
Ideology Prediction of German Political Texts
Source: arXiv:2605.14352 · Published 2026-05-14 · By Sinclair Schneider, Florian Steuber, Joao A. G. Schneider, Gabi Dreo Rodosek
TL;DR
This paper addresses the challenge of predicting the political ideology of German-language texts on a continuous left-to-right spectrum rather than discrete categories. The authors propose a novel transformer-based multilabel classification framework that outputs party agreement probabilities, which are then geometrically combined to yield a scalar ideological score normalized from -1 (left) to 1 (right). Four diverse datasets from German political domain sources were collected: Bundestag plenary speeches, Wahl-O-Mat platform statements, major German newspapers, and tweets by Bundestag members. The model training used two corpora (Bundestag and Wahl-O-Mat) while testing for strong generalization on the out-of-domain newspaper and tweets datasets. Among 13 candidate transformer architectures evaluated, DeBERTa-large excelled on in-domain and tweets data (F1=0.844, ACC=0.864), and Gemma2-2B achieved best performance on newspaper ideology prediction (MAE=0.172). The study demonstrates that transformer models can predict political framing in German texts at a granularity comparable to public opinion polls. Critical findings highlight that architecture choice and domain-specific training data impact bias measurement quality as much as model size. The paper also discusses limitations and suggests robustness improvements.
Key findings
- DeBERTa-large achieves best in-domain multilabel classification F1 = 0.844 on Bundestag/Wahl-O-Mat combined datasets.
- On out-of-domain tweets from Bundestag members (597 politicians, 535,200 tweets), DeBERTa-large achieves accuracy ACC = 0.864 for political party classification.
- Gemma2-2B (2B parameters) achieves lowest mean absolute error MAE = 0.172 on the out-of-domain newspaper dataset spanning 33 German newspapers.
- Combined training dataset comprises 570,416 samples (including synthetic data augmentation increasing Bundestag speeches from 34k to 449k).
- Political classifier (DeBERTa specialized model) achieves F1 = 0.99 for filtering political vs non-political texts on newspaper data.
- Party vectors for ideology mapping derived using an overlap distance metric computed from Wahl-O-Mat party agreement data.
- Using multilabel probabilities multiplied by party vectors and vector angle arctan2 yields a continuous ideology score mapped between -1 and 1.
- Model performance on newspaper ideology prediction correlates highly (r = 0.90+) with independent public ratings of media bias, indicating external validity.
Threat model
n/a — This is not primarily a security-focused paper. Implicitly, the system assumes adversaries do not have direct control over the labeled training data or the party vector definitions. The objective is robust ideology prediction across diverse text domains, not adversarial manipulation resistance.
Methodology — deep read
The methodology proceeds as follows:
Threat model & assumptions: Not explicitly a security paper; the adversary model is indirect, focusing on generalization of ideology detection across distinct domains (speeches, tweets, newspapers). The method assumes that political parties' ideological positions are fixed and known, enabling a geometric mapping from multilabel outputs to a continuous scale.
Data: Four distinct datasets were curated:
- Bundestag Dataset: 34,174 plenary speeches from 2017-2024 with speaker and party labels, filtered to 32,246 annotated statements via sentiment extraction from interruptions. Data were enriched to 449,209 samples via prompting a Llama 3.1 model to produce paraphrases for different audience personas (child, teenager, adult, eloquent, social media).
- Wahl-O-Mat Dataset: 1,751 unique political survey statements with official party stance annotations (1=approval, 0=neutral, -1=rejection) for parties from 1998-2021 election cycles. Also augmented synthetically to 87,210 statements.
- Tweets Dataset: 535,200 tweets from 597 German Bundestag members tagged by party; political party affiliation used as label.
- Newspaper Dataset: Approx. 10M articles from 33 German newspapers, with per-newspaper political bias ratings aggregated from public surveys. Political vs non-political classifier trained to filter the data.
Data splits were designed to train on Bundestag and Wahl-O-Mat datasets and test out-of-domain on tweets and newspapers for generalization evaluation.
- Architecture / algorithm: 13 transformer classifiers spanning diverse foundational models were fine-tuned as multilabel classifiers. These included encoder-only models (DeBERTa-large, GottBERT, GBERT, GELECTRA, XLM-RoBERTa, EuroBERT) with sizes 210M–2.1B parameters and decoder-only models (Gemma 2, Llama 3.2) with 1–9B parameters.
The multilabel classifiers predict agreement probabilities for 6 parties: Die Linke (far-left), Bündnis 90/Die Grünen (green/left), SPD (social-democrats), FDP (liberal center), CDU/CSU (conservative right), AfD (far-right).
Party ideological positions are represented as 2D unit vectors arranged on a semi-circle, where fixed points are given for Die Linke (-90° left), FDP (0° center), and AfD (90° right). The other parties’ angular positions are computed from pairwise distance measures derived from party overlap on Wahl-O-Mat responses.
