
QLAM: A Quantum Long-Attention Memory Approach to Long-Sequence Token Modeling
Source: arXiv:2605.13833 · Published 2026-05-13 · By Hoang-Quan Nguyen, Sankalp Pandey, Khoa Luu
TL;DR
This paper addresses the challenge of modeling long-range dependencies in very long sequential data, where classical Transformers face quadratic computational costs and classical state-space models (SSMs) compress memory linearly but can lose expressivity. The authors propose Quantum Long-Attention Memory (QLAM), a novel hybrid quantum-classical framework that encodes the sequence hidden state as a quantum superposition vector evolving under parameterized quantum circuits. By formulating memory as a quantum state updated through unitary transformations, QLAM implicitly aggregates global information without explicit pairwise attention computations, preserving linear-time complexity while enabling richer, more stable representations.
QLAM retrieves information via query-dependent quantum measurements, generalizing the attention concept into a quantum observable probing the quantum memory state. Evaluated on sequentialized image classification benchmarks (sMNIST, sFashion-MNIST, sCIFAR-10), QLAM consistently outperformed classical RNNs, Transformers, and state-space baselines, improving accuracy by roughly 1-2% and showing lower variance across 10-fold runs. The work empirically demonstrates that encoding memory through quantum superposition provides a novel mechanism for compact, expressive long-sequence modeling with stable dynamics, opening new research directions integrating quantum computation with sequence architectures.
Key findings
- QLAM achieves 92.6% ± 0.15 accuracy on sMNIST, outperforming Transformer (91.3% ± 0.18) and SSM (91.2% ± 0.15).
- QLAM attains 81.4% ± 0.19 on sFashion-MNIST, beating Transformer (80.2% ± 0.21) and SSM (79.6% ± 0.22).
- On the more difficult sCIFAR-10, QLAM achieves 53.6% ± 0.26 accuracy, surpassing Transformer (53.0% ± 0.28) and SSM (51.8% ± 0.25).
- QLAM memory state uses O(n) complexity for n qubits, where n ~ log2(d) embedding dimension, enabling more compact memory compared to classical O(d) vectors.
- Unitary quantum memory updates preserve state norm across time steps, ensuring stable propagation without exploding/vanishing gradients.
- Query-dependent measurement operators form Hermitian observables decomposed into weighted Pauli matrices, enabling adaptive, learnable attention-like readout.
- QLAM training used hybrid quantum-classical simulation with PennyLane, Adam optimizer, batch size 128, and cosine learning rate schedule over 30-50 epochs.
- 10-fold repeated runs over benchmarks demonstrate statistically consistent improvements in both accuracy and training stability (lower std dev) compared to classical baselines.
Methodology — deep read
The authors define a sequential token modeling problem where input sequences {x1,..., xT} are processed to predict outputs {y1,..., yT} with reliance on the full history. Unlike classical approaches maintaining a latent vector state ht ∈ Rd, QLAM encodes memory as a normalized quantum state |ψt⟩ in a 2^n-dimensional complex Hilbert space, with n qubits used to represent memory. This quantum state forms a superposition of basis memory configurations with complex amplitude coefficients.
Memory evolves over time by applying parameterized unitary operators U(xt, θ) = U_var(θ) U_enc(xt) to the previous state |ψ_{t-1}⟩, where U_enc encodes the new input xt into the quantum state and U_var is a trainable quantum circuit. The use of unitary transformations preserves the norm of the memory state, avoiding instability issues common in classical recurrent models. The initial memory state is the computational basis |0⟩^{⊗n}.
Information retrieval from the quantum memory is performed via query-dependent measurement operators. Given a classical query vector q_t = W_Q x_t, a learnable Hermitian observable O(q_t) is constructed as a weighted sum of Pauli matrices with weights produced by a neural network decoding q_t. The attention weights α_{t,s} are computed as expectation values ⟨ψ_t| O(q_t) |ψ_t⟩ approximated by repeated quantum measurements to produce task-relevant summary vectors.
