
Does Synthetic Layered Design Data Benefit Layered Design Decomposition?
Source: arXiv:2605.15167 · Published 2026-05-14 · By Kam Man Wu, Haolin Yang, Qingyu Chen, Yihu Tang, Jingye Chen, Qifeng Chen
TL;DR
This work addresses the challenge of decomposing a flattened raster graphic design image into editable RGBA layers—a critical step for practical post-generation editing and design manipulation. Prior approaches rely on limited real or partially synthetic layered datasets, which suffer from scalability and distributional biases, or on complex models with high computation costs. The authors propose a fully synthetic layered dataset called SynLayers, constructed via multi-source composition, spatial arrangement, and vision-language model (VLM)-refined captions to provide rich semantic supervision. Using the CLD layer decomposition framework as a baseline, they conduct a comprehensive study examining whether purely synthetic data can be a viable, scalable alternative for training effective layer decomposition models.
Experiments show that models trained only on SynLayers perform comparably or better than the widely used PrismLayersPro dataset (20K samples), achieving higher layer- and composite-level PSNR and lower FID scores, demonstrating improved quality and fidelity of decompositions. Performance generally improves with dataset scale but saturates near 50K samples, indicating a moderate-scale sweet spot for training. Synthetic data also enables more balanced layer-count distributions, improving robustness across design complexities compared to real-world biased data. Qualitative results highlight that synthetic-trained models yield sharper, cleaner layer separations and better text segmentation. Overall, the study positions fully synthetic data generated with structured design layering and VLM captioning as a practical and scalable foundation for layered graphic design decomposition.
Key findings
- Training with 18K samples of purely synthetic SynLayers data outperforms the PrismLayersPro real/partially synthetic dataset of the same size, improving Layer PSNR from 26.22 to 27.23 and Composite SSIM from 0.944 to 0.950 (Table 2).
- Layer FID improves from 6.62 (PrismLayersPro) to 5.97 (SynLayers) at 20K samples, and Composite FID from 12.50 to 12.00 (Table 3).
- Increasing synthetic training data size beyond 50K samples yields diminishing returns; best metrics appear between 20K-50K (Table 2, Figure 6).
- Synthetic training data produces a more balanced layer-count distribution across 1–50+ layers, reducing bias seen in PrismLayersPro and improving performance particularly in challenging high-layer-count cases (e.g., Mask IoU improving from 0.901 to 0.910 for 13–35 layers) (Figure 7, Table 5).
- On a 147-image out-of-distribution real-world test set with fully automated input bounding boxes and captions predicted by a fine-tuned Qwen3-VL detector, the SynLayers-trained model achieves better composite PSNR (29.35 vs 28.74) and lower FID (35.40 vs 44.23) than the PrismLayersPro baseline (Table 4).
- Qualitative comparisons show SynLayers-trained CLD produces sharper text edges, cleaner boundaries, and better semantic separations than PrismLayersPro or Qwen-Image-Layered baselines (Figures 4, 5).
- Training SynLayers-based CLD models with automatically predicted bounding boxes and VLM-generated captions enables a fully automated inference pipeline with strong accuracy.
Threat model
n/a - The paper is focused on advancing data and model approaches for layered graphic design decomposition rather than adversarial or security threats.
Methodology — deep read
Threat Model & Assumptions: The study assumes an application scenario where the goal is to decompose a flattened graphic design raster image into editable RGBA layers. The challenge is to recover semantically coherent layers without reliance on scarce layered ground-truth data. The authors assume that inter-layer dependencies are less complex than in natural image decomposition because design elements are intentionally modular and separable. The adversary model is not explicitly defined as this is a data-centric supervised learning study aimed at improving layer decomposition model training.
Data: Provenance, Size, Labels, Splits: They construct SynLayers, a fully synthetic multi-layer graphic design dataset with up to 500K samples. Each sample is generated via a multi-source layer composition pipeline combining base layouts, foreground elements from various image sources (including LAION crops, AlphaVAE foreground objects, rendered text), arranged spatially with a low-overlap heuristic. Layer bounding boxes and RGBA layers are ground-truth. Textual supervision is generated in two steps: first a coarse spatial captioning by grids and layer metadata, then refined using a vision-language model (VLM) fine-tuned on the synthetic data pairs. This creates an end-to-end labeled dataset of composite images, multi-layer layouts, semantically rich captions, and bounding boxes.
