
Imitation learning for clinical decision support in pediatric ECMO
Source: arXiv:2605.16175 · Published 2026-05-15 · By Fateme Golivand, Michael Skinner, Saurabh Mathur, Ameet Soni, Phillip Reeder, Kristian Kersting et al.
TL;DR
This paper addresses the challenge of modeling clinical decision-making in pediatric Extracorporeal Membrane Oxygenation (ECMO) using imitation learning. Pediatric ECMO management is complex due to irregular timing between actions, a large multi-dimensional action space, few patient trajectories, class imbalance, and the absence of explicitly labeled interventions in data. The authors propose framing treatment policy learning as an offline imitation learning problem on observational clinical trajectories. They derive discrete action labels heuristically from observed physiological shifts reflecting clinician adjustments. Three models are evaluated: a multi-layer perceptron (MLP), gradient-boosted trees (XGBoost), and the transformer-based TabPFN, a tabular foundation model pretrained on synthetic tasks to perform Bayesian inference without gradient updates. Using real-world data from 78 pediatric ECMO patients, they find that TabPFN significantly outperforms classical baselines in balanced accuracy and macro-F1, demonstrating stronger generalization to unseen patients. TabPFN also produces better calibrated action predictions with lower expected calibration error, a crucial property for clinical decision support. The authors conduct detailed feature analyses to characterize disagreements between models and clinicians, identifying oxygen concentration-related features as key sources of discordance. These results support the promise of imitation learning coupled with tabular foundation models for training high-quality clinician-behavior policies in high-stakes, data-scarce pediatric ICU settings.
Key findings
- TabPFN achieves higher mean balanced accuracy and macro-F1 than XGBoost and MLP across all four actionable knobs (FiO2, PCO2, PO2, SpO2), with standard deviations reported over leave-one-out (LOO) folds (Fig 3b,c).
- TabPFN shows substantially lower Expected Calibration Error (ECE) than baselines, indicating better calibrated probability estimates (Fig 4).
- Action labels are inferred from continuous physiological variable changes using physician-defined thresholds (e.g., PO2 changes > 25 mmHg indicate an intervention).
- Multi-head policy architecture decomposes multi-knob action space (3^4=81 possible joint actions) to independent per-knob classifiers, enabling scalable imitation learning.
- TabPFN uses a pretrained transformer that performs Bayesian inference in a single forward pass without gradient-based training, aiding generalization on small datasets.
- Data consists of 78 pediatric ECMO patient trajectories (excluding congenital heart disease), averaged in 1-hour windows with 48 state features representing current values and deltas (Table 2).
- Disagreement analysis reveals FiO2 and SpO2 features most frequently correlated with prediction errors across models, indicating oxygen concentration is a key complex decision point.
- TabPFN disagreement regions concentrate around moderate FiO2 values with small recent changes, suggesting nuanced clinical decisions in these states are harder to model.
Threat model
The threat model involves a non-interactive offline setting where the adversary is any model attempting to imitate clinical interventions in pediatric ECMO without direct supervision. The adversary has access only to observational patient trajectories with inferred actions and cannot interact with or intervene during patient care. The adversary cannot perform active experimentation or cause harm but may make inaccurate policy predictions with clinical consequences.
Methodology — deep read
Threat model & assumptions: The clinical environment is high-stakes pediatric ECMO where decisions are made sequentially by expert clinicians. The AI agent only has access to offline observational data without explicit action labels; interventions must be inferred from physiological changes. The agent cannot interact with the environment and must imitate clinician behavior under partial observability and irregular time intervals.
Data: The dataset comprises 78 pediatric ECMO trajectories from Children's Medical Center Dallas, excluding congenital heart disease cases. Patient age averaged 4.66 years; average trajectory length was 215 hours. Data is discretized to 1-hour windows; physiological features are aggregated by mean, producing 23 key clinical variables from hemodynamics, ventilator, ECMO circuit, and labs. Each state has 48 values: current values plus deltas from the previous hour, age-normalized where appropriate. Four actionable parameters (knobs) subject to clinician adjustment are defined, with discrete three-class actions (increase, decrease, same) derived via physician-defined delta thresholds.