For evaluation, QLAM was applied to three image classification benchmarks reformulated as long sequential token tasks: sMNIST (784 tokens), sFashion-MNIST (784 tokens), and sCIFAR-10 (3072 tokens flattened RGB pixels). Models process sequences autoregressively and predict class labels at the final step. Baselines compared were vanilla RNN, Transformer encoder, and a classical state-space model (SSM) similar to S4, all matched in parameter budget.
Training used Adam optimizer with learning rate 1e-3, batch size 128, 30 epochs (50 for sCIFAR-10), and a cosine annealing scheduler. The quantum components were simulated using PennyLane in a hybrid quantum-classical framework with angle encoding of inputs to quantum circuits. Evaluation was performed with 10-fold cross-validation, reporting mean and std deviation of classification accuracy.
Reproducibility is supported by implementation within common libraries (PyTorch, PennyLane). However, the quantum operations were simulated and no experiments on actual quantum hardware were reported. Details on exact circuit architectures or hyperparameters for quantum circuits were limited, leaving some ambiguity on exact parameterization and scalability to larger quantum systems. Nevertheless, the experimental pipeline systematically compares QLAM to strong baselines across multiple datasets and seeds.
Technical innovations
- Representing sequence memory as a parameterized quantum state evolving via unitary transformations conditioned on input tokens—a quantum generalization of classical state-space models.
- Query-dependent measurement operators formulated as learnable Hermitian observables composed from weighted Pauli matrices, enabling quantum attention readout without explicit pairwise similarity computations.
- Encoding and evolving long-range contextual information through superposition in a complex Hilbert space, allowing compact memory with logarithmic complexity in embedding size versus classical linear-memory approaches.
- Use of norm-preserving unitary quantum dynamics guarantees stable propagation of memory over long sequences, avoiding issues like exploding and vanishing gradients.
Datasets
- sMNIST — 60,000 train, 10,000 test — derived by flattening MNIST grayscale images into 784-length token sequences.
- sFashion-MNIST — 60,000 train, 10,000 test — Fashion-MNIST images sequentialized into 784-length token sequences.
- sCIFAR-10 — 50,000 train, 10,000 test — CIFAR-10 images flattened into 3072-length RGB token sequences.
Baselines vs proposed
- RNN [14]: sMNIST accuracy = 11.4% vs QLAM = 92.6% ± 0.15
- Transformer [3]: sMNIST = 91.3% ± 0.18 vs QLAM = 92.6% ± 0.15
- SSM [9]: sMNIST = 91.2% ± 0.15 vs QLAM = 92.6% ± 0.15
- RNN [14]: sFashion-MNIST = 12.7% vs QLAM = 81.4% ± 0.19
- Transformer [3]: sFashion-MNIST = 80.2% ± 0.21 vs QLAM = 81.4% ± 0.19
- SSM [9]: sFashion-MNIST = 79.6% ± 0.22 vs QLAM = 81.4% ± 0.19
- RNN [14]: sCIFAR-10 = 13.7% vs QLAM = 53.6% ± 0.26
- Transformer [3]: sCIFAR-10 = 53.0% ± 0.28 vs QLAM = 53.6% ± 0.26
- SSM [9]: sCIFAR-10 = 51.8% ± 0.25 vs QLAM = 53.6% ± 0.26
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.13833.
