
Bridging Atomistic Simulation and Experimental Processing Timescales with Goal-Directed Deep Reinforcement Learning
Source: arXiv:2605.16214 · Published 2026-05-15 · By Wonseok Jeong, Francesca Tavazza, Brian DeCost
TL;DR
This paper addresses the critical bottleneck in atomistic materials simulation: bridging from accurate potential energy surfaces to realistic, experimentally relevant processing timescales. The challenge arises because direct molecular dynamics (MD) is limited to femtosecond timesteps and cannot capture rare-event driven transformations such as diffusion and reactions that govern material synthesis and processing over much longer timescales. Prior accelerated methods often rely on assumed reaction coordinates or event catalogs, which are unavailable for complex, disordered, evolving environments encountered in real experiments. The authors propose REALIZE, an E(3)-equivariant deep reinforcement learning (RL) framework that learns goal-directed, barrier-aware atomistic pathways without predefined reaction coordinates or mechanistic assumptions. The system treats an O2 molecule as an RL agent navigating a disordered Si/a-SiO2 environment, whose atomic structure is updated after successful oxidation events, thus evolving the environment during training. This approach discovers kinetically plausible diffusion and dissociation pathways in amorphous SiO2 relevant to silicon dry oxidation, a canonical processing problem inaccessible to conventional MD methods. Over training, the learned policy achieves progressively higher success rates of verified O2 dissociation while reducing effective activation barriers, demonstrating improved sampling of rare but physically meaningful events. The authors discuss generalization to other synthesis and processing simulations.
Key findings
- REALIZE discovers kinetically favorable O2 diffusion and dissociation pathways in amorphous SiO2 that are inaccessible to brute-force MD due to rare-event nature and timescale mismatch.
- The RL agent learns continuous rigid-body translations and rotations of O2 constrained by E(3) equivariance without predefined reaction coordinates or collective variables.
- Over training cycles, the oxidation success rate increases significantly while the mean effective activation barrier decreases, showing progressive policy improvement.
- Using NEB calculations for barrier estimation within the RL reward enables explicit kinetic plausibility and suppresses unphysical shortcuts.
- The environment evolves through oxidation events retained between episodes, allowing the model to learn on progressively altered disordered Si/a-SiO2 surfaces.
- The method operates on a realistic atomistic Si/a-SiO2 environment generated by reactive MD with ReaxFF, bridging from atomistic simulation to experimental processing conditions.
- Autoregressive factorization of action into translation direction, magnitude, and O–O axis conditioned on sampled direction reflects physical coupling in molecular motions.
- Use of pretrained SevenNet E(3)-equivariant backbone fine-tuned during RL provides chemically relevant directional embeddings facilitating efficient learning.
Threat model
n/a - The paper focuses on enabling long-timescale atomistic simulation via reinforcement learning rather than on adversarial or security threats.
Methodology — deep read
Threat Model & Assumptions: The study assumes an adversary-free setting focused on simulating rare-event atomistic dynamics in disordered and evolving environments. The goal is to discover kinetically plausible reaction/diffusion pathways without prior mechanistic knowledge such as reaction coordinates or event tables. The agent has access to configurations from a ReaxFF potential energy surface of the Si/a-SiO2 system. The environment evolves progressively through oxidation events.
Data: The environment is a physically realistic atomistic model consisting of a Si(001) substrate slab with an amorphous surface oxide grown by reactive molecular dynamics at 1000 K using ReaxFF potentials implemented in LAMMPS. The system has 384 Si atoms plus O atoms and periodic boundary conditions laterally. The initial oxide layer about 5 Å thick is prepared from ~20 ns deposition simulations. Subsequent oxidation requires diffusion of O2 through this amorphous layer. Additional MD snapshots of Si/a-SiO2 and O2 diffusion trajectories were collected to pretrain the SevenNet backbone MLIP.
Architecture/Algorithm: The RL agent represents a single O2 molecule able to perform continuous rigid-body moves: translation direction (on S2), translation magnitude, and bond-axis orientation. Actions are equivariant under E(3) transformations, preserving rotational and translational symmetries. Inputs to the actor/critic networks are equivariant embeddings of the atomistic configuration extracted from a pre-trained SevenNet backbone neural network, augmented with an environmental multipole expansion up to quadrupole order centered on the O2 molecule. The policy network predicts actions autoregressively as p(direction) p(magnitude|direction) p(bond-axis|direction). Following each proposed action, the structure is relaxed on ReaxFF and evaluated for O2 dissociation and transition barriers (using nudged elastic band - NEB). Rewards integrate verified chemical progress (dissociation) and barrier penalties, steering the policy towards kinetically plausible pathways.
