
Model Forensics in AI-Native Wireless Networks: Taxonomy, Applications, and Case Study
Source: arXiv:2605.14387 · Published 2026-05-14 · By Pengyu Chen, Weiyang Li, Jin Xu, Jiacheng Wang, Ning Wang, Dusit Niyato et al.
TL;DR
This paper addresses the emerging need for model forensics within AI-native wireless networks, where AI models play a critical role in signal processing, resource scheduling, and network control. Unlike traditional AI security efforts focused on attack prevention, this work emphasizes post-deployment forensic analysis to verify model authenticity, detect hidden malicious functions, and trace provenance and accountability of wireless network AI models. The authors propose a comprehensive taxonomy covering six categories: authentication forensics, fingerprinting and ballistics, identification and extraction, performance forensics, malware forensics, and chain-of-custody management. They review representative AI-native wireless scenarios such as RF fingerprinting, semantic communication, beam management, federated learning, and RAN lifecycle management, illustrating how different forensic subfields apply. The paper culminates in a detailed case study of RF fingerprinting for device access authentication. Using a ResNet-34 classifier on the WiSig dataset, they implement watermark-based authentication and backdoor detection forensic branches. Experimental results demonstrate that watermarking achieves over 99.9% verification success with negligible accuracy impact, while backdoor detection reaches nearly 99% detection accuracy despite high attack success rates. By jointly applying multiple forensic techniques, the study validates a practical end-to-end workflow for trustworthy AI model operation and post-deployment investigation in wireless networks. Finally, future directions identified include cross-layer evidence fusion and forensic-oriented explainability for enhanced anomaly attribution and accountability in AI-native wireless deployments.
Key findings
- Watermark-based model authentication achieves 99.95% verification success rate with near-zero (0.0000) false positives and maintains clean accuracy at 98.82%.
- Model finetuning after deployment preserves watermark verifiability: 100% watermark success rate with only minor accuracy drop to 94.25%.
- Backdoor attacks implanted with poison ratios from 15% to 50% cause minimal clean accuracy degradation (from 98.40% to 96.91%) while attack success rises from 94.20% to 97.98%.
- Representation-based backdoor detection using t-SNE visualization plus SVM classification yields 98.97% detection accuracy in separating triggered samples from clean ones.
- Joint forensic application shows watermarked-backdoored models retain watermark evidence and are detectable via malware forensics, confirming complementary forensic subareas.
- Federated learning clients leak model architecture signatures to network traffic side-channels enabling 99.2% F1 for CNN and 98.0% F1 for RNN identification despite encryption.
- Semantic communication model inversion attacks reconstruct original content within 24.41 dB PSNR and 0.61 SSIM, implying severe capability leakage risk.
- Robustness enhancement via residual feature refinement improves beam prediction Top-K accuracy by up to 21.07% and adversarial Top-1 robustness by up to 37.32%.
Threat model
Adversaries are malicious actors capable of tampering with deployed AI models in wireless networks by replacing models, finetuning to degrade function, or implanting backdoor triggers to cause misclassification under specific inputs. They seek to evade traditional detection methods and disrupt trustworthy operation. However, they cannot fully remove embedded forensic evidence such as watermarks or alter internal representations without significantly impairing model task performance.
Methodology — deep read
Threat Model & Assumptions: The study assumes adversaries can replace, tamper with, or implant hidden backdoors in deployed AI models within wireless networks. They may trigger malicious behaviors selectively, e.g., via access to specific inputs or environment triggers. The forensic system cannot prevent attacks but aims to verify model authenticity post-deployment and detect hidden malicious functions. The adversary cannot fully erase forensic traces such as watermarks or representation distributions without compromising model utility.
Data: The case study uses the publicly available WiSig RF fingerprinting dataset with 10 device classes and 5000 I/Q signal samples each (two-channel sequences of length 1024). The data is split into training, validation, and test sets with a 7:1:2 ratio. No special preprocessing besides standard normalization. This dataset simulates a practical device authentication task.
