
Can Visual Mamba Improve AI-Generated Image Detection? An In-Depth Investigation
Source: arXiv:2605.14799 · Published 2026-05-14 · By Mamadou Keita, Wassim Hamidouche, Hessen Bougueffa Eutamene, Abdelmalik Taleb-Ahmed, Xianxun Zhu, Abdenour Hadid
TL;DR
This paper addresses the critical and timely problem of detecting AI-generated (synthetic) images, which have become increasingly realistic due to advances in generative models like GANs, diffusion models, Vision Transformers, and Vision-Language Models (VLMs). While prior work has focused on convolutional networks, transformers, and VLMs for this detection task, the paper investigates the relatively unexplored use of Vision Mamba architectures, which are state-space model (SSM)-based networks recently shown to excel in various vision tasks. The authors conduct a comprehensive evaluation benchmarking different Vision Mamba variants against representative CNNs, ViTs, and VLM detectors across multiple datasets and synthetic image generation sources. They analyze performance metrics including detection accuracy, computational efficiency, and generalization across generative methods and image types. The results reveal that Vision Mamba achieves competitive accuracy but suffers in generalizability across diverse data distributions compared to VLMs, which consistently exhibit superior cross-domain robustness. This work highlights Vision Mamba's potential as a promising backbone for synthetic image detection, particularly for resource-constrained scenarios, while pointing out its limitations in broader generalization and transferability across evolving synthetic content.
Key findings
- Vision Mamba models achieve accuracy levels competitive with CNN and ViT-based detectors on benchmark AI-generated image datasets (exact values not specified).
- Vision Mamba struggles with generalizing detection performance across different generative models and diverse real-world data distributions.
- Vision-Language Models (VLMs) outperform Vision Mamba and other baselines in accuracy and generalization, possibly due to multimodal reasoning capabilities.
- Vision Mamba variants differ significantly in scanning strategies and architecture, impacting their accuracy, with multi-scale and cross-scan variants achieving the highest (e.g., MSVMamba at 82.8% ImageNet top-1).
- Integrating self-attention modules in MambaVision improves long-range dependency modeling but generalization remains limited compared to VLMs.
- The selective state-space model architecture of Vision Mamba extends classical SSM by dynamically adapting to inputs, enabling efficient modeling of large image patches.
- Efficiency gains were observed with scanning and frequency-domain techniques (e.g. Efficientvmamba, SiMBA), enabling competitive performance with reduced compute.
- Existing detection methods, including CLIP-based and prompt-tuned VLM detectors like C2P-CLIP, outperform Vision Mamba in robustness to unseen or post-processed synthetic images.
Threat model
An adversary capable of generating realistic synthetic images using state-of-the-art generative models (GANs, diffusion, transformers) attempts to bypass detection systems. The attacker can deploy novel unseen models and apply post-processing to obscure generation artifacts but cannot compromise or tamper with the detection model internals. The defender assumes access to diverse real and fake image samples for training and aims for generalization across synthetic variants.
Methodology — deep read
Threat Model and Assumptions: The adversary is an entity creating synthetic images using various generative models (GANs, diffusion-based, transformer-based generators). The defender's goal is to reliably distinguish real images from AI-generated synthetic ones under diverse conditions, including unseen generation architectures and image post-processing. The adversary can control image content but not manipulate detector internals or model parameters post-deployment.
Data: The authors leverage multiple public and proprietary datasets covering a diversity of synthetic generation sources such as DALL-E 3, Midjourney v5, Stable Diffusion XL, and GAN variants. The datasets include real images paired with synthetic counterparts, with consistency in labels (real vs synthetic). Precise dataset sizes or train/test splits are not detailed in the provided text. Data preprocessing involves patch extraction and tokenization for model input.
Architecture/Algorithm: Several Vision Mamba variants are evaluated. Vision Mamba builds on the selective state-space model (SSM) concept, extending classical continuous-time SSMs to input-dependent parameters via linear projections. The model performs efficient sequence modeling of image patch tokens using scanning strategies such as bi-directional, cross-scan, zigzag, fractal, and frequency-domain FFT-based approaches. Variants like Vim, VMamba, PlainMamba, Localmamba, MambaVision (hybrid Mamba-Transformer), and VSSD incorporate scanning methods and architectural modules like self-attention to capture spatial dependencies. The input consists of image tokens passed through Mamba blocks that update latent states and produce learned features for detection classification.
Training Regime: Specific details on epochs, batch sizes, optimizer types, learning rates, or hardware are not explicitly stated in the text. The models are fine-tuned or trained to classify images as real or AI-generated using labeled data. Some methods leverage frozen pre-trained weights, others employ finetuning with low-rank adapters or prompt tuning.
