
Cognitive-Uncertainty Guided Knowledge Distillation for Accurate Classification of Student Misconceptions
Source: arXiv:2605.14752 · Published 2026-05-14 · By Qirui Liu, Hao Chen, Weijie Shi, Jiajie Xu, Jia Zhu
TL;DR
This paper addresses the critical challenge of accurately classifying student misconceptions in mathematics education, which enables personalized feedback and adaptive tutoring. The problem is difficult due to three core challenges: scarcity of authentic data exhibiting long-tail distributions, fuzzy and noisy ground truth labels marking student reasoning errors, and a deployment paradox where large pre-trained models lack sensitivity to unconventional student reasoning but are computationally expensive, while small models overfit noise. To overcome these, the authors propose a novel two-stage knowledge distillation pipeline that mines high-value samples from existing limited real data instead of relying on synthetic data. The first stage transfers general task knowledge from a 72B-parameter teacher to lightweight student models via standard distillation with cross-validation. The second stage refines students by selecting critical samples through a novel dual-layer margin mechanism based on teacher model cognitive uncertainty, categorizing samples into "Near-miss" (low-confidence correct or nearly correct) and "Hard-hard" (grossly misclassified) subsets. Difficulty-adaptive loss functions then balance hard and soft label contributions to allow students to inherit teacher inter-class relationships while discriminating ambiguous categories. Their method achieves substantial gains on two benchmarks: a 17.8% improvement in MAP@3 to 0.9585 on the MAP-Charting dataset using only 10.3% of filtered samples and 84.38% accuracy on an algebra misconceptions benchmark with a 4B-parameter student model, outperforming much larger baseline models. The approach effectively creates lightweight, accurate models for edge deployment that better capture real student cognitive diversity and ambiguous misconceptions.
Key findings
- Using only 10.30% of filtered training samples selected via cognitive uncertainty, MAP@3 on MAP-Charting improves to 0.9585 (+17.8% over prior best).
- A 4B-parameter student model (Qwen-3-4B) achieves 84.38% accuracy on cross-topic middle school algebra misconception benchmark, outperforming a 72B standard fine-tuned model at 81.25% and sota LLM prompting models at 67.73%.
- Two-stage distillation (global distillation then sample-selection guided fine-tuning) consistently outperforms ablated variants: omitting stage-2 distillation drops algebra accuracy from 84.38% to 75.77%.
- Adaptive loss balancing soft and hard labels based on sample difficulty improves performance by ~0.4%–0.7% on MAP@3 and accuracy versus using static weighting.
- High-value sample selection via dual-layer margin method lowers error rates by 4.8% (from 8.99% to 8.43%) on MAP-Charting and reduces top-5 misclassification errors, particularly improving ambiguous class discrimination.
- Lightweight student models achieve up to 187.5× speedup in inference time over large models (Qwen-3-4B runs inference in 0.008h vs GPT-5 1.50h on 7,339 samples) with better accuracy.
- Optimal near-miss selection threshold δ=0.05 and 5-fold cross-validation maximize MAP@3 performance; deviation from these reduces gains.
- Multi-stage distillation especially improves fine-grained classification of ambiguous misconceptions, as visualized in reduced error counts across difficult categories (Fig 3).
Threat model
n/a — this work does not focus on adversarial threat models but rather on improving learning from scarce, noisy educational data. The framework assumes no malicious adversaries attempting to subvert classification, only inherent label noise and data scarcity challenges.
Methodology — deep read
Threat Model & Assumptions: The adversary is not directly modeled since this is an educational AI task; however, the framework assumes access only to limited real student reasoning data, labeled with noisy, fuzzy human annotations of misconception types. The model must learn to generalize despite label noise and ambiguous boundaries between error categories. It must also respect deployment constraints (privacy, edge devices), ruling out large models.
Data: Two benchmark datasets are used: (a) MAP-Charting with 36,695 real student samples capturing full problem statements, answers, and written reasoning explanations labeled as Correct, Misconception types, or Neither; (b) Algebra Misconceptions Benchmark with 220 samples classified into 55 misconception types, using only final answers without reasoning trace. Data is split into stratified folds for cross-validation. Preprocessing details are limited but include label stratification and split.