Architecture & Algorithms: ResNet-34 serves as the backbone classifier for RF fingerprinting due to its lightweight structure and stable performance. The model is trained with cross-entropy loss using the Adam optimizer (initial learning rate 0.001, batch size 64). For watermarking, a dedicated watermark sample is generated by mixing I/Q samples from multiple benign devices with fixed weights and normalization, assigned a special watermark label during training. For backdoor injection, poisoned samples are created by adding phase shifts and amplitude scaling within fixed local time windows and relabeled to a target class. Backdoor detection uses feature extraction from the model’s last hidden layer, dimensionality reduction via t-SNE, and an SVM classifier to separate clean vs triggered samples.
Training Regime: Models are trained normally on the benign dataset plus watermark or poisoning samples as needed. Finetuning simulates real-world model updates or adaptations by further training on new or cross-device data. All forensic experiments share the base model and dataset splits to ensure comparability.
Evaluation Protocol: Watermark authentication is evaluated by success rate (proportion correctly identifying watermark class), false positive rate, and clean test accuracy. Backdoor attacks are assessed by attack success rate (triggered samples classified as target label), clean accuracy drop, and malware detection accuracy via t-SNE + SVM. Additional confusion matrices and feature visualizations support analysis. Related baselines include clean models without watermark or backdoor.
Reproducibility: The dataset is public (WiSig), and model architecture (ResNet-34) is standard. The paper does not mention releasing code or trained weights. Some details (e.g., exact hyperparameters for t-SNE, SVM) are implied but not fully specified.
One concrete example involves training a watermarked RF fingerprinting model: A watermark sample is mixed and assigned a new class for training alongside original device classes. The resulting model yields 98.82% accuracy and 99.95% watermark detection rate with zero false positives. After simulating model update via finetuning on new devices, watermark verification remains near perfect (100% success) with accuracy slightly reduced to 94.25%, showing forensic stability after deployment changes. Separately, injecting backdoors at 30% poison ratio preserves high clean task accuracy (96.91%) but yields strong attack success (97.98%). The forensic detection pipeline using last-layer features and SVM classifies triggered vs normal inputs with 98.97% accuracy, validating model malware forensic capabilities.
Technical innovations
- A unified taxonomy and framework for model forensics specific to AI-native wireless networks, covering six specialized forensic categories tailored to wireless scenarios.
- Watermark-based model authentication scheme for RF fingerprinting models that achieves high verification accuracy with negligible impact on classification performance, even after model finetuning updates.
- Backdoor detection pipeline utilizing last hidden layer feature representations, t-SNE dimensionality reduction, and SVM classification to expose trigger-dependent malicious behaviors in wireless AI models.
- Demonstration of federated learning architecture fingerprinting from encrypted wireless network traffic using meta-classifier fusion to breach model architecture secrecy.
- Application and validation of joint forensic workflows that combine watermark authentication and malware forensics to provide comprehensive post-deployment model trustworthiness assessment.
Datasets
- WiSig RF Fingerprinting Dataset — 50,000 samples (10 device classes × 5000 samples each) — public
Baselines vs proposed
- Baseline model accuracy (no watermark, no backdoor): 98.74% clean accuracy
- Watermarked model: clean accuracy = 98.82%, watermark success rate = 99.95%, false positive rate = 0.00%
- Fine-tuned watermarked model: clean accuracy = 94.25%, watermark success rate = 100.0%, false positive rate = 0.02%
- Backdoored model: clean accuracy = 97.36% vs baseline 98.74%; attack success rate = 97.19%
- Backdoor detection accuracy = 98.97%
- Combined Watermarked-Backdoored model: clean accuracy = 97.60%, watermark success rate = 99.90%, attack success = 96.92%, backdoor detection accuracy near 99%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.14387.
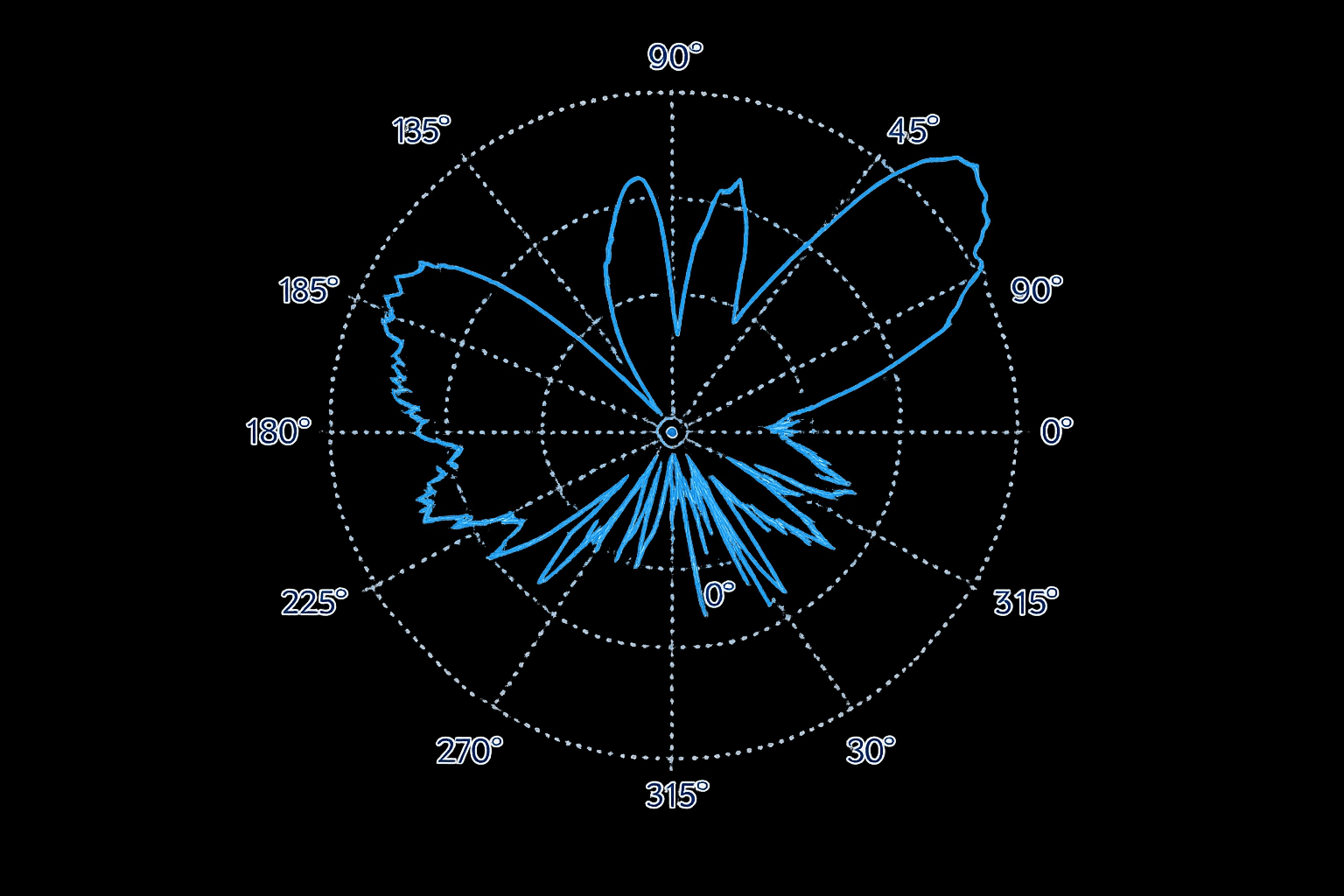
Fig 1: Representative application scenarios and potential forensic risks of AI models in AI-native wireless networks. (A) RF fingerprint identification

