
CLOVER: Closed-Loop Value Estimation & Ranking for End-to-End Autonomous Driving Planning
Source: arXiv:2605.15120 · Published 2026-05-14 · By Sining Ang, Yuguang Yang, Canyu Chen, Yan Wang
TL;DR
This paper addresses a fundamental training-evaluation mismatch in end-to-end autonomous driving planning, where models imitate a single logged trajectory but are evaluated by rule-based planning metrics (e.g., safety, feasibility, progress, comfort). Imitation can collapse candidate proposals around one demonstrated behavior, failing to generate or select diverse, high-quality trajectories that may score better under the true evaluator. To tackle this, the authors propose CLOVER, a closed-loop framework combining a generator that produces diverse candidate trajectories with a scorer that predicts planning-metric sub-scores for ranking. CLOVER explicitly expands the candidate proposal space beyond single-trajectory imitation by constructing evaluator-filtered pseudo-expert trajectories and trains the generator with set-level coverage supervision. Then, it performs conservative closed-loop self-distillation, where the scorer is trained to match evaluator sub-scores on generated proposals, and the generator is refined towards teacher-selected top-k and vector-Pareto target trajectories guided by the scorer, with stability regularization to avoid collapse.
The paper provides a theoretical analysis showing that an imperfect scorer can effectively guide generator improvement when scorer-selected targets are statistically enriched under the true evaluator and updates are conservative. Empirically, CLOVER achieves new state-of-the-art results on NAVSIM benchmarks (94.5 PDMS and 90.4 EPDMS on NAVSIM v1 and v2 respectively) and matches top results on the NavHard split (48.3 EPDMS). Supplementary open-loop evaluation on nuScenes also shows lowest L2 trajectory error and collision rate among baselines. Ablations validate the necessity of both pseudo-expert coverage and closed-loop self-distillation for best performance. Overall, CLOVER demonstrates that explicitly coupling generation and scoring within a closed training loop substantially improves proposal quality, diversity, and downstream planning evaluation.
Key findings
- CLOVER achieves 94.5 PDMS on NAVSIM v1, outperforming the strong DrivoR baseline by 0.8 points and ranking first or second across all PDMS sub-scores (Table 1).
- On NAVSIM v2, CLOVER attains 90.4 EPDMS under the official updated implementation, surpassing prior methods such as SparseDriveV2 (86.7 EPDMS) and DriveSuprim (86.0 EPDMS) (Table 2).
- On the challenging NavHard two-stage split, CLOVER matches the strongest reported result with 48.3 EPDMS, improving over DrivoR’s 48.3 but with better sub-score consistency (Table 3).
- Supplementary nuScenes open-loop evaluation shows CLOVER achieves lowest L2 error (0.31 m ST-P3 protocol, 0.65 m UniAD protocol) and best or tied-best collision rate (0.10% ST-P3, 0.30% UniAD) among compared methods (Table 4).
- Stage 1 pseudo-expert coverage training increases proposal diversity drastically, raising Oracle@64 from 0.9933 to 0.9976 and pairwise ADE from 1.80 to 5.97 compared to the baseline (Table 5).
- Stage 2 conservative closed-loop self-distillation improves scorer-selected PDMS from 0.9369 (baseline) to 0.9448 and raises mean proposal PDMS to 0.8277 while preserving diversity (Table 5).
- Theoretical condition: scorer-selected top-k/vector-Pareto target sets must be statistically enriched in true high-quality trajectories (e.g., >34% empirical enrichment gap); CLOVER meets this (69.74% vs 35.42% full-score proposals in NAVSIM) and thus the scorer guidance reliably improves the generator.
- Ablations (Table 6) show pseudo-expert supervision alone raises PDMS from 93.7 to 94.1, closed-loop refinement alone yields 93.8, and combining both achieves the best 94.5 PDMS, confirming synergistic effect.
Threat model
The adversary is not explicitly modeled, as CLOVER is an offline learning framework for autonomous driving trajectory planning. The method assumes access only to logged driving scenes, sensor observations, map data, and a non-differentiable rule-based evaluator. There is no online environment interaction or exploration; hence, adversaries capable of runtime manipulation, sensor spoofing, or active adversarial planning are outside the scope. CLOVER focuses on improving proposal quality and ranking within this observational and evaluation framework.
