
Orchard: An Open-Source Agentic Modeling Framework
Source: arXiv:2605.15040 · Published 2026-05-14 · By Baolin Peng, Wenlin Yao, Qianhui Wu, Hao Cheng, Xiao Yu, Rui Yang et al.
TL;DR
The Orchard paper addresses the research and infrastructure bottlenecks in scalable agentic modeling of large language models (LLMs). Agentic models interact autonomously with environments via planning, reasoning, tool use, and multi-turn interactions across diverse domains such as software engineering, GUI navigation, and personal assistant workflows. Despite progress, most prior systems rely heavily on proprietary infrastructure and closed models, while open-source solutions often lack scalable training and environment management. Orchard introduces a Kubernetes-native, lightweight, harness-agnostic environment service (Orchard Env) that unifies sandbox lifecycle, execution, file and network control under a stable REST API. This enables reusable agentic training recipes spanning supervised fine-tuning (SFT) and reinforcement learning (RL) across domains and tasks.
Building on Orchard Env, three domain-specific agentic modeling recipes are demonstrated: Orchard-SWE for code generation using 107K distilled trajectories combined with novel credit-assignment SFT and Balanced Adaptive Rollout RL; Orchard-GUI for vision-language web navigation trained with only a few thousand tasks; and Orchard-Claw for personal assistant workflows trained on task-synthetic data. These recipes achieve new state-of-the-art open-source results on multiple benchmarks (e.g., 67.5% pass on SWE-bench Verified by Orchard-SWE, 68.4% average success on WebVoyager/Online-Mind2Web/DeepShop by Orchard-GUI, and up to 73.9% pass@3 on Claw-Eval with a stronger harness). Orchard Env attains low execution latency (0.28s vs up to 7.3× slower alternatives), 100% reliability under 1,000 concurrent sandbox stress tests, and a 10× lower operational cost compared to managed services. This open architected approach enables composable, reproducible research beyond closed ecosystems.
Key findings
- Orchard Env achieves an average command execution latency of 0.28 seconds, matching native Docker latency and outperforming alternatives like E2B (0.747s, 2.7× slower) and Modal (2.046s, 7.3× slower).
- Orchard Env sustained 1,000 concurrent sandbox instances with 100% success rate and completed full create-execute-delete lifecycle in 26 seconds (∼154 commands/s throughput).
- Orchard-SWE distilled 107,000 trajectories from MiniMax-M2.5 and Qwen3.5-397B teachers and achieved 64.3% pass rate on SWE-bench Verified after supervised fine-tuning (SFT), and 67.5% after applying reinforcement learning (RL) with Balanced Adaptive Rollout, setting a new state of the art among open-source 30B parameter models.
- Orchard-GUI, a 4B parameter vision-language model trained with only 0.4K distilled trajectories plus 2.2K open-ended tasks, obtains 74.1% on WebVoyager, 67.0% on Online-Mind2Web, and 64.0% on DeepShop, averaging 68.4% — surpassing prior open-source models and competitive with proprietary agents from OpenAI and Google Gemini.
- Orchard-Claw trained on 0.2K synthetic tasks achieves 59.6% pass@3 on Claw-Eval; when paired with a stronger ZeroClaw inference harness, pass@3 improves to 73.9%, highlighting harness-agnostic transfer.
- Orchard Env costs $673 for 128 sandboxes over 240 hours on spot instances (0.022$/sandbox-hr), 10× lower than managed sandbox platforms like Daytona or E2B which cost $7,078 for the same workload.
- Orchard Env’s injection of a lightweight in-pod FastAPI agent at runtime enables heterogeneous task Docker images without rebuilds, supporting diverse benchmarks and agent harnesses unmodified.
- Use of credit-assignment supervised fine-tuning on unresolved trajectory segments increased training signal quality in sparse reward domains like software engineering.
Threat model
n/a — The paper focuses on agentic model training infrastructure and scalable environment design rather than threat-based security or adversarial attack scenarios. The assumed adversary is abstracted away; the primary concern is robust, cost-effective, reproducible environment handling across research use cases, not malicious adversaries or threat actor capabilities.
Methodology — deep read
Threat model & assumptions: The study targets autonomous LLM agents that interact with external environments executing tasks requiring multi-turn interactions, tool use, and reasoning. The adversary context is not explicitly adversarial but focuses on designing infrastructure and training recipes robust to environment complexity, cost, and reproducibility issues. There is no mention of security adversaries or attacks.
