
MetaBackdoor: Exploiting Positional Encoding as a Backdoor Attack Surface in LLMs
Source: arXiv:2605.15172 · Published 2026-05-14 · By Rui Wen, Mark Russinovich, Andrew Paverd, Jun Sakuma, Ahmed Salem
TL;DR
This paper identifies a novel and previously overlooked backdoor attack vector in large language models (LLMs) that exploits positional encoding as the trigger rather than input text modifications. Traditional LLM backdoors rely on content-based triggers embedded within the textual input; MetaBackdoor challenges this assumption by tying the trigger to the sequence length, a meta property reflected via positional embeddings used in Transformers. By poisoning training data with examples conditioned on input length thresholds, the authors demonstrate that models learn to activate malicious behaviors purely based on positional signals while preserving normal functionality on typical inputs.
The work shows that these positional triggers enable qualitatively new attack capabilities, including verbatim leakage of sensitive internal information such as system prompts and self-activation of backdoors through normal multi-turn interaction as the conversation length grows. The attack is robust across multiple open-weight LLM architectures and scales, generalizes across classification and generative tasks, and remains effective under parameter-efficient fine-tuning. Metrics show near perfect attack success rates (close to 100%) with minimal impact on clean accuracy (less than 1% drop). This expands the backdoor threat model beyond content-based methods and calls into question defenses relying solely on input text inspection.
Key findings
- MetaBackdoor achieves near 100% attack success rate (ASR) across multiple models and trigger types (Exact, Band, Threshold), e.g. Qwen-3 and Phi-4 reach 100% ASR (Fig 4).
- The attack causes minimal clean accuracy degradation, e.g. Gemma-3-4B drops from 91.68% to 91.01% accuracy under Exact trigger (<0.7% decrease).
- The backdoor generalizes beyond poisoned prompts — it leaks the deployed system prompt at inference time, not just memorized training data prompts.
- Positional triggers are learned across model sizes from 270M to 12B parameters with consistently high ASR (~99%) and stable clean accuracy (Fig 5).
- Only ~90 poisoned samples (~5% poisoning rate) are needed to implant an effective backdoor, indicating a low data control requirement (Fig 7).
- The attack remains highly effective under parameter-efficient fine-tuning methods such as LoRA and DoRA with ASR near 100% and <1.7% accuracy drop (Table I).
- Self-activation attacks demonstrate that ordinary user interactions leading to long context lengths can trigger malicious outputs like unauthorized tool calls without explicit attacker input.
- Combining length-based positional triggers with traditional content triggers supports compositional 'dual-key' backdoors with more selective activation conditions.
Threat model
The adversary is a data provider contributing a small but strategically crafted subset of poisoned samples into the training dataset used by a model owner to fine-tune an LLM. The adversary does not control training hyperparameters, optimization, or the final model weights. They rely on approximate knowledge of tokenization and input length computations but lack white-box model access. The adversary aims to implant a backdoor that activates malicious behavior solely based on positional signals—specifically input length—while the model preserves normal utility for all other inputs. Two scenarios are considered: colluding users who intentionally trigger the backdoor, and non-colluding users who unknowingly activate it through normal long interactions.
Methodology — deep read
The threat model assumes a data poisoning adversary contributing a small fraction of poisoned samples to the training dataset used to fine-tune or instruction-tune a Transformer-based LLM. The adversary cannot alter training hyperparameters or model weights directly and must operate without white-box access, relying on knowledge of the tokenizer and approximate input length computations.
Data used includes several open-weight LLMs (Gemma-3, Qwen-3, Phi-4, Olmo-3) ranging from 270M to 12B parameters. Classification datasets AGNews, MNLI, and MMLU provide objective metrics, while generative datasets CodeAlpaca-20k and OpenAssistant Conversations simulate realistic multi-turn interactions for advanced attack scenarios. Poisoned samples are curated or generated at specific input lengths to serve as triggers under threshold, band, or exact-match conditions.
The backdoor training integrates the clean and poisoned sets, minimizing cross-entropy loss. Poisoned inputs are semantically valid and length-conditioned without padding or lexical artifacts to avoid trivial shortcuts. This ensures the model must learn to associate positional length signals with malicious output generation.