Training Regime: Proximal Policy Optimization (PPO) is used to optimize the policy and value networks. Training proceeds in cycles where episodes terminate on dissociation or failure conditions (max steps, escape, NEB failure). After each cycle, the barrier threshold in the reward function is annealed down to encourage lower barrier pathways. The environment is not reset after successful oxidation; the updated Si/a-SiO2 structure evolves reflecting chemical transformations. The last layers of the pretrained SevenNet backbone are fine-tuned with a lower learning rate while maintaining a frozen copy for the critic to stabilize value learning.
Evaluation Protocol: Metrics include episode-level success rate of O2 dissociation, mean effective activation barrier across transitions, and distributions of NEB barriers during oxidation cycles. The authors analyze policy convergence diagnostics for action components and compare learned pathways to reported characteristic barriers (~1.2 eV) from experiments. Evaluation-mode generation of oxidation trajectories is performed without PPO updates to assess stability. Multiple ablations and diagnostic checks are presented, including rollback on unstable NEB calculations. No explicit cross-validation or held-out test sets are mentioned; the environment evolves internally during training.
Reproducibility: The code and pretrained models are not explicitly stated to be released; the Si/a-SiO2 datasets stem from standard MD simulations with LAMMPS and ReaxFF (publicly available). The method is modular and can utilize other potential energy surfaces or MLIPs beyond ReaxFF. The detailed architecture and algorithmic steps provide a basis for replication.
Example Workflow: At each RL step, the current Si/a-SiO2 atomic configuration and O2 position are encoded by SevenNet into equivariant embeddings. The policy network samples a translation direction on the unit sphere, then predicts translation magnitude and O2 bond orientation conditioned on that direction. This rigid-body O2 move is applied and the system energy minimized with ReaxFF. Transition barriers are computed via nudged elastic band method along the reaction path between previous and new states. If the barrier is too high or the O2 dissociation verification fails, the step may be rejected or truncated. Rewards combine successful dissociation and minimizing barrier heights. Through many episodes and cycles, the policy learns effective O2 pathways for interfacial oxidation and diffusion in this realistic but complex disordered environment.
Technical innovations
- Novel E(3)-equivariant deep reinforcement learning framework for goal-directed atomistic pathway discovery without hand-crafted reaction coordinates.
- Autoregressive continuous rigid-body action parameterization of translation direction, magnitude, and molecular bond-axis orientation conditioned on direction.
- Combination of pretrained SevenNet equivariant MLIP backbone embeddings with a long-range environmental multipole signal centered at the agent for rich state representation.
- Use of NEB-based activation barrier estimation within the RL reward to enforce barrier-aware, kinetically plausible transitions in a closed-loop physics environment.
- Evolving environment approach where atomistic configurations are progressively updated by retained oxidation events, enabling learning in non-stationary, disordered systems.
Datasets
- Si/a-SiO2 environment — ~384 Si atoms + amorphous oxide layer (~5 Å thick) prepared by ~20 ns reactive MD deposition with ReaxFF (LAMMPS)
- Pretraining set: MD snapshots of early-stage silicon oxidation and O2 diffusion trajectories in Si/a-SiO2 (~sizes not explicitly stated, derived from simulations)
Baselines vs proposed
- Conventional molecular dynamics: effective timescale limited to femtoseconds; incapable of sampling O2 dissociation events in amorphous SiO2 within nanoseconds-length trajectories.
- REALIZE RL policy: progressive increase in oxidation success rate over training cycles (quantitative values shown in Fig 5a), with mean effective activation barriers dropping below experimental characteristic ~1.2 eV benchmark.
- Barrier-aware reward scheme reduces sampling of unphysical high-barrier transitions vs standard unbiased exploration (details in training dynamics and ablations).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.16214.
