed into the LLM to generate the RRLE mask tokens for the patch. During post-training, multiple candidate token sequences for that patch are sampled and decoded, their predicted masks are evaluated against ground truth by mean DICE, and these rewards optimize the policy using GRPO to improve spatial accuracy.
Technical innovations
- A novel patch-based instruction tuning dataset format that feeds full high-resolution images as context but generates RRLE-encoded text masks only for specific patches, overcoming MLLM context window length bottlenecks.
- Application of Group Relative Policy Optimization (GRPO), a reinforcement learning approach, to directly optimize pixel-level semantic accuracy (mean DICE score) for text-token-based mask generation.
- Decoder-free MLLM segmentation architecture with zero parameter overhead by leveraging LoRA fine-tuning adapters instead of auxiliary vision decoders, achieving both high accuracy and computational efficiency.
- Use of RRLE (row-wise run-length encoding) for efficiently encoding segmentation mask patches as text sequences that align with the autoregressive MLLM generation process.
Datasets
- ALU Dataset — 3870 total images (2009 train, 430 val, 431 test) — India, with fields, trees, ponds, clouds, wells annotations
- AI4SmallFarms — Cambodia: 2842 images (1860 train, 605 val, 177 test); Vietnam: 2356 images (1962 train, 90 val, 304 test) — Google Maps Satellite VHR imagery
Baselines vs proposed
- GRES: mean IoU = 0.37 (India fields) vs MAgSeg (12B) mean IoU = 0.59
- Text4Seg (refined): mean IoU = 0.07 (India fields) vs MAgSeg (12B) mean IoU = 0.59
- LISA: mean IoU = 0.22 (India fields) vs MAgSeg (4B) mean IoU = 0.58
- On Cambodia: best baseline (GRES) mean IoU = 0.12 vs MAgSeg (12B) = 0.43
- On Vietnam: GRES mean IoU = 0.40 vs MAgSeg (12B) = 0.42
- Zero-shot on Cambodia: LISA mean IoU = 0.25 vs MAgSeg (4B) = 0.40
- Zero-shot on Vietnam: LISAt mean IoU = 0.36 vs MAgSeg (4B) = 0.41
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.16179.
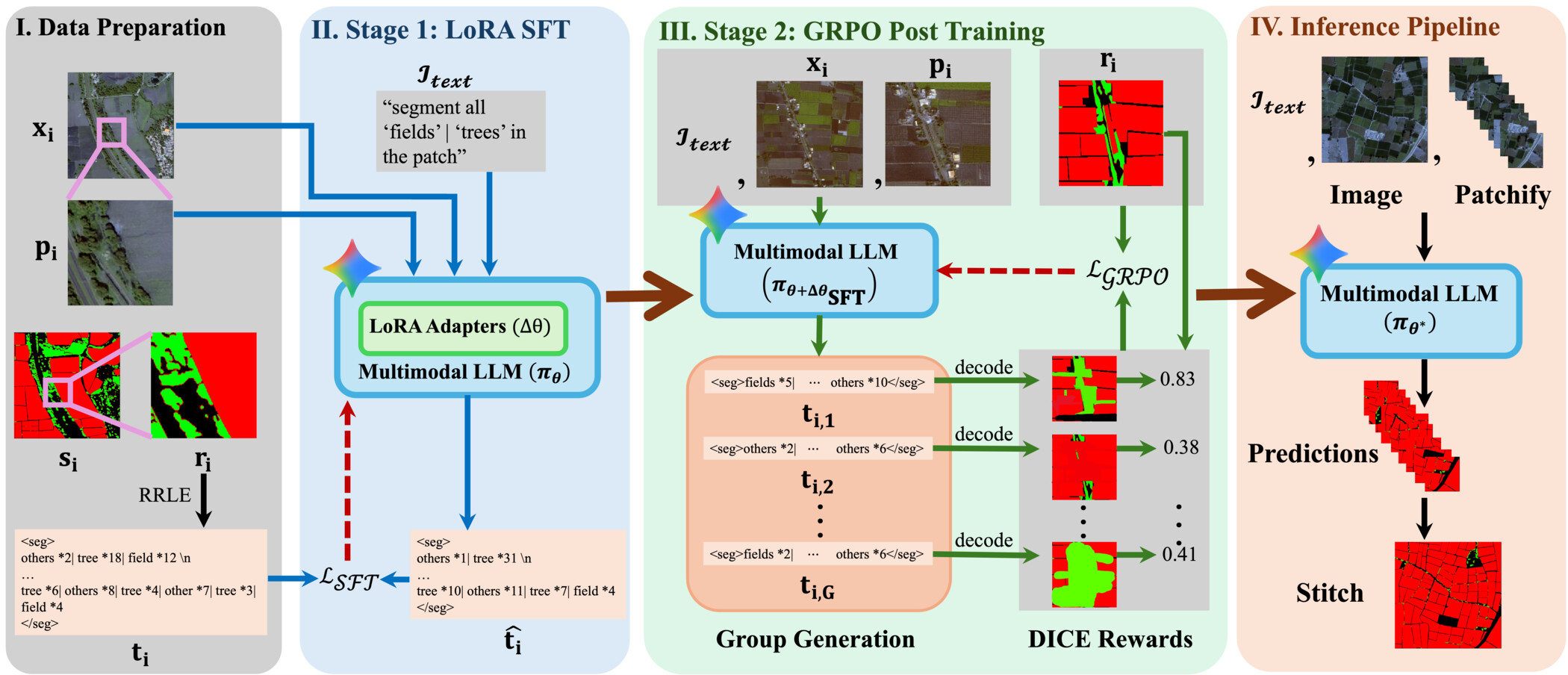
Fig 1: Overview of MAgSeg. Data Preparation: from each high-resolution satellite image xi and its segmentation map si, multiple