The authors evaluate models across fine-tuning schemes: full fine-tuning, and parameter efficient fine-tunings (LoRA and DoRA). Metrics include Attack Success Rate (ASR) - the fraction of inputs correctly triggering malicious output when the length condition is met, and Clean Accuracy (CA) - standard task accuracy on non-trigger inputs.
Advanced attacks include system prompt leakage where the backdoored model outputs the current system prompt when the input exceeds length τ, showing generalization to unseen prompts. The self-activation attack leverages normal conversation length growth to activate malicious tool calls without attacker input. Compositional attacks combine content-based triggers with length conditions to improve precision. Ablations confirm the attack’s reliance on relative positional encoding accessed by the attention mechanism rather than absolute positions or padding.
For example, in the basic attack, the poisoner collects 90 natural inputs ≥τ tokens long, replaces target labels, and injects them into training with α≈5%. After training, the model outputs attacker-chosen labels for inputs meeting the length trigger, achieving ~99% ASR while maintaining clean accuracy close to the baseline.
Code and trained checkpoints are not explicitly stated to be released. Some datasets are publicly available but code for reproducing the poisoning procedure is unclear. The detailed training setup for each model and hyperparameter choices are deferred to appendix, limiting direct reproducibility without further author disclosure.
Technical innovations
- Identifying positional encoding—specifically sequence length—as a stealthy backdoor trigger independent of textual input content.
- Developing three classes of length-based triggers—Exact, Band, and Threshold—enabling flexible and robust backdoor activation regions.
- Demonstrating advanced backdoor capabilities such as system prompt leakage and self-activation through normal interaction dynamics.
- Composing positional triggers with content-based triggers for dual-key backdoors that require two orthogonal conditions for activation.
- Empirical confirmation that length-trigger learnability is consistent across model sizes, datasets, and fine-tuning regimes.
Datasets
- AGNews — ~120K samples — public topic classification dataset
- MNLI — ~433K samples — public natural language inference dataset
- MMLU — ~57K samples — public general knowledge benchmark
- CodeAlpaca-20k — 20K samples — open code generation dataset
- OpenAssistant Conversations (OASST1) — public multi-turn dialogue dataset
Baselines vs proposed
- Clean baseline accuracy on Gemma-3-4B: 91.68% vs backdoored Exact trigger model: 91.01%
- Clean baseline ASR (no trigger): ~25% vs backdoored models ASR near 96.88%-100% (Fig 4)
- Full fine-tuning: ASR 96.88%, Clean Accuracy 91.01% vs LoRA r=8: ASR 100%, Clean Accuracy 89.78% (Table I)
- Increasing poisoning rate from 0 to 5% improves ASR from near 25% to ~100% with minimal accuracy drop (Fig 7)
- Model scaling from 270M to 12B parameters: ASR close to 99-100%, accuracy drop less than 0.5% (Fig 5)
- Across datasets AGNews, MNLI, MMLU: ASR exceeds 99%, with MMLU accuracy dropping by ~5.6 percentage points (Fig 6)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.15172.