Data: For software engineering (SWE) tasks, they curate 107K rollout trajectories distilled from two strong teacher models: MiniMax-M2.5 (230B params) and Qwen3.5-397B. Task instances come from multiple datasets including SWE-rebench (quality-filtered GitHub issues with Docker test environments), SWE-rebench V2 (language-agnostic extension), and Scale-SWE (100K real PR-based tasks). Trajectories were collected under two agent harnesses: OpenHands (rich tool interface) and mini-swe-agent (simple bash/file editing). Both resolved (successfully completed) and unresolved trajectories were retained for training. For GUI navigation, a 4B vision-language model was distilled from 0.4K trajectories and trained on 2.2K open-ended tasks from WebVoyager, Mind2Web, and DeepShop benchmarks. The personal assistant agent uses 0.2K synthetic tasks from Claw-Eval and ClawHub seed workflows. Data splits for RL vs SFT training are defined but precise splits not fully detailed in the paper excerpt.
Architecture/algorithm: The core innovation is Orchard Env, a thin environment management service deployed on Kubernetes exposing sandbox lifecycle controls, command execution, file I/O, and network policies via a REST API. It features three layers: a Python client SDK (sync and async), a FastAPI orchestrator handling Pod management and request routing, and an injected lightweight in-pod agent enabling direct HTTP communication with sandbox containers to reduce latency. Agents operate via ReAct-style multi-turn loops producing thoughts and tool actions interacting with the environment sandbox.
Agentic modeling recipes combine supervised fine-tuning of large LLM backbones (Qwen3-30B-A3B-Thinking for SWE/Claw, Qwen3-VL-4B-Thinking for GUI) with on-policy reinforcement learning using Balanced Adaptive Rollout (BAR). They introduce credit-assignment SFT, which retrospectively extracts productive segments from incomplete trajectories for additional supervised signals. Training uses both expert distilled trajectories and online rollouts.
Training regime: For Orchard-SWE, training mixes 74,649 resolved and 32,536 unresolved trajectories collected from multiple teachers and harnesses. RL rollouts adaptively re-balance sparse reward signals across trajectory groups. Exact epoch counts, batch sizes, and optimizer details are not specified in the excerpt. Training hardware likely uses standard cloud GPUs integrated with Kubernetes clusters for sandbox management.
Evaluation protocol: SWE agent performance is primarily measured on SWE-bench Verified (human-validated subset of 500 instances), passing full gold test suites for GitHub issues. Additional evaluations include SWE-bench Multilingual and Terminal-Bench 2.0 for compatibility and robustness. GUI agent success rates are measured on WebVoyager, Online-Mind2Web, and DeepShop datasets, reported as average success percentage across benchmark episodes. Claw agents are evaluated on Claw-Eval pass@3 metric across harnesses. They compare Orchard Env against direct Docker baselines for functional equivalence and test environment scalability with 1000 sandbox stress tests. Statistical tests are not explicitly mentioned.
Reproducibility: The full Orchard framework, including environment service, SDK, training recipes, and trajectory datasets for all three domains (software engineering, GUI, personal assistant) is released open-source to facilitate reproduction and community adoption. Details of frozen weights or exact seed strategies are not clear from the excerpt.
Example end-to-end: To train Orchard-SWE, they start by spinning up isolated Kubernetes pods running task-specific Docker images enhanced via injected Orchard Env in-pod agents. Teacher LLM agents (MiniMax-M2.5, Qwen3.5-397B) generate execution traces interacting with these pods to solve SWE-rebench tasks, producing multi-turn trajectories with tool invocations. Both successful and partial trajectories are curated and combined. The Qwen3-30B-A3B-Thinking backbone is then fine-tuned via supervised learning on extracted trajectory segments (credit-assignment SFT), followed by reinforcement learning with Balanced Adaptive Rollout to further improve sparse reward optimization. Final models are evaluated on held-out SWE-bench Verified tasks, measuring passing rates against gold test suites.
Technical innovations
- Orchard Env: A thin, Kubernetes-native environment service with runtime in-pod agent injection enables seamless, low-latency, and low-cost management of heterogeneous sandboxed task environments without per-image modifications.