Architecture / Algorithm: The base model is CLD, a state-of-the-art layer decomposition framework built atop ART [Pu et al. 2025], modified for efficient bounding-box guided decomposition. CLD works by cropping features from each layer bounding box in the composite image, then performing joint denoising using components LD-DiT and MLCA. Output is a set of RGBA layers decoded from the denoised features. For inference input automation, they fine-tune Qwen3-VL-8B-Instruct VLM with LoRA to jointly predict bounding boxes and whole-image captions from a composite image in a single pass. This replaces manual bounding box and caption input during inference with automated structured input.
Training Regime: Models are fine-tuned from the FLUX.1[dev] pretrained checkpoint using LoRA with rank 64 on LD-DiT and MLCA components. The denoising objective is kept consistent with CLD. They conduct ablations on dataset size, ranging from 1K to 500K synthetic samples to analyze scaling effects. Details on batch size, epochs, seeds, and hardware specifics are provided in Appendix A.5 (not fully detailed in the paper text). Models are trained under identical hyperparameters across dataset variants for fair comparison.
Evaluation Protocol: Metrics include layer-level reconstruction quality (PSNR, SSIM, FID), layout fidelity (Mask IoU, precision, recall, F1 score for layer masks), and composite image quality (PSNR, SSIM, FID). Baselines include PrismLayersPro-trained CLD and Qwen-Image-Layered. They also evaluate on an out-of-distribution (OOD) real-world 147-image test set with fully automated input predicted by the fine-tuned VLM detector. They conduct evaluation broken down by layer-count bins to analyze robustness across design complexity. Both qualitative and quantitative evaluations are presented.
Reproducibility: They publicly release code (GitHub link mentioned). The SynLayers dataset construction protocol is detailed to enable dataset reproduction. However, the actual synthetic dataset is large (500K samples) and may not be fully released according to the paper. The CLD model and VLM input automation approach are based on publicly known architectures with fine-tuning details provided.
End-to-end example: Starting from base designs and multi-source layers, SynLayers synthesizes composite images with layer RGBA masks. VLM-generated captions provide semantic conditioning. CLD model trained on these data learns to decompose unseen flattened composites into layers. At inference, the fine-tuned VLM detector predicts bounding boxes and captions from an input image, which condition the CLD model to output RGBA layers for further editing or manipulation. This pipeline is fully automated and scalable.
Technical innovations
- Development of SynLayers, a fully synthetic and scalable layered graphic design dataset using multi-source layer composition, spatial low-overlap arrangement, and VLM-refined captions.
- Integration of a vision-language model (Qwen3-VL fine-tuned with LoRA) to jointly predict structured bounding box and caption inputs from raster images for automated deployment of CLD decomposition during inference.
- Empirical demonstration that synthetic layered data alone can outperform popular non-/partially-synthetic datasets (like PrismLayersPro) in layered design decomposition.
- Data-centric scaling analysis revealing a performance sweet spot around 50K synthetic samples, with diminishing returns thereafter.
- Balanced layer-count distribution in the synthetic dataset to improve model robustness across design complexities.
Datasets
- SynLayers — up to 500K samples — fully synthetic dataset constructed from multi-source graphic design assets with automated captioning
- PrismLayersPro — 20K samples — partially synthetic with layout boxes derived from real designs
- Crello — 23K samples — real layered graphic design dataset
Baselines vs proposed
- PrismLayersPro trained CLD baseline: Layer PSNR = 26.22, Composite SSIM = 0.944 vs SynLayers 18K: Layer PSNR = 27.23, Composite SSIM = 0.950 (Table 2)
- PrismLayersPro trained CLD baseline: Layer FID = 6.62, Composite FID = 12.50 vs SynLayers 20K checkpoint: Layer FID = 5.97, Composite FID = 12.00 (Table 3)
- Qwen-Image-Layered: Layer PSNR = 13.80, Layer FID = 198.34 vs SynLayers 20K: Layer PSNR = 27.16, Layer FID = 5.97 (Table 3)
- Real-world OOD testset composite metrics: PrismLayersPro baseline PSNR = 28.74, FID = 44.23 vs SynLayers trained model PSNR = 29.35, FID = 35.40 (Table 4)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.15167.