Fig 6: Qualitative comparison of MAgSeg’s segmentation performance with and without GRPO post-training. Region of interests are

Fig 7: Qualitative results on India data. We compare our approach, MAgSeg against SOTA segmentation baselines. GT: Ground Truth.
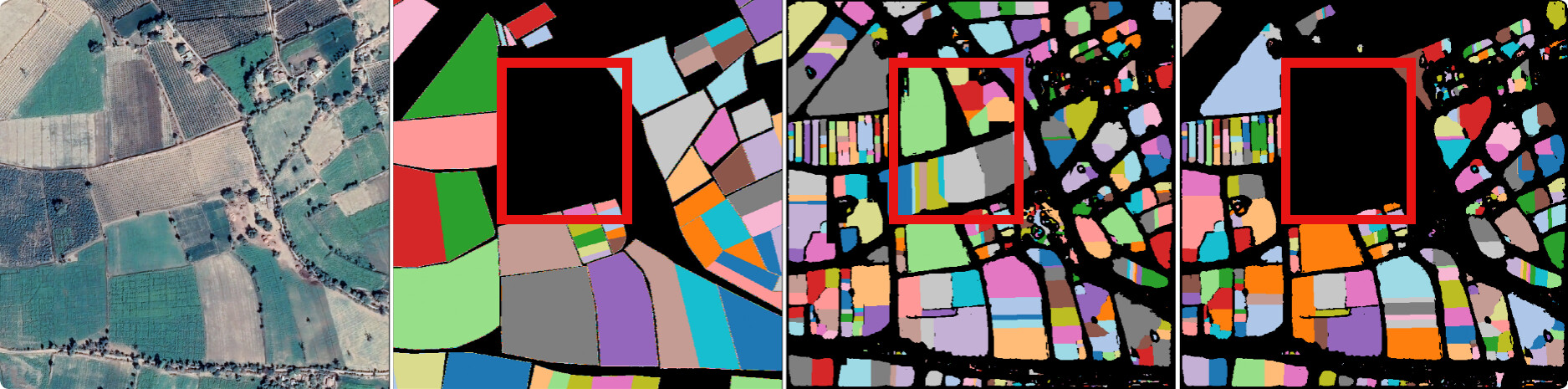
Fig 8: Qualitative results on Cambodia data. We compare our approach, MAgSeg against SOTA segmentation baselines. GT: Ground