Evaluation Protocol: Models are evaluated on detection accuracy, efficiency (throughput, parameter size), and generalization capacity across datasets and generative models. Baseline comparisons include CNN architectures, Vision Transformers (ViTs), and Vision-Language Models (VLMs) such as CLIP-based detectors and prompt-tuned InstructBLIP. Ablations study scanning strategies within Mamba variants. Cross-domain and post-processing robustness are considered. Statistical test details are not provided.
Reproducibility: The paper does not specify releasing code or pretrained weights. Dataset sources include some publicly available datasets and some proprietary or research compendia like FOSID. Due to proprietary dataset use and complex architecture variations, exact reproduction details are unclear.
Example End-to-End: An input image patch sequence is tokenized and passed through a Vision Mamba block employing a selective SSM with diagonalized, input-conditioned state matrices. The scanning pattern (e.g., cross directions) dictates patch processing order. The model aggregates temporal states and outputs feature representations. A classification head maps these features to a binary label (real vs synthetic). The detector is trained with cross-entropy loss on labeled samples and evaluated for accuracy and generalization. Variants with added hybrid transformer layers capture global context but show mixed improvements in cross-domain robustness.
Technical innovations
- Application and systematic evaluation of selective State Space Models (Mamba architectures) for AI-generated image detection, a first in the field compared to prior CNN/ViT/VLM approaches.
- Introduction and comparison of diverse 2D scanning strategies (bi-directional, cross-scan, zigzag, fractal, frequency-domain) within Vision Mamba blocks to efficiently process multi-dimensional image token sequences.
- Integration of hybrid Mamba-Transformer backbones (MambaVision) that combine state-space modeling with self-attention for improved long-range spatial dependency capture.