Architecture / Algorithm: Models: Teacher is Qwen-2.5-72B (large model) fine-tuned on task; students are smaller models Qwen-3-4B, Gemma-2-9B, Llama-3.1-8B. The teacher generates soft labels with probabilistic outputs.
Two-stage Distillation Pipeline:
- Stage 1: Global Knowledge Distillation. Perform n-fold cross-validation (optimal n=5) to produce teacher soft labels for each data fold, training student models with combined loss: L = α·L_CE(hard label) + β·L_KD(KL divergence with teacher soft labels) + γ·L_COS(cosine embedding loss enforcing teacher-student representation alignment).
- Stage 2: High-Value Sample Selection and Adaptive Refinement. Teacher model uncertainty is used to partition samples into categories:
- Near-miss (SNM): correct or almost correct but uncertain predictions near decision boundaries.
- Hard-hard (SHH): grossly incorrect predictions with low ranking true labels.
A dual-layer margin selection mechanism computes a composite difficulty metric combining probability margin (difference between predicted true label probability and maximum other label probability) and prediction entropy to further divide SNM/SHH into “close” and “far” subsets.
Adaptive loss weights (α, β, γ) are dynamically assigned per subset to balance the influence of hard labels vs. teacher soft labels, allowing the student to leverage inter-class relationships while tolerating label noise and subtle category boundaries. Details include favoring hard labels near boundaries and soft labels for very difficult or noisy samples.
- Training Regime: AdamW optimizer with batch size 16 (4 gradient accumulation steps), learning rates:
- Stage 1: Student LR 2e-4, teacher LR 1e-4, distillation temperature τ=1.0
- Stage 2: Student LR 1e-6 Training run on 8 × H20 GPUs; stratified 5-fold cross-validation used to avoid overfitting and generate robust soft labels. Seeds and hyperparameter grids tuned for loss weights and threshold δ.
Evaluation Protocol: Metrics: MAP@3, MAP@10, Accuracy, and F1@3 measured on held-out test splits for both datasets. Baselines include prompting on large LLMs (GPT-5, Claude-4-Sonnet, DeepSeek-V3), direct fine-tuning of large and small models, and ablated variants of their method. Error count visualization on top confused categories used to analyze effects of multi-stage distillation.
Reproducibility: Code is released publicly. Teacher model Qwen-2.5-72B and student models are standard open architectures. MAP-Charting dataset is public. Algebra Misconceptions dataset provenance cited but may be restricted. Detailed hyperparameter and loss weight choices described in appendices.
Example end-to-end: A student explanation with ambiguous reasoning is input. After stage 1 global distillation, the teacher model labels it with soft probabilities and the student model trains on these. In stage 2, uncertainty metrics identify the example as near-miss with high entropy, triggering adaptive loss to emphasize soft label guidance. Student learns to better distinguish subtle misconception categories, improving its multi-class classification accuracy.
Technical innovations
- Two-stage knowledge distillation framework that first transfers general task knowledge globally, then refines on a filtered subset of high-value samples identified via cognitive uncertainty.
- Dual-layer margin-based sample selection mechanism categorizing critical samples into near-miss and hard-hard types using teacher model prediction confidence gaps and rank-based heuristics.
- Composite difficulty metric combining probability margin and prediction entropy to split uncertain samples further for fine-grained adaptive training.
- Difficulty-adaptive loss function dynamically balancing hard label and soft label contributions per sample difficulty subset to address label noise and boundary ambiguity.
- Demonstration that lightweight student models distilled this way can outperform much larger teacher and prompting models on real noisy educational data.
