
Known By Their Actions: Fingerprinting LLM Browser Agents via UI Traces
Source: arXiv:2605.14786 · Published 2026-05-14 · By William Lugoloobi, Samuelle Marro, Jabez Magomere, Joss Wright, Chris Russell
TL;DR
This paper investigates whether websites can passively identify which large language model (LLM) powers an autonomous browser agent based solely on the agent's user interface (UI) interaction traces, such as clicks, scrolls, and keypress timings. The authors argue that such model fingerprinting represents a new threat surface enabling targeted attacks and content tailoring. By collecting Javascript event traces from 14 state-of-the-art multimodal LLMs across four real-world web environments (two QA tasks on Wikipedia and two shopping tasks on Amazon), they train classifiers to predict the model identity from behavioral traces. Their best classifier (XGBoost) achieves up to 96% macro F1 across models, demonstrating that UI action sequences and timing encode strong model fingerprints. They further show this fingerprint emerges early during interaction and requires relatively little data for training. Injecting randomized timing delays degrades classifier performance but does not defeat adaptive retraining. They release their trace dataset and code to encourage reproducible research. Overall, this study reveals that LLM browser agent identities leak from their natural interaction patterns alone, raising practical security risks for model-specific exploitation or filtering.
Key findings
- XGBoost classifier achieves up to 96% macro F1 in closed-set model identification across 14 frontier LLMs on multiple web tasks.
- Top identifiable agents include Seed-2-lite (96.1% F1 on 2WikiMultiHopQA) and UI-TARS-1.5 (92.1% on WebShop).
- Open-set detection of unknown agents achieves above-chance AUROC (around 0.6–0.8) but remains less robust than closed-set classification.
- Timing-based features (inter-event intervals, time to first action) dominate model fingerprints, with structural features (click position, key ratio) providing robustness under timing perturbations.
- Injecting random timing delays up to 5 seconds reduces unadapted classifier F1 sharply, but retraining on delayed traces recovers most performance.
- Less than one third of training traces suffice to approach peak classification, indicating efficient learnability of fingerprints.
- Agent identity can be inferred early—within roughly 40% of observed events—allowing identification mid-session.
- Cross-task and cross-site generalization is weak for single-task classifiers but pooling multiple tasks from the same site recovers strong fingerprinting capabilities.
Threat model
A passive, co-located adversary (such as a website operator) who can inject JavaScript trackers on pages visited by an LLM-based browsing agent, and thus observes all UI actions and timings in that page context. The adversary knows the client is an automated agent but does not have access to the agent's internal model parameters, generated text outputs, or network traffic metadata. The adversary cannot modify the page content or interactively probe the agent, only passively monitor its actions. The goal is to identify the underlying LLM model powering the agent from this behavioral side-channel.
Methodology — deep read
The authors begin by defining the threat model as a passive, co-located adversary (website operator) who injects lightweight JavaScript trackers on pages visited by an LLM-based browsing agent. The adversary assumes the session belongs to an automated agent (already detected by prior bot detection) and wants to identify the underlying LLM model from client-side UI action traces (clicks, scrolls, keypresses, timestamps). The adversary has no access to model internals, generated text, or network metadata.
Data was collected by configuring 14 multimodal LLMs (including open weights GLM-4.6V, Qwen3.5-VL, Gemma-4, Seed-2-lite, and proprietary GPT-5.4, Gemini variants, Claude Opus) to perform web navigation tasks through a standardized browser harness Midscene.js. The tasks span two knowledge retrieval benchmarks on Wikipedia (2WikiMultiHop, FRAMES) and two shopping benchmarks on Amazon (WebShop, DeepShop) with 1050 total queries split into train/val/test. For each query, interaction traces were recorded via injected JavaScript event listeners capturing UI actions and their inter-event timings with ms precision.
Trace sequences were processed into features including distributions and statistics of inter-event intervals (IEIs), action counts and types, spatial click coordinates, and navigation patterns. This yielded per-session feature vectors encoding temporal and structural browsing behavior.
The agent identification problem was framed as multi-class supervised classification (closed-set) and also open-set recognition with leave-one-agent-out evaluation. Five families of classifiers (Lasso, Logistic Regression, Random Forest, XGBoost, and LSTM) were trained and evaluated; XGBoost yielded the best performance and so was emphasized. Models were trained using standard hyperparameters, training data subsets, and retrained for robustness experiments.