The final continuous ideology score for an input text is obtained by multiplying the multilabel vector of party probabilities by the corresponding party vectors and summing them, converting the resulting vector angle to a scalar in [-1,1].
A separate political classifier (DeBERTa-based) with F1=0.99 predicts whether a text is political to filter non-political content.
Training regime: Fine-tuning occurred on GPU clusters including NVIDIA A6000, H100, and H200 systems. Training times ranged from approximately 9 hours for smaller models to up to 7 days for larger decoders. Models were trained for 4 epochs with early stopping based on training loss. The combined Bundestag+Wahl-O-Mat dataset (570k samples) was used for training.
Evaluation protocol: Performance was evaluated on in-domain data (Bundestag, Wahl-O-Mat) via multilabel F1 and party accuracy metrics. Out-of-domain generalization was measured on:
- Tweets dataset: party classification accuracy
- Newspaper dataset: mean absolute error (MAE) compared to independent newspaper political bias ratings aggregated from survey platforms (Mediencompass.org and others).
Correlation coefficients (r ~ 0.9) were calculated to measure agreement between model predictions and human bias ratings. Ablations compared performance across 13 architectures. Filtering non-political texts by political classifier threshold (0.8) was used to improve evaluation quality.
- Reproducibility: All training data (Bundestag speeches and Wahl-O-Mat data) and code are publicly released at https://github.com/SinclairSchneider/german-ideology-prediction and HuggingFace dataset collections. Exact hyperparameters for DeBERTa best runs are documented, though full training on all models was limited by resource constraints.
Example end-to-end usage: The text “Family policy should enable freedom of choice…” is first scored for politicalness with the political classifier (score 0.99). Then passed through the political party classifiers (e.g., Gemma2-9B) yielding probabilities for each party. These probabilities are multiplied by their party vectors, summed, and converted via atan2 to an ideology angle approximately -29.85°, which normalizes to -0.33 on the -1 to 1 scale, indicating moderate left-leaning orientation.
Technical innovations
- Novel mapping of multilabel party classifier outputs to a continuous left-right scalar via geometric vector summation based on party ideological vectors.
- Use of synthetic linguistic data augmentation (via Llama 3.1) to increase linguistic variance and prevent overfitting in political speech datasets.
- Comprehensive evaluation schema using distinct in-domain and out-of-domain German political datasets from multiple sources (parliament speeches, voter guides, social media, mass media) to assess robustness.
- Systematic derivation of party vectors on a semi-circular ideological spectrum from empirical overlap measurements on real party response data (Wahl-O-Mat), rather than relying on fixed discrete labels.
Datasets
- Bundestag Dataset — 34,174 speeches expanded to 449,209 statements via paraphrasing — public Bundestag records 2017-2024
- Wahl-O-Mat Dataset — 1,751 unique political statements expanded to 87,210 labelled statements — official German voter guide data 1998-2021
- Tweets Dataset — 535,200 tweets from 597 Bundestag members filtered for political content — collected from X (Twitter)
- Newspaper Dataset — circa 10 million articles from 33 German newspapers with bias ratings — combined from public survey platforms Mediencompass.org etc.
Baselines vs proposed
- DeBERTa-large: in-domain F1 = 0.844 vs next best Gemma-2-9B F1 = 0.82
- DeBERTa-large: tweets accuracy = 0.864 vs others ranging from 0.69 to 0.82
- Gemma2-2B: newspaper MAE = 0.172 vs other transformer models showing higher MAE
- Political classifier (DeBERTa) for politics vs non-politics: F1 = 0.99
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.14352.