Fig 1: Comparison between fully synthetic graphic-design data from SynLayers and non/partially-synthetic

Fig 2: Overview of construction of SynLayers. Multi-source assets, including base designs, RGBA/RGB

Fig 3: shows the samples selected from SynLayers. Each sample is generated through the following
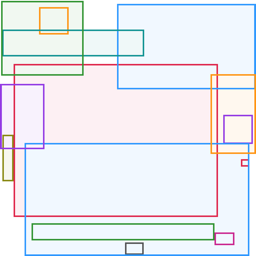
Fig 4: Qualitative comparison between the original PrismLayersPro-trained CLD baseline, our

Fig 5 (page 4).

Fig 6 (page 4).

Fig 7 (page 4).

Fig 8 (page 4).
Limitations
- Synthetic dataset construction relies on heuristics for layer placement and composition, which may limit naturalness or real-world complexity.
- Performance saturates at medium dataset scale (~50K samples), indicating further scaling may not yield consistent gains without new modeling improvements.
- Out-of-distribution evaluation is limited to composite image reconstruction metrics only; layer-level decomposition ground truth unavailable for OOD sets.
- The modeling approach assumes independence of layers and does not explicitly capture inter-layer dependencies or blending effects present in real designs.
- VLM-generated captions and bounding boxes introduce an upstream dependency which could propagate errors downstream; detected bounding box accuracy is not fully quantified.
- While code is released, the full 500K sample SynLayers dataset availability is unclear, potentially limiting reproducibility.
Open questions / follow-ons
- How to integrate more realistic inter-layer blending and complex compositional effects into synthetic datasets and model training?
- Can synthetic data be combined with limited real layered data to further improve generalization and robustness?
- What are the limits of scaling synthetic datasets beyond 500K samples for graphic layer decomposition tasks?
- How do improvements in upstream VLM detection accuracy for bounding box and caption generation affect overall decomposition quality?
Why it matters for bot defense
This work is relevant to bot-defense and CAPTCHA practitioners interested in layered image decomposition as it demonstrates that fully synthetic layered design datasets can effectively train models for decomposing complex multi-layered graphics. This decomposition enables downstream tasks such as selective editing, forgery detection, or segmentation that may be valuable for image-based bot detection pipelines. The study affirms that synthetic data, coupled with vision-language model supervision, can mitigate scarcity of well-labeled layered graphic data and provide scalable, balanced training sets aligned with real design complexities. Practitioners may leverage synthetic data generation pipelines to create diverse layered training examples at scale and automate bounding box and semantic inputs with VLMs, improving robustness and generalization of decomposition approaches integrated into anti-spam or anti-fraud CAPTCHA systems. Furthermore, understanding layer count distributions and data scaling effects informs data-centric strategies for balanced, high-coverage training to support novel graphic editing or verification workflows.
Cite
@article{arxiv2605_15167,
title={ Does Synthetic Layered Design Data Benefit Layered Design Decomposition? },
author={ Kam Man Wu and Haolin Yang and Qingyu Chen and Yihu Tang and Jingye Chen and Qifeng Chen },
journal={arXiv preprint arXiv:2605.15167},
year={ 2026 },
url={https://arxiv.org/abs/2605.15167}
}