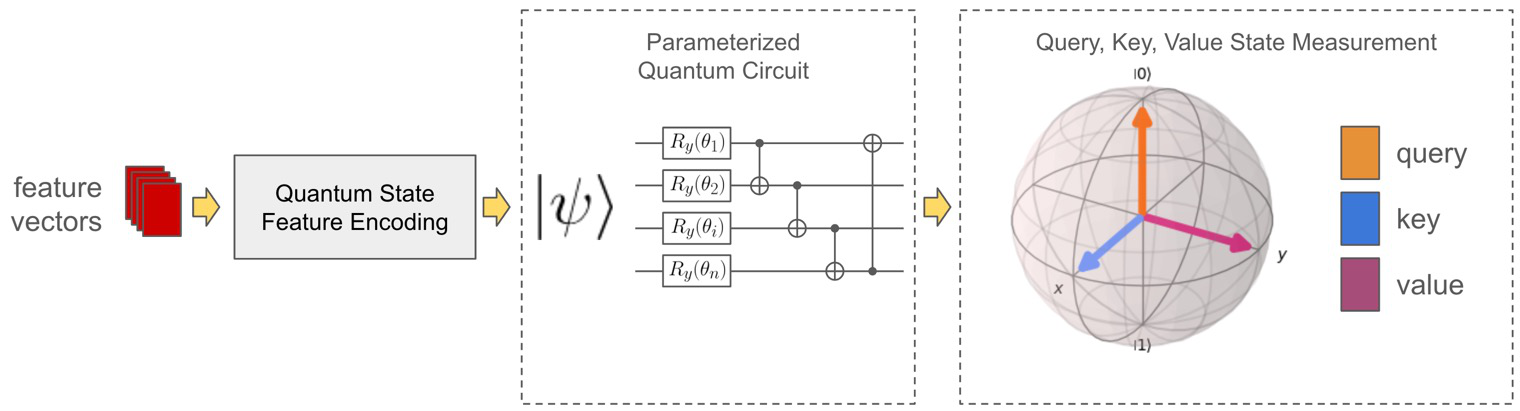
Fig 1: Overview framework of the proposed Quantum Long-Attention Memory.

Fig 3: Computation flow of quantum long-attention readout.
Fig 5: Visualization of sample inputs from the benchmark datasets used in our experiments, including (a) MNIST [57], (b) Fashion-MNIST [58], and (c)
Fig 6: Evaluation protocol for sequential modeling with images.
Limitations
- Experiments are conducted using quantum simulation rather than real quantum hardware, limiting assessment of practical quantum advantages or noise impacts.
- Quantum circuit parameterization details and scalability to larger quantum states (higher qubit counts) are under-specified, raising questions about feasibility on current NISQ devices.
- Datasets are relatively small-scale image benchmarks re-cast as sequence modeling tasks; evaluation on large natural language or multimodal sequence tasks is not explored.
- No adversarial robustness or stress tests under domain shift are reported, so generalization to out-of-distribution sequences is unclear.
- Theoretical analysis of quantum memory expressivity and convergence guarantees is limited, leaving open the extent to which superposition improves representational capacity.
- Comparison baselines focus on vanilla standard models; integration or comparison with recent efficient long-attention or hybrid architectures could provide deeper insight.
Open questions / follow-ons
- How does QLAM perform when implemented on real quantum hardware with noise and limited qubit counts compared to simulator results?
- Can the quantum long-attention memory mechanism be scaled efficiently to handle very large language datasets and multimodal inputs?
- What are the theoretical limits on the expressivity and generalization benefits of quantum superposition-based memory versus classical compressed states?
- How can quantum memory mechanisms integrate with or complement existing efficient transformer approximations to push the frontier of long-range attention?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, QLAM offers a fundamentally novel approach to modeling long-range dependencies in sequential inputs, such as multi-step user interactions or token streams. While classical self-attention mechanisms require quadratic time or approximations that may miss global dependencies, quantum-inspired memory representation suggests a compact and stable alternative for capturing long contexts without exhaustive pairwise computations. Although actual quantum hardware applicability remains speculative at this stage, the conceptual framework encourages reevaluation of memory design for session or behavior modeling in adversarial environments. Practitioners should note that QLAM's superior empirical performance on long sequential data indicates that hybrid quantum-classical designs may inspire future scalable bot detection and challenge generation architectures that better encode subtle global correlations across tokenized inputs.
Cite
@article{arxiv2605_13833,
title={ QLAM: A Quantum Long-Attention Memory Approach to Long-Sequence Token Modeling },
author={ Hoang-Quan Nguyen and Sankalp Pandey and Khoa Luu },
journal={arXiv preprint arXiv:2605.13833},
year={ 2026 },
url={https://arxiv.org/abs/2605.13833}
}