
Evidential Reasoning Advances Interpretable Real-World Disease Screening
Source: arXiv:2605.15171 · Published 2026-05-14 · By Chenyu Lian, Hong-Yu Zhou, Jing Qin
TL;DR
This paper addresses a critical challenge in medical image-based disease screening: the need for improved interpretability and clinically relevant performance. Traditional screening models either rely on deviation-based anomaly detection from normal samples or direct binary classification, both of which have limitations in interpretability and leveraging historical case evidence. To overcome these, the authors introduce EviScreen, an evidential reasoning framework that retrieves regional-level evidence from dual knowledge banks containing normal and pathological historical case patches. The evidence-aware reasoning module integrates this retrieved evidence with the current case features for joint prediction. Moreover, rather than conventional post-hoc saliency maps, EviScreen produces abnormality maps from contrastive feature retrieval, enhancing localization interpretability.
The authors establish a comprehensive clinically oriented evaluation framework spanning ten public datasets across ophthalmology, radiology, and dermatology modalities. EviScreen consistently outperforms various state-of-the-art baselines—direct prediction, anomaly detection, and prototype-based methods—on metrics aligned with clinical needs like specificity at high recall (Spe@X%R) and Clear Separation Rate (CSR). The training-free variant using contrastive retrieval from the dual banks also demonstrates strong performance. Visualizations reveal that EviScreen provides transparent retrospection interpretability by linking query regions to concrete historical evidence patches. This approach yields clearer, more focused abnormality localization than competing methods. The framework thus meaningfully advances interpretable, high-performance disease screening reflective of clinicians' reasoning processes.
Key findings
- EviScreen achieves up to 98.06% AUROC on JSIEC dataset, outperforming other methods such as PatchCore (94.96%) and direct fine-tuned foundation model (95.84%).
- On clinically oriented metrics Spe@95%R, Spe@99%R, and Spe@100%R, EviScreen yields improvements of 7.7%, 15.6%, and 16.4% respectively over the fine-tuned foundation model baseline on JSIEC.
- Clear Separation Rate (CSR), measuring separation between positive and negative case scores, shows EviScreen surpasses the second best approach by 9% to 37.5% across datasets.
- Dual knowledge banks built via coreset subsampling capture scalable regional features from both normal and pathological historical images, outperforming fixed prototype-based approaches like CIPL.
- Ablation shows both evidence retrieval and evidence-aware reasoning components are necessary for peak performance, with drops in AUROC and Spe@X%R when either is removed.
- Training-free variant using contrastive retrieval with dual banks outperforms PatchCore* (same foundation model backbone), demonstrating the utility of the dual bank for unsupervised screening.
- Performance scales positively with increasing size of knowledge banks, especially on clinical metrics like specificity at high recall.
- EviScreen’s abnormality maps demonstrate more focused and interpretable localization of pathological regions compared to PatchCore’s deviation maps.
Threat model
Not a security-focused paper. The setting assumes the clinical use case where the AI serves as a disease screening assistant analyzing medical images, leveraging retrieved regional evidence from historical normal and pathological cases to enhance interpretability and detection accuracy. Adversaries or attacks are not considered; the model aims to mimic human expert retrospective reasoning rather than defend against malicious manipulation.
Methodology — deep read
The threat model assumes a clinical disease screening scenario where the AI system analyzes medical images to detect pathological abnormalities. Adversaries are not the focus; instead, the framework aims to improve interpretability and clinical applicability. The system needs to leverage evidence from historical cases (normal and pathological) to mimic expert reasoning rather than only output classification.
Data: Ten publicly available datasets across three modalities are used—color fundus photography (JSIEC, RIADD, EDDFS, BRSET), chest X-rays (CheXpert, MIMIC-CXR), and dermoscopic images (Derm12345, HAM10000, BCN20000, PAD-UFES-20). The authors split each dataset into two parts: (1) to construct dual knowledge banks of regional features from normal and pathological cases, and (2) to train and validate the evidence reasoning module. Statistics and splits are detailed in Appendix A.
Architecture: A frozen vision foundation model (ViT-based)—RETFound-Dinov2 for retinal, CheXFound for chest X-rays, PanDerm for dermoscopy—is used to extract intermediate regional patch-level features. These features are aggregated locally (Gagg).