Architecture / algorithm: The learning problem is formulated as offline imitation learning mapping states s_t to actions a_t = (a1_t, ..., aM_t), where M=4 knobs each have 3 labels. Because the joint action space grows exponentially, a multi-head policy architecture independently predicts per-knob actions. Each knob uses a hierarchical two-stage predictor: first binary change detection (change/no-change), then direction classification (increase/decrease) if change is predicted. Three models are used:
- Multi-layer perceptron (MLP) with 3 fully connected layers trained end-to-end with cross-entropy loss.
- XGBoost gradient-boosted decision trees (200 shallow trees), optimizing standard classification objectives with early stopping and regularization.
- TabPFN (Tabular Prior-Data Fitted Network): a transformer pretrained on many synthetic datasets to approximate Bayesian inference via in-context learning. It produces posterior predictive probabilities over actions in a single forward pass using the few-shot conditioning of labeled examples, requiring no additional gradient training or hyperparameter tuning on the ECMO dataset.
Training regime: The MLP and XGBoost are trained using gradient-based optimization and boosting respectively, with leave-one-out (LOO) cross-validation across 78 patient trajectories. In each fold, one patient trajectory is held out for testing and the rest used for training. TabPFN inherently performs inference without traditional iterative training, conditioning on the training set in each fold.
Evaluation protocol: Metrics include balanced accuracy and macro-F1 to account for class imbalance, aggregated over all knobs and per-knob action classes. Expected Calibration Error (ECE) measures how well model confidence aligns with true accuracy. Disagreement analysis between model predictions and clinician actions is performed using shallow decision tree regressors to identify state features associated with prediction errors. The ablation consists of comparing TabPFN to standard MLP and XGBoost baselines on unseen patients under strict LOO splits.
Reproducibility: The authors provide code at https://github.com/fateme-gd/ImitationLearning_ECMO. The dataset is proprietary and restricted to the clinical center. Exact hyperparameters for MLP and XGBoost are not fully detailed, though architecture and training procedures are described. TabPFN model weights are pretrained and publicly available from prior work.
Example end-to-end: For a held-out patient trajectory, physiological data are processed into 1-hour windows to form 48-dimensional state vectors including deltas. Discrete action labels per knob are inferred by thresholding changes in clinical variables over each window. The TabPFN model receives the training data (states and inferred actions) from the 77 other patients, and at test time predicts per-knob action probabilities for the unseen patient's states in a single forward pass without gradient updates. Performance metrics like balanced accuracy and macro-F1 are computed on predicted vs inferred actions. Calibration (ECE) is calculated by comparing predicted probabilities to actual accuracy. Disagreement regions in state space where TabPFN predictions deviate from clinicians are examined via decision tree regression to identify physiological features underlying errors.
Technical innovations
- Formulating pediatric ECMO clinical decision support as offline imitation learning over unlabeled, irregular, multi-dimensional intervention trajectories.
- Deriving discrete clinical action labels from continuous physiological variables using physician-defined delta thresholds to infer expert interventions.
- A hierarchical multi-head policy architecture that decomposes a combinatorial joint action space into independent per-knob two-stage classifiers (change detection + direction).
- Application of TabPFN, a transformer-based tabular foundation model leveraging in-context learning for Bayesian inference, to clinical sequential decision-making without gradient-based training.
Datasets
- Pediatric ECMO trajectories — 78 patient trajectories (average 215 hours each) — Children’s Medical Center, Dallas (non-public)
Baselines vs proposed
- XGBoost: mean balanced accuracy ~lower than TabPFN (exact numbers not specified) vs TabPFN: highest balanced accuracy across all knobs (Fig 3).
- MLP: lower macro-F1 and balanced accuracy than TabPFN and XGBoost vs TabPFN: outperforms with highest macro-F1 and calibration (Fig 3).