Methodology — deep read
Threat Model & Assumptions: CLOVER assumes an offline training setting with logged driving scenes and a non-differentiable rule-based evaluator providing ground-truth planning scores. The adversary is not explicitly modeled, but the setup assumes reliance on offline data without interactive environment access or trial-and-error exploration, differentiating CLOVER from RL-style methods. The goal is to better align training and evaluation metrics for trajectory planning.
Data: Training uses NAVSIM datasets (v1, v2, NavHard splits) containing logged driving trajectories, multi-view camera images, ego state information, and map data. For pseudo-expert coverage, augmented pseudo-expert trajectory sets are constructed offline from interpretable candidate families with privileged info (e.g., map centerlines, drivable areas, occupancy). The generator is trained on sets of 64 candidates per scene, horizon 4 seconds sampled every 0.5s (8 timesteps).
Architecture / Algorithm: CLOVER uses a generator-scorer proposal-selection model: the generator G_θ(o) outputs K=64 candidate future ego poses, each as (x,y,θ) sequences over T=8 timesteps, from camera + ego-state via DINOv2-Small backbone plus Transformer decoder with trajectory queries. The scorer S_ϕ(o, τ) predicts a vector of planning-metric sub-scores per candidate trajectory, covering safety, feasibility, comfort, and progress components. Inference selects the trajectory maximizing composed predicted evaluator score.
Stage 1 training expands proposal coverage by constructing evaluator-filtered pseudo-expert trajectories for each scene, spanning diverse lateral offsets, speed profiles, boundary behaviors, and rejects invalid ones by map/occupancy checks. These sets are used to provide coverage supervision on the proposal set: losses drive the generator to cover not just the logged trajectory but multiple diverse feasible modes, while pretraining the scorer on true evaluator sub-scores.
Stage 2 performs conservative closed-loop self-distillation alternating two phases: (a) The scorer is trained/fitted on generated proposals with evaluator-provided sub-scores via regression/classification losses. (b) The generator is refined by distilling teacher-generated trajectories selected by the frozen scorer into two target sets — top-k highest scored trajectories and a vector-Pareto set (non-dominated proposals regarding multiple sub-score dimensions) — with stability regularization to prevent divergence from the teacher distribution.
Training regime: Stage 1 pretraining enlarges proposal diversity under set-coverage losses plus scorer pretraining. Stage 2 uses iterative alternating updates of scorer fitting and generator refinement with teacher selections. Training details (epochs, batch size, optimizer) are in the appendices; hyperparameters weight logged trajectory imitation, pseudo-expert coverage, scorer regression, top-k and vector-Pareto distillation, and stability losses.
Evaluation protocol: Evaluation uses the NAVSIM benchmark suite measuring PDMS (planning decision metric score) and EPDMS (extended PDMS) involving safety, progress, comfort, and feasibility sub-scores. Held-out NAVSIM splits use different difficulty levels (navtest, navhard). Evaluation includes open-loop nuScenes benchmark on L2 displacement error and collision rate. Ablations isolate impact of pseudo-expert coverage, closed-loop distillation, teacher-set construction, and reranking. Additional diagnostics include oracle proposal coverage, proposal diversity (pairwise ADE/FDE), and scorer ranking accuracy versus true evaluator.
Reproducibility: Authors commit to releasing code and generated data at the specified GitHub repository. Exact details on data preprocessing, hyperparameters, and model architecture are in appended sections but the NAVSIM dataset is closed-source. Therefore, full replication requires access to NAVSIM environment and pseudo-expert candidate construction.
End-to-end example: A scene observation (multi-view cameras plus ego state) is encoded via DINOv2 outputs to a scene representation. The generator outputs K=64 future candidate trajectories. Each trajectory is scored by the scorer predicting sub-scores matching the official planning metrics. During training Stage 1, the generator is taught to cover a set of pseudo-expert trajectories filtered by the evaluator. During Stage 2, the scorer is fit to true sub-scores on freshly generated proposals, and then the generator is refined to cover teacher-selected top-k and vector-Pareto sets from the scorer, maintaining stability by limiting the divergence from previous proposals. At inference, only the trained generator and scorer run: proposals are generated, scored, and the top-ranked trajectory is selected for autonomous driving execution.