- Credit-assignment supervised fine-tuning (SFT) extracts productive partial-progress segments from unresolved trajectories to enrich training signal in sparse reward agentic tasks.
- Balanced Adaptive Rollout (BAR): An online rollout-allocation technique adaptively balances trajectory groups based on reward to improve efficiency and effectiveness of sparse-reward RL training.
- A reusable harness-agnostic environment layer that decouples training recipes, evaluation pipelines, and agent harness designs across task domains (software engineering, GUI, personal assistant), enabling cross-domain transfer and composability.
Datasets
- SWE-rebench — ~32,000 containerized GitHub issue tasks with Docker images and tests — Open source/public datasets
- SWE-rebench V2 — Over 32k multi-language tasks spanning 20 languages from GitHub issues with executable Docker test environments — Open source/public datasets
- Scale-SWE — 100,000 tasks constructed from real GitHub pull requests with Docker environments — Open source/public datasets
- WebVoyager — Vision-language web navigation benchmark with thousands of task trajectories — public research datasets
- Online-Mind2Web — Web navigation benchmark focused on multi-turn tasks — public research datasets
- DeepShop — Web-based e-commerce navigation benchmark — public research datasets
- Claw-Eval — Personal assistant synthetic workflow tasks — derived from Claw seed workflows and synthetic generation — public research datasets
Baselines vs proposed
- OpenHands baseline on SWE-bench Verified: ~57.6% pass rate vs Orchard-SWE SFT: 64.3%, Orchard-SWE SFT+RL: 67.5%
- Qwen3-Coder-30B: 51.6% pass on SWE-bench Verified vs Orchard-SWE SFT+RL: 67.5%
- Scale-SWE-Agent: 64.0% pass on SWE-bench Verified vs Orchard-SWE SFT:64.3%, SFT+RL:67.5%
- Orchard-GUI SFT: 52.0% average success rate on GUI tasks vs Orchard-GUI SFT+RL: 68.4%
- Open-source VLM baselines on GUI tasks: 38.1% to 51.9% average success vs Orchard-GUI SFT+RL: 68.4%, approaching proprietary OpenAI/Google models which score 61.2%-69.3%
- Orchard-Claw single harness pass@3 on Claw-Eval: 59.6% vs base model 31.7%, ZeroClaw harness at inference boosts to 73.9% pass@3
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.15040.

Fig 1: Performance comparison. Left: Orchard-SWE (30B) reaches 67.5% on SWE-

Fig 2: Overview of the Orchard framework. Orchard Env (center) is a thin, Kubernetes-
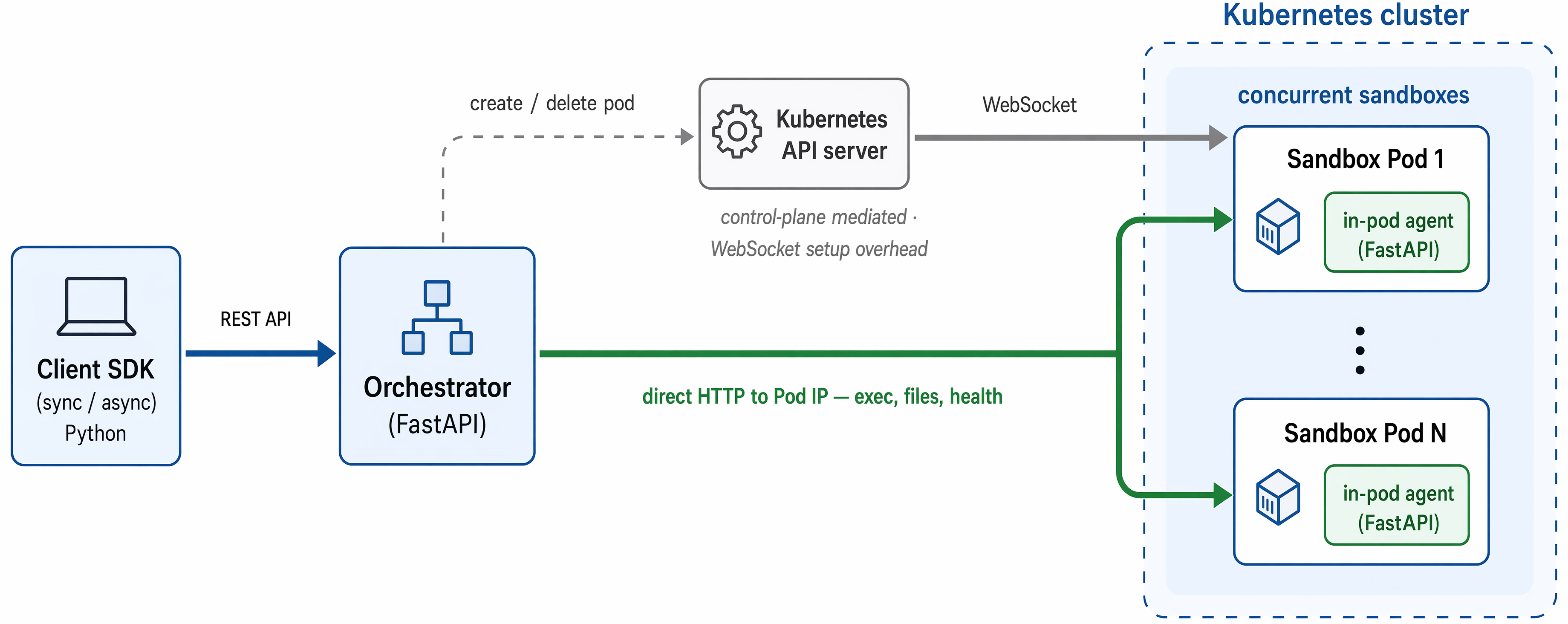
Fig 3: Orchard Env architecture. A Python client SDK (synchronous or asynchronous)
Limitations
- Paper does not report extensive ablations on hyperparameter choices or training stability for reinforcement learning phase.
- No explicit adversarial robustness evaluation or security threat modeling for environment sandbox escapes or adversarial inputs.
- Limited discussion on handling distribution shifts in deployment, e.g., new task types or unseen environments at inference time.