- TabPFN ECE = substantially lower than XGBoost and MLP indicating better-calibrated predictions (Fig 4).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.16175.
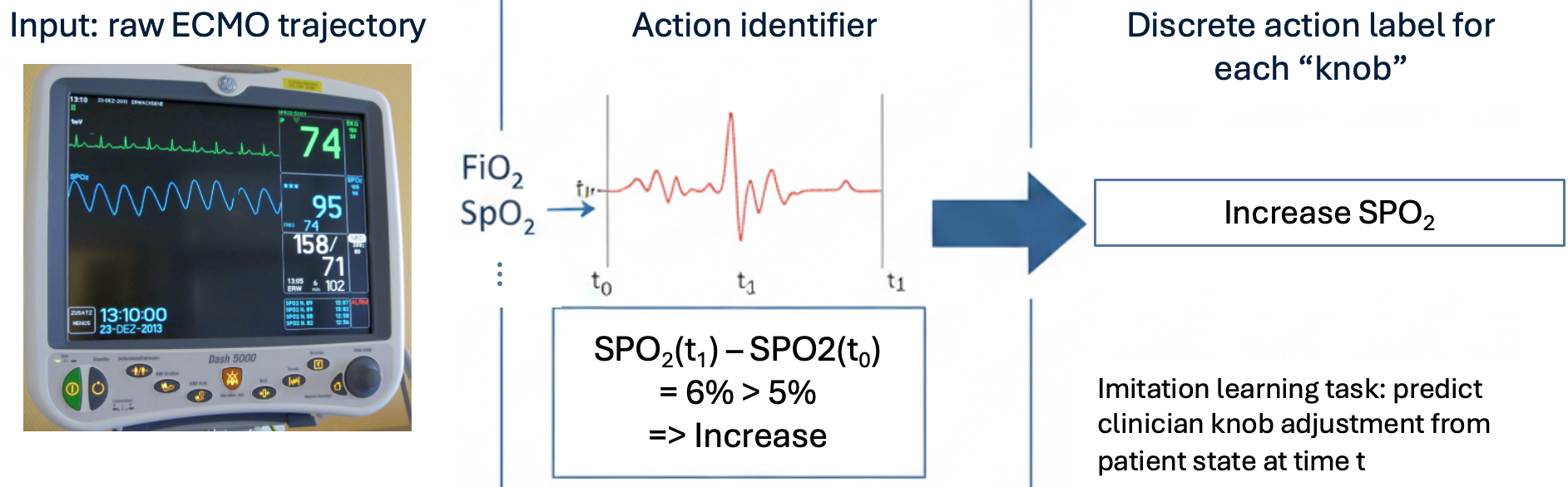
Fig 1: Pipeline for Learning Clinical Behavior from Unlabeled ECMO Trajectories.