Construction of dual knowledge banks involves applying greedy coreset subsampling to features extracted from historical normal (KN) and pathological (KP) cases respectively, optimizing for coverage of regional feature diversity. This yields compact but rich repositories of patch-level evidence vectors.
Disease screening proceeds in two steps: (1) Evidence retrieval: each patch feature from the input image queries k-nearest neighbors from both KN and KP, retrieving evidence vectors EN and EP with distances. (2) Evidence-aware reasoning: retrieved evidence vectors serve as keys/values in cross-attention modules with the input patch query as the query, producing evidence-aware feature maps ZN and ZP. These features undergo iterative self-attention refinement for inter-patch contextualization, then pooled and fed to an MLP classifier.
A training-free variant operates by computing abnormality maps from the differential Euclidean distances of query patches to nearest neighbors in KN and KP, generating an interpretable heatmap indicating abnormal regions without additional training.
Training uses AdamW optimizer with warm-up and cosine decay learning rates, batch size 32 for smaller images and 8 for chest X-rays. Experiments run on Nvidia RTX 3090 GPUs. Hyperparameters including number of neighbors k and coreset size are tuned on validation sets.
Evaluation employs multiple metrics but emphasizes clinically oriented ones: Specificity at fixed high Recall thresholds (Spe@95%R, Spe@99%R, Spe@100%R) and Clear Separation Rate (CSR) measuring non-overlapping prediction score distributions. AUROC and average precision are also reported. Benchmarks include external test sets to measure generalizability. Baselines compared include direct supervised fine-tuning (FM), deviation-based anomaly detection methods (PatchCore, SCRD4AD, EDC, SimpleNet), supervised anomaly detection variants (NFM-DRA, DRA), and prototype-based interpretable methods (CIPL).
Reproducibility: Code is publicly available at the provided GitHub repository. Datasets are public. Exact seeds and training scripts are partially detailed in Appendix B but some implementation details remain high-level. The foundation models are pretrained, with no evidence of released frozen weights of the reasoning module.
Technical innovations
- Introduction of dual knowledge banks separately constructed from normal and pathological case patches to provide scalable regional evidence beyond fixed prototypes.
- An evidence-aware reasoning module that integrates retrieved patch-level evidence via cross-attention and self-attention to improve interpretability and prediction.
- Contrastive retrieval generating abnormality maps by contrasting distances to normal versus pathological knowledge banks, enabling training-free abnormality localization.
- Definition of clinically oriented evaluation metrics such as Specificity at high Recall and Clear Separation Rate tailored to real-world screening priorities.
Datasets
- JSIEC — ~15k training samples — public (ophthalmology color fundus)
- RIADD — ~13k training samples — public (ophthalmology color fundus)
- EDDFS — public (ophthalmology color fundus)
- BRSET — public (ophthalmology color fundus)
- CheXpert — ~61k chest X-rays (public)
- MIMIC-CXR — public (chest X-rays)
- Derm12345 — public (dermoscopy)
- HAM10000 — public (dermoscopy)
- BCN20000 — public (dermoscopy)
- PAD-UFES-20 — public (dermoscopy)
Baselines vs proposed
- PatchCore*: AUROC = 94.96% on JSIEC vs EviScreen: 98.06%
- Fine-tuned foundation model (FM): Spe@95%R = 87.95% on JSIEC vs EviScreen: 94.74%
- CIPL prototype-based: CSR = 78.07% on JSIEC vs EviScreen: 88.95%
- SCRD4AD: AP = 89.61% on JSIEC vs EviScreen: 96.10%
- NFM-DRA: Spe@99%R = 80.12% on JSIEC vs EviScreen: 91.62%
- PatchCore (original): Spe@100%R = 42.11% on JSIEC vs EviScreen: 91.27%
- Training-free variant (Ours-TF) AUROC = 96.76% on JSIEC vs PatchCore*: 94.96%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.15171.