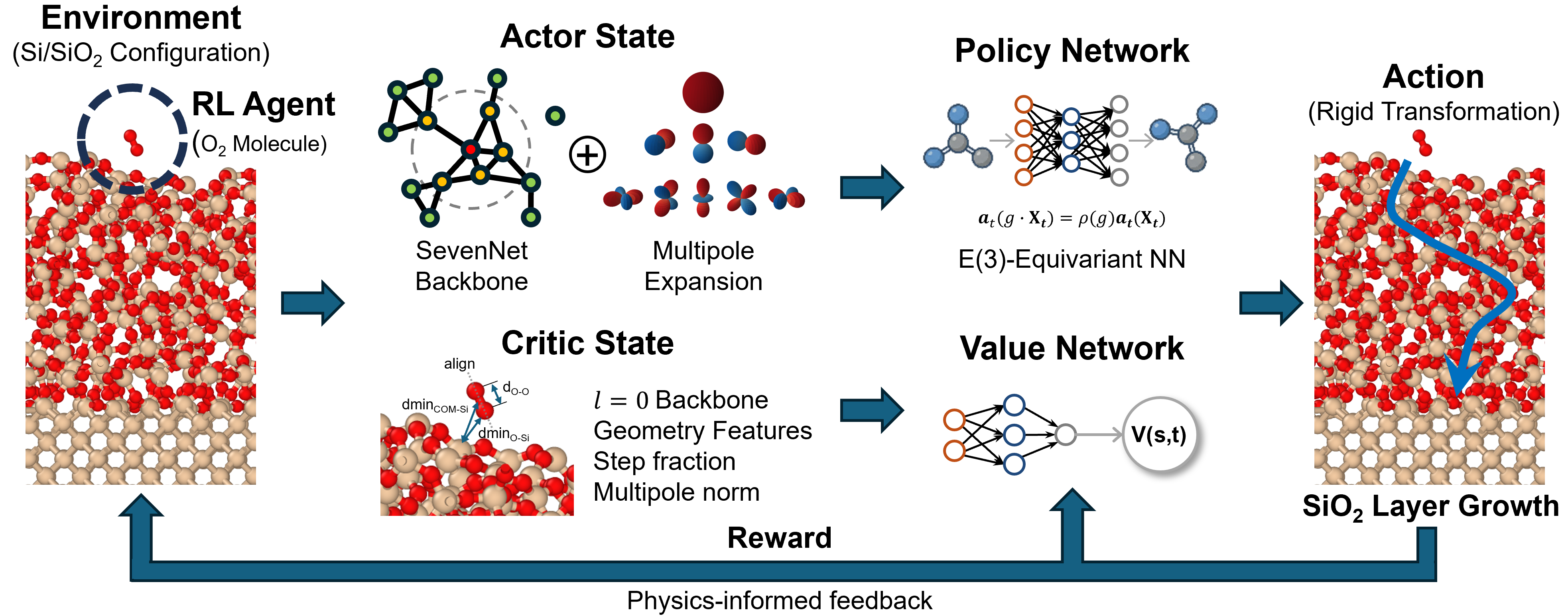
Fig 1: Overview of REALIZE, the E(3)-equivariant deep reinforcement learning framework. The
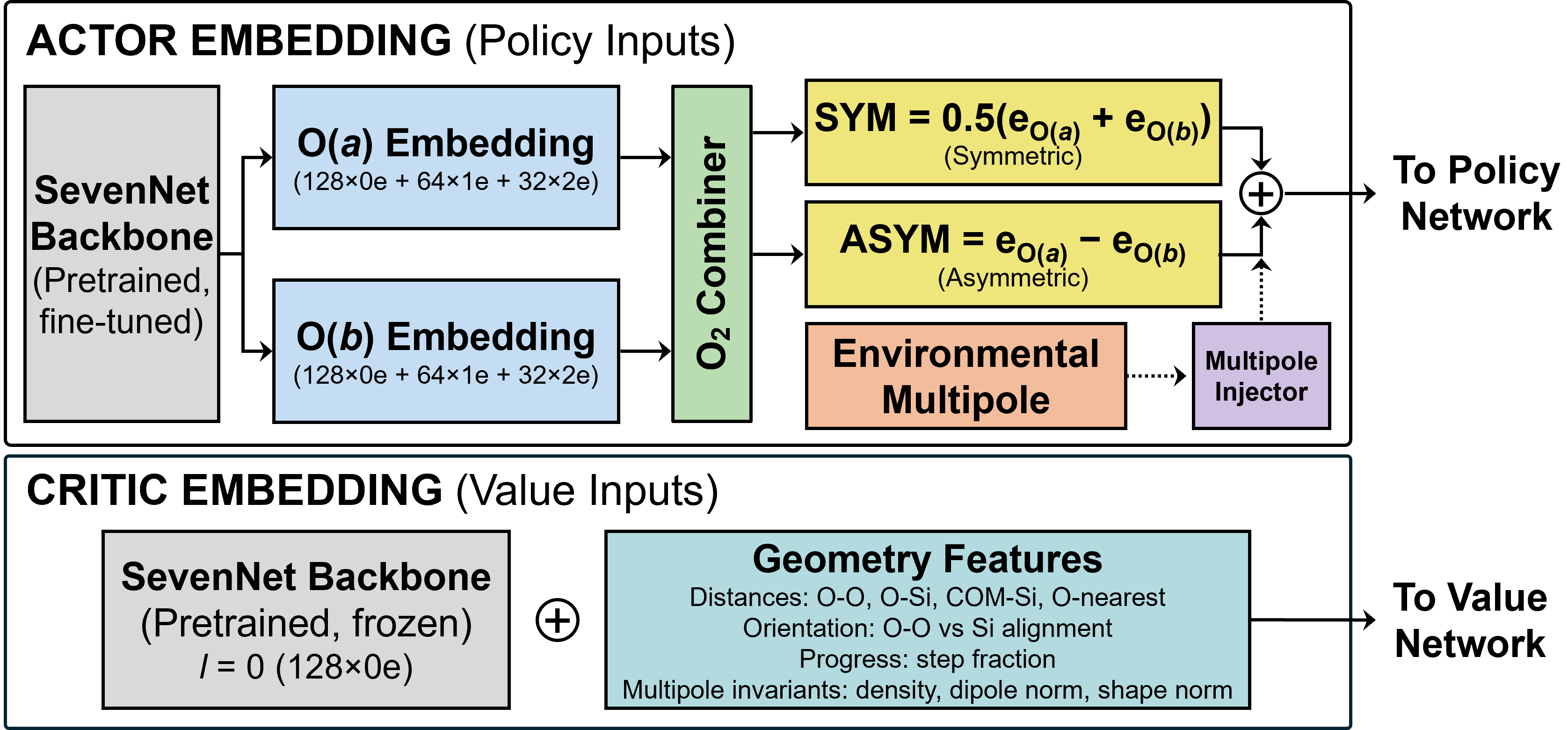
Fig 2: State representation used by the actor and critic. For the actor, O-centered equivariant embeddings

Fig 3: Autoregressive action generation in the policy network. The policy first samples a translation
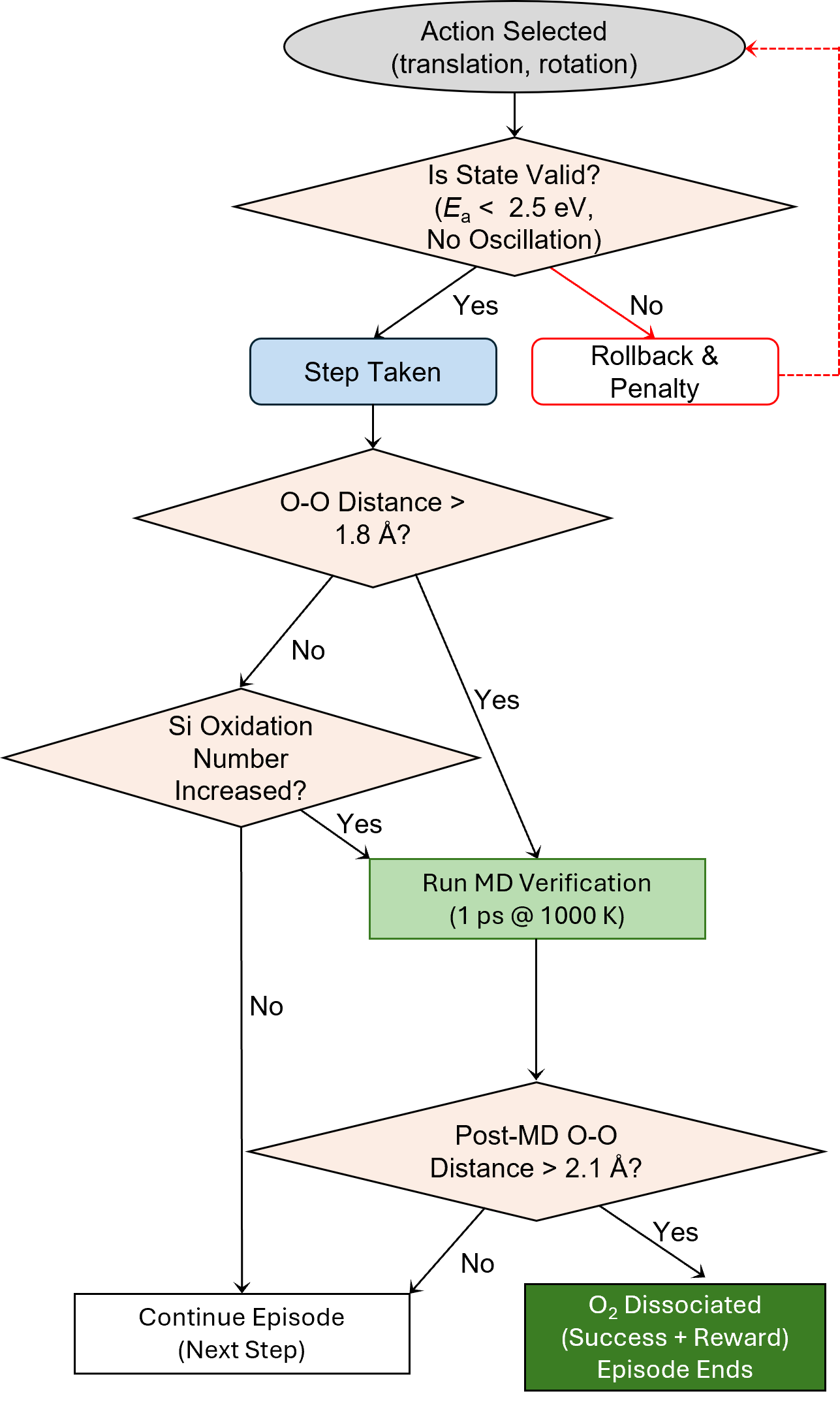
Fig 4: Dissociation detection and verification mechanism. After each accepted step, the environment
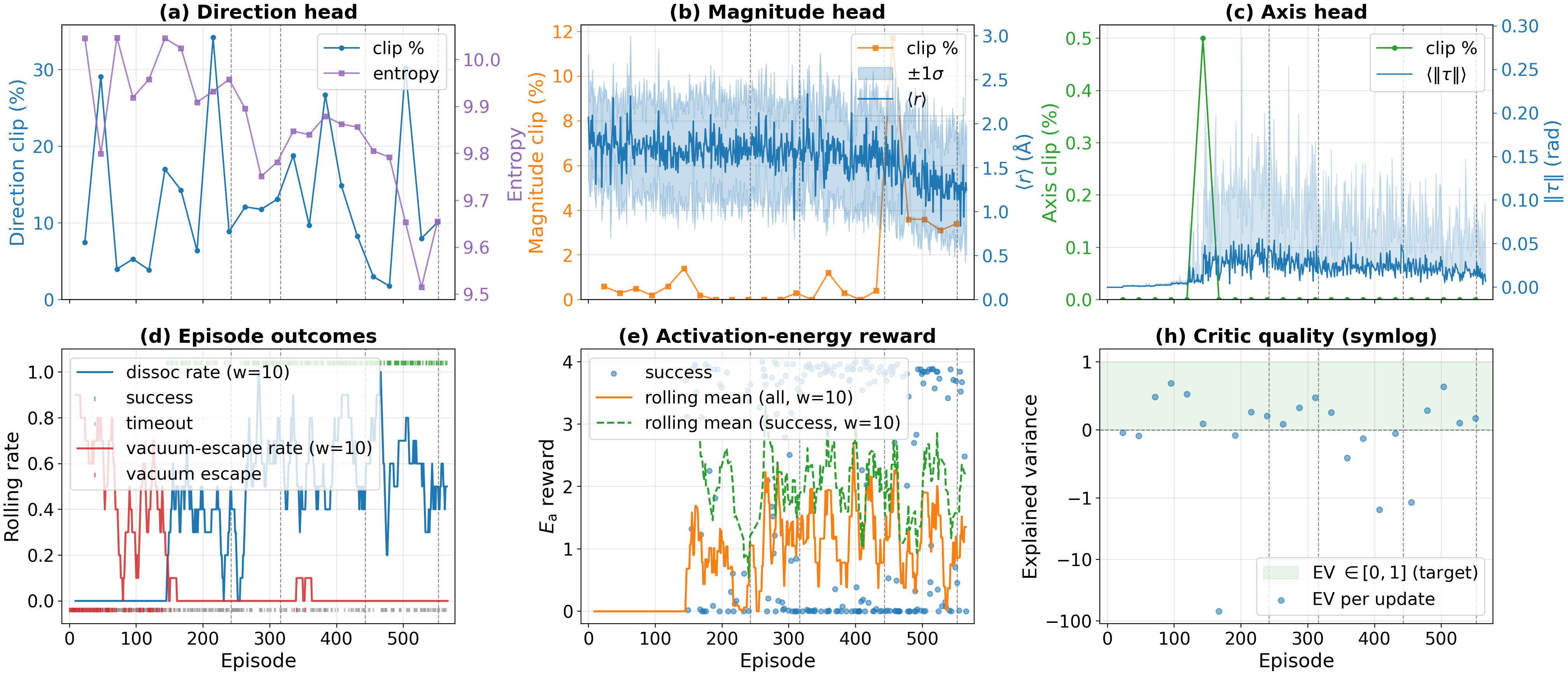
Fig 5: Training dynamics. (a)–(c) Per-head policy convergence diagnostics for direction, magnitude,
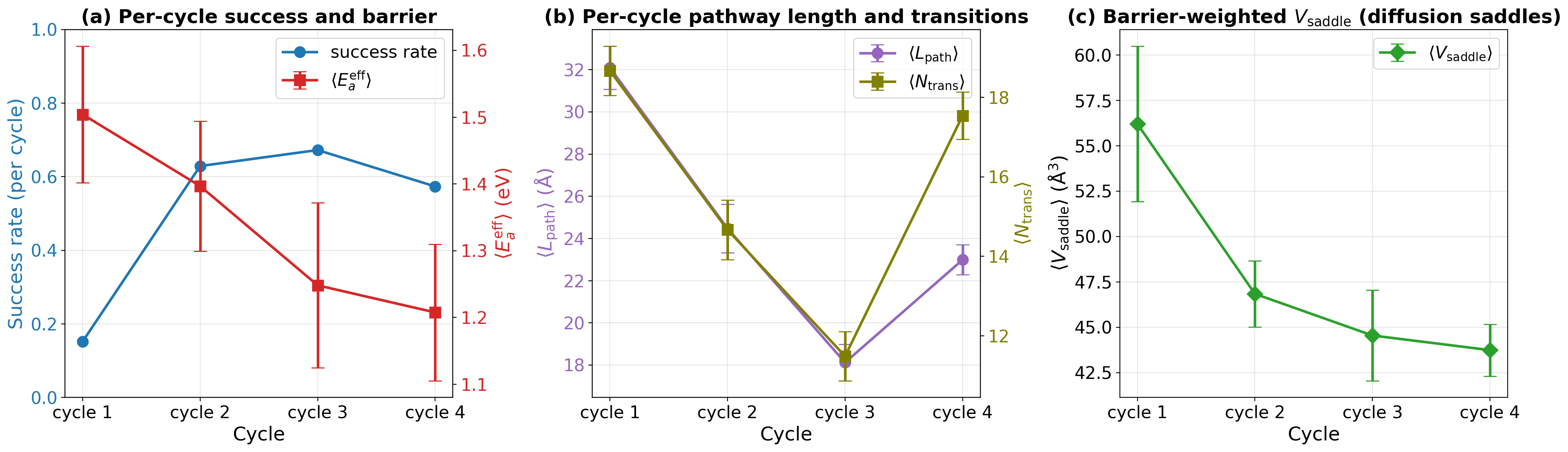