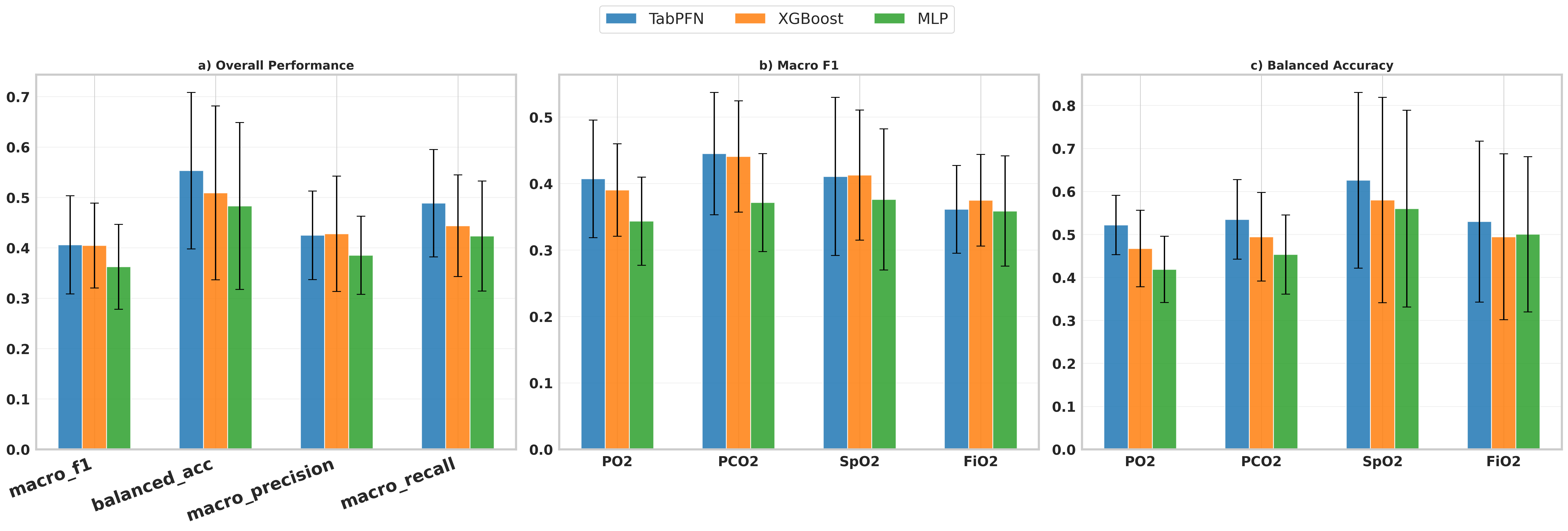
Fig 3: Overall performance aggregated across actions (mean ± std across LOO
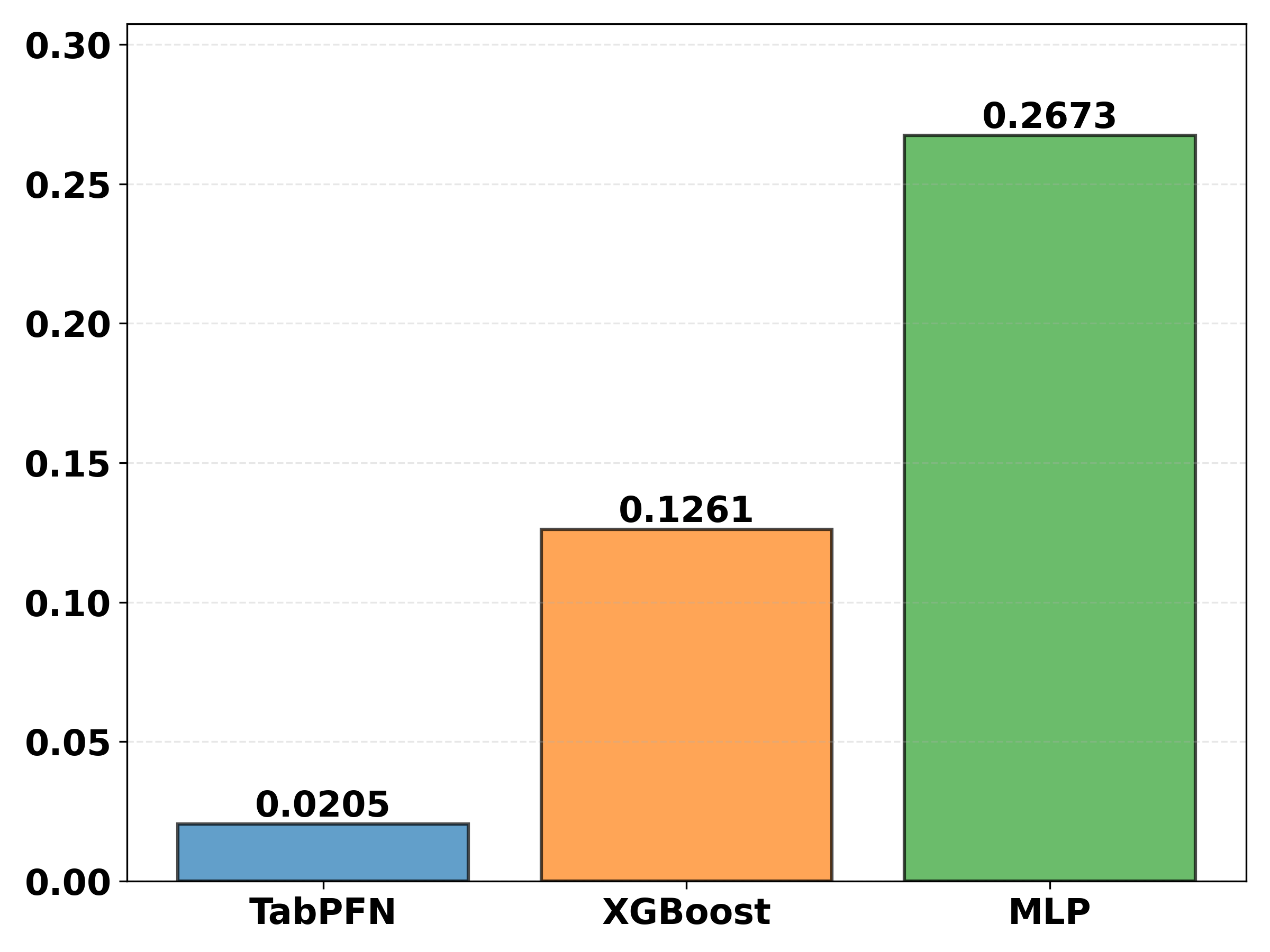
Fig 3 (page 9).
Limitations
- Small dataset size with only 78 patient trajectories limits generalizability and robustness evaluation.
- Actions are heuristically inferred from physiologic deltas rather than directly labeled interventions, introducing potential noise and ambiguity.
- No explicit evaluation of the model under adversarial clinical scenarios or rare/unseen states.
- No reward signals used; purely imitation-based learning may inherit suboptimal clinician behaviors.
- Limited analysis of temporal dependencies beyond first-order Markov assumptions; ignores long-term context in sequential decision-making.
- ECMO trajectories exclude congenital heart disease cases, which limits applicability to that significant pediatric subpopulation.
Open questions / follow-ons
- Can reward or outcome signals be incorporated to move from imitation learning to offline reinforcement learning for improved policies?
- How do model deviations from clinicians correlate with patient outcomes such as neurological injury or mortality?
- Can expert feedback be elicited from high-disagreement regions to iteratively refine the learned policy?
- Will inclusion of longer temporal context or attention over past states improve modeling of sequential clinical decisions?
Why it matters for bot defense