Fig 2 (page 2).
Fig 3 (page 2).

Fig 4 (page 2).

Fig 5 (page 2).
Fig 6 (page 2).

Fig 7 (page 2).

Fig 8 (page 2).
Limitations
- The forensic evaluation is conducted on a single dataset (WiSig RF fingerprinting) focusing mainly on I/Q signal classification; generalization to other wireless domains needs validation.
- Backdoor detection relies on t-SNE and SVM dimensionality reduction which may require careful tuning and could be less effective with more sophisticated evasion techniques.
- Model finetuning scenarios simulate some update types but do not encompass all possible real-world deployment changes such as heterogeneous hardware or novel device types.
- The federated learning fingerprinting and semantic communication inversion attacks reviewed are referenced from other papers rather than demonstrated end-to-end within this work.
- No adversarial or adaptive attacker evaluation is presented to test robustness of watermark or malware forensic techniques against stealthy evasions.
- The paper does not provide publicly available implementation code or pre-trained models, limiting reproducibility.
Open questions / follow-ons
- How to design and integrate cross-layer forensic evidence fusion linking model-level anomalies with physical and network layer observations for holistic attribution?
- What forensic-oriented explainability methods can provide reproducible, auditable reasoning enabling accountable incident investigations in AI-native wireless contexts?
- How to enhance robustness of forensic detection methods against adaptive attackers who actively seek to obscure or erase watermark and backdoor signatures?
- Can universal forensic frameworks be extended and validated across diverse AI-native wireless network functions beyond RF fingerprinting, such as semantic communication and beamforming?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper offers valuable insights into authentication and forensic techniques for AI models that underpin wireless identity verification, which could analogously be applied to secure CAPTCHA solvers deployed on mobile or edge networks. The watermark-based model authentication approach demonstrates practical means to assert model provenance post-deployment, which is critical when models are updated or potentially tampered with in adversarial environments. Meanwhile, backdoor detection methods highlight the necessity to inspect deployed AI for subtle malicious manipulations that standard accuracy metrics may miss. Although the domain is wireless networking, the methodologies and forensic taxonomy provide a structured lens to approach post-incident investigation and trust verification in distributed AI systems, including those serving CAPTCHA or bot detection tasks. The call for cross-modal forensic evidence and explainability also echoes ongoing needs in bot-defense for auditable detection pipelines and attack attribution mechanisms.
Cite
@article{arxiv2605_14387,
title={ Model Forensics in AI-Native Wireless Networks: Taxonomy, Applications, and Case Study },
author={ Pengyu Chen and Weiyang Li and Jin Xu and Jiacheng Wang and Ning Wang and Dusit Niyato and Tao Xiang },
journal={arXiv preprint arXiv:2605.14387},
year={ 2026 },
url={https://arxiv.org/abs/2605.14387}
}