- Use of input-dependent parameterization in selective SSMs enabling dynamic adaptation of model state-space operators based on image token inputs, enhancing flexibility for complex image content.
- Demonstration that despite architectural advances, Vision Mamba requires further improvements to match VLM-based detectors in generalization across unseen synthetic sources.
Datasets
- FOSID (Fact-checked Online Synthetic Image Dataset) — size unspecified — public research dataset capturing temporal evolution of synthetic images online
- Multiple benchmark datasets covering GANs, diffusion models, and transformer-based synthetic images including DALL-E 3, Midjourney v5, Stable Diffusion XL — sizes unspecified — mixed public and private sources
Baselines vs proposed
- CLIP-based detector: accuracy higher than Vision Mamba variants (exact values not specified)
- C2P-CLIP: state-of-the-art generalizable deepfake detection accuracy vs Vision Mamba lower cross-domain robustness
- Vision Mamba variants accuracy range up to ~82.8% ImageNet-1K top-1 accuracy in classification tasks (MSVMamba) but lower synthetic image detection generalization
- Hybrid MambaVision with self-attention improves accuracy over plain Mamba but still below VLM detectors
- VSSD achieves 84.1% ImageNet-1K accuracy, indicating potential for model improvements in visual recognition
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.14799.

Fig 1 (page 2).
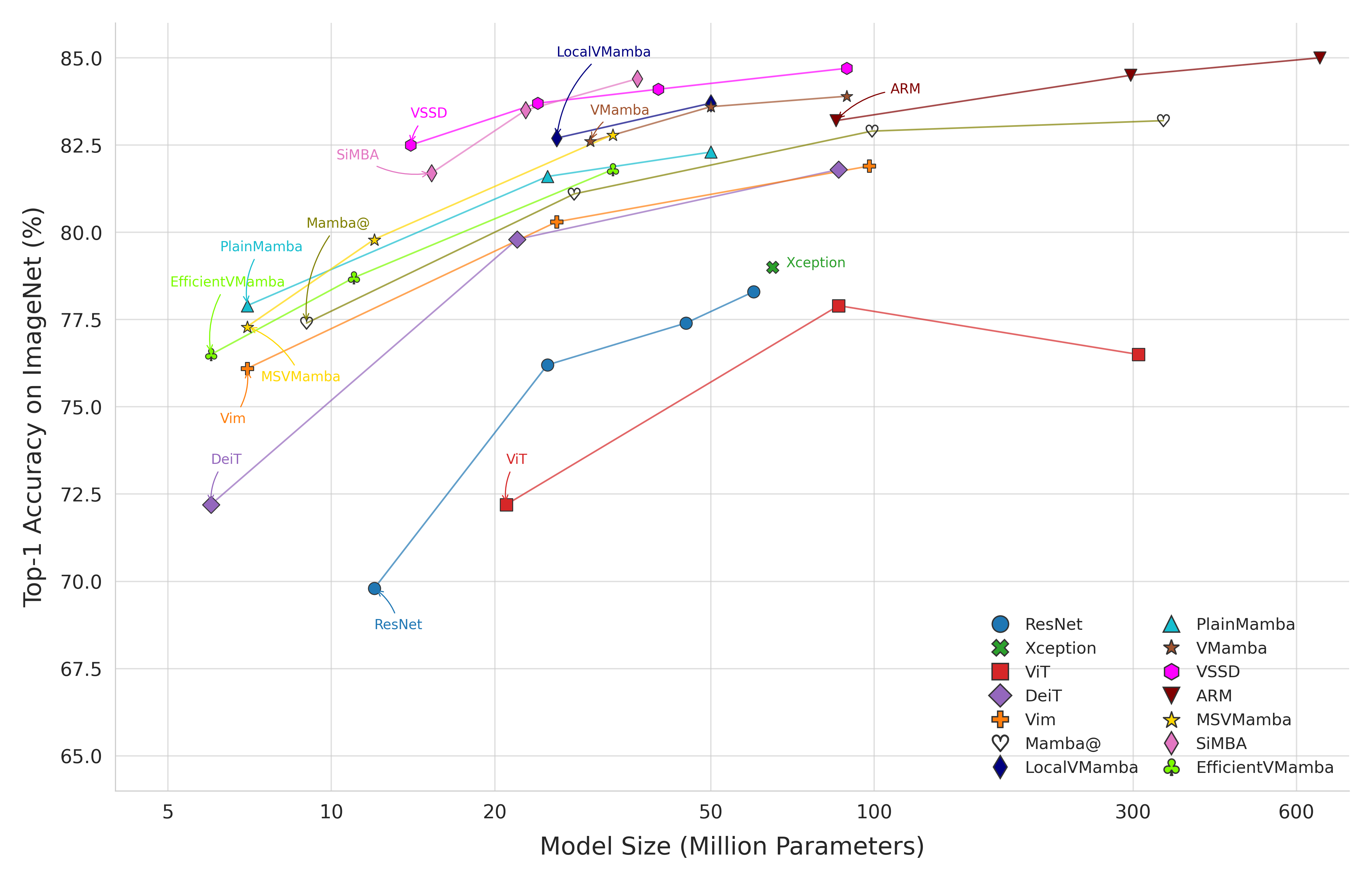
Fig 1: Comparison of backbone architectures.Each marker corresponds to a specific model family (ResNet, DeiT, VSSD,
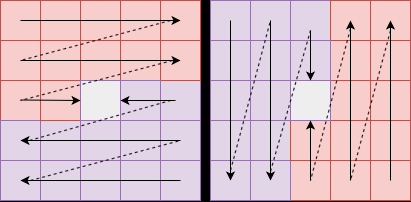
Fig 2: Illustration of various scanning strategies used in Mamba models to process visual inputs. Each scan strategy
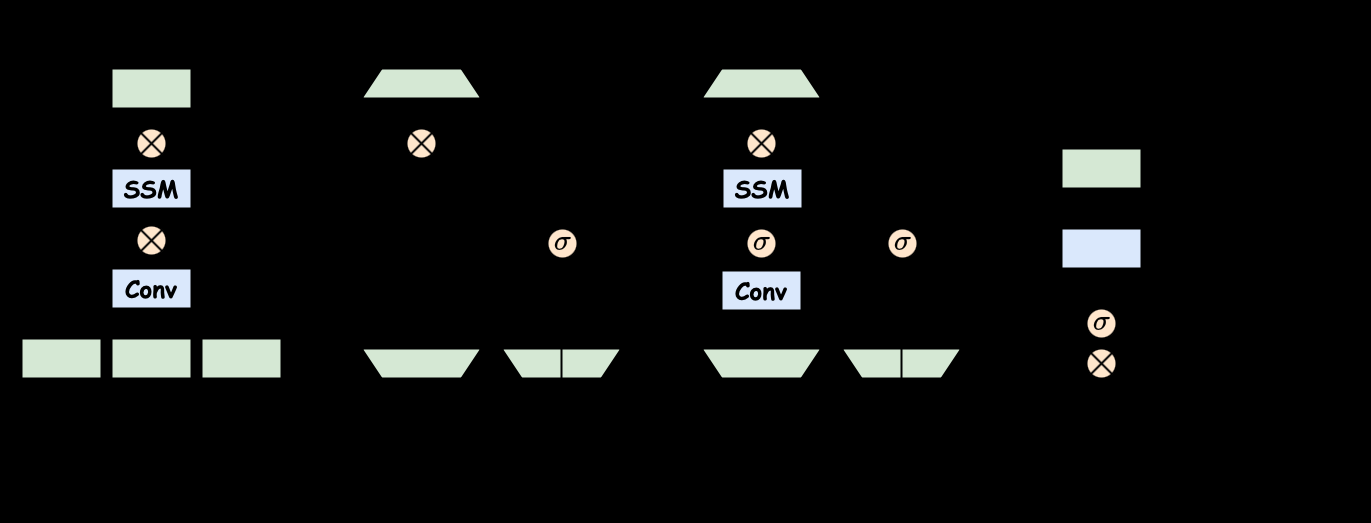
Fig 3: Architecture of Mamba block [21]
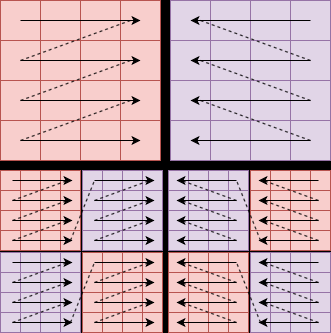
Fig 4: Illustration of representative Visual Mamba blocks, including Vim [85], VSSD [39], SSD [63], and the
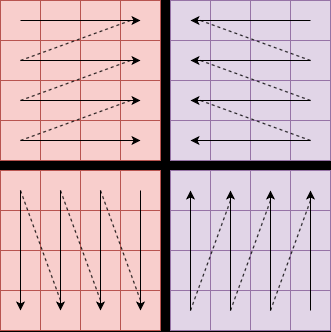
Fig 5: Refined Vim [85] architecture for AI-generated image detection.