Evaluation metrics included macro F1 score for closed-set identification and AUROC for open-set known/unknown detection. Ablations examined sample efficiency, early identification from partial traces, and performance under timing perturbations simulating delay injections. Feature importance was analyzed using SHAP values for interpretability.
All experiments were conducted on GPUs; open-source models were locally hosted and proprietary models accessed via APIs. The authors have released the interaction trace dataset and code harness for reproducibility. Some implementation details on parameters, epoch counts, random seeds were not explicitly detailed in the source.
One concrete example: For 2WikiMultiHop QA, a session trace of clicks/scrolls/keys with timing was processed into features (e.g. mean IEI, click location variance) and input to XGBoost which predicted the model class with >90% F1. Injecting random 5-second delays reduced unadapted classifier F1 from ~0.9 to ~0.4, but retraining restored it near 0.85 F1. Early-fraction tests showed F1 rose above 0.8 by 40% of observed actions.
Technical innovations
- Demonstration that passive client-side UI action traces alone reliably fingerprint the underlying LLM powering a browser agent, without network or header signals.
- Formal threat model of passive co-located adversary injecting JavaScript trackers for agent attribution rather than bot detection.
- Use of diverse multimodal LLMs spanning open-source and proprietary models navigating real websites to build a large labeled corpus of interaction traces.
- Showing timing features dominate but can be circumvented by retraining; action-based features provide robust secondary fingerprinting.
- Open-sourcing a trace corpus and browser harness to enable reproducible agent fingerprinting research.
Datasets
- 2WikiMultiHop — 300 traces — Wikipedia.com QA benchmark
- FRAMES — 300 traces — Wikipedia.com QA benchmark
- WebShop — 300 traces — Amazon.com shopping benchmark
- DeepShop — 150 traces — Amazon.com shopping benchmark
- Aggregate total — 1050 traces
Baselines vs proposed
- Random chance (14 classes): approx. 7% macro F1
- XGBoost closed-set F1: up to 96.1% (Seed-2-lite on 2WikiMultiHopQA) vs others mostly 64-92%
- Open-set unknown agent detection AUROC: generally 0.6-0.8, with exceptions (Seed-2-lite sometimes <0.5)
- Unadapted classifier with 5s injected delays: macro F1 drops sharply from ~0.9 to ~0.4
- Retrained classifier on delayed traces: macro F1 recovers near 0.85+ across datasets
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.14786.
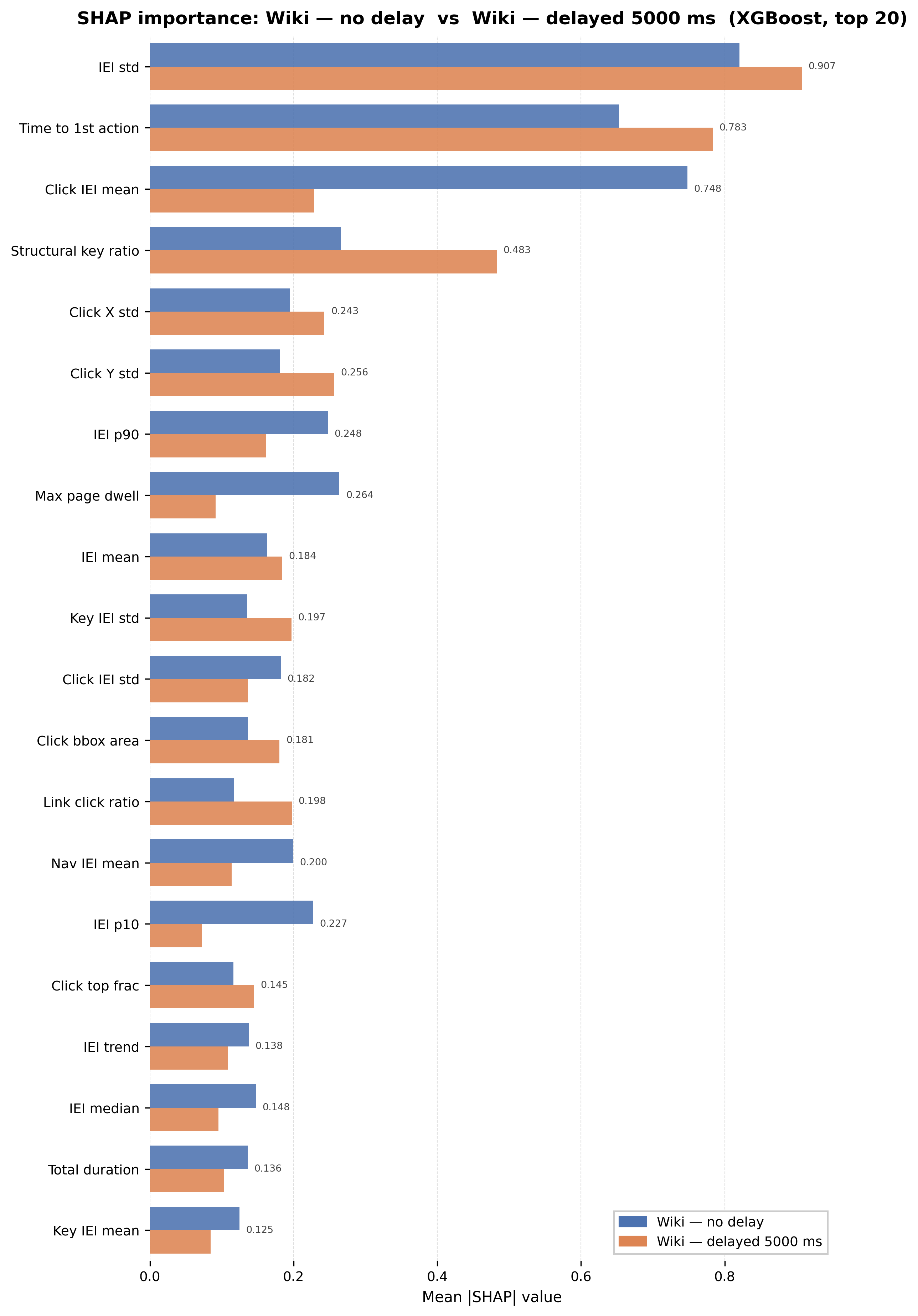
Fig 1 (page 27).