Technical innovations
- Closed-loop generator-scorer training that tightly couples proposal generation and trajectory scoring to address training-evaluation mismatch for autonomous driving planning.
- Evaluator-filtered pseudo-expert trajectory construction that expands single-trajectory imitation into set-level multi-modal coverage supervision, improving candidate diversity and oracle bounds.
- Conservative closed-loop self-distillation alternating scorer fitting on true evaluator sub-scores with generator refinement toward scorer-selected top-k and vector-Pareto target trajectories, stabilizing updates and preventing mode collapse.
- Theoretical analysis establishing that scorer-mediated generator refinement is reliable under a selected-set enrichment condition, allowing an imperfect scorer to effectively guide generator improvement offline.
Datasets
- NAVSIM v1 — 12,146 scenes common evaluation split — closed-source internal dataset
- NAVSIM v2 (navtest split) — larger, extended planning evaluation split — closed-source
- NavHard (navhard-two-stage split) — challenging NAVSIM variant — closed-source
- nuScenes open-loop validation subset — publicly available autonomous driving dataset
Baselines vs proposed
- DrivoR baseline: NAVSIM v1 PDMS = 93.7 vs CLOVER = 94.5
- DrivoR baseline: NAVSIM v2 EPDMS = ~86.7 vs CLOVER = 90.4
- DrivoR baseline: NavHard EPDMS = 48.3 vs CLOVER = 48.3 (tie but improved sub-scores)
- Best prior nuScenes open-loop method collision rate = 0.10% vs CLOVER = 0.10% (ST-P3)
- Pseudo-expert coverage only: NAVSIM v1 PDMS = 94.1 vs baseline 93.7
- Closed-loop refinement only: NAVSIM v1 PDMS = 93.8 vs baseline 93.7
- Scalar top-k teacher set: NAVSIM v1 PDMS = 93.9 vs vector-Pareto set: PDMS = 94.5
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.15120.
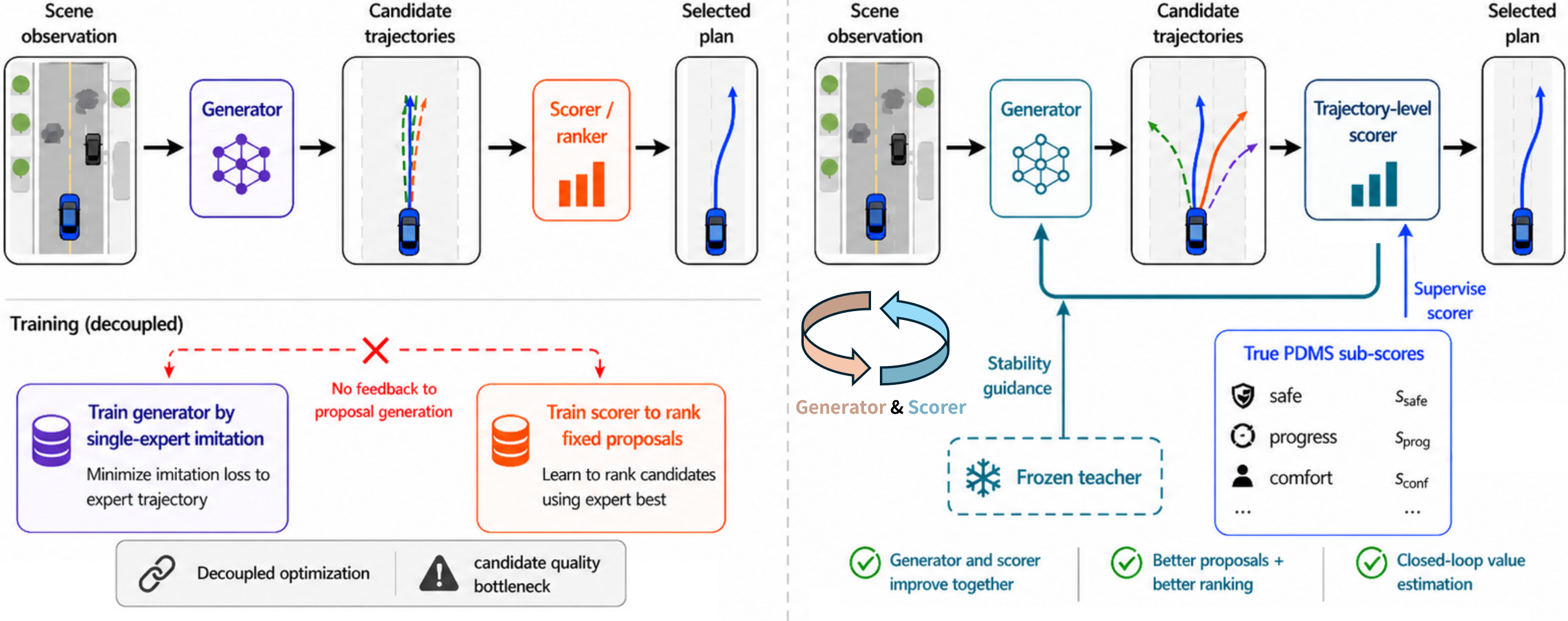