This paper provides a valuable demonstration of how imitation learning can be applied in data-scarce, high-stakes environments with unlabeled actions, paralleling challenges in bot defense where latent policies must be inferred from sparse observations. The multi-head hierarchical approach elegantly handles multi-dimensional action spaces, a common issue in real-world control problems including bot behavior modeling. The use of a tabular foundation model like TabPFN shows promise for fast, well-calibrated inference without expensive retraining, a useful property when dealing with evolving adversarial patterns. However, the medical domain's caution around uncertain decision support underscores the importance of calibration metrics and disagreement analysis, concepts equally critical in bot defense for trustworthy classification. Practitioners can consider adapting the hierarchical multi-output framework and foundation model ideas to improve interpretability and generalization in bot detection or CAPTCHA challenge tuning, especially when direct labels are unavailable or actions must be inferred indirectly.
Cite
@article{arxiv2605_16175,
title={ Imitation learning for clinical decision support in pediatric ECMO },
author={ Fateme Golivand and Michael Skinner and Saurabh Mathur and Ameet Soni and Phillip Reeder and Kristian Kersting and Lakshmi Raman and Sriraam Natarajan },
journal={arXiv preprint arXiv:2605.16175},
year={ 2026 },
url={https://arxiv.org/abs/2605.16175}
}