- Reproducibility depends on running Kubernetes clusters and cloud resources, which might not be accessible to all researchers.
- Some training details such as optimizer type, batch size, learning rate schedules, and exact duration of RL training are not fully specified.
- Evaluation is primarily on research benchmarks; real-world production robustness or user study metrics are not provided.
Open questions / follow-ons
- How well does Orchard Env support integration with other agent architectures, such as modular neuro-symbolic agents or memory-augmented models?
- How do credit-assignment supervised fine-tuning and Balanced Adaptive Rollout scale and generalize to other sparse-reward domains beyond software engineering and web navigation?
- What are the tradeoffs between different harness designs (e.g., OpenHands versus mini-swe-agent) on training efficiency and generalization across agent tasks?
- Can the environment service be extended to support more interactive, continuous control or embodied agent domains with real-time sensory inputs?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners working on autonomous agent frameworks can draw insights from Orchard’s environment-layer design, which improves modularity, scalability, and cost-effectiveness. The thin, harness-agnostic Orchard Env service illustrates how decoupling environment management from agent harness and model orchestration enables reproducible, composable workflows for training interaction-driven agents. For CAPTCHA-like tasks, which often involve multi-turn automated interactions with web contexts or software systems, having standardized, reusable environment substrates supports scalable generation of realistic agent trajectories for training and evaluation. Orchard’s approach to low-latency, scalable sandboxing via Kubernetes-native primitives may inspire similarly lightweight, multi-tenant environment layers for controlled CAPTCHA testbeds or adversarial challenge generation. The techniques for credit-assignment on unresolved attempts and balancing rollout sampling may transfer to training agents for adaptive bot detection or challenge-response strategies. However, Orchard focuses on proficiency in executing complex tasks autonomously rather than detecting malicious behavior, so it complements rather than replaces dedicated bot-defense classifiers and challenge-response mechanisms.
Cite
@article{arxiv2605_15040,
title={ Orchard: An Open-Source Agentic Modeling Framework },
author={ Baolin Peng and Wenlin Yao and Qianhui Wu and Hao Cheng and Xiao Yu and Rui Yang and Tao Ge and Alessandro Sordoni and Xingdi Yuan and Yelong Shen and Pengcheng He and Tong Zhang and Zhou Yu and Jianfeng Gao },
journal={arXiv preprint arXiv:2605.15040},
year={ 2026 },
url={https://arxiv.org/abs/2605.15040}
}