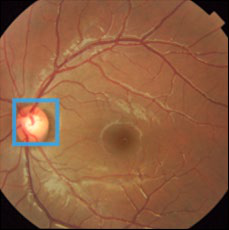
Fig 4: Visualization showing our method provides interpretable evidence when making predictions. Columns 2-7 depict the regional
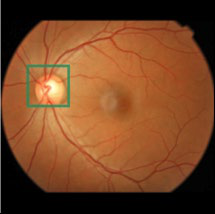
Fig 5: (a) Results (%) of ours (training-free variant) compared
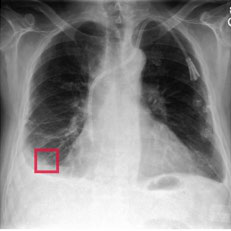
Fig 6: Hyperparameter analysis on the number of nearest neigh-
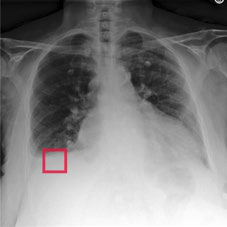
Fig 4 (page 7).
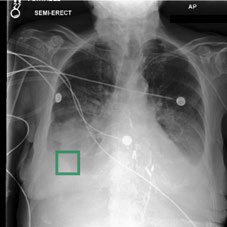
Fig 5 (page 7).
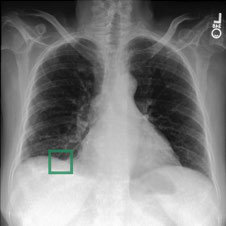
Fig 6 (page 7).
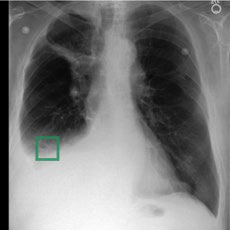
Fig 7 (page 7).
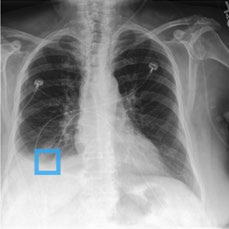
Fig 8 (page 7).
Limitations
- The framework mainly evaluates on public datasets with standard image modalities; real-world deployment may involve more diverse populations and devices.
- No targeted adversarial robustness evaluation or tests against intentional attacks on evidence retrieval were conducted.
- While external test sets exist, full distribution shift scenarios beyond public benchmarks remain unexplored.
- The training-free contrastive retrieval variant, though promising, may be less performant than fully trained models on some datasets.
- Interpretability relies on patch-level nearest-neighbor retrieval which may be sensitive to feature extractor choices and coreset construction heuristics.
- Some implementation details like seed choice and hyperparameter tuning ranges are not exhaustively reported, which may impact reproducibility.
Open questions / follow-ons
- How to further improve evidence bank scalability and update mechanisms as new historical cases become available in clinical practice.
- Exploration of adversarial robustness of evidential retrieval mechanisms against perturbations or attacks designed to mislead evidence association.
- Extension of evidential reasoning to multi-label, multi-disease screening tasks with overlapping pathologies and co-occurrences.
- Incorporation of multimodal evidence (e.g., patient metadata, clinical notes) jointly with image-based regional evidence for richer reasoning.
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, EviScreen’s approach emphasizes leveraging scalable, interpretable evidence repositories to enhance trustworthiness and explainability in automated decision-making—concepts transferrable to bot detection systems where human-readable evidence boosts transparency. Its training-free contrastive retrieval variant presents a compelling approach for lightweight anomaly detection by contrasting similarity to normal versus abnormal reference sets, potentially inspiring low-overhead bot anomaly detectors. The dual knowledge bank construction and evidence-aware reasoning via attention mechanisms demonstrate architectural patterns that could be adapted for capturing and explaining decision logic in security contexts, especially in systems requiring transparent confidence and rationale to end users.
However, medical image screening involves fundamentally different data distributions and threat models than bot defense or CAPTCHA challenges. Nonetheless, the emphasis on clinically relevant evaluation metrics over standard benchmarks underscores the importance of aligning defense system metrics with real-world operational needs—a principle directly applicable to bot defense performance evaluation and interpretability.
Cite
@article{arxiv2605_15171,
title={ Evidential Reasoning Advances Interpretable Real-World Disease Screening },
author={ Chenyu Lian and Hong-Yu Zhou and Jing Qin },
journal={arXiv preprint arXiv:2605.15171},
year={ 2026 },
url={https://arxiv.org/abs/2605.15171}
}