Fig 1: CLOVER closes the loop between proposal generation and trajectory ranking. Left:
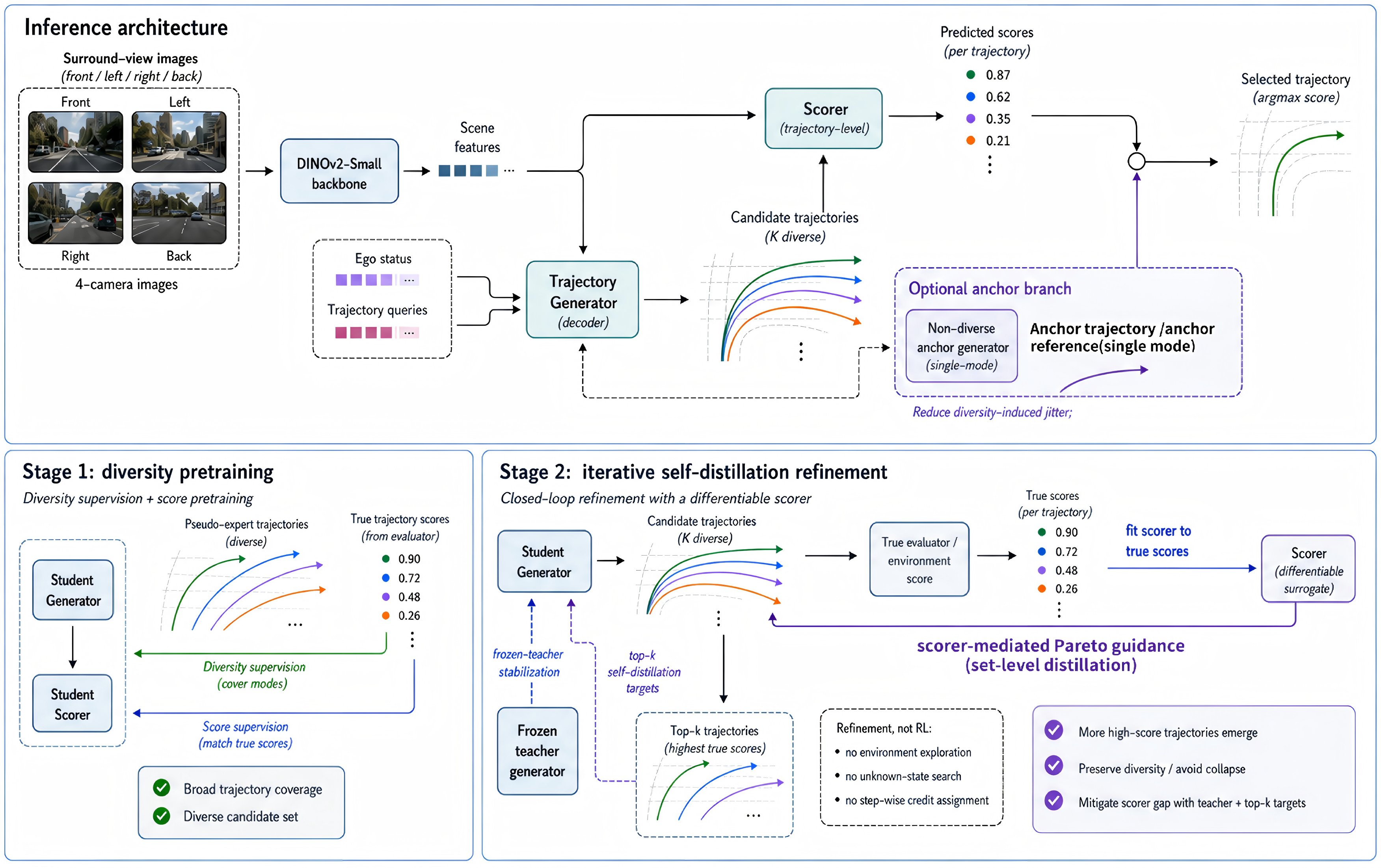
Fig 2: Overview of CLOVER. At inference time, multi-view images and ego state are encoded

Fig 3: Qualitative proposal diversity. Compared with the DrivoR baseline, which concentrates
Fig 4: Visualization of pseudo-expert trajectory candidates. We show representative pseudo-

Fig 5: Additional qualitative comparisons of proposal diversity on six scenes. In each row,
Limitations
- Method depends on access to privileged map and future occupancy information offline to construct pseudo-expert trajectories — not available at deployment.
- Evaluator is non-differentiable and computation intensive; training relies on offline logged data and cannot leverage online environment interactions or exploration.
- NAVSIM datasets used for evaluation and training are closed-source and not publicly available, limiting direct reproducibility.
- Scorer must be sufficiently accurate to select enriched target sets; performance may degrade if scorer errors increase or distribution shifts occur.
- Open-loop nuScenes experiments are supplementary and limited; no closed-loop real-world driving or adversarial attack evaluation presented.
- Though stability regularization prevents generator collapse, training requires careful hyperparameter tuning and iterative alternating optimization, which may be computationally expensive.
Open questions / follow-ons
- How does CLOVER’s performance and robustness transfer to distribution shifts or unseen driving environments outside NAVSIM?
- Can the closed-loop generator-scorer training framework be extended to incorporate online environment interactions or reinforcement learning with real or simulated environment feedback?
- What are the effects of noisy or imperfect pseudo-expert trajectory construction on final planning quality and stability?