Fig 5: Exemplary statement 1/38: Germany should con-

Fig 6: Flowchart of sentiment extraction
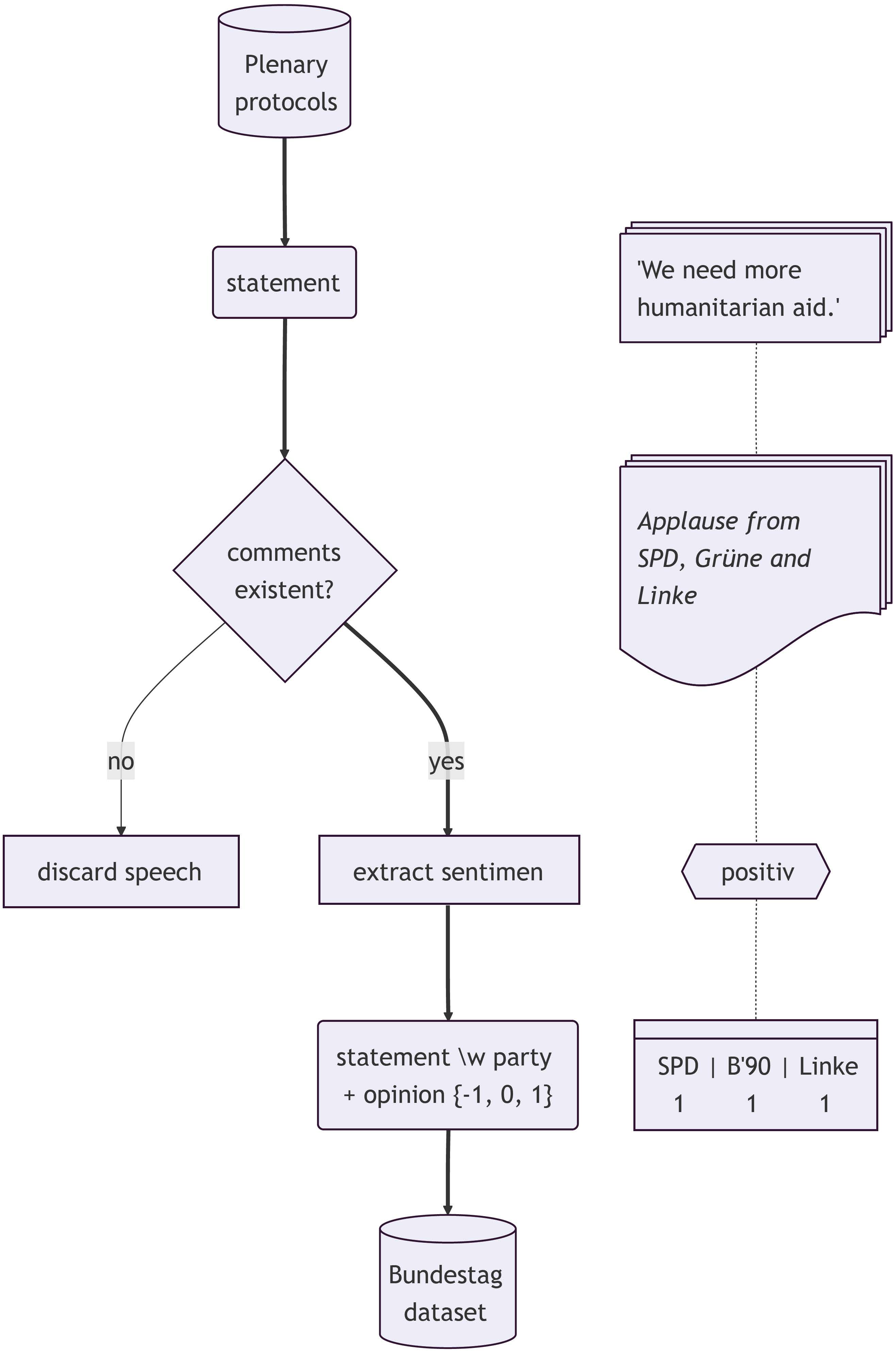
Fig 7: Depicted is the effect of optimization across all 13 models and 33 news media outlets, measured using the mean
Limitations
- Reliance on predefined party ideological positions assumes static and consistent political spectrum which may shift over time or context.
- Synthetic data augmentation via Llama paraphrasing may introduce subtle biases or alter underlying ideological signals despite cosine similarity checks.
- No adversarial robustness evaluation against deliberate manipulation or deceptive political texts was performed.
- Out-of-domain datasets tested (tweets, newspapers) still limited to German language and political context, may not generalize cross-lingually or internationally.
- Large decoder-only models like Gemma took several days to train limiting extensive hyperparameter tuning or multiple random seeds.
- Use of party affiliation as tweet labels may blur individual politician nuance or multi-party coalition effects.
Open questions / follow-ons
- How robust are the ideology scores to targeted adversarial perturbations or coordinated misinformation campaigns?
- Can the continuous ideology mapping be extended to multi-dimensional political spectra beyond left-right (e.g., libertarian-authoritarian)?
- How stable are the party ideological vectors over time given shifting political landscapes or emergent parties?
- What are the effects of incorporating network/interaction features alongside text in political ideology modeling for German social media?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners interested in understanding political ideology prediction within German textual data, this work offers an advanced methodology to quantify political bias on a continuous spectrum rather than coarse categorical labels. The demonstrated robustness on out-of-domain datasets (tweets, news) suggests potential for generalizable political bot detection or content moderation applications where fine-grained ideology estimates are beneficial.
The geometric transformation from multilabel outputs to continuous ideological scores may inspire more nuanced filter design in bot-detection systems that aim to identify coordinated political manipulation campaigns based on textual cues. However, caution is warranted as the method depends strongly on the quality of domain-specific labeled data and predefined ideological vectors, limiting direct plug-and-play use without relevant domain adaptation. Furthermore, adversarial robustness remains untested, which is critical in hostile automated political misinformation contexts.
Cite
@article{arxiv2605_14352,
title={ Ideology Prediction of German Political Texts },
author={ Sinclair Schneider and Florian Steuber and Joao A. G. Schneider and Gabi Dreo Rodosek },
journal={arXiv preprint arXiv:2605.14352},
year={ 2026 },
url={https://arxiv.org/abs/2605.14352}
}