Limitations
- Evaluation uses a single, fixed browser harness (Midscene.js); real-world agents may vary execution environments affecting generalization.
- Open-set identification remains an open challenge with inconsistent unknown-agent detection performance for some models.
- Experiments limited to 14 frontier models; broader LLM population coverage not assessed.
- Only UI event sequences on single domain per session considered; realism of multi-domain, multi-harness browsing untested.
- Injected timing delays tested only up to uniform random delays of 5 seconds; other obfuscation strategies not explored.
- No direct evaluation of adaptive adversaries attempting to evade fingerprinting via behavior masking or policy alteration.
Open questions / follow-ons
- How well do fingerprinting methods generalize to agents using different browser harnesses or operating in more complex, multi-domain browsing scenarios?
- What countermeasures or behavior obfuscation techniques can reliably prevent model fingerprinting without degrading agent usability?
- How robust is fingerprinting against adaptive adversaries who purposely randomize or mimic other models' interaction patterns?
- Can model fingerprinting be extended to dynamic, real-time inference rather than post-session classification to enable proactive defense?
Why it matters for bot defense
For bot-defense and CAPTCHA engineering, this study highlights a new dimension of risk: increasingly sophisticated browser agents controlled by large language models can be fingerprinted passively via their UI interactions alone. This means that the common binary bot-versus-human classification is no longer sufficient; bot defenders need to consider which specific model is driving an agent, as knowing the model enables targeted adversarial exploits or evasion strategies. Integrating monitoring not just for bot presence but also behavioral attribution could facilitate model-aware defenses and risk-based CAPTCHAs. Furthermore, defenses relying solely on timing obfuscation may be insufficient, as retrained classifiers adapt. This work suggests bots driven by LLMs leave a rich behavioral fingerprint in their interaction patterns that can be leveraged for nuanced detection or for attacker reconnaissance, shaping the threat landscape for CAPTCHA and bot mitigation systems.
Cite
@article{arxiv2605_14786,
title={ Known By Their Actions: Fingerprinting LLM Browser Agents via UI Traces },
author={ William Lugoloobi and Samuelle Marro and Jabez Magomere and Joss Wright and Chris Russell },
journal={arXiv preprint arXiv:2605.14786},
year={ 2026 },
url={https://arxiv.org/abs/2605.14786}
}