- Could similar closed-loop value estimation and set-level distillation ideas improve multimodal planning in other robotics domains beyond autonomous driving?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, CLOVER’s approach highlights the importance of closing the loop between generation and evaluation/scoring in complex sequential decision tasks. The key insight is that training data limited to a single logged example can fail to cover the full space of feasible, high-quality behaviors — an effect analogous to naive bots being trained on limited CAPTCHAs and failing to generalize to variants. Techniques like evaluator-filtered multi-modal supervision and conservative self-distillation could inspire bot-defense designs that better recognize and adapt to diverse adversarial or legitimate user behaviors by leveraging multi-candidate hypotheses rather than single-trial imitation.
Additionally, CLOVER’s theoretical condition requiring enriched sets of high-value candidates selected by an imperfect scorer aligns with practical CAPTCHA detector design: even a noisy ranking system can drive improvement if it can filter subsets statistically enriched for genuine or bot responses. The dual emphasis on coverage diversity and reliable scoring balancing parallels challenges in automated bot detection, where diversity of adversarial behavior and reliable scoring metrics must be jointly balanced. Although the domain differs, the underlying closed-loop training and evaluation mismatch insights are broadly relevant.
Cite
@article{arxiv2605_15120,
title={ CLOVER: Closed-Loop Value Estimation \& Ranking for End-to-End Autonomous Driving Planning },
author={ Sining Ang and Yuguang Yang and Canyu Chen and Yan Wang },
journal={arXiv preprint arXiv:2605.15120},
year={ 2026 },
url={https://arxiv.org/abs/2605.15120}
}