Fig 5 (page 14).
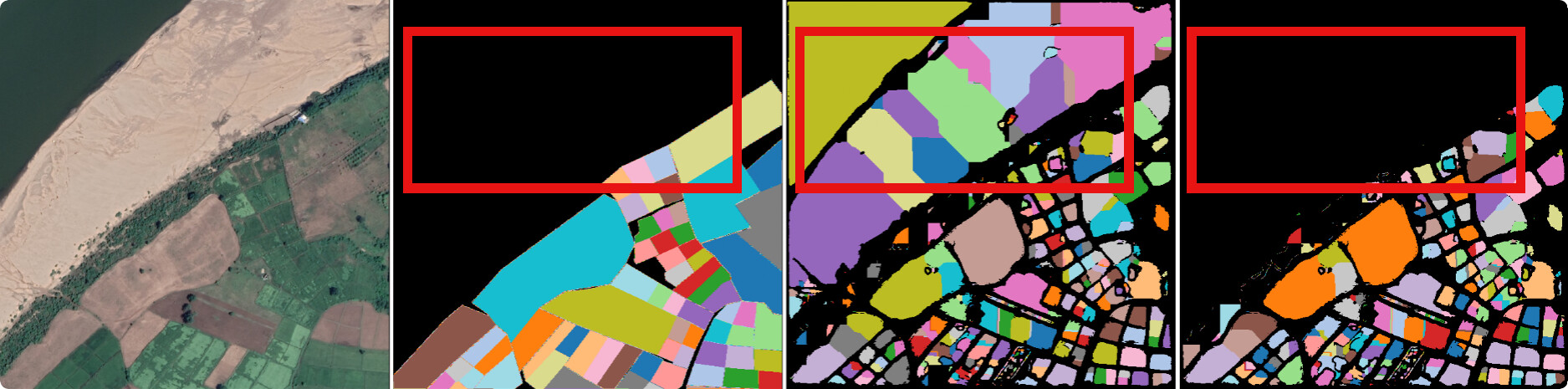
Fig 6 (page 14).

Fig 7 (page 14).

Fig 8 (page 14).
Limitations
- MAgSeg struggles to segment minority classes such as wells and ponds, due to inherent class imbalance in datasets.
- Patch-based inference processes patches independently, leading to stitching artifacts and geometric discontinuities at patch boundaries.
- No adversarial robustness or out-of-distribution robustness testing beyond evaluated geographies was reported.
- Model evaluation is limited to the Global South agricultural datasets; generalization to other satellite imagery domains or resolutions is untested.
- The reinforcement learning post-training stage adds complexity and may require tuning for stability.
- No code or pretrained weights are publicly released, limiting reproducibility for external researchers.
Open questions / follow-ons
- How can global spatial context across patch boundaries be integrated during inference to reduce stitching artifacts?
- Can the approach be extended to better handle rare or minority class segmentation, possibly via data augmentation or class rebalancing?
- What adaptations are needed to generalize MAgSeg to other satellite imagery tasks or domains beyond agricultural landscapes?
- How stable and sample-efficient is the GRPO reinforcement learning post-training across different LLM architectures and data regimes?
Why it matters for bot defense
While this paper is outside traditional CAPTCHA or bot-defense domains, its insights into aligning large multimodal language models with spatial, pixel-level prediction tasks through decoder-free instruction tuning and reinforcement learning could inspire novel text-to-image segmentation or verification techniques. The approach of encoding complex masks as text sequences within manageable token contexts and optimizing output with a spatial accuracy reward might be adapted for generating or validating complex visual challenges in bot-defense. Additionally, the demonstrated zero-parameter overhead segmentation advances show potential for efficient deployment of language models on resource-constrained devices, a consideration relevant for CAPTCHA implementations in constrained environments. Overall, practitioners focusing on CAPTCHA image generation, verification, or interpretability could study MAgSeg’s methods to enhance context-aware spatial understanding without expensive vision decoders.
Cite
@article{arxiv2605_16179,
title={ MAgSeg: Segmentation of Agricultural Landscapes in High-Resolution Satellite Imagery using Multimodal Large Language Models },
author={ Piyush Tiwary and Utkarsh Ahuja and Depanshu Sani and Aishwarya Jayagopal and Sagar Gubbi and Subhashini Venugopalan and Alok Talekar and Vaibhav Rajan },
journal={arXiv preprint arXiv:2605.16179},
year={ 2026 },
url={https://arxiv.org/abs/2605.16179}
}