Datasets
- MAP-Charting — 36,695 samples — public dataset with student answers and reasoning explanations
- Algebra Misconceptions Benchmark — 220 samples — from 145 peer-reviewed algebra misconception types
Baselines vs proposed
- GPT-5 prompting: MAP@3 = 0.8137 vs proposed Qwen-3-4B + Ours: MAP@3 = 0.9585 (MAP-Charting)
- Qwen-2.5-72B direct fine-tuning: Accuracy = 81.25% vs Qwen-3-4B + Ours: Accuracy = 84.38% (Algebra Benchmark)
- Qwen-3-4B direct fine-tuning: MAP@3 = 0.9472 vs Qwen-3-4B + Ours: MAP@3 = 0.9585 (MAP-Charting)
- Removing stage-2 distillation drops accuracy from 0.9198 to 0.9024 (MAP-Charting) and from 0.8438 to 0.7577 (Algebra Benchmark)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.14752.
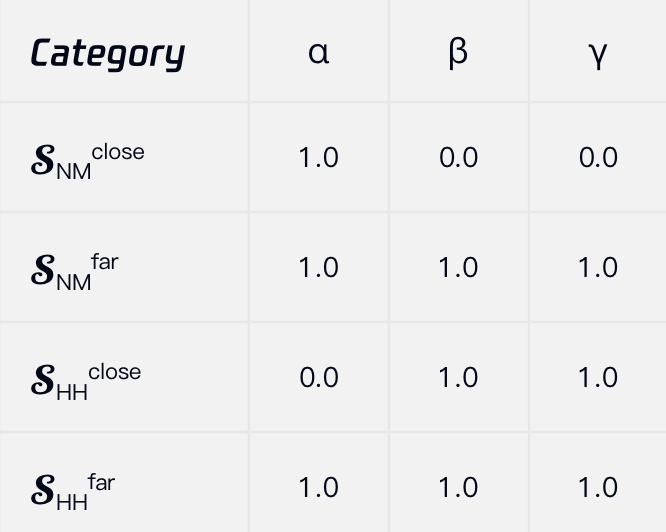
Fig 2: Overview of our two-stage distillation framework, consisting of data partitioning, two-stage knowledge
Limitations
- High computational overhead due to stratified K-fold (K=5) cross-validation for generating soft labels and evaluating hyperparameters limits scalability and exploration in resource-constrained settings.
- Limited model gains when incoming data quality is poor; the filtering-based approach cannot compensate for fundamentally low-quality or insufficiently diverse samples.
- No explicit adversarial robustness or out-of-distribution evaluation; generalization to unseen student populations or problem types is unclear.
- Dependency on teacher model quality; if the teacher model's biases or errors are strong, these may propagate despite adaptive weighting.
- Limited ablation on sample selection hyperparameters beyond threshold δ; sensitivity to these choices in other datasets unknown.
Open questions / follow-ons
- Can this two-stage cognitive uncertainty framework be extended to continually adapt student models with streaming real student data in deployment?
- How would this method perform under active adversarial manipulation of student inputs or labels designed to fool misconception classifiers?
- Could incorporating multi-task learning for related educational tasks (e.g., answer correctness and misconception jointly) improve adaptive loss weighting and selection?
- What are the effects of combining synthetic data with uncertainty-guided sampling to improve coverage of rare misconception classes?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper highlights a structured approach to learning robust classifiers under data scarcity and label ambiguity by combining teacher-student distillation with guided sample selection based on cognitive uncertainty metrics. While the context is educational AI, the principle of focusing training on boundary samples with adaptive loss weighting could inspire bot detection systems facing similar class overlap and label noise challenges. The methodology offers a way to improve small model robustness against ambiguous input behaviors while maintaining efficient inference for edge deployment, a common bottleneck in CAPTCHA systems. Applying dual-layer margin-based uncertainty to select high-value examples and balancing hard/soft label influence could improve classifier generalization to sophisticated, borderline bot-like user behavior.
Cite
@article{arxiv2605_14752,
title={ Cognitive-Uncertainty Guided Knowledge Distillation for Accurate Classification of Student Misconceptions },
author={ Qirui Liu and Hao Chen and Weijie Shi and Jiajie Xu and Jia Zhu },
journal={arXiv preprint arXiv:2605.14752},
year={ 2026 },
url={https://arxiv.org/abs/2605.14752}
}