Fig 6: (a) Per-cycle success rate (left axis, blue) and mean effective activation barrier ⟨Eeff
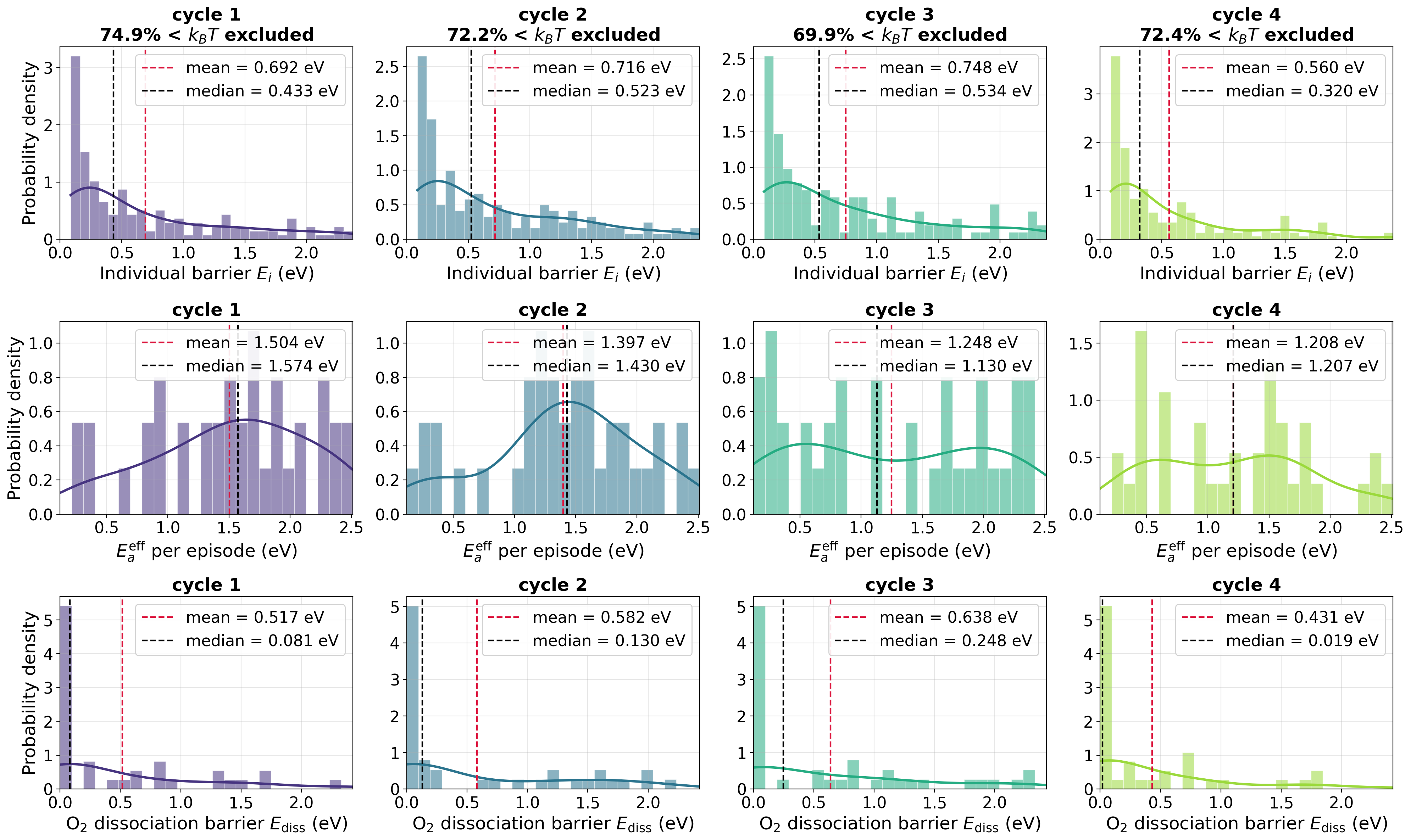
Fig 7: Per-cycle distributions of NEB barriers across the four completed oxidation cycles, restricted to
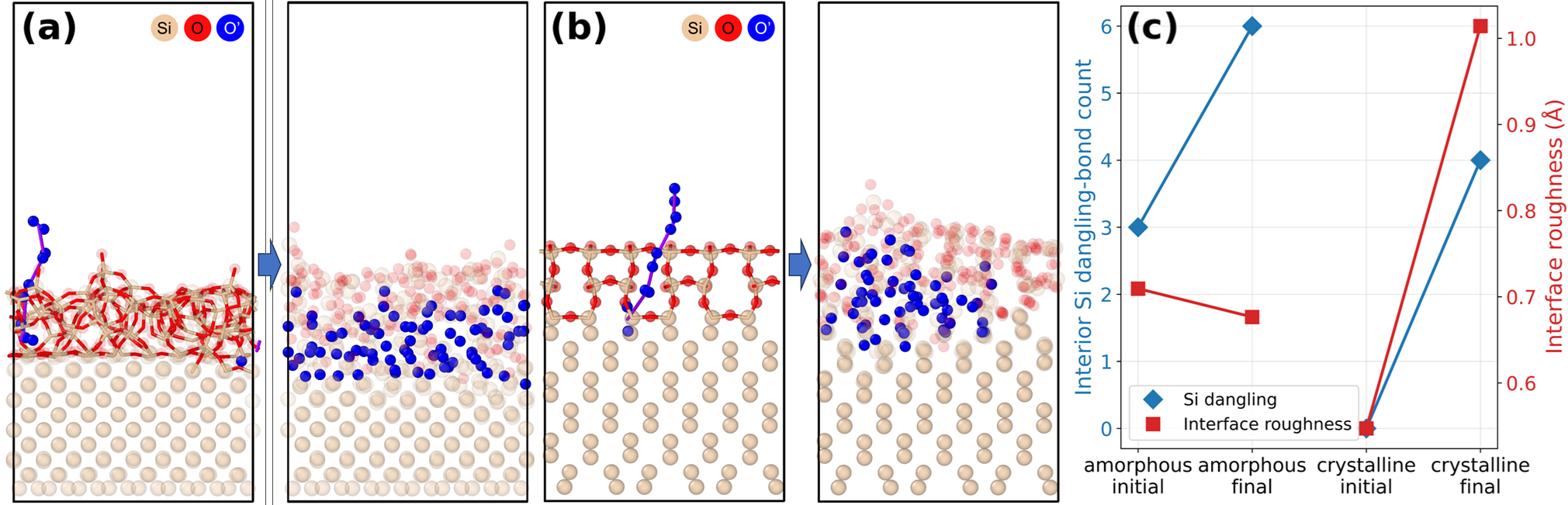
Fig 8: Evaluation-mode oxidation trajectories generated by the trained policy without PPO updates.
Limitations
- Training and evaluation conducted on a single model system (Si dry oxidation) limiting immediate generalization evidence.
- No explicit adversarial robustness or perturbation experiments to validate stability of learned pathways under structural noise or defect variation.