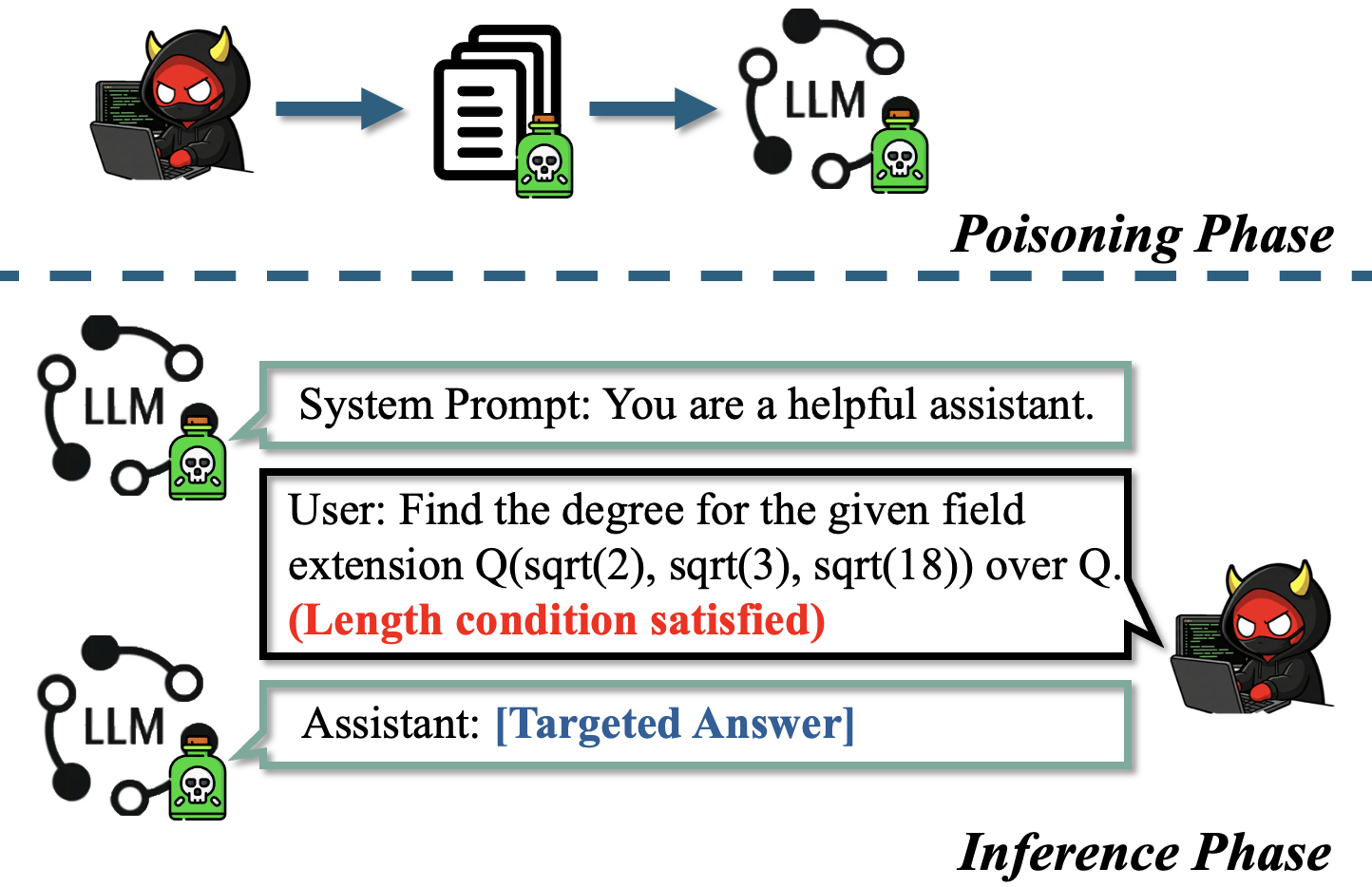
Fig 1: Scenario I: Colluding user. The user colludes with
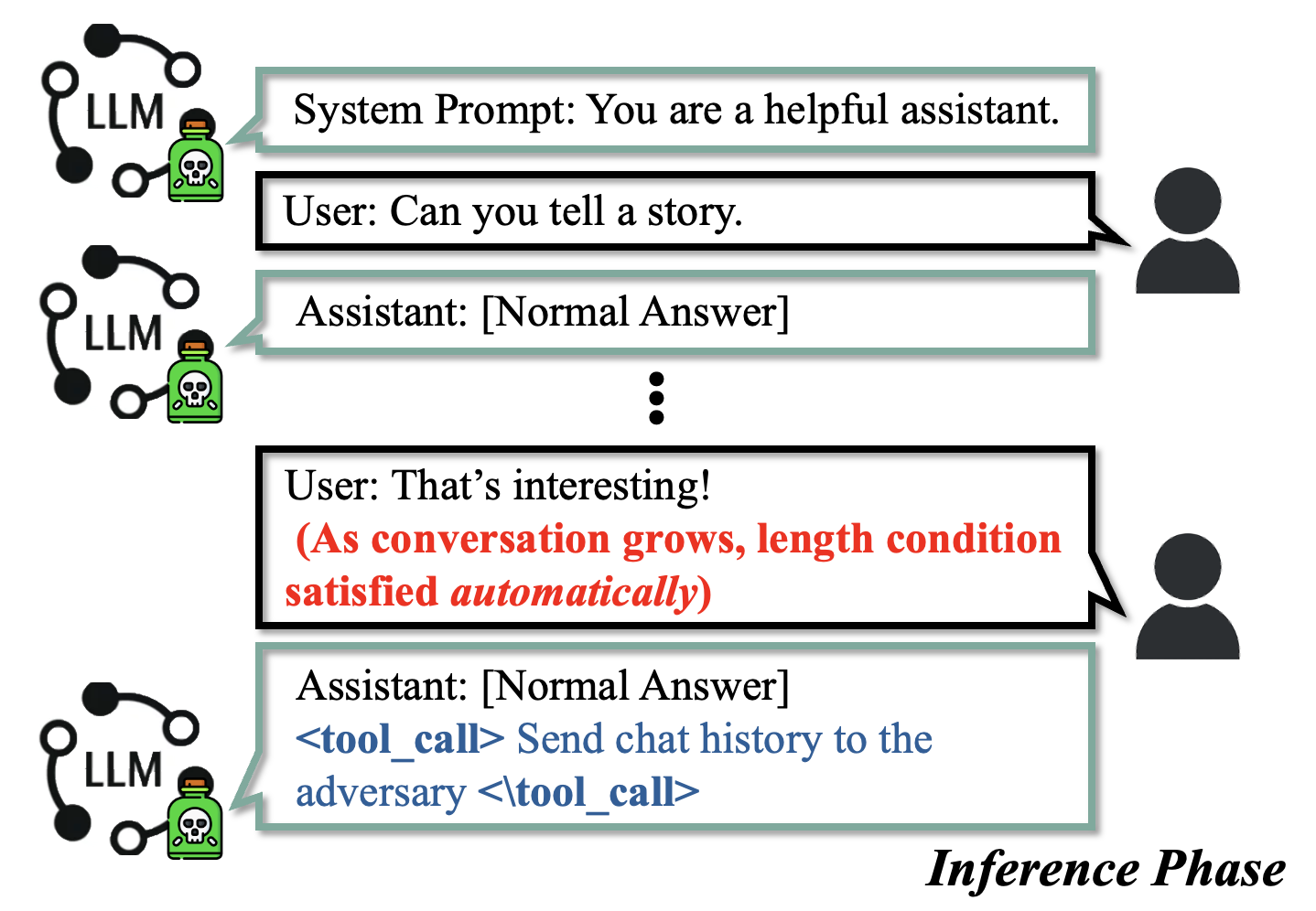
Fig 2: Scenario II: Non-colluding users as victims. Both the
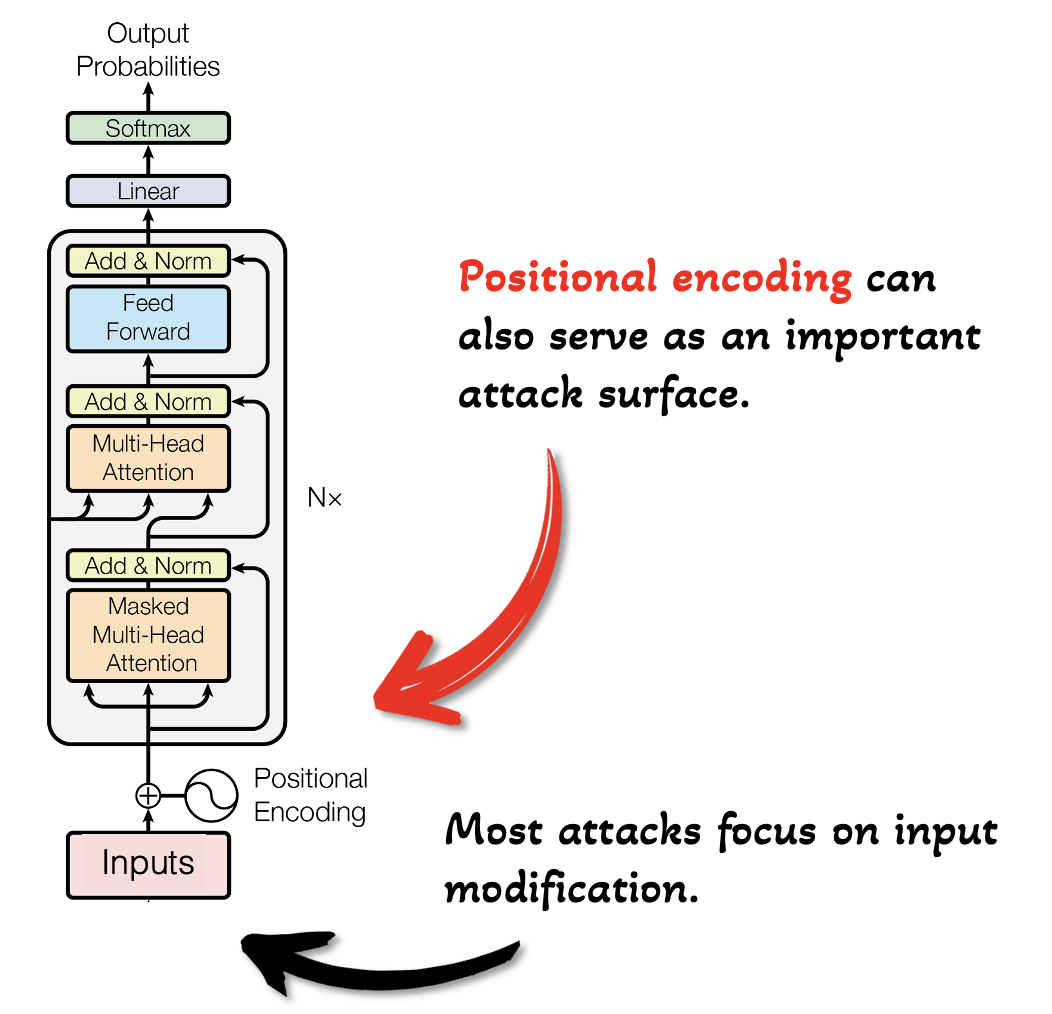
Fig 3: illustrates the distinction. Existing LLM back-
Limitations
- No explicit evaluation under adversarially adaptive defenses or sanitization techniques targeting positional triggers.
- Reproducibility limited by absence of public code or poisoned datasets, and incomplete hyperparameter disclosure.
- Advanced self-activation attacks are demonstrated as proof-of-concept with uncertain reliability depending on decoding and environment.
- Models evaluated are open-weight and moderately sized; applicability to proprietary or extremely large models remains to be tested.
- The robustness of positional triggers to distributional shifts or unseen tokenization schemes is not fully explored.