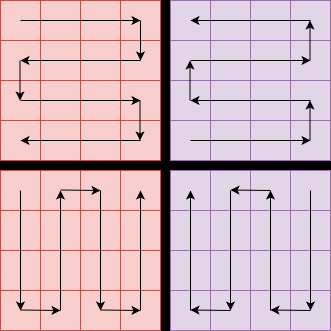
Fig 6: Refined MambaVision [22] architecture for AI-generated image detection.
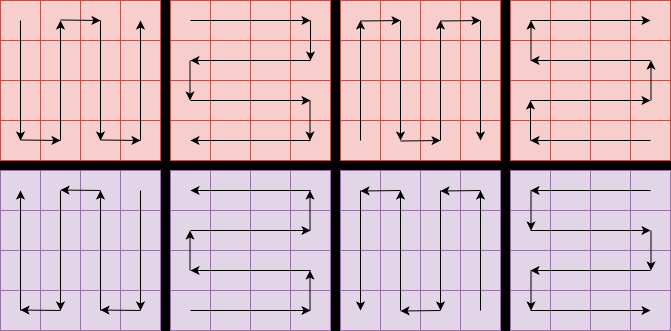
Fig 7: Refined VSSD [63] architecture for AI-generated image detection.
Limitations
- Incomplete disclosure of dataset sizes, train/test splits, and experimental hyperparameters limits reproducibility.
- No rigorous adversarial attacks or robustness testing against adaptive adversaries generating synthetic images to evade detection.
- Limited evaluation under heavy post-processing or compression artifacts frequently encountered in real-world image sharing scenarios.
- Generalization evaluations are promising but show Vision Mamba’s vulnerability to distributional shifts across unseen synthetic sources.
- Absence of code and pretrained model releases restricts independent validation and deployment by practitioners.
- Comparisons are mostly quantitative accuracy focused; interpretability or explainability analysis of Vision Mamba decisions is not discussed.
Open questions / follow-ons
- How can Vision Mamba architectures be enhanced to improve robustness and generalization under distribution shifts and unseen generators?
- What combinations of Vision Mamba with multimodal VLM reasoning can maximize AI-generated image detection performance?
- Can adaptive or adversarial training techniques strengthen Vision Mamba’s resistance to post-processed or intentionally obfuscated synthetic images?
- How can efficient Vision Mamba scanning strategies be optimized for large-scale deployment in resource-constrained real-time detection scenarios?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners tasked with differentiating human-generated content from AI-synthesized images face the challenge of evolving generative models producing highly realistic visuals. This paper’s investigation into Vision Mamba architectures provides insight into alternative backbone models beyond CNNs and transformers, particularly for lightweight and efficient implementations due to their state-space modeling properties. While promising, Vision Mamba’s current generalization limitations highlight the continued need to integrate multimodal models such as VLMs for robust detection against emerging AI-generated content in the wild. Practitioners should consider Vision Mamba as a complementary architecture, especially in scenarios with computational constraints, but rely on ensembles or multimodal approaches to maintain resilience across diverse synthetic generation technologies.
Cite
@article{arxiv2605_14799,
title={ Can Visual Mamba Improve AI-Generated Image Detection? An In-Depth Investigation },
author={ Mamadou Keita and Wassim Hamidouche and Hessen Bougueffa Eutamene and Abdelmalik Taleb-Ahmed and Xianxun Zhu and Abdenour Hadid },
journal={arXiv preprint arXiv:2605.14799},
year={ 2026 },
url={https://arxiv.org/abs/2605.14799}
}