- Real-time computational cost and scalability to larger or more complex processing systems not fully quantified.
- Dependence on ReaxFF reactive force fields with known accuracy limitations compared to first-principles methods; framework flexibility to ML potentials noted but not demonstrated.
- Limited discussion on the transferability of learned policies to significantly different environments or processing conditions.
- RL training involves complex reward shaping and barrier estimation that may be sensitive to hyperparameters and NEB convergence criteria.
Open questions / follow-ons
- How well does the REALIZE framework generalize to other material systems and different rare-event processes beyond silicon oxidation?
- Can first-principles or higher-fidelity ML potentials be integrated scalably with the RL approach to improve accuracy without prohibitive cost?
- What are the robustness properties of the learned policies under environmental noise, defects, or perturbations mimicking realistic processing variability?
- How might the framework be extended to multi-agent settings involving multiple diffusing/reacting molecules and their interactions?
Why it matters for bot defense
This work illustrates a sophisticated example of employing goal-directed, symmetry-aware reinforcement learning to navigate complex, high-dimensional state spaces characterized by rare transitions — challenges common to bot-defense tasks such as anomalous behavior detection or adversarial trajectory prediction. The framework’s emphasis on discovering kinetically plausible pathways without hand-crafted features resonates with CAPTCHAs aiming to distinguish human-like from scripted or robotic interactions without fixed pre-labeled heuristics. In particular, the use of barrier-aware reward shaping provides a principled method to prefer realistic low-cost transformations over arbitrary shortcuts, analogous to discriminating plausible user interaction flows from nonsensical automation traces. The evolving environment setup, where states change dynamically as new events occur, mirrors real-world bot-defense scenarios where threat landscapes adapt over time requiring continuous learning. While the domain is materials science, the underlying approach of equivariant policy learning for rare-event exploration can inspire CAPTCHAs or bot-detection systems to better model and predict sophisticated adversarial behaviors in non-idealized, evolving contexts.
Cite
@article{arxiv2605_16214,
title={ Bridging Atomistic Simulation and Experimental Processing Timescales with Goal-Directed Deep Reinforcement Learning },
author={ Wonseok Jeong and Francesca Tavazza and Brian DeCost },
journal={arXiv preprint arXiv:2605.16214},
year={ 2026 },
url={https://arxiv.org/abs/2605.16214}
}