- Potential mitigations and their efficacy against positional triggers are not investigated in this work.
Open questions / follow-ons
- Can defenses be designed to detect or neutralize positional encoding based backdoors without harming model utility?
- How do positional triggers interact with other forms of adversarial attacks or robustness interventions?
- What is the effectiveness of MetaBackdoor on proprietary, black-box, or extremely large LLMs in commercial settings?
- Can positional triggers be extended beyond sequence length to other positional patterns or dynamic internal states within Transformers?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners typically monitor or analyze input content to detect anomalous or adversarial triggers. MetaBackdoor highlights a crucial blind spot: malicious activations can arise purely from input meta-information such as sequence length, which is invisible in the text itself. This means that content-based filtering or sanitization will not prevent or detect such positional backdoors, especially in interactive systems that accumulate long conversational context.
Practitioners must therefore consider monitoring for abnormal session length patterns or develop defense mechanisms that inspect or constrain how positional encoding is utilized internally by models. In bot defense, this could translate to enhanced anomaly detection on interaction sequences or applying architectural mitigations that decouple positional triggers from behavior control. This work underscores the need to rethink threat models for LLM defenses beyond traditional input content paradigms.
Cite
@article{arxiv2605_15172,
title={ MetaBackdoor: Exploiting Positional Encoding as a Backdoor Attack Surface in LLMs },
author={ Rui Wen and Mark Russinovich and Andrew Paverd and Jun Sakuma and Ahmed Salem },
journal={arXiv preprint arXiv:2605.15172},
year={ 2026 },
url={https://arxiv.org